图计算引擎分析——Gemini
作者:京东科技 王军
前言
Gemini 是目前 state-of-art 的分布式内存图计算引擎,由清华陈文光团队的朱晓伟博士于 2016 年发表的分布式静态数据分析引擎。Gemini 使用以计算为中心的共享内存图分布式 HPC 引擎。通过自适应选择双模式更新(pull/push),实现通信与计算负载均衡 [1]。图计算研究的图是数据结构中的图,非图片。
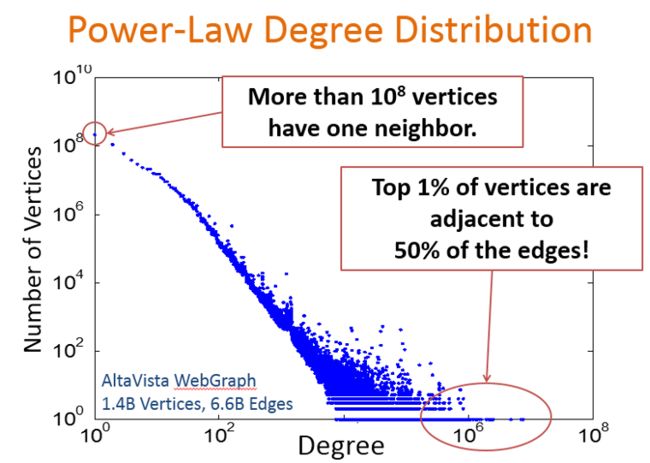
实际应用中遇到的图,如社交网络中的好友关系、蛋白质结构、电商等 [2] 等,其特点是数据量大(边多,点多),边服从指数分布(power-law)[7],通常满足所谓的二八定律:20% 的顶点关联了 80% 的边,其中 1% 的点甚至关联了 50% 的边。
如何存储大图
随着社交媒体、零售电商等业务的发展。图数据的规模也在急剧增长。如标准测试数据集 clueweb-12,生成后的文本数据大小 780+GB。单机存储已经不能满足需求。必须进行图切分。常见的图切分方式有:切边、切点。

