Seq2Seq模型
文章目录
- 一、Seq2Seq模型
-
- 1、Seq2Seq的介绍
- 2、Seq2Seq模型的实现
-
- 2.1、实现流程
- 2.2、文本转化为序列、准备Dataloader
- 二、模型的搭建
-
- 1.准备编码器
- 2. 准备解码器
- 3. seq2seq模型搭建、训练和保存
- 三、整体流程
一、Seq2Seq模型
1、Seq2Seq的介绍
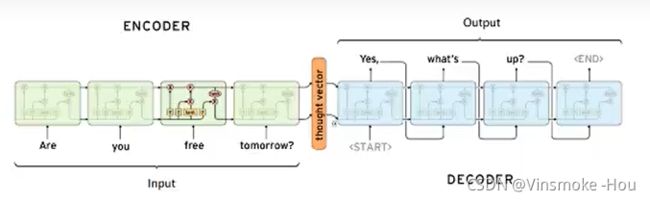
Sequence to Sequence(Seq2Seq)是由encoder(编码器)和decoder(解码器)两个RNN组成的。其中encoder负责对输入句子的理解,转化为context vector,decoder负责对理解后的句子的向量进行处理,解码,获得输出。
那么此时,就有一个问题,在encoder的过程中得到的context vector作为decoder的输入,那么这样一个输入,怎么能够得到多个输出呐?
其实就是当前一步的输出,作为下一单元的输入。然后得到结果
outputs = []
while True:
output = decoder(output)
outputs.append(output)
那么循环什么时候停止呐?
在训练数据集中,可以在输出的最后面添加一个结束符“<\END>”,如果遇到结束符,则可以终止循环。
outputs = []
while output!=""
output = decoderd(output)
outputs.append(output)
总之:Seq2Seq模型中的encoder接收一个长度为M的序列,得到一个context vector,之后decoder把这一个context vector转化为长度为N的序列作为输出,从而构成一个M to N的模型,能够处理很多不定长输入输出的问题。比如:文本翻译、问答、文章摘要、关键字写诗等等。
2、Seq2Seq模型的实现
下面,我们通过一个简单的例子,来看看普通的Seq2Seq模型应该如何实现。
需求:完成一个模型,实现往模型中输入一串数字,输出这串数字+0
例如:输入:123456789,输出:1234567890
2.1、实现流程
- 文本转化为序列,准备数据集,准备Dataloader
- 完成编码器,实现对输入的理解
- 完成解码器,实现输出
- 完成seq2seq模型
- 模型训练
- 模型评估
2.2、文本转化为序列、准备Dataloader
由于输入的是数字,为了把这些数字和词典中的真实数字进行对应,可以把这些数字理解为字符串。那么我们需要做的是:
- 把字符串对应为数字
- 把数字转化为字符串
"""
将数字进行序列化
"""
class num_sequence():
PAD_TAG = "PAD"
UNK_TAG = "UNK"
UNK = 0
PAD = 1
EOS_TAG = "EOS"
EOS = 2
def __init__(self):
self.dict = {
self.UNK_TAG:self.UNK,
self.PAD_TAG:self.PAD
}
for i in range(10):
self.dict[str(i)] = len(self.dict)
self.reverse_dict = dict(zip(self.dict.values(),self.dict.keys()))
def transform(self,sentence,max_len=None,add_eos=False):
"""把字符串转换为序列
add_eos: true 输出句子长度为max_len+1
add_eos: false 输出句子长度为max_len
"""
if len(sentence)>max_len:
sentence = sentence[:max_len]
sentence_len = len(sentence)
if add_eos:
sentence = sentence + [self.EOS_TAG]
if sentence_len<max_len:
sentence = sentence+[self.PAD]*(max_len-sentence_len)
result = [self.dict.get(i,self.UNK) for i in sentence]
return result
def reversedTransform(self,sentence):
"""把序列转换会字符串"""
return [self.reverse_dict.get(i,self.UNK_TAG) for i in sentence]
准备dataset
其中需要注意:
- 需要对batch中的数据进行排序,根据数据的真实长度进行降序排序
- 需要调用文本序列化的方法,把文本进行序列化的操作,同时target需要进行add eos操作
- 最后返回序列的LongTensor格式
- 在Dataloader中有drop_last参数,当数据量无法被batch_sie整除时,最后一个batch的数据个数和之前的数据个数长度不同,可以考虑进行删除。
class my_dataset(Dataset):
def __init__(self):
# 使用numpy创建一堆数字
self.data = np.random.randint(0,1e6,size=[500000])
def __getitem__(self, index):
input = list(str(self.data[index]))
label = input+["0"]
input_length = len(input)
label_length = len(label)
return input,label,input_length,label_length
def __len__(self):
return len(self.data)
def collate_fn(batch):
