「深度学习一遍过」必修17:基于Pytorch细粒度分类实战
本专栏用于记录关于深度学习的笔记,不光方便自己复习与查阅,同时也希望能给您解决一些关于深度学习的相关问题,并提供一些微不足道的人工神经网络模型设计思路。
专栏地址:「深度学习一遍过」必修篇
目录
1 实战内容简介
2 数据集读取
2.1 dataset
2.2 dataloader
3 模型搭建
3.1 基准模型
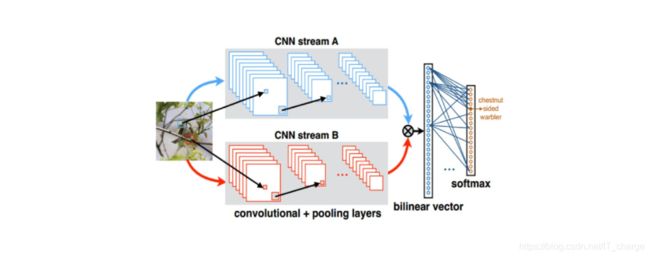
3.2 与基准模型相对应的双线性模型
4 性能差异比较
4.1 tensorboard查看测试集准确率差异
4.2 耗时比较(单位:秒)
1 实战内容简介
数据集:CUB-200,共200类不同种类的鸟。
- 第
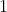 步:计算每一个通道对应的特征,
步:计算每一个通道对应的特征,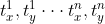 ,
,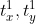 表示第
表示第 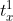 行
行 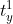 列激活值最大,
列激活值最大, 表示图像个数。
表示图像个数。 - 第
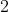 步:聚类初始化,使用
步:聚类初始化,使用 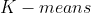 等聚类方法对特征进行聚类,得到
等聚类方法对特征进行聚类,得到  个部件
个部件 - 第
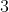 步:得到初始的 个部件,为每一个部件引入全连接层,预测
步:得到初始的 个部件,为每一个部件引入全连接层,预测  维向量,对应每一个通道有多大概率属于该部件,初始标签为第 步聚类结果
维向量,对应每一个通道有多大概率属于该部件,初始标签为第 步聚类结果 - 第
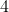 步:得到 个 维向量,对特征图进行加权求和,得到 个部件的注意力
步:得到 个 维向量,对特征图进行加权求和,得到 个部件的注意力 - 第
 步:将虚拟部件对应区域特征进行池化得到特征向量,进行分类
步:将虚拟部件对应区域特征进行池化得到特征向量,进行分类
2 数据集读取
2.1 dataset
import os
import random
# 定义一个列表,用于txt文件内存放路径及标签数据
data_list = []
# 初始化类别标签
class_label = -1
# 加载dataset图片数据
dataset_path = './data/CUB_200_2011/images/'
# 遍历文件,依次将文件名存入上述定义列表当中
for root,_,filenames in os.walk(dataset_path):
for i in filenames:
data = root+"/"+i+"\t"+str(class_label)+"\n"
print(data)
data_list.append(data) # 依次添加,不清空
class_label += 1
# 打乱txt文件中的数据,保证下面分类进行测试集与训练集每个标签都有涉及
random.shuffle(data_list)
# 定义训练文本数据列表
train_list = []
# 将打乱后的总数据列表中的80%的数据用于训练集
for i in range(int(len(data_list) * 0.8)):
train_list.append(data_list[i])
# 创建并以“写”方式打开train.txt
with open('train.txt', 'w', encoding='UTF-8') as f:
for train_img in train_list:
f.write(str(train_img)) # 将训练数据集数据写入train.txt
# 定义测试文本数据列表
eval_list = []
# 将打乱后的总数据列表中的20%的数据用于训练集
for i in range(int(len(data_list) * 0.8),len(data_list)):
eval_list.append(data_list[i])
# 创建并以“写”方式打开eval.txt
with open('eval.txt', 'w', encoding='UTF-8') as f:
for eval_img in eval_list:
f.write(eval_img) # 将测试数据集数据写入eval.txt
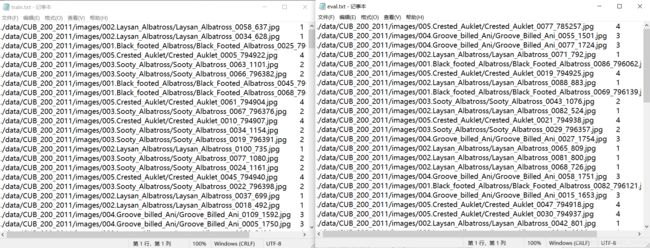
2.2 dataloader
import torch
from PIL import Image
import torchvision.transforms as transforms
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
from torch.utils.data import Dataset
# 定义一个dataloader用于等会调用
class Data_Loader(Dataset):
def __init__(self, txt_path, train_flag=True):
self.imgs_info = self.get_images(txt_path)
self.train_flag = train_flag
self.targetsize = 224 # 把图片压缩成224X224
# 训练集的处理方法
self.train_tf = transforms.Compose([
transforms.Resize(self.targetsize), # 压缩图片
transforms.RandomHorizontalFlip(), # 随机水平反转
transforms.RandomVerticalFlip(), # 随机垂直反转图片
transforms.ToTensor(), # 把图片转变为Tensor()格式,pytorch才能读写
])
# 验证集(测试集)的处理方法
self.val_tf = transforms.Compose([
transforms.Resize(self.targetsize),
transforms.ToTensor(),
])
# 通过读取txt文档内容,返回文档中的每一条信息
def get_images(self, txt_path):
with open(txt_path, 'r', encoding='utf-8') as f:
imgs_info = f.readlines()
imgs_info = list(map(lambda x:x.strip().split('\t'), imgs_info))
return imgs_info
def padding_black(self, img):
w, h = img.size
scale = 224. / max(w, h)
img_fg = img.resize([int(x) for x in [w * scale, h * scale]])
