构建强化学习
Ten months ago, I started my work as an undergraduate researcher. What I can clearly say is that it is true that working on a research project is hard, but working on an Reinforcement Learning (RL) research project is even harder!
牛逼恩个月前,我开始了我的工作,作为一个大学生研究员。 我可以明确地说的是, 从事研究项目确实很辛苦,但是从事强化学习(RL)研究项目的确更难!
What made it challenging to work on such a project was the lack of proper online resources for structuring such type of projects;
从事这样一个项目的挑战是缺乏适当的在线资源来构造这种类型的项目 ;
Structuring a Web Development project? Check!
构建Web开发项目? 检查!
Structuring a Mobile Development project? Check!
构建移动开发项目? 检查!
Structuring a Machine Learning project? Check!
构建机器学习项目? 检查!
Structuring a Reinforcement Learning project? Not really!
构建强化学习项目? 并不是的!
To better guide future novice researchers, beginner machine learning engineers, and amateur software developers to start their RL projects, I pulled up this non-comprehensive step-by-step guide for structuring an RL project which will be divided as follows:
为了更好地指导未来的新手研究人员,初学者机器学习工程师和业余软件开发人员启动RL项目,我整理了这份非全面的分步指南,以构建RL项目 ,该指南分为以下几部分:
Start the Journey: Frame your Problem as an RL Problem
开始旅程:将您的问题定为RL问题
Choose your Weapons: All the Tools You Need to Build a Working RL Environment
选择武器:建立有效的RL环境所需的所有工具
Face the Beast: Pick your RL (or Deep RL) Algorithm
面对野兽:选择您的RL(或深度RL)算法
Tame the Beast: Test the Performance of the Algorithm
驯服野兽:测试算法的性能
Set it Free: Prepare your Project for Deployment/Publishing
免费设置:为部署/发布准备项目
In this post, we will discuss the first part of this series:
在本文中,我们将讨论本系列的第一部分:
开始旅程:将您的问题定为RL问题 (Start the Journey: Frame your Problem as an RL Problem)

This step is the most crucial in the whole project. First, we need to make sure whether Reinforcement Learning can be actually used to solve your problem or not.
这是整个项目中最关键的一步。 首先,我们需要确定强化学习是否可以真正用于解决您的问题 。
1.将问题视为马尔可夫决策过程(MDP) (1. Framing the Problem as a Markov Decision Process (MDP))
For a problem to be framed as an RL problem, it must be first modeled as a Markov Decision Process (MDP).
对于要被构造为RL问题的问题,必须首先将其建模为马尔可夫决策过程(MDP)。
A Markov Decision Process (MDP) is a representation of the sequence of actions of an agent in an environment and their consequences on not only the immediate rewards but also future states and rewards.
马尔可夫决策过程(MDP)表示环境中代理行为的顺序,以及它们不仅对即时收益而且对未来状态和收益的影响 。
An example of a MDP is the following, where S0, S1, S2 are the states, a0 and a1 are the actions, and the orange arrows are the rewards.
以下是一个MDP的示例,其中S0,S1,S2是状态,a0和a1是动作,橙色箭头是奖励。

An MDP must also satisfy the Markov Property:
MDP还必须满足Markov属性 :
The new state depends only on the preceding state and action, and is independent of all previous states and actions.
新状态仅取决于先前的状态和动作,并且独立于所有先前的状态和动作 。
2.确定目标 (2. Identifying your Goal)