# 1.对batch进行按照长度从长到短降序排序
batch = sorted(batch,key=lambda x:x[3],reverse=True)
input,label,input_length,label_length = list(zip(*batch))
# 把input转化为序列
# 2.进行padding的操作
input = torch.LongTensor([config.sequence.transform(i,max_len=config.max_len) for i in input])
label = torch.LongTensor([config.sequence.transform(i, max_len=config.max_len+1) for i in label])
input_length = torch.LongTensor(input_length)
label_length = torch.LongTensor(label_length)
return input,label,input_length,label_length
dataloader = DataLoader(my_dataset(),shuffle=True,batch_size=config.train_batch_size,collate_fn=collate_fn)
二、模型的搭建
1.准备编码器
编码器(encoder)的目的就是为了对文本进行编码,把编码后的结果交给后续的程序使用。所以在这里我们可以使用Embedding+GRU的结构来使用,使用最后一个time step的输出(hidden state)作为句子的编码结果。
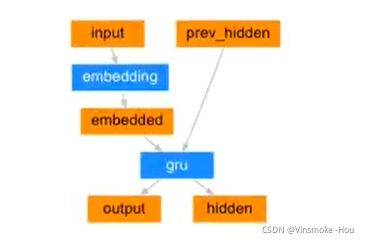
需要注意:
- Embedding和GRU的采纳数,这里我们让GRU中batch放在前面。
- 输出结果的形状。
- 在LSTM和GRU中,每个time step的输入会进行计算,得到结果,整个过程是一个和句子长度相关的一个循环,手动实现速度较慢。
- pytorch 中实现了
nn.utils.rnn.pack_padded_sequence对padding后的句子进行打包的操作能够更快获得LSTM或者GRU的结果。 - 同时实现了
nn.utils.rnn.pad_packed_sequence对打包的内容进行解包的操作。
- pytorch 中实现了
nn.utils.rnn.pack_padded_sequence使用过程中需要对batch中的内容按照句子的长度降序排序。
class Encoder(nn.Module):
def __init__(self):
super(Encoder,self).__init__()
self.embedding = nn.Embedding(
num_embeddings = len(config.sequence),
embedding_dim=config.embedding_dim,# 词的维度
padding_idx=config.num_sequence.PAD
)
self.gru = nn.GRU(
input_size=config.embedding_dim,
hidden_size=config.hidden_size,
num_layers=config.num_layers,
batch_first=True
)
def forward(self, input,length):
"""
:param input:[batch_size,seq_len]
:return:
"""
embeded = self.embedding(input) # embeded :[batch_size,seq_len,embedding_dim]
# 对文本对齐之后的句子进行打包,能够加速在LSTM或GRU中的计算过程
embeded = pack_padded_sequence(embeded,length,batch_first=True)
out,hidden = self.gru(embeded)
# 解包
result,out_length = pad_packed_sequence(out,batch_first=True,padding_value=config.num_sequence.PAD)
return result,hidden
2. 准备解码器
解码器主要负责实现对编码之后结果的处理,得到预测值,为后续计算损失做准备。此时需要思考:
- 使用什么样的损失函数,预测值需要是什么格式的?
- 结合之前的经验,我们可以理解为每次输出是一个分类问题,即每次选择一个概率最大的词输出。
- 真实值的形状是
[batch_size,max_len],从而我们知道输出的结果需要是一个[batch_size,max_len,vocab_size]的形状 - 即预测值的最后一个维度进行计算log_softmax,然后和真实值进行相乘,从而得到损失
- 如何把编码结果
[1,batch_size,hidden_size]进行操作,得到预测值。解码器也是一个RNN,即也可以使用LSTM或GRU的结构,所以在解码器中:- 通过循环,每次计算的一个time step的内容
- 编码器的结果作为初始的隐层状态,定义一个[batch_size,1]的全为sos的数据作为最开始的输入,告诉解码器,要开始工作了
- 通过解码器预测一个输出
[batch_size,hidden_size](会进行形状的调整为[batch_size,vocab_size]),把这个输出作为输入再使用解码器进行解码 - 上述是一个循环,循环的次数就是句子的最大长度,那么就可以得到max_len个输出
- 把所有输出的结果进行concate,得到
[batch_size,max_len,vocab_size]
- 在RNN的训练过程中,使用前一个预测结果作为下一个step的输入,可能会导致一步错,步步错的结果,如何提高模型的收敛速度?