size_fg = img_fg.size
size_bg = 224
img_bg = Image.new("RGB", (size_bg, size_bg))
img_bg.paste(img_fg, ((size_bg - size_fg[0]) // 2,
(size_bg - size_fg[1]) // 2))
img = img_bg
return img
# 我们在遍历数据集中返回的每一条数据
def __getitem__(self, index):
img_path, label = self.imgs_info[index] # 读取每一条数据,得到图片路径和标签值
img = Image.open(img_path) # 利用 Pillow打开图片
img = img.convert('RGB') # 将图片转变为RGB格式
img = self.padding_black(img)
if self.train_flag: # 对训练集和测试集分别处理
img = self.train_tf(img)
else:
img = self.val_tf(img)
label = int(label)
return img, label # 返回图片和其标签值
# 我们在遍历数据集时,遍历多少,返回的是数据集的长度
def __len__(self):
return len(self.imgs_info)
if __name__ == "__main__":
train_dataset = Data_Loader("eval.txt", True)
print("数据个数:", len(train_dataset))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=10,
shuffle=True)
test_dataset = Data_Loader("eval.txt", False)
print("数据个数:", len(test_dataset))
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=50,
shuffle=True)
for image, label in test_loader:
print(image.shape)
print(label)
3 模型搭建
3.1 基准模型
import torch.optim as optim
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from dataloader import Data_Loader
from torchvision.models import resnet50
from tensorboardX import SummaryWriter
import time
# 创建一个基准模型类
class Baisc_Net(nn.Module):
def __init__(self):
super(Baisc_Net, self).__init__()
self.features = nn.Sequential(resnet50().conv1,
resnet50().bn1,
resnet50().relu,
resnet50().maxpool,
resnet50().layer1,
resnet50().layer2,
resnet50().layer3,
resnet50().layer4)
self.classifiers = nn.Linear(100352, 5)
def forward(self, x):
x = self.features(x)
x = x.view(-1, 100352)
x = self.classifiers(x)
return x
# 定义一个函数,在训练集上进行,打印输出loss值与acc值,并写入tensorboard中
def baisic_net_train(train_loader, model, criterion, optimizer, epoch):
model.train()
# 初始化正确率
running_corrects = 0.0
for i, (input, target) in enumerate(train_loader):
input = input.cuda()
target = target.cuda()
output = model(input) # 将输入输入到模型中,产生一个输出
loss = criterion(output, target) # 计算实际输出与目标输出之间的差距,将值传入loss变量中
_, preds = torch.max(output.data, 1) # 按行输出该维度预测概率最大的那一个标签
running_corrects += torch.sum(preds == target).item() # 计算该轮次中预测正确的标签数总和
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 迭代更新
if i % 20 == 0:
print("Training loss = ", loss.item()) # 每轮中的20次输出一次loss
epoch_acc = running_corrects / dataset_sizes
print("Training Accuracy = ", epoch_acc) # 输出每轮的准确率
writer.add_scalar('contrast figure basic net', epoch_acc, global_step=epoch) # 将准确率写入到tensorboard中
if __name__ == "__main__":
train_dir_list = 'train.txt'
valid_dir_list = 'eval.txt'
batch_size = 1 # 看显存
epochs = 50 # 总共训练多少回合
# 加载数据集
# 自创了一个data_loader,调用时需要从dataloader.py中进行读取
# train_data是我们的训练集
train_data = Data_Loader(train_dir_list, train_flag=True)
valid_data = Data_Loader(valid_dir_list, train_flag=False)
dataset_sizes = len(train_data) # 查看训练数据集数量
print(dataset_sizes)
# 用dataloader加载dataset
# 数据集的读写方式,num_workers控制多线程读写数据集,pin_memory是内存上锁,batch_size是多少个数据并行读取,shuffle是每次读写重新打乱数据集
train_loader = DataLoader(dataset=train_data, num_workers=0, pin_memory=True, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, num_workers=0, pin_memory=True, batch_size=batch_size)
# 定义网络
model = Baisc_Net()
print(model)
model = model.cuda()