What distinguishes Reinforcement Learning from other types of Learning such as Supervised Learning is the presence of exploration and exploitation and the trade-off between them.
强化学习与其他类型的学习(如监督学习) 的区别在于探索和开发的存在以及它们之间的权衡 。
While Supervised Learning agents learn by comparing their predictions with existing labels and updating their strategies afterward, RL agents learn by interacting with an environment , trying different actions, and receiving different reward values while aiming to maximize the cumulative expected reward at the end.
监督学习的代理商通过将其预测与现有标签进行比较并随后更新策略来进行 学习 ,而RL代理商通过与环境进行交互 , 尝试不同的操作并获得不同的奖励值来学习,同时力求最大程度地提高最终的预期奖励 。
Therefore, it becomes crucial to identify the reason that pushed us to use RL:
因此,确定促使我们使用RL的原因至关重要:
Is the task an optimization problem?
任务是优化问题吗?
Is there any metric that we want the RL agent to learn to maximize (or minimize)?
是否有任何我们希望RL代理学习最大化(或最小化)的指标?
如果您的回答是肯定的,那么RL可能很适合这个问题! (If your answer is yes, then RL might be a good fit for the problem!)
3.构筑环境 (3. Framing the Environment)
Now that we are convinced that the RL is a good fit for our problem. It is important to define the main components of the RL environment: the states, the observation space, the action space, the reward signal, and the terminal state.
现在,我们确信RL非常适合我们的问题。 定义RL环境的主要组成部分很重要: 状态,观察空间,动作空间,奖励信号和终端状态 。
Formally speaking, an agent lies in a specific state s1 at a specific time. For the agent to move to another state s2, it must perform a specific action a0 for example. We can confidently say that the state s1 encapsulates all the current conditions of the environment at that time.
从形式上来说,代理在特定时间处于特定状态s1。 为了使代理移动到另一个状态s2,它必须执行例如特定的操作a0。 我们可以自信地说状态s1封装了当时环境的所有当前条件。
The observation space: In practice, the state and observation are used interchangeably. However, we must be careful because there is a discernable difference between them. The observation represents all the information that the agent can capture from the environment at a specific state.
观察空间 :实际上,状态和观察可以互换使用。 但是,我们必须小心,因为它们之间存在明显的差异。 观察结果表示代理可以在特定状态下从环境捕获的所有信息。
Let us take the very famous RL example of the CartPole environment, where the agent has to learn to balance a pole on a cart:
让我们以CartPole环境的非常著名的RL示例为例,代理商必须学习平衡推车上的杆:

The observations that are recorded at each step are the following:
每个步骤记录的观察结果如下:
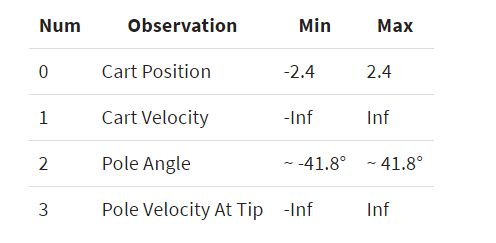
Another good example might be the case of an agent trying to discover its way through a maze, where at each step, the agent might receive for example an observation of the maze architecture and its current position.
另一个很好的例子可能是代理试图通过迷宫发现自己的方式的情况,在该步骤中,代理可能会收到例如对迷宫架构及其当前位置的观察。

The action space: The action space defines the possible actions the agent can choose to take at a specific state. It is by optimizing its choice of actions, that the agent can optimize its behavior.
操作空间 :操作空间定义了代理可以选择在特定状态下采取的可能操作。 代理可以通过优化其操作选择来优化其行为。