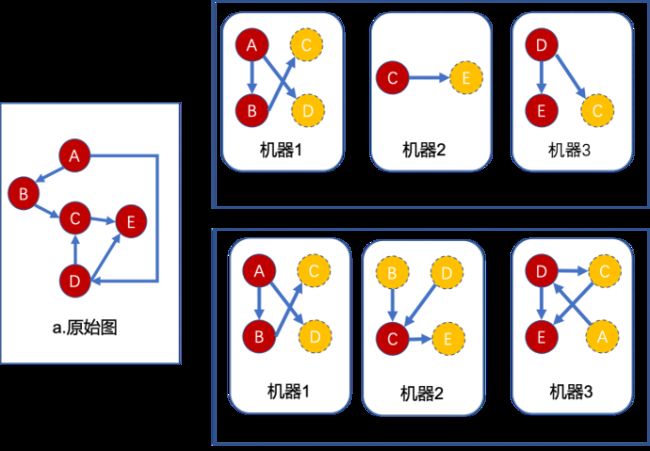
切点:又称 “以边为中心的切图”,保证边不被切开,一条边在一台机器上被存储一次,被切的点创建多个副本,副本点所在的机器不清楚关于此点的相关边。如上图所示,中间点被分别保存三个版本,此点会分别出现在三台机器上,在做更新时需要更新三次。
切边:又称以 “顶点为中心的切图”,相比于切点,保证点不被切开。边会被保存两次,作为副本点所在机器能清楚感知到此点的相关边。如上图所示信息只进行一次更新。
Gemini 采用切边的方式进行存储。
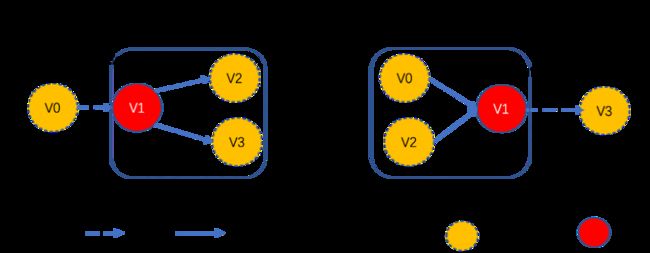
定义抽象图为 G (V,E),Gemini 定义了主副本(master)与镜像副本(mirror),计算时是以 master 为中心进行计算。如下图所示,集群每台机器上仅保存 mirror 到 master 的子图拓扑结构,而 mirror 点并未被实际存储(比如权重值),每台机器负责一部分 master 存储(
 )。
)。
如下图所示,Gemini 将图按照 partition 算法切分到 2 个不同的机器。其中 mirror 作为逻辑结构,没有为其分配实际存储空间;但每条边被存储了两次。
优点:单机可以完整获取 master 的拓扑结构,不需要全局维护节点状态。
图存储
图的常见存储方式:邻接矩阵、邻接表、十字链表,此处不作详细解释,有兴趣可参照 [3]。
| 表示方法 | 邻接矩阵 | 邻接表 | 十字链表 |
|---|---|---|---|
| 优点 | 存储结构简单,访问速度快,顺序遍历边 | 节省空间,访问速度较快 | 在邻接表基础上进一步,节省存储空间。 |
| 缺点 | 占用空间很大(n*n 存储空间) | 存储使用指针,随遍历边结构,为提高效率,需要同时存储出边入边数据。 | 表示很复杂,大量使用了指针,随机遍历边,访问慢。 |
分析上表优缺点,可见:上述三种表示方式都不适合幂律分布的 graph 存储。
压缩矩阵算法
图计算问题其实是一个 HPC(High Performance Computing)问题,HPC 问题一般会从计算机系统结构的角度来进行优化,特别在避免随机内存访问和缓存的有效利用上。有没有一种既保证访问效率,又能满足内存的局部性,还能节省空间的算法呢?压缩矩阵存储。
常见的图压缩矩阵算法有三种 coordinate list(COO)、Compressed sparse row(CSR)、Compressed sparse column (CSC) 算法进行压缩 [8][9]。
COO 压缩算法
COO 使用了坐标矩阵实现图存储(row,collumn,value),空间复杂度 3*|E|;对于邻接矩阵来说,如果图中的边比较稀疏,那么 COO 的性价比是比较高。

CSR/CSC 压缩算法
CSC/CSR 都存储了 column/row 列,用于记录当前行 / 列与上一个行 / 列的边数。Index 列存储边的所在 row/column 的 index。
CSC/CSR 是在 COO 基础上进行了行 / 列压缩,空间复杂度 2|E|+n,实际业务场景中的图,边往往远多于点,所以 CSR/CSC 相对 COO 具有更好压缩比。

优点:存储紧密,内存局部性强;
缺点:遍历边时,需要依赖上一个点的最后一条边的 index,所以只能单线程遍历。
压缩矩阵算法无法实时更新拓扑结构,所以压缩矩阵算法只适用静态或者对数据变化不敏感的场景。
| CSC 伪代码 | CSR 伪代码 |
|---|---|
| loc← 0 for vi←0 to colmns for idx ←0 to colmn [i] do // 输出到指定行的列 edge [vi][index [idx]] ←value [loc] loc← loc+1 end end | loc← 0 for vi←0 to rows for idx ←0 to row [i] do // 输出到指定列的行 edge [ index [idx]] [vi] ←value [loc] loc← loc+1 end end |
Gemini 的图压缩
Gemini 对 CSC/CSR 存储并进行了改进,解释了压缩算法的原理。Gemini 在论文中指出,index 的存储空间复杂度是 O (V),会成为系统的瓶颈。
引出了两种算法:Bitmap Assisted Compressed Sparse Row(bitmap 辅助压缩 CSR)和 Doubly Compressed Sparse Column(双压缩 CSC),空间复杂度降到 O (|V’|),|V’| 为含有入边点的数量。