- 可以考虑在训练的过程中,把真实值作为下一步的输入,这样可以避免步步错的局面
- 同时在使用真实值的过程中,仍然使用预测值作为下一步的输入,两种输入随机使用
"""
实现解码器(decoder.py)
"""
import torch.nn as nn
import torch
from seq2seq import config
import torch.nn.functional as F
class Decoder(nn.Module):
def __init__(self):
super(Decoder,self).__init__()
self.embedding = nn.Embedding(num_embeddings=len(config.sequence),
embedding_dim=config.embedding_dim,
padding_idx=config.sequence.PAD)
self.gru = nn.GRU(hidden_size=config.hidden_size,
input_size=config.embedding_dim,
batch_first=True,
num_layers=config.num_layers)
self.fc = nn.Linear(config.hidden_size,len(config.sequence))
def forward(self, target,encoder_hidden):
# 1.获取encoder的输出,作为decoder第一次的hidden_state
decoder_hidden = encoder_hidden
# 2.准备decoder第一个时间步的输入,[batch_size,1] SOS 作为输入
batch_size = target.size(0)
decoder_input = torch.LongTensor(torch.ones([batch_size,1],dtype=torch.int64)*config.sequence.SOS)
# 3.在第一个时间步上进行计算,得到第一个时间步的输出,hidden_state
# 4.把第一个时间步的输出进行计算,得到第一个最后的输出结果
# 5.把前一次的hidden_state作为当前时间步的hidden_state,把前一步的输出作为当前时间步的输入
# 6.循环4-5步
# 保存预测的结果
decoder_outputs = torch.zeros([batch_size,config.max_len+2,len(config.sequence)])
for t in range(config.max_len+2): # +2 是因为dataset中+1,add_eos加了1
decoder_output_t,decoder_hidden = self.forward_step(decoder_input,decoder_hidden)
decoder_outputs[:,t,:] = decoder_output_t
# topk取前k个值
value,index = torch.topk(decoder_output_t,1)
decoder_input = index
return decoder_outputs,decoder_hidden
def forward_step(self,decoder_input,decoder_hidden):
"""
计算每个时间步上的结果
:param decoder_input:[batch_size,1]
:param decoder_hidden:[1,batch_size,hidden_size]
:return:
"""
decoder_input_embeded = self.embedding(decoder_input)
# out:[batch_size,1,hidden_size]
# decoder_hidden:[1,batch_size,hidden_size]
out,decoder_hidden = self.gru(decoder_input_embeded,decoder_hidden)
out = out.squeeze(1) # [batch_size,hidden_size]
output = F.log_softmax(self.fc(out),dim=-1) # [batch_size,vocab_size]
return output,decoder_hidden
3. seq2seq模型搭建、训练和保存
模型的搭建
"""
把encoder和decoder进行合并,得到seq2seq模型
"""
import torch.nn as nn
from seq2seq.encoder import Encoder
from seq2seq.decoder import Decoder
class Seq2seq(nn.Module):
def __init__(self):
super(Seq2seq,self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
def forward(self,input,input_length,traget,traget_length):
encoder_outputs,encoder_hidden = self.encoder(input,input_length)
decoder_outputs,decoder_hidden = self.decoder(traget,encoder_hidden)
return decoder_outputs,decoder_hidden
模型的训练和保存
# 训练流程:
# 1. 实例化model,optimizer,loss
# 2. 遍历Dataloader
# 3. 调用模型得到output
# 4. 计算损失
# 5. 模型保存和加载
from seq2seq.dataset import dataloader
from seq2seq.seq2seq_model import Seq2seq
from torch.optim import Adam
import torch.nn.functional as F
import torch
from seq2seq import config
seq2seq = Seq2seq()
optimizer = Adam(seq2seq.parameters(),lr = 0.001)
def train(epoch):
for index,(input,label,input_length,label_length) in enumerate(dataloader):
optimizer.zero_grad()
decoder_outputs,_ = seq2seq(input,input_length,label,label_length)
