[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning
本文的研究目标是车在网络中的频谱资源分配问题,具体来讲是如何实现多个V2V链路重用V2I链路的频谱。车载链路中环境的快速变化使传统的在基站处收集CSI信息以进行集中式资源管理成为难题,而本方法将资源共享建模为多主体强化学习问题,并使用适合于分布式实现的基于指纹的深度Q网络实现。V2V链路通过与环境交互更新Q网络进而改善频谱和功率分配。经过验证此方法可以以分布式的方式同时提高V2I链路容量和V2V链路的传输速率。
概况
本文致力于研究车联网(由V2I和V2V连接组成)的频谱接入设计。采用3GPP定义的基于蜂窝的V2X架构的Mode 4(车辆从资源池中自动选择通信资源)。通过V2V链路与V2I链路共享频谱(此时要注意干扰控制)提高频谱效率;通过改进V2V频谱和功率分配方案满足服务需求并最大化V2I容量和V2V可靠性,进而实现高带宽内容的传输和安全消息共享;为实现适应消息生成周期内小规模衰落的自带选择和功率控制,提出了改进V2V链路周期性安全消息可靠性的方法。
研究背景
传统的V2X资源分配方法存在一些问题,首先,快速变化的信道会导致资源分配带来很大的不确定性,其次,新的V2X应用的服务要求更加苛刻。这两点让建模变得困难,而RL可以在不确定的条件下解决此问题,并且其可以让分布式算法成为可能[12]。目前已有一些解决信道状况时变性强的方案,[13]通过一种启发式的空频重用方案减轻了对CSI的需求,[14]通过最大化V2I链路的吞吐让V2X资源分配可以适应缓慢变化的大尺度信道衰落,进而减小了信令开销。[15]中允许V2V链路之间进行频谱共享。[16]中通过一种结合QoS和邻近度的资源共享方案减少V2V链路的发送功率,并使用基于Lyapunov的随机优化框架实现时延和可靠性需求。[17]结合大尺度衰落信息可提高V2I链路的遍历容量,[18]结合CSI的周期性反馈也可达成统一目的。
RL方法在[20][21][22]中也被用于解决V2X网络中的资源分配问题。[22]中,用RL解决车辆云的资源供应问题,以最小的开销满足云中各种实体的资源分配和服务质量需求。[23]使用软件定义的车辆网络,以最小化传输时延的无线资源管理问题。[24]使用基于DL的RL方法,可高效解决联合优化问题。[25]使用RL对用电池RSU优化了下行链路调度,以最大程度提高放电期间的服务数。[26]使用D2C学习具有高为连续输入的调度策略。[27]开发了一种分布式用户关联方法,用于异构BS的车载网络。[28]考虑了异构车联网中的切换控制方法。
本文特点在于:致力于改进V2V交付率(如指定时间内传输指定大小的数据包的成功率);提出一种多代理的RL方法,此方法鼓励V2V通过合作来提高系统整体性能。
系统模型
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第1张图片](http://img.e-com-net.com/image/info8/f44bf00fec534e7e885f90333f5f8259.jpg) D2D车辆通信网络
D2D车辆通信网络
如上图,存在M个V2I链路和K个V2V链路。V2I使用Uu连接车辆和BS以提供高数据率的服务,V2V通过PC5以周期性发送安全信息。
将V2I链路的集合记作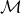 ={1, ..., M},V2V链路的集合记作
={1, ..., M},V2V链路的集合记作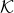 = {1, ..., K}。假设以固定的功率将M个V2I链路预先分配了正交频谱子带,即m号V2I占据了m号子带,所以我们的目标是为V2V链路设计有效的频谱分配方案,以最小的信令开销实现性能要求。
= {1, ..., K}。假设以固定的功率将M个V2I链路预先分配了正交频谱子带,即m号V2I占据了m号子带,所以我们的目标是为V2V链路设计有效的频谱分配方案,以最小的信令开销实现性能要求。
OFDM可将频选信道转化成在不同子载波上的平坦信道。几个连续的子载波分到一个频谱子带中,并假定一个子带内的衰落近似,不同子带间则独立。在一个相干时间内,通过m号子带传输的k号V2V链路的信道功率增益为,其中h表征与频率相关的小尺度衰落,alpha表征与频率无关的大尺度衰落。
类似的,方括号中为信道编号,角标代表发送/接收端。符号整理如下
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第2张图片](http://img.e-com-net.com/image/info8/2d1a9c5ef2f146bea3c777550dbfc81f.jpg) m号V2I信道、k号V2V信道、k号V2V对基站的干扰、m号V2I对k号V2V的干扰、k'号V2V对k号V2V的干扰 的增益
m号V2I信道、k号V2V信道、k号V2V对基站的干扰、m号V2I对k号V2V的干扰、k'号V2V对k号V2V的干扰 的增益
m号V2I在BS的SINR为:
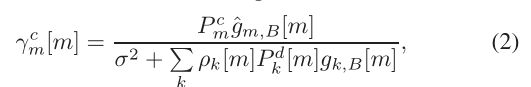
经由m号子带传输的k号V2V在接收端的SINR为:

其中P为发射功率, 是噪声功率。
是噪声功率。![I_{k}[m]=P_{m}^{c} \hat{g}_{m, k}[m]+\sum_{k^{\prime} \neq k} \rho_{k^{\prime}}[m] P_{k^{\prime}}^{d}[m] g_{k^{\prime}, k}[m]](http://img.e-com-net.com/image/info8/c4a9d47008574e3ebbfdcf4385db4e46.gif) (4),其中
(4),其中 为bool,表示k号V2V链路是否在m号RB上传输。m号V2I链路在m号子带上的容量为
为bool,表示k号V2V链路是否在m号RB上传输。m号V2I链路在m号子带上的容量为![C_{m}^{c}[m]=W \log \left(1+\gamma_{m}^{c}[m]\right)](http://img.e-com-net.com/image/info8/7d10ce63adfb431f978babed582f4d35.gif) ,k号V2V链路在m号子带上的容量为
,k号V2V链路在m号子带上的容量为![C_{k}^{d}[m]=W \log \left(1+\gamma_{k}^{d}[m]\right)](http://img.e-com-net.com/image/info8/1dc66d940bd34a77b8564c970896b306.gif) ,其中W为子带频谱的带宽。
,其中W为子带频谱的带宽。
因为V2I链路主要用于高数据率的娱乐服务,因此其设计目标是最大化总容量![]() ,V2V链路主要用于周期性的安全信息传输,将其速率建模为在时间T内大小为B的包的传输速率
,V2V链路主要用于周期性的安全信息传输,将其速率建模为在时间T内大小为B的包的传输速率![\operatorname{Pr}\left\{\sum_{t=1}^{T} \sum_{m=1}^{M} \rho_{k}[m] C_{k}^{d}[m, t] \geq B / \Delta_{T}\right\}, \quad k \in \mathcal{K} \label{(7)}](http://img.e-com-net.com/image/info8/aa54a61cc9e4499a9ef272f482362254.gif) (7)。其中B表示V2V生成的周期性的消息的大小,
(7)。其中B表示V2V生成的周期性的消息的大小, 为信道相干时间,C中的t说明k号V2V链路在不同时隙是不同的。
为信道相干时间,C中的t说明k号V2V链路在不同时隙是不同的。
本算法的目标为:通过设计V2V的频谱分配(以布尔量 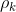 表示)和传输功率(以
表示)和传输功率(以![]() 表示),最大化V2I链路纵容量和V2V的传输速率(7)。
表示),最大化V2I链路纵容量和V2V的传输速率(7)。
高移动性使中央控制器处无法收集完整的CSI,因此应使用分布式V2V资源分配。如何协调他们使总体性能最佳是个问题。
资源分配的多代理强化学习
将每个V2V链路视作agent,多个agent同时与环境交互,并更新频谱分配和功率控制策略。为防止其相互竞争,对所有agent使用一个的奖励从而使其为网络整体性能而演进。
学习采用集中式,学习时每个agent的奖励为系统级的,并通过DQN调整策略;实施采用分布式,实施时每个agent只得到局部的环境信息,然后根据经过训练的DQN在时间尺度上选择与小尺度衰落同步的的动作。
状态和观察空间
问题可建模成一个MDP,如图2所示。在每个时点t给一个环境值S,每个agent得到一个环境观测值Z(由观测函数O决定)并选择一个行动![]() ,多个agent的行动共同组成
,多个agent的行动共同组成![]() 。之后,agent将得到奖励R,并且环境S发生变化(以概率p)。此时每个agent将得到新的观测值Z。
。之后,agent将得到奖励R,并且环境S发生变化(以概率p)。此时每个agent将得到新的观测值Z。
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第3张图片](http://img.e-com-net.com/image/info8/ee43ac0da3e44a1e83bcfd45c6710c80.jpg)
环境值S内含所有的信道状态和agent的动作,这对每个agent是隐藏的,agent只能通过观测函数了解环境。观测空间包含:当前agent的信道信息![]() ,除V2V到BS的干扰增益以外的所有信道增益信息都可在V2V的接收端均可得到;V2V到BS的干扰增益将在BS得到并广播到所有其覆盖范围内的车。m号子带上的接收干扰
,除V2V到BS的干扰增益以外的所有信道增益信息都可在V2V的接收端均可得到;V2V到BS的干扰增益将在BS得到并广播到所有其覆盖范围内的车。m号子带上的接收干扰![]() 由V2V接收器测量并加入其观测空间。此外,局部观测空间还包括剩余的V2V负载
由V2V接收器测量并加入其观测空间。此外,局部观测空间还包括剩余的V2V负载 ,剩余时延
,剩余时延 。局部观测空间表示为:
。局部观测空间表示为:
![]()
其中![]() 。
。
IQL(Indepent Q-learning)可用于解决多agent的RL问题但是很难收敛,将DQN与IQL结合后,情况会变得更糟。为解决这个问题,我们使用基于指纹的方法。其思想为,尽管单个agent的行动价值函数在其他agent经常变动状态时很不稳定,但可以估计其他agent的行为准则进而扩张每个agent的观察空间,这也是超Q学习的基本思想。但是,这里也不希望动作-打分函数包含其他其他agent的参数做输入,因为每个agent都包括一个高维的DQN。作为代替,将一个低维的指纹特征(这个特征可以跟组其他代理商的策略变化)加入该函数,此方法有效是因为动作-打分函数的不稳定是来自于其他agent的策略的变化而非策略本身。进一步的分析表明,每个agent的策略改变都与训练迭代次数和探索率(比如随机动作选择的概率)高度相关.因此,我们将他们包含到agent的观测空间中
动作空间
这里的动作其实就是V2V链路的频谱子带选择和功率控制,此处为便于学习和控制,将功率控制设置为四个级别(即离散量)[23,10,5,-100]dBm(这里-100意味着V2V传输功率为0)。因此动作空间尺寸为4*M,每个动作对应频谱的子带和功率的一种特定组合。
奖励设计
奖励函数的灵活设计是解决优化难题的杀手锏。我们在这里的目标如上所述有两个:在一定时间内,最大化V2I容量并增加V2V传输的可靠性。
首先看第一个目标,V2I链路的总容量的瞬时值为![]() ;为实现第二个目标,可通过V2V剩余负载Bk是否大于0判断信息是否成功交付。由此得到V2V链路在每个时间步t的奖励为
;为实现第二个目标,可通过V2V剩余负载Bk是否大于0判断信息是否成功交付。由此得到V2V链路在每个时间步t的奖励为
![]() (10)
(10)
其中的 表示成功交付后所获得的奖励,而上面的式子是没成功交付的情况,这时的奖励是V2V的传输速率。为了给成功交付更大的奖励应设置大于最大的V2V传输速率。
表示成功交付后所获得的奖励,而上面的式子是没成功交付的情况,这时的奖励是V2V的传输速率。为了给成功交付更大的奖励应设置大于最大的V2V传输速率。
学习的目标是找到一个优化准则![]() (即由状态到动作的映射),最大程度提高回报期望
(即由状态到动作的映射),最大程度提高回报期望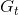 ,他是单步奖励的加权和,权重为
,他是单步奖励的加权和,权重为 (称为折现率,0~1)得到:【此式也可称为 状态-价值函数】
(称为折现率,0~1)得到:【此式也可称为 状态-价值函数】
 (11)
(11)
对于这里的,如果其近1的话,那么表示直到传输完成的所有奖励和当前奖励一视同仁,此时最大化累计奖励的期望将会导致V2V链路传递更多数据。
此外,提高(10)中的也可提高奖励。但(10)的\beta是一个超参数,其代表了设计目标时对奖励和学习效率之间的权衡。如果只是想最大化奖励,那么可以设置\beta为0,但是这将给学习造成麻烦,因为此时agent无法在训练的开头获得任何有用的知识。这里我们可以在奖励中引入一些先验知识,比如V2V传输速率。奖励函数如下所示:
![]()
其中的 是V2I和V2V指标成分的权重。
是V2I和V2V指标成分的权重。
学习算法
情景设置如下:每个情景都经历V2V的传递时间约束T,每个情景由一个随机初始化的环境状态(由所有车辆链路的初始传输功率、信道状态决定)、一个完整的V2V负载组成,并持续到T结束。小尺度衰落的变化将导致环境状态的转变并引发学习的过程。
训练过程
使用带有经验重播的DQL进行学习。动作-价值函数为:在状态s根据策略 采取动作a的过程:
采取动作a的过程:
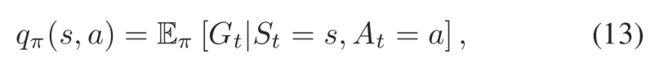
其中(状态-价值函数)在(11)中有定义。最优策略将决定动作价值函数。[6]中证明了,在学习率的随机近似条件不同且所有状态动作函数都持续更新时,Q学习中学到的动作-价值函数以概率1收敛到最佳动作价值函数。在DQL中,动作价值函数通过DNN确定,称作DQN。
每个V2V agent有一个DQN,其将当前观测值Z做输入并输出所有动作的价值函数。训练过程中,每个V2V通过soft策略(如 贪婪算法,此算法以概率选择可使价值最大化的动作)探索状态-动作空间。根据环境的改变,每个agent收集转换对并将其存储在重播内存中。在每个情节中,都会从内存中均匀采样一小批体验并以随机梯度下降的方法更新
贪婪算法,此算法以概率选择可使价值最大化的动作)探索状态-动作空间。根据环境的改变,每个agent收集转换对并将其存储在重播内存中。在每个情节中,都会从内存中均匀采样一小批体验并以随机梯度下降的方法更新 ,以最小化平方和误差。
,以最小化平方和误差。

其中 是目标Q网络的参数,他周期性的从Q网络的参数集\theta中复制过来并更新两次。经验重放将通过对存储的体验惊醒重复采样来提高采样效率,并在连续更新中打破相关性,从而稳定学习。训练过程如算法1所示
是目标Q网络的参数,他周期性的从Q网络的参数集\theta中复制过来并更新两次。经验重放将通过对存储的体验惊醒重复采样来提高采样效率,并在连续更新中打破相关性,从而稳定学习。训练过程如算法1所示
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第4张图片](http://img.e-com-net.com/image/info8/def179618fc649e48ab76ca10e7cd698.jpg)
分布式实施
在每个时间步t,每个agent将估计其信道状态并构造局部观察Z,并且以最大化回报为目的选择执行动作A,此后,所有V2V链路以该动作中的功率和频谱分配进行传输。
要注意,算法1中的训练可以适用于许多场景中,也就是可以进行离线执行。仅当环境特征发生重大变化时(可以设置一月/周一次),才需要对受训的DQN进行更新。
仿真结果
本节根据3GPP TR36.885中定义的城市案例的参数定制了模型,该模型描述了车辆散步、密度、速度、移动方向等。M个V2I链路由M量车发起,并且每辆车于其附近的车形成K个V2V链路。表1中列出了仿真参数,表2中列出了V2V和V2I链路的参数。
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第5张图片](http://img.e-com-net.com/image/info8/c4f578dd93784a1ba4655218b5ec20a1.jpg)
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第6张图片](http://img.e-com-net.com/image/info8/06231e5cde9b468fba5d7ef81f7911f9.jpg)
每个agent的DQN包含三个全连接的隐藏层,分别有500 250 120个神经元。使用ReLU做激活函数,RMSProp做优化器,学习率为0.001。对每个agent的Q网络迭代3000次,探索率在开始的2400次迭代中使用线性退火从1到0.02,之后保持恒定。在这个过程中我们修复了迭代中的大尺度衰落从而使算法更稳定。训练阶段的V2V有效负载为2*1060字节,但在测试阶段对其进行改变以验证算法的鲁棒性。
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第7张图片](http://img.e-com-net.com/image/info8/c5c8fabe4f4a4632ac1cba7b87aa409d.jpg)
如图3和图4所示,比较了MARL(多代理RL算法)、SARL(单代理RL算法,此算法一次只更新一个agent的行动)、随机基线(每次V2V链路随机选择频谱子带和传输功率)还有两个理论的性能上限进行了比较,这两个上限分别为:1.禁用所有V2V链路;2.忽略V2I链路的需求,此假设将时间约束T内通过多步传输B字节转化成对V2V速率的分步优化。此时我们在所有agent的动作空间搜索最大化V2V速率的动作。此方法需要以集中式实施并提供全局CSI,因此命名为maxV2V。后面两种方法是为了显示所提出的方法可以一多大程度靠近理论性能极限。
图三可见,V2I的容量随V2V负载变化的情况,V2I容量随V2V负载增大而下降,这是因为V2V载荷增多会导致V2V的传输时间更长、发射功率更大,由此将导致对V2I链路的干扰更强,进而影响其容量。即便如此,MARL方案仍然比其他两个baseline具有更好的性能,虽然他使用2*1060进行训练但当N增加时也便显出很好的鲁棒性。与性能上限相比,在6*1060时效果最糟。Centralized maxV2V的曲线很有趣,虽然他忽略V2I的需求,但是在此情况下V2I的容量性能还不错,这可能是因为集中式大大提高了V2V链路的数据传输速率,而一旦V2V传输完成,则其不会对V2I链路产生干扰。这个方案提醒我们可以进一步研究V2I和V2V链路之间的性能折中。
图4可见,V2V传输成功率和传输负载的关系。传输成功率会随着负载增大而下降单max V2V始终为1。MARL比max V2V稍微差点但是比其他两个还是好得多。特别是在负载N为1和2时,成功率为100%;N为3和4时,性能也接近完美。为什么MARL在N > 4时性能会下降呢?结合图3的观察结果猜测为随着负载的增大,DQN的学习效果不再适用,可能需要改变训练集的N进行重新训练。
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第8张图片](http://img.e-com-net.com/image/info8/00f977b4d06c4b7e9dccffd49322aa0c.jpg)
图5呈现了随着迭代进行累计奖励的变化情况,从这个图可以看出本算法的收敛性。首先可以看到随着训练进行,累计奖励数值不断增加,当训练到2000时,数值开始收敛(尽管因为信道衰落仍存在一些波动)。因此我们评估图1 2的性能是,将迭代次数设置成了3000。
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第9张图片](http://img.e-com-net.com/image/info8/0d075f1b11374595b9f20fadc844cb2f.jpg)
![[论文笔记]Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning_第10张图片](http://img.e-com-net.com/image/info8/1e18918f9e594fe9ba51ca1fbd9b8827.jpg)
为探究为什么此算法可以达成很好的性能,我们选择了使所有V2V链路都能成功交付2120字节的载荷的迭代结果,而随机baseline允许失败。在图6中绘制了所有V2V链路在施加约束内剩余V2V载荷的变化,在多代理强化学习(a图)中,链路四很快的完成了传输而其他三个链路大致同时完成传输。在随机baseline(b图)中,链路1和4很早就完成了交付,但是链路3和4的传输情况就很不理想。
图7显示了在时间约束内V2V链路瞬时速率的变化,在多代理RL(a图)中,链路4以很快的速率完成了传输,而链路1首先低速以确保其他链路的高速率,而观察链路2 3可见,他们貌似在进行轮流传输,以便载荷可以快速传递。而随机baseline(b图)不能为易被干扰的链路提供保护,所以其传输失败的可能性很高。