# 使用交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 利用SGD优化算法
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 将tensorboard文件写入runs文件夹中
writer = SummaryWriter('./runs')
# 定义一个开始时间,用于查看整个模型训练耗时
start_time = time.time()
# 开始训练
for epoch in range(epochs):
print("********************* Epoch ", epoch, " ************************")
baisic_net_train(train_loader, model, criterion, optimizer, epoch) # 调用前面定义的训练方法
epoch = epoch + 1
# 定义一个结束时间
end_time = time.time()
# 用开始时间-结束时间=总耗时
time = end_time - start_time
print(time)
# 关闭tensorboard写入
writer.close()3.2 与基准模型相对应的双线性模型
import torch.optim as optim
import torch
import time
import torch.nn as nn
from torch.utils.data import DataLoader
from dataloader import Data_Loader
from torchvision.models import resnet50
from tensorboardX import SummaryWriter
# 定义一个双线性模型类
class Bilinear_form_Net(nn.Module):
def __init__(self):
super(Bilinear_form_Net, self).__init__()
self.features = nn.Sequential(resnet50().conv1,
resnet50().bn1,
resnet50().relu,
resnet50().maxpool,
resnet50().layer1,
resnet50().layer2,
resnet50().layer3,
resnet50().layer4)
self.classifiers = nn.Linear(2048 ** 2, 5)
def forward(self, x):
x = self.features(x)
batch_size = x.size(0)
x = x.view(batch_size, 2048, x.size(2) ** 2)
x = (torch.bmm(x, torch.transpose(x, 1, 2)) / 28 ** 2).view(batch_size, -1)
x = self.classifiers(x)
return x
# 定义一个双线性模型测试集训练方法
def bilinear_form_net_train(train_loader, model, criterion, optimizer, epoch):#, writer):
model.train()
running_corrects = 0.0
for i, (input, target) in enumerate(train_loader):
input = input.cuda()
target = target.cuda()
output = model(input)
loss = criterion(output, target)
_, preds = torch.max(output.data, 1)
running_corrects += torch.sum(preds == target).item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 20 == 0:
print("Training loss = ", loss.item())
epoch_acc = running_corrects / dataset_sizes
print("Training Accuracy = ", epoch_acc)
writer.add_scalar('contrast figure bilinear form net', epoch_acc, global_step=epoch)
if __name__ == "__main__":
train_dir_list = 'train.txt'
valid_dir_list = 'eval.txt'
batch_size = 1
epochs = 50
# 加载数据
train_data = Data_Loader(train_dir_list, train_flag=True)
valid_data = Data_Loader(valid_dir_list, train_flag=False)
dataset_sizes = len(train_data)
print(dataset_sizes)
# 用dataloader读取dataset
train_loader = DataLoader(dataset=train_data, num_workers=0, pin_memory=True, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, num_workers=0, pin_memory=True, batch_size=batch_size)
# 实例化双线性模型
model = Bilinear_form_Net()
print(model)
model = model.cuda()
# 损失函数采用交叉熵损失
criterion = nn.CrossEntropyLoss()
# 优化器采用SGD优化器
optimizer = optim.SGD(model.parameters(), lr=0.01)
# tensorboard文件写入runs文件夹下的文件中
writer = SummaryWriter('./runs')
start_time = time.time()
# 开始训练,迭代epoch次
for epoch in range(epochs):
print("********************* Epoch ", epoch, " ************************")
bilinear_form_net_train(train_loader, model, criterion, optimizer, epoch) # 调用训练方法
epoch = epoch + 1
end_time = time.time()
time = end_time - start_time # 总耗时
print(time)
# 关闭tensorboard写入
writer.close()4 性能差异比较
4.1 tensorboard查看测试集准确率差异
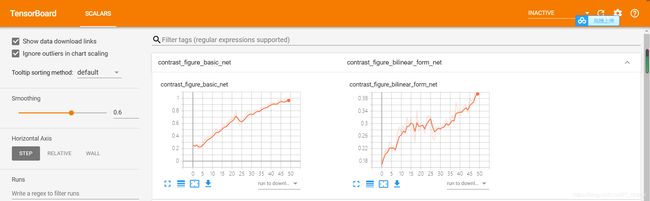
4.2 耗时比较(单位:秒)
基准模型
![]()
双线性模型
![]()