Gemini 改进后的 CSR 算法使用 bitmap 替换 CSR 原有的 Rows 结构:
• ext 为 bitmap,代码此 bit 对应的 vid 是否存在出边,如上 id 为 0/2/4 的点存在出边。
• nbr 为出边 id;
• ndx 表示保存了边的 nbr 的 index 范围;
如上图 CSR 图,点 0 存在出边(ext [0] 为 1),通过 idx 的差值计算出 0 点存在一条出边(idx [1]-idx [0]=1),相对于存储 0 点第一条出边的 nbr 的下标为 0(idx [0]);同理可推得点 1 无出边。
Gemini 双压缩 CSC 算法将 idx 拆分成 vtx 及 off 两个结构:
• vtx 代表存在入边的点集合;
• nbr 为入边数组;
• Off 表示保存入边 nbr 的 index 偏移范围;
如上图 CSC 算法:vtx 数组表示点 1,2,3,5 存在入边,使用 5 个元素的 off 存储每个点的偏移量。如点 2 存在由 0 指向自己的入边 (0ff [2]-off [1]=1), 所以 nbr [1] 存储的就是点 2 的入边 id(0)。
优点:通过改进后的存储结构,同时支持多线程并行。
Gemini 的双模式更新
双模式更新是 Gemini 的核心:Gemini 采用 BSP 计算模型,在通信及计算阶段独创性地引入 QT 中的 signal、slot 的概念;计算模式上借鉴了 ligra 的设计 [5]。
Gemini 沿用 Ligra 对双模式阈值定义:当活跃边数量小于(|E|/20,|E | 为总边数)时,下一轮计算将使用 push 模式(sparse 图);否则采用 pull 模式(dense 图)。这个值为经验值,可根据场景进行调整。
在开始计算前,都需要统计活跃边的数量,确定图模式。
在迭代过程中,每一个集群节点只保存部分计算结果。
在分布式系统中,消息传播直接涉及到通信量,间接意味着阈值强相关网络带宽和引擎的计算效率。双模式直接平衡了计算负载与通信负载。
圆角矩形标识操作是在本地完成的,Gemini 将大量的需通信工作放在本地完成。
Gemini 节点构图
Gemini 在实现上,增加 numa 特性。如何分配点边,如何感知 master 在哪台机器,哪个 socket 上,都直接影响到引擎计算效率。
location aware 和 numa aware 两个 feature 去解决了上述问题;由于 Graph 幂律分布的特点,运行时很难获得很好的负载均衡效果,所以在 partition 时,也引入了平衡因子 α,达到通信与计算负载均衡。
在 partition 阶段通过增加 index 结构:partition_offset, local_partition_offset。(partition_offset 记录跨机器的 vid offset,local_partition_offset 记录跨 numa 的 vid offset)。
Location-aware
以边平均算法为例,集群规模 partitions = 4(台),图信息见下表。
点边分布情况
| 点 s | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|---|
| Out Edge | 0 | 3 | 5 | 30 | 2 | 4 | 6 | 2 | 20 |
存在出边 sum = 72
| 切图轮次 | 1 | 2 | 3 |
|---|---|---|---|
| 剩余边 | 72 | 34 | 22 |
| 平均分配 | 18 | 12 | |
| Master 分配结果 | 0: 0~3 | ||
| 1: | 4~6 | ||
| 2: | 7~8 | ||
| 3: |
从上表分析可见:
• 编号为 0 的机器分配 4 点 38 条边;
• 编号为 1 的机器分配 3 点 12 条边;
• 编号为 2 的机器分配 2 点 22 条边;
• 编号为 3 的机器分配 0 点 0 条边。
此方法分配会造成负载的偏斜,影响到引擎的计算效率。
Gemini 在切图时,每个 partition 分配点个数遵循公式

, 其中平衡因子定义为 α=8*(partitions-1)。
仍然以上图为例,Gemini 通过ɑ因子平衡了边的分布。
| 切图轮次 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 剩余权重边 | 288 | 208 | 128 | 44 |
| 平均分配 | 72 | 70 | 64 | 44 |
| Master 分配结果 | 0: 0~2 | |||
| 1: | 3~4 | |||
| 2: | 5~7 | |||
| 3: | 8 |
对比两次切分的结果,添加 α 增加了出边较少的点的权重。
通过实际场景应用发现:按照论文中 α 平衡因子设定,很可能出现内存的倾斜(内存分配上相差 20% 左右,造成 oom kill)。在实际生产场景中,我们根据时间场景和集群配置,重新调整了 α 参数取值设置,内存分配基本浮动在 5% 左右。
Numa-aware
NUMA 介绍
根据处理器的访问内存的方式不同,可将计算机系统分类为 UMA(Uniform-Memory-Access,统一内存访问)和 NUMA(Non-Uniform Memory Access, 非一致性内存访问)。
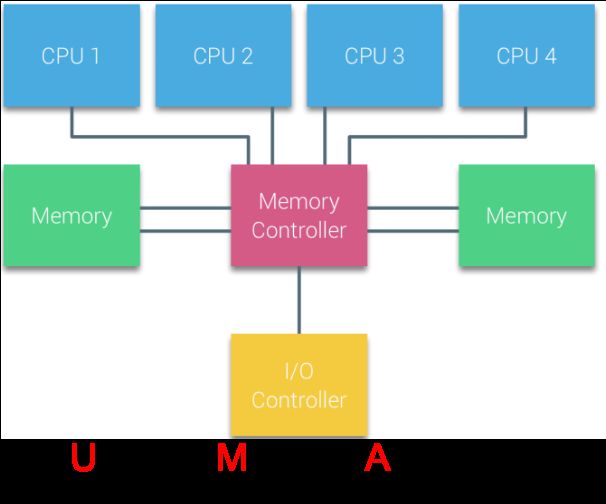
在 UMA 架构下,所有 cpu 都通过相同的总线以共享的方式访问内存。在物理结构上,UMA 就不利于 cpu 的扩展(总线长度、数据总线带宽都限制 cpu 的上限)。
Numa (Non-Uniform Memory Access, 非一致性内存访问)是目前内核设计主流方向。每个 cpu 有独立的内存空间(独享),可通过 QPI(quick path Interconnect)实现互相访问。由于硬件的特性,所以跨 cpu 访问要慢 [11]。

相对于 UMA 来说,NUMA 解决 cpu 扩展,提高数据总线宽度总线长度带来的问题,每个 cpu 都有自己独立的缓存。
根据 NUMA 的硬件特性分析,NUMA 具有更高本地内存的访问效率,方便 CPU 扩展。HPC 需要数据访问的高效性,所以 NUMA 架构更适合 HPC 场景(UMA 与 NUMA 无优劣之分)。
Gemini 充分利用了 NUMA 对本 socket 内存访问低延迟、高带宽的特性,将本机上的点跨多 socket 数据实现 NUMA-aware 切分(切分单位 CHUNKSIZE)。切分算法参考 Location-aware。
Gemini 的任务调度
Gemini 计算采用 BSP 模型(Bulk Synchronous Parallel)。为提高 CPU 和 IO 的利用率做了哪些工作呢?Gemini 提出了两个设计:计算通信协同调度、work stealing(偷任务)。
计算通信系统调度
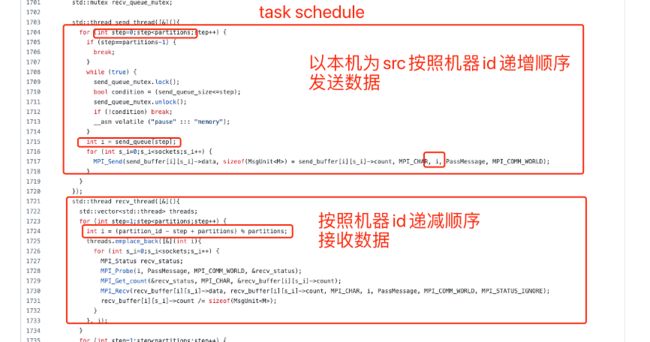
Geimini 在计算过程中引入了任务调度控制。他的调度算法设计比较简单,可简单理解为使用机器节点 ID 按照规定顺序收发数据,避免收发任务碰撞。
Gemini 将一轮迭代过程称为一个 step,把每一个 step 又拆分为多个 mini step(数量由集群规模确定)。
• computation communication interleave
为了提高效率,减少线程调度的开销,Gemini 将一次迭代计算拆分成了 computation 和 communication 两个阶段。在时间上,每一轮迭代都是先计算,再进行通信,通信任务调度不会掺杂任何计算的任务。
这样设计的好处在于既保证上下文切换的开销,又保证内存的局部性(先计算再通信)。缺点就在于需要开辟比较大的缓存 buffer。
• Task Schedule
简而言之:每个机器都按照特定的顺序收发数据
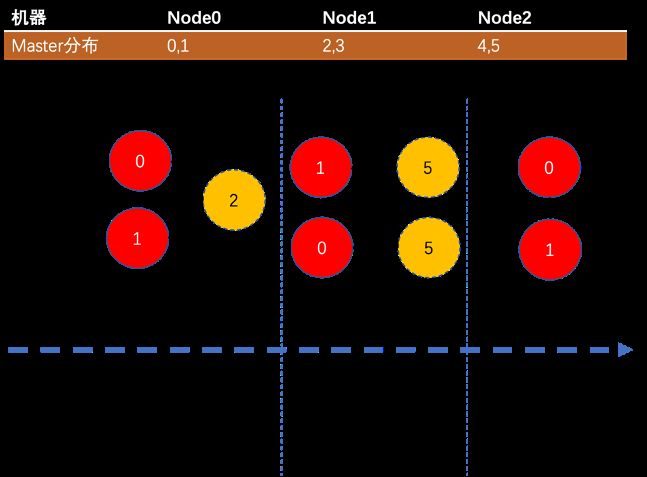
上图列举了集群中 master 分布情况,以 Node0 为例:
| 节点 | Node 0 |
|---|---|
| Master 范围 | 0、1 |
| 阶段 1 | 将数据向 Node1 发送关于点 2 的数据,接收来自 Node2 数据 |
| 阶段 2 | 将数据向 Node2 发送关于点 5 的数据,接收来自 Node1 数据 |
| 阶段 3 | 处理自身的数据(本地数据不经网络传输) |
在整个过程中,node0 按照机器 id 增序发送,按照机器 id 降序接收,这个 feature 可以一定程度避免出现:同时多台机器向同一台机器发送数据的情况,降低通信信道竞争概率。
Work stealing
该设计是为了解决分布式计算系统中常见的 straggler 问题。
当某个 cpu task 处理完成所负责的 id,会先判断同一个 socket 下的其他 cpu task 是否已完成。如果存在未完成任务,则帮助其他的 core 处理任务。(跨机器的 work stealing 没有意义了,需要经历两次网络 io,而网络 io 延迟是大于处理延迟。)
Gemini 开源代码中定义线程状态管理结构,下图引用了开源代码的数据结构,并对变量进行了说明。

开始计算时,每个 core 均按照自己的 threadstate 进行处理数据,更大提升 cpu 使用效率。该设计是以点为单位进行的数据处理,但未解决热点的难题(这也是业界难题,可以对热点再次切分,也是需要突破的一个问题)。
下面是 2 core 的 work stealing 示意图:
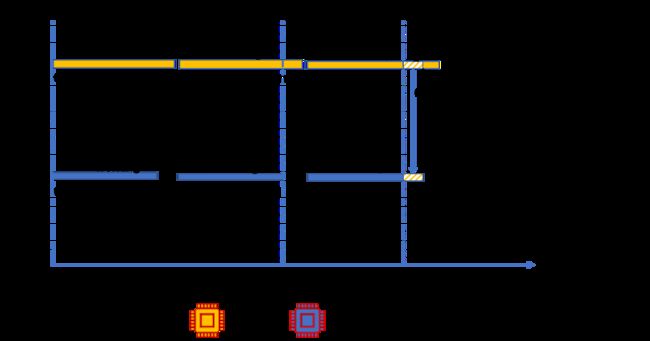
其中在初始情况 T0 时刻,core1 与 core2 同时开始执行,工作状态都为 working;
在 T1 时刻, core2 的任务首先执行完成,core1 还未完成。
为了提高 core2 的利用率,就可以将 core1 的任务分配给 core2 去做。为了避免 core1、core2 访问冲突,此处使用原子操作获取 stealing 要处理 id 范围,处理完成之后,通过 socket 内部写入指定空间。
在 T2 时刻,core2 更新工作状态为 stealing,帮助 core1 完成任务。
在开源代码中,在构图设计 tune chunks 过程,可以实现跨机器的连续数据块读取,提升跨 socket 的效率。
注:开源代码中,push 模式下并未使用到 tread state 结构,所以 tune chunks 中可以省略 push 模式 thread state 的初始化工作。其中在初始情况 T0 时刻,core1 与 core2 同时开始执行,工作状态都为 working;
Gemini API 接口设计
API 设计上借鉴了 Ligra,设计了一种双相信号槽的分布式图数据处理机制来分离通信与计算的过程。
屏蔽底层数据组织和计算分布式的细节。算法移植更加方便,简化开发难度。并且可以实现类 Pregel 系统的 combine 操作。
将图的稀疏、稠密性作为双模式区分标志。
Gemini 算法调用使用 c++11 的 lambda 函数表达式,将算法实现与框架解耦。
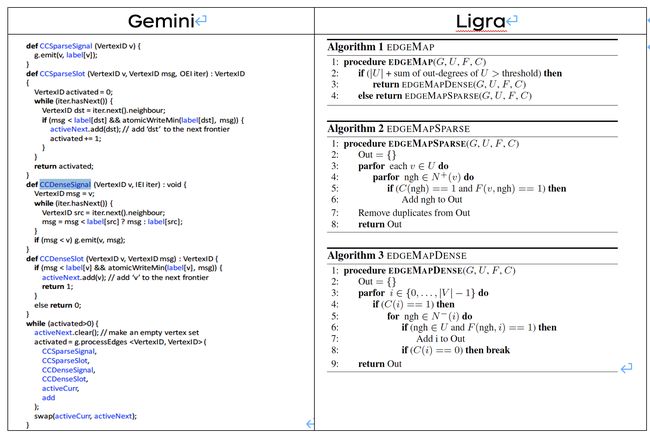
Gemini 在框架设计中创新的使用 signal、slot。将每轮迭代分为两个阶段:signal(数据发送),slot(消息处理),此处实现了通信与数据处理过程的解耦。
Gemini 源码分析
Gemini 代码可以分为初始化,构图,计算三部分。
初始化:设置集群配置信息,包括 mpi、numa、构图时所需的 buffer 开销的初始化;
构图:依据算法输入的数据特征,实现有 / 无向图的构造;
计算:在已构造完成的图上,使用双模式计算引擎计算。
Gemini 构图代码分析
Gemini 在构图时,需要事先统计每个点的出边、入边信息,再依据统计信息切图,申请存储图所需的空间。
以无向图构建为例,整个构图过程经历了 3 次文件读取:
1. 统计入边信息;
2. 生成图存储结构(bitmap、index);
3. 边数据存储。
入口函数:load_undirected_from_directed
开源源码 Gemini 集群同时分段读取同一份 binary 文件,每台机器都分段读取一部分数据。
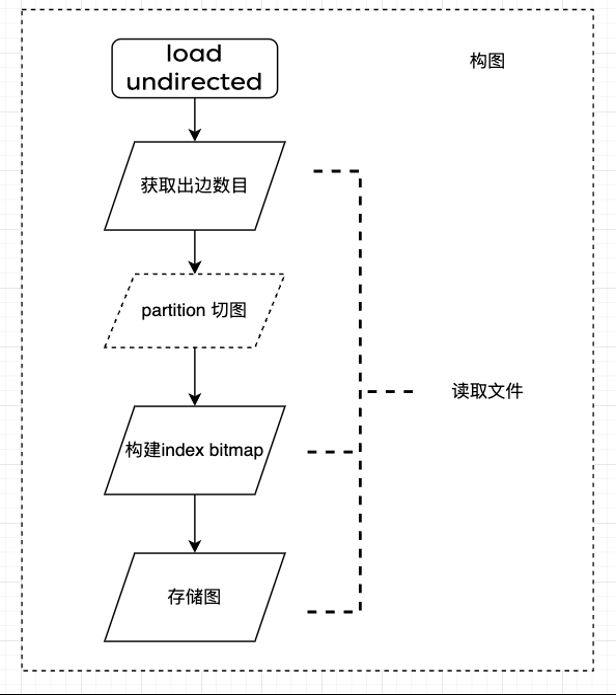
出边信息统计

上图代码分段读取文件,统计每个点的出边信息,见 line 456、457,通过 openmpi 通信,聚合所有点出边信息 line 460。
Line 451:原理上可以使用 omp 并发,但由于原子操作锁竞争比较大效率并不高。
Location aware 代码实现
Gemini 在 location aware 解决了地址感知,集群负载平衡的工作。

解释最后一行:owned_vertices 记录当前机器 master 点个数,partition_offset [partition_id] 记录 master 节点 vid 的下限,partition_offset [partition_id+1] 记录 master 节点 vid 的上限。
好处:
1. 提升了内存的访问效率;
2. 减少了内存的零头(在这个过程中,Gemini 为提高内存块读取的效率,使用 pagesize 进行内存对齐。)。
NUMA aware 代码实现
NUMA aware 作用是在 socket 上进行了 partition,平衡算力和 cpu 的负载,程序实现与 Location aware 过程类似。
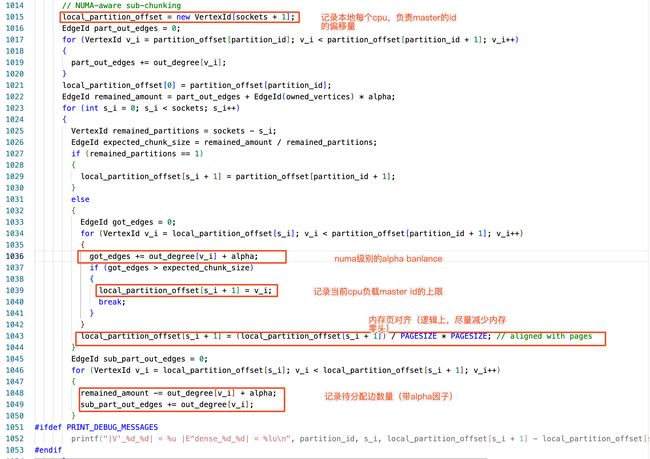
NUMA aware 也进行了 a 因子平衡和 pagesize 对齐。
总结:机器机器共享同一份出边统计数据,所以在 location aware 和 numa aware 阶段的结果都是相同的,partition 结果也不会出现冲突的情况。
注:aware 阶段都是对 master 的切分,未统计 mirror 的状态;而构图过程是从 mirror 的视角实现的,所以下一个阶段就需要统计 mirror 信息。
构建边管理结构
在完成 Location aware 和 NUMA aware 之后,需要考虑为边 allocate 存储空间。由于 Gemini 使用一维数组存储边,所以必须事先确定所需的存储空间,并 allocate 相应的内存管理结构。Gemini 使用二级索引实现点边遍历。
读者很可能出现这样的误区:建立 master->mirror 关系映射。这样会带来什么问题?超级顶点。也就意味着通信和计算负载都会上升。这对图计算引擎的效率影响很大。
可自行计算万亿级别点,每个 socket 上存储的 index 占用的空间。