# 将decoder_outputs变为2维,label真实值变成1维
decoder_outputs = decoder_outputs.view(decoder_outputs.size(0)*decoder_outputs.size(1),-1)# [batch_size*seq_len,-1]
label = label.view(-1)# [batch_size*seq_len]
print(decoder_outputs.size())
print(label.size())
loss = F.nll_loss(decoder_outputs,label)
loss.backward()
optimizer.step()
print(epoch,index,loss)
if index%100 == 0:
torch.save(seq2seq.state_dict(),config.model_path)
torch.save(optimizer.state_dict(),config.model_path)
if __name__ == '__main__':
for i in range(10):
train(i)
模型的评估
在decoder.py中需要创建evaluate方法
def evaluate(self,encoder_hidden):
"""模型评估"""
decoder_hidden = encoder_hidden # [1,batch_size,hidden_size]
batch_size = decoder_hidden.size(1)
decoder_input = torch.LongTensor(torch.ones([batch_size,1],dtype=torch.int64)*config.sequence.SOS)
indices = []
# while True:
for i in range(config.max_len):
decoder_output_t,decoder_hidden = self.forward_step(decoder_input,decoder_hidden)
value,index = torch.topk(decoder_output_t,1)# 获取概率最大的词语 # [batch_size,1]
decoder_input = index
# if index.item() == config.sequence.EOS:
# break
indices.append(index.squeeze(-1).cpu().detach().numpy())
return indices
然后再进行评估,创建eval.py
"""
模型的评估
"""
from seq2seq import config
from seq2seq import seq2seq_model
import numpy as np
import torch
# 训练流程
# 1. 准备训练数据
data = [str(i) for i in np.random.randint(0,1e8,size=[100])] # input
data = sorted(data,key=lambda x:len(x),reverse=True)
input_length = torch.LongTensor([len(i) for i in data])
input = torch.LongTensor([config.sequence.transform(i,config.max_len) for i in data])
# 2. 实例化模型,加载model
seq2seq = seq2seq_model()
model = seq2seq.load_state_dict(config.model_path)
# 3. 获取预测值
indices = seq2seq.evaluate(input,input_length)
indices = np.array(indices).transpose()
# 4. 反序列化,观察结果
result = []
for line in indices:
temp_result = config.sequence.reversedTransform(line)
cur_line = ""
for word in temp_result:
if word == config.sequence.EOS_TAG:
break
cur_line+=word
result.append(cur_line)
print(data[:10])
print(result[:10])
三、整体流程
- encoder
- 对input进行embedding
- 对embedding的结果进行打包
- 传入GRU计算,得到output和hidden
- output进行解包
- decoder
- 构造一个起始符号,size:[batch_size,1],第一个时间步的输入
- 第一个时间步的输入进行embedding
- gru得到output和hidden,hidden作为下一个时间步的hidden
- 计算第一个时间步输出的值:第一个时间步的输出进行变形,最后一个维度为vocab_size,之后计算log_softmax,得到output,获取值最大的位置,它就是第一个时间步输出的具体值
- output进行保存,是第一个时间步的输出
- 第二个时间步的输入有:hidden和第一个时间步的输出的具体值
- 重复b-f步骤:重复max_len
- 得到outputs
- train
- output和target计算nll_loss(需要进行变形)
- eval
- 和decoder大致相同,但是不需要保存output,只需要batch数据在每个时间步的输出
- 每个时间步的输出放在列表中,其每一列才是出入的最终结果
一些问题:
在RNN的训练过程中,使用前一个预测的结果作为下一个step的输入,可能会导致一步错,步步错的结果,那么如何提高模型的收敛速度?
- 可以考虑在训练的过程中,把真实值作为下一步的输入,这样可以避免步步错的局面。
- 同时在使用真实值的过程中,仍然使用预测值作为下一步的输入,两种输入随机使用。
- 上述这种机制被称为Teacher forcing,就像是一个指导老师,在每一步都会对我们的行为进行纠偏。
Teacher forcing主要过程就是在seq2seq中,把真实值和预测值交替作为某一个时间步的输入,避免一步错步步错的情况。
if random.random()>config.teacher_forcing_ratio: # 使用teacher forcing机制,加速收敛
decoder_input = target[t]
else:
# topk取前k个值
value,index = torch.topk(decoder_output_t,1)
decoder_input = index
本文参照代码:https://github.com/SpringMagnolia/PytorchTutorial/tree/master/seq2seq