In the Maze example, an agent roaming the environment would have the choice of moving up, down, left, or right to move to another state.
在迷宫示例中,漫游环境的代理可以选择上,下,左或右移动到另一个状态。
The reward Signal: Generally speaking, the RL agent tries to maximize the cumulative reward over time. With that in mind, we can design the reward function in the best way to be able to maximize or minimize specific metrics that we choose.
奖励信号 :一般而言, RL代理会尝试随着时间的推移最大化累积奖励 。 考虑到这一点,我们可以以最佳方式设计奖励功能,以便能够最大化或最小化我们选择的特定指标。
For the CartPole environment example, the reward function was designed as follows:
对于 CartPole 环境例子 ,奖励功能设计如下:
“Reward is 1 for every step taken, including the termination step. The threshold is 475.”
“所采取的每个步骤(包括终止步骤)的奖励均为1。 阈值为475。”
Knowing that when the pole slips off the cart the simulation is ended, the agent has to learn eventually to balance the pole on the cart as much as possible, by maximizing the sum of individual rewards it gets at each step.
知道当杆子滑出购物车时,模拟结束了,代理商必须学习如何通过最大化每个步骤获得的单个奖励的总和来尽可能地平衡车子上的杆子。
In the case of the Maze environment, our goal might be to let the agent find its way from the source to destination in the least number of steps possible. To do so, we can design the reward function to give the RL agent a negative reward at each step to teach it eventually to take the least number of steps while approaching the destination.
在迷宫环境中 ,我们的目标可能是让代理以尽可能少的步骤找到从源到目的地的方式。 为此,我们可以设计奖励功能,为RL代理在每个步骤中提供负奖励,以指导其在到达目的地时最终采取最少的步骤。
The terminal state: Another crucial component is the terminal state. Although it might not seem like a major issue, failing to set the flag that signals the end of a simulation correctly can badly affect the performance of an RL agent.
终端状态 :另一个至关重要的组成部分是终端状态。 尽管这看起来似乎不是主要问题,但未能正确设置信号来指示模拟结束的标记可能会严重影响RL代理的性能。
The done flag, as referred to in many RL environment implementations, can be set whenever the simulation reaches its end or when a maximum number of steps is reached.Setting a maximum number of steps will prevent the agent from taking an infinite number of steps to maximize its rewards as much as possible.
在许多RL环境实现中都提到的完成标志 ,可以在模拟结束时或达到最大步数时进行设置。设置最大步数将阻止代理采取无限步数进行操作。尽可能最大化其奖励。
It is important to note that designing the environment is one of the hardest parts of RL. It requires lots of tough design decisions and many remakes. Unless the problem is that straightforward, you will most likely have to experiment with many environment definitions until you land on the definition that yields the best results.
重要的是要注意 ,设计环境是RL最难的部分之一 。 它需要许多艰难的设计决策和许多重制。 除非问题很简单,否则您很可能必须尝试许多环境定义,直到您获得可产生最佳结果的定义。
我的建议:尝试查找类似环境的先前实现,以获取构建您的灵感。 (My advice: Try to look up previous implementations of similar environments to get some inspiration for building yours.)
4.奖励延迟吗? (4. Are Rewards Delayed?)
Another important consideration is to check whether our goal is to maximize the immediate reward or the cumulative reward. It is crucial to have this distinction set clearly before starting the implementation since RL algorithms optimize the cumulative reward at the end of the simulation and not the immediate reward.
另一个重要的考虑因素是检查我们的目标是最大化即时奖励还是累积奖励 。 在开始实施之前,必须明确设置此区别,这是至关重要的, 因为RL算法会在模拟结束时优化累积奖励,而不是立即奖励 。
Consequently, the RL agent might opt for an action that might lead to a low immediate reward to be able to get higher rewards, later on, maximizing the cumulative reward over time. In case you are interested in maximizing the immediate reward, you might better use other techniques such as Bandits and Greedy approaches.
因此,RL代理可能会选择可能导致立即奖励较低的行动,以便能够获得更高的奖励,此后,随着时间的推移,最大化的累积奖励。 如果您希望最大程度地获得即时奖励,则最好使用其他技术,例如强盗和贪婪方法。
5.注意后果 (5. Be Aware of the Consequences)
Similar to other types of Machine Learning, Reinforcement Learning (and especially Deep Reinforcement Learning (DRL) ) is very computationally expensive. So you have to expect to run many training episodes, testing and tuning iteratively the hyperparameters.
与其他类型的机器学习类似,强化学习(尤其是深度强化学习(DRL))在计算上非常昂贵 。 因此,您必须期望运行许多训练情节,迭代地测试和调整超参数。
Moreover, some DRL algorithms (like DQN) are unstable and may require more training episodes to converge than you think. Therefore, I would suggest allocating a decent amount of time for optimizing and perfecting the implementation before letting the RL agent train enough.
此外,某些DRL算法(例如DQN)不稳定,可能需要比您想象的更多的训练集来收敛。 因此, 我建议在让RL代理进行足够的训练之前, 分配一些时间来优化和完善实现 。
结论 (Conclusion)
In this article, we laid the foundations needed to make sure whether Reinforcement Learning is a good paradigm to tackle your problem, and how to properly design the RL environment.
在本文中,我们奠定了必要的基础,以确保强化学习是否是解决您的问题的良好范例,以及如何正确设计RL环境。
In the next part: “Choose your Weapons: all the Tools you Need to Build a Working RL Environment”, I am going to discuss how to build the infrastructure needed to build an RL environment with all the tools you might need!
在下一部分: “选择武器:构建有效的RL环境所需的所有工具”中 ,我将讨论如何使用所需的 所有工具来构建构建RL环境所需的基础结构 !
Buckle up and stay tuned!
系好安全带,敬请期待!

Originally published at https://anisdismail.com on June 21, 2020.
最初于 2020年6月21日 在 https://anisdismail.com 上 发布 。
翻译自: https://medium.com/analytics-vidhya/how-to-structure-a-reinforcement-learning-project-part-1-8a88f9025a73
构建强化学习