单
节点处理本地数据(按照 CHUNCKSIZE 大小,分批向集群其他节点分发边数据)。记录 mirror 点的 bitmap 及出边信息。

数据发送过程是按照 CHUNCKSIZE 大小,分批发送。
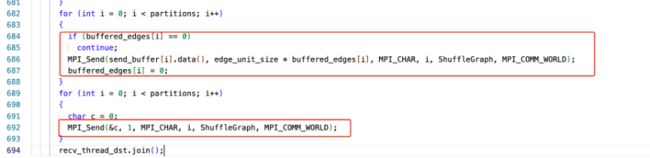
在发送结束时,需确保所用的数据发送完成,发送字符‘\0‘作为结束符。
图存储
依据上一阶段构建的管理结构实现边的存储,管理结构解释:
Bitmap 的作用是确定在此 socket 下,此 mirror 点是否存在边;
Index 标识边的起始位置(见图压缩章节介绍)。
下图注释内容介绍了 index 的构建过程,构建过程中使用了单线程,cpu 利用率较低,可自行测试一下。
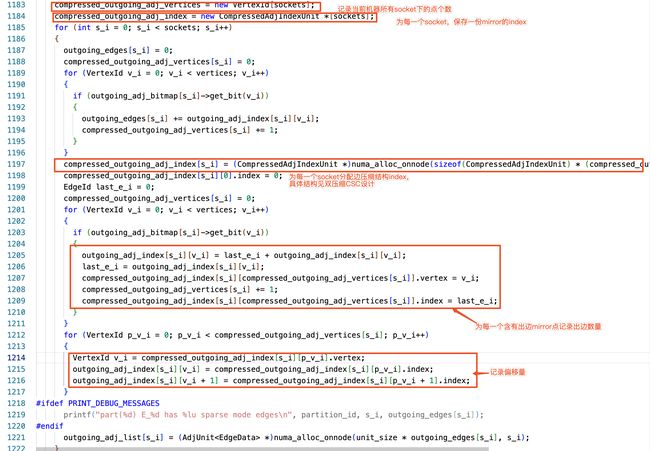
在边存储时,数据分发实现了并发传输。代码实现过程,见下图代码注释。

边数据分发过程代码:

任务调度代码实现
构建任务调度数据结构 ThreadState, 参数配置 tune_chunks 代码实现,使用了 α 因子进行平衡。逻辑上将同一个 socket 的边数据,按照线程进行二次划分(balance)。

计算源码分析
双模式的核心思想:尽可能将通信放到本地内存,减少网络 IO 开销。
以 dense 模式为例:pull 模式将集群中的其他节点的部分结果 pull 到本地,实现同步计算。

处理模块代码定义

注意:line1796 send_queue_mutex 的使用,通过锁控制发送模块的先后顺序。
任务调度算法实现:
为保证每台机器上的计算结果一致,所以在传播过程中每个机器都会接收到相同的数据,在进行计算。
总结
Gemini 的关键设计:
• 自适应双模式计算平衡了通信和计算的负载问题;
• 基于块的 Partition 平衡了集群单机计算负载;
• 图压缩降低了内存的消耗。
Gemini 可继续优化方向:
• Proces_edges 过程中,发送 / 接收 buffer 开辟空间过大,代码如下:

在切换双模运算时,调用了 resize 方法,此方法实现:当仅超过 capacity 时,才重新 alloc 内存空间,未实现进行缩容(空间
![]()
)。

a
• adj_index 会成为系统瓶颈
论文中也提到 adj_index 一级索引会占用大部分空间(论文中也提到了会成为瓶颈)。改进后的 CSC 压缩算法使用二级索引结构。在计算时会影响数据访问速度,无向图中压缩效果不好,远高于一级索引的空间复杂度(幂律分布决定,极大部分点存在 1 条以上的出边,易得空间复杂度 2|V’|>|V|)。
• α 因子调整
α 因子应该根据图的特征进行动态调整,否则很容易造成内存 partition 偏斜。
• 动态更新
由于压缩矩阵和 partition 方式都限制了图的更新。可通过改变 parition 切分方式,牺牲 numa 特性带来的局部性,通过 snapshot 实现增量图。
• 外存扩展
Gemini 是共享内存的分布式引擎。在实际生产环境中,通过暴力增加机器解决内存不足的问题,不是最优解。大容量外存不失为更好的解决方案。
参考文献
11 1. Gemini: A Computation-Centric Distributed Graph Processing System 2. https://zh.wikipedia.org/wiki/%E5%9B%BE_(%E6%95%B0%E5%AD%A6) 3. https://oi-wiki.org/graph/save/ 4. https://github.com/thu-pacman/GeminiGraph.git 5. Ligra: A Lightweight Graph Processing Framework for Shared Memory 6. Pregel:a system for large-scale graph processing. 7. Powergraph: Distributed graph-parallel computation on natural graphs 8. https://en.wikipedia.org/wiki/Sparse_matrix#Coordinate_list_(COO) 9. https://programmer.ink/think/implementation-of-coo-and-csr-based-on-array-form-for-sparse-matrix.html 10. https://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series/ 11. https://frankdenneman.nl/2016/07/13/numa-deep-dive-4-local-memory-optimization/
内容来源:京东云开发者社区 [https://www.jdcloud.com/]