gridsearchcv参数_百闻不如一练:可视化调试模型超参数
以下使用scikit-learn中数据集进行分享。
如果选用随机森林作为最终的模型,那么找出它的最佳参数可能有1000多种组合的可能,你可以使用使用穷尽的网格搜索(Exhaustive Grid Seaarch)方法,但时间成本将会很高(运行很久...),或者使用随机搜索(Randomized Search)方法,仅分析超参数集合中的子集合。
该例子以手写数据集为例,使用支持向量机的方法对数据进行建模,然后调用scikit-learn中validation_surve方法将模型交叉验证的结果进行可视化。需要注意的是,在使用validation_curve方法时,只能验证一个超参数与模型训练集和验证集得分的关系(即二维的可视化),而不能实现多参数与得分间关系的可视化。以下搜索的参数是gamma,需要给定参数范围,用param_range进行传递,评分策略用scoring参数进行传递。其代码示例如下所示:
print(__doc__)import matplotlib.pyplot as pltimport numpy as npfrom sklearn.datasets import load_digitsfrom sklearn.svm import SVCfrom sklearn.model_selection import validation_curveX, y = load_digits(return_X_y=True)param_range = np.logspace(-6, -1, 5)train_scores, test_scores = validation_curve( SVC(), X, y, param_name="gamma", param_range=param_range, scoring="accuracy", n_jobs=1)train_scores_mean = np.mean(train_scores, axis=1)train_scores_std = np.std(train_scores, axis=1)test_scores_mean = np.mean(test_scores, axis=1)test_scores_std = np.std(test_scores, axis=1)plt.title("Validation Curve with SVM")plt.xlabel(r"$gamma$")plt.ylabel("Score")plt.ylim(0.0, 1.1)lw = 2plt.semilogx(param_range, train_scores_mean, label="Training score", color="darkorange", lw=lw)plt.fill_between(param_range, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.2, color="darkorange", lw=lw)plt.semilogx(param_range, test_scores_mean, label="Cross-validation score", color="navy", lw=lw)plt.fill_between(param_range, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.2, color="navy", lw=lw)plt.legend(loc="best")plt.show(); 代码中:
X, y = load_digits(return_X_y=True) # 等价于 digits = load_digits()X_digits = digits.datay_digits = digits.target 以下是支持向量机的验证曲线,调节的超参数gamma共有5个值,每一个点的分数是五折交叉验证(cv=5)的均值。

当想看模型多个超参数与模型评分之间的关系时,使用scikit-learn中validation curve就难以实现,因此可以考虑绘制三维坐标图。
主要用plotly的库绘制3D Scatter(3d散点图)。以下的例子使用scikit-learn中的莺尾花的数据集(iris)。以下例子选用随机森林模型(RandomForestRegressor),利用scikit-learn中的GridSearchCV方法调试最佳超参(tuning hyper-parameters),分别设置超参数"n_estimators","max_features","min_samples_split"的参数范围,详见代码如下:
import numpy as npfrom sklearn.model_selection import validation_curvefrom sklearn.datasets import load_iris from sklearn.ensemble import RandomForestRegressor from plotly.offline import iplot from plotly.graph_objs as go model = RandomForestRegressor(n_jobs=-1, random_state=2, verbose=2)grid = {'n_estimators': [10,110,200], 'max_features': [0.05, 0.07, 0.09, 0.11, 0.13], 'min_samples_split': [2, 3, 5, 8]}rf_gridsearch = GridSearchCV(estimator=model, param_grid=grid, n_jobs=4, cv=5, verbose=2, return_train_score=True)rf_gridsearch.fit(X, y)# and after some hours...df_gridsearch = pd.DataFrame(rf_gridsearch.cv_results_) trace = go.Scatter3d( x=df_gridsearch['param_max_features'], y=df_gridsearch['param_n_estimators'], z=df_gridsearch['param_min_samples_split'], mode='markers', marker=dict( # size=df_gridsearch.mean_fit_time ** (1 / 3), size = 10, color=df_gridsearch.mean_test_score, opacity=0.99, colorscale='Viridis', colorbar=dict(title = 'Test score'), line=dict(color='rgb(140, 140, 170)'), ), text=df_gridsearch.Text, hoverinfo='text')data = [trace]layout = go.Layout( , margin=dict( l=30, r=30, b=30, t=30 ), scene = dict( xaxis = dict( , nticks=10 ), yaxis = dict( , ), zaxis = dict( , ), ), )fig = go.Figure(data=data, layout=layout)iplot(fig) 其运行结果如果,是一个三维散点图(3D Scatter)。
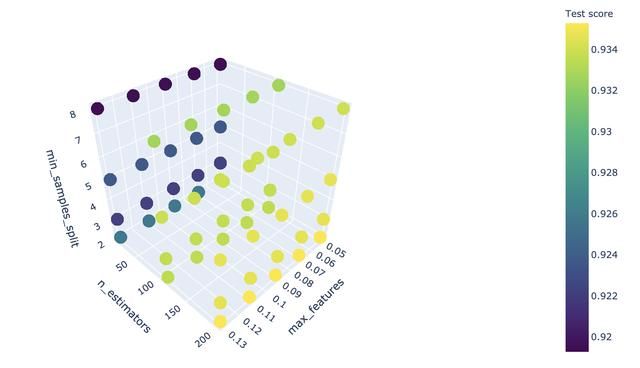
可以看到颜色越浅,分数越高。n_estimators(子估计器)越多,分数越高,max_features的变化对模型分数的影响较小,在图中看不到变化,min_samples_split的个数并不是越高越好,但与模型分数并不呈单调关系,在min_samples_split取2时(此时,其它条件不变),模型分数最高。
除了使用scikit-learn中validation curve绘制超参数与得分的可视化,还可以利用seaborn库中heatmap方法来实现两个超参数之间的关系图,如下代码示例:
import seaborn as sns title = '''Maximum R2 score on test set VS max_features, min_samples_split''' sns.heatmap(max_scores.mean_test_score, annot=True, fmt='.4g');plt.title(title);plt.savefig("heatmap_test.png", dpi = 300); import seaborn as sns title = '''Maximum R2 score on train set VS max_features, min_samples_split''' sns.heatmap(max_scores.mean_train_score, annot=True, fmt='.4g');plt.title(title);plt.savefig("heatmap_train.png", dpi = 300); max_features和min_samples与模型得分关系的可视化如下图所示(分别为网格搜索中测试集和训练集的得分):
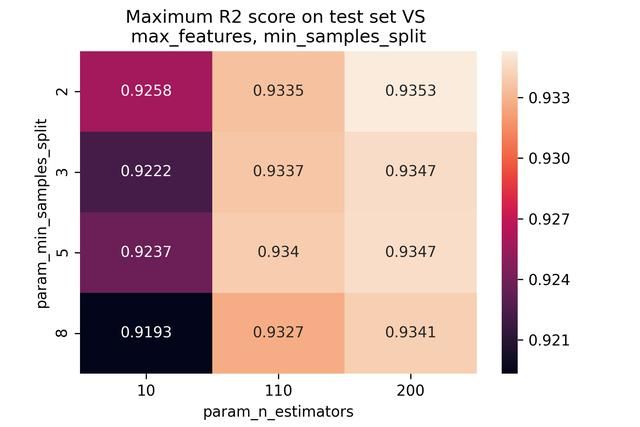
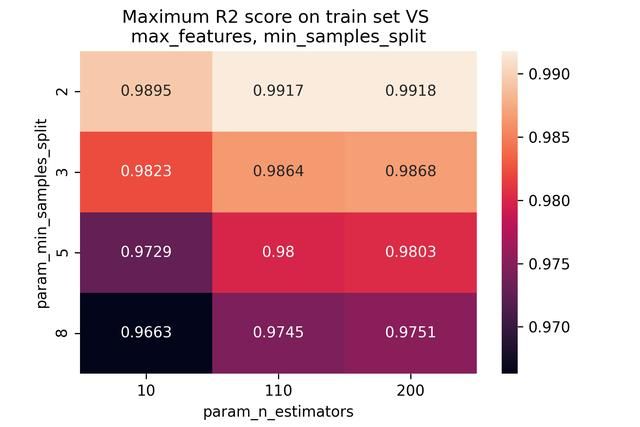
由于一般人很难迅速的在大量数据中找到隐藏的关系,因此,可以考虑绘图,将数据关系以图表的形式,清晰的显现出来。
综上,当关注单个超参数的学习曲线时,可以使用scikit-learn中validation curve,找到拐点,作为模型的最佳参数。
当关注两个超参数的共同变化对模型分数的影响时,可以使用seaborn库中的heatmap方法,制作“热图”,以找到超参数协同变化对分数影响的趋势。
当关注三个参数的协同变化与模型得分的关系时,可以使用poltly库中的iplot和go方法,绘制3d散点图(3D Scatter),将其协同变化对模型分数的影响展现在高维图中。
(1)获取更多优质内容及精彩资讯,可前往:https://www.cda.cn/?seo
(2)了解更多数据领域的优质课程:
