学习下Redis内存模型
作者:京东零售 吴佳
前言
redis,对于一个java开发工程师来讲,其实算不得什么复杂新奇的技术,但可能也很少人去深入了解学习它的底层的一些东西。下面将通过对内存统计、内存划分、存储细节、对象类型&内部编码这四个模块来学习学习redis的内存模型,手字笔录,潜心修行。
一、redis的内存统计
info memory 命令查看内存使用情况:服务器基本信息、CPU、内存、持久化、客户端连接信息等等,如下图:
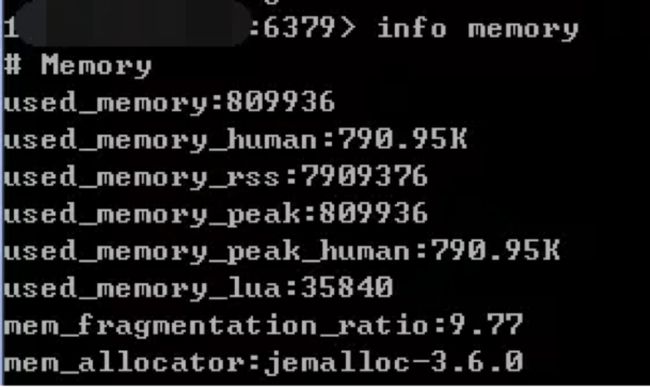
(1)used_memory和used_memory_rss
used_memory:Redis分配器分配的内存总量 + 虚拟内存(磁盘)
used_memory_rss:Redis进程占据操作系统的内存 + 进程运行本身需要的内存 + 内存碎片等 (*:注意 used_memory_rss 不包括虚拟内存)
两者区别:
①面向角度:used_memory: Redis角度 used_memory_rss:操作系统角度
②大小不一定是后者大于前者:内存碎片和Redis进程运行需要占用内存,使得前者可能比后者小,另一方面虚拟内存的存在,使得前者可能比后者大
(2)mem_fragmentation_ratio
内存碎片比率, 等于 used_memory_rss / used_memory
mem_fragmentation_ratio > 1 : 值越大,内存碎片比例越大
mem_fragmentation_ratio < 1 : 说明Redis使用了虚拟内存
*:由于虚拟内存的媒介是磁盘,比内存速度要慢很多,当这种情况出现时,应该及时排查,如果内存不足应该及时处理,如增加Redis节点、增加Redis服务器的内存、优化应用等。
正常情况下:mem_fragmentation_ratio = 1.03左右 (健康:对于jemalloc来说)
上面的情况:没有向Redis中存入数据,Redis进程本身运行的内存使得used_memory_rss 比used_memory大得多
(3)mem_allocator:
Redis使用的内存分配器,在编译时指定,可以是 libc 、jemalloc或者tcmalloc,默认是jemalloc。
(4)used_memory_peak:
Redis的内存消耗峰值
(5)used_memory_human和used_memory_peak_human:
字面含义,以人类阅读的方式返回。
二、redis的内存划分
数据:最主要的部分,会统计在used_memory。实际上,在Redis内部,每种类型可能有2种或更多的内部编码实现。此外,Redis在存储对象时,并不是直接将数据扔进内存,而是会对对象进行各种包装:如RedisObject、SDS等。
进程本身内存:Redis主进程本身运行肯定需要占用内存,如代码、常量池等等。这部分内存大约几兆,在大多数生产环境中与Redis数据占用的内存相比可以忽略。这部分内存不是由jemalloc分配,因此不会统计在used_memory中。
缓冲内存:包含客户端缓冲区、复制积压缓冲区、AOF缓冲区
客户端缓冲区:存储客户端连接的输入输出缓冲
复制积压缓冲区:用于部分复制功能
AOF缓冲区:用于在进行AOF重写时,保存最近的写入命令
内存碎片:内存碎片是Redis在分配、回收物理内存过程中产生的。
三、redis的数据存储细节
当我们执行一个redis指令,比如:set hello world,redis底层存储到底干了什么?
上面就涉及到两个概念:jemalloc和RedisObject
(1)jemalloc
内存分配器:可以是 libc 、jemalloc或者tcmalloc,默认jemalloc
jemalloc内存划分:小、大、巨大,每个又分许多小内存块单位

(例如,如果需要存储大小为130字节的对象,jemalloc会将其放入160字节的内存单元中。)
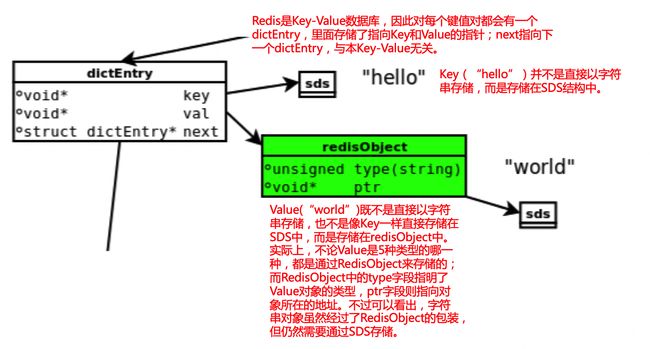
(2)RedisObject(核心数据结构)
redis的五种类型都是通过RedisObject存储,Redis对象的 类型、内部编码、内存回收、共享对象等功能都需要RedisObject对象支持。
typedef struct redisObject{
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
}
type:表示对象的数据类型,占4bit。
encoding:表示对象内部的编码,占4bit,对于redis的每种数据类型,都至少有俩
种内部编码。比如字符串类型有:int、embstr、raw。
lru:记录的是对象最后一次被命令程序访问的时间,占据的比特数不同的版本有所不同(如4.0版本占24比特,2.6版本占22比特)。
refcount:
1、概念:refcount记录的是该对象被引用的次数,类型目前仅为整型。
2、作用:refcount的作用,主要在于对象的引用计数和内存回收:
①当创建新对象时,refcount初始化为1;
②当有新程序使用该对象时,refcount加1;
③当对象不再被一个新程序使用时,refcount减1;
④当refcount变为0时,对象占用的内存会被释放。
3、为什么只支持整数值的字符串对象?对内存和CPU(时间)的平衡:
①对于整数值,判断操作复杂度为O(1);
②对于普通字符串,判断复杂度为O(n);
③而对于哈希、列表、集合和有序集合,判断的复杂度为O(n^2)。
4、目前实现:Redis服务器在初始化时,会创建10000个字符串对象,值分别是0~9999的整数值;10000这个数字可以通过调整参数REDIS_SHARED_INTEGERS(4.0中是 OBJ_SHARED_INTEGERS)的值进行改变。(共享对象的引用次数可以通过object refcount命令查看:)
ptr:ptr指针指向具体的数据,如前面的例子中,set hello world,ptr指向包含字符串world的SDS
(3)SDS
1、概念:Redis没有直接使用C字符串(即以空字符‘\0’结尾的字符数组)作为默认的字符串表示,而是使用了SDS。SDS是简单动态字符串(Simple Dynamic String)的缩写。
2、结构:

3、相关计算:
*:buf数组的长度 = free+len+1(其中1表示字符串结尾的空字符)
一个SDS结构占据的空间 = free所占长度+len所占长度+ buf数组的长度=4+4+free+len+1=free+len+9。
4、加“\0”目的:为了简单字符串能够调用c字符串部分函数
四、redis的对象类型&内部编码
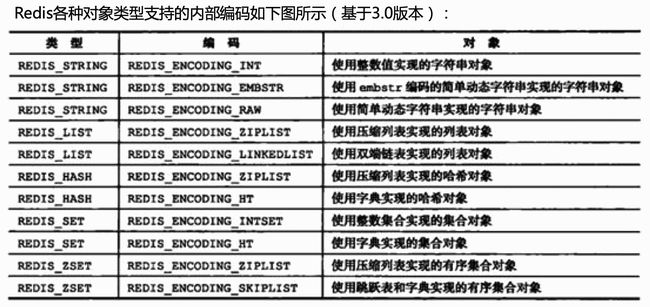
(1)字符串
1、字符串长度不超过512MB
2、内部编码有三种: int、embstr、raw
3、编码转换关系:
int:整形
embstr:<=39字节的字符串
raw:>39字节的字符串
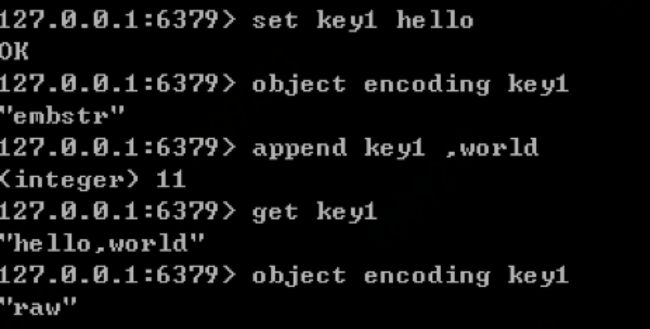
4、embstr和raw的区别:
①embstr都使用redisObject和sds结构存储
②emstr创建只分配一次内存空间(redisObject和sds一起分配,因为它是连续的)
缺点:创建和删除都需要整个redisObject和sds重新分配空间,所以emstr实现为只读。
③raw需要分配两次
5、当emstr被修改时,会先变成raw,再修改,无论是否达到39字节
这也是为了避免创建整个redisObject和sds

(2)列表
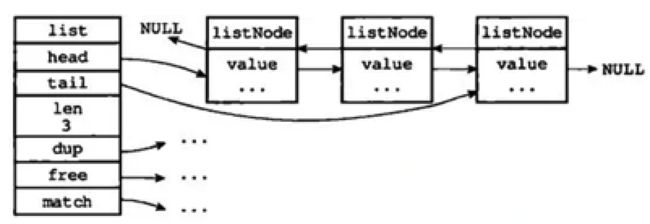
1、内部编码:ziplist和linkedlist:(每个节点指向的是redisObject)
2、压缩列表:节约空间,连续内存块
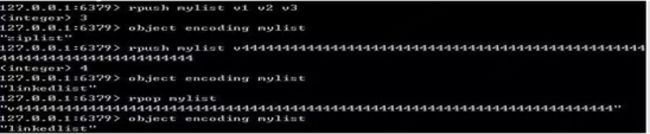
3、编码转换:什么情况下使用压缩列表?
①列表元素 < 512个
②列表中所有字符串对象都不足64字节(字符串长度)
(3)hash: 内层哈希和外层哈希
内层哈希:ziplist、hashtable
外层哈希:hashtable