论文阅读 6 | Bayesian Meta-Learning for the Few-Shot Setting via Deep Kernels
基于深度核的少样本设置的贝叶斯元学习
- 摘要
- 1 简介
-
- 1.1 动机
- 2 背景
- 2.1 Few-shot Learning
-
- 2.2 Kernels
- 3 方法说明
-
- 3.1 回归
- 3.2 分类
- 4 相关工作
- 5 实验
-
- 5.1 回归
- 5.2 分类
- 5.3 跨域分类
- 6 结论
- Broader Impact
摘要
最近,已经引入了不同的机器学习方法来解决具有挑战性的少样本学习场景,即从与特定任务相关的小标记数据集中学习。常见的方法采取了元学习的形式:学习如何在旧问题的基础上学习新问题。在认识到元学习是在多层次模型中实现学习之后,我们通过使用深层内核对元学习内部循环进行了贝叶斯处理。因此,我们可以学习一个转移到新任务的内核; 我们称之为深度内核传输 (DKT) 。这种方法具有许多优点: 可以直接实现为单个优化器,提供不确定性量化,并且不需要估计任务的特定参数。我们从经验上证明,DKT在几次分类方面优于几种最先进的算法,并且是 跨域自适应 和回归的最新技术。我们得出的结论是,复杂的元学习例程可以用更简单的贝叶斯模型代替,而不会损失准确性。
1 简介
最先进的机器学习方法,如深度学习 (LeCun等人,2015; Schmidhuber,2015) 和人类学习之间的一个关键区别是,前者需要大量的数据,以便发现跨样本的相关模式,而后者从少数例子中获得了丰富的结构信息。此外,深度学习方法难以提供不确定性的度量,这是处理稀缺数据时的一个关键要求,而人类可以在有限的证据下有效地权衡不同的选择。在这方面,一些作者已经提出,人类进行少样本归纳推理的能力可以源自贝叶斯推理机制 (Steyvers等,2006; Tenenbaum等,2011)。因此,我们认为,通过使用深度内核方法,将元学习自然解释为在层次模型中实现学习,从而导致贝叶斯等效。
深度内核将神经网络与内核相结合,以提供可扩展且可表达的闭式协方差函数 (Hinton和Salakhutdinov,2008; Wilson等,2016)。如果一个人有大量的小但相关的任务,就像在很少的学习中一样,可以定义一个诱导知识转移的通用先验。此先验可以是具有跨任务共享参数的深层内核,因此,给定一个新的看不见的任务,可以有效地估计以小支持集为条件的查询集上的后验分布。在元学习框架中(Hospedales等人,2020),这对应于内循环的贝叶斯处理。这是我们提出的方法,我们称之为带转移的深度核学习,简称为深度核转移(DKT)。
我们为回归和分类设置导出了两个版本的DKT,并将其与标准化基准环境中的最新方法进行了比较; 该代码以开源许可证发布。DKT与其他少样板方法相比有几个优点,可以总结如下:
- 简单和高效。它不需要任何复杂的元学习优化例程,可以直接实现为单个优化器,因为内部循环被解析边际似然计算所取代,并且在低数据体系中是有效的。
- 灵活性。它可以用于各种设置,例如回归,跨域和域内分类,具有最先进的性能。
- 健壮性: 它提供了有关新实例的不确定性的度量,这对于决策者在很少的情况下至关重要。
主要贡献:
(i) 一种通过使用深层内核来处理少样本学习问题的新颖方法
(ii) 对元学习内部循环的有效贝叶斯处理
(iii) 经验证据表明,用于少量学习的复杂元学习例程可以用更简单的分层贝叶斯模型代替,而不会损失准确性。
1.1 动机
针对少样本设置的贝叶斯元学习方法主要遵循层次建模和多任务学习的路线。底层的有向图形模型区分所有任务共有的一组共享参数 θ \mathbf θ θ 和一组 N N N 个任务特定参数 ρ t \mathbf \rho_t ρt。给定一个训练任务数据集 D = { T t } t = 1 N \mathcal D = \{\mathcal T_t\}_{t=1}^N D={Tt}t=1N,每个包含输入输出对 T = { ( x l , y l ) } l = 1 L \mathcal T = \{(x_l,y_l)\}_{l=1}^L T={(xl,yl)}l=1L,并给定来自新任务 T ∗ \mathcal T^* T∗ 的测试点 x ∗ x_* x∗,学习包括找到 θ \mathbf θ θ 的估计值,在任务特定参数 p ( ρ t ∣ x ∗ , D , θ ) p(\mathbf {ρ}_t | x_∗, \mathcal D, \mathbf θ) p(ρt∣x∗,D,θ) 上形成后验分布,然后计算后验预测分布 p ( y ∗ ∣ x ∗ , θ ) p(y_∗ | x_∗, \mathbf θ) p(y∗∣x∗,θ)。从概率角度来看,这种方法是原则性的,但存在问题,因为它需要通过摊余分布或抽样来管理两个层次的推断,通常需要繁琐的架构。
在最近的可微元学习方法中,通过最大似然估计、迭代更新外循环中的 θ \mathbf θ θ 和内循环中的 ρ t \mathbf ρ_t ρt来学习两组参数。这种情况有各种各样的问题,因为两组参数的联合优化以及更新权重时需要估计高阶导数 (梯度的梯度) 会导致学习不稳定。
为了避免这些缺点,我们提出了一种更简单的解决方案,即在特定任务的数据上边缘化 ρ t \mathbf ρ_t ρt。这种边缘化是分析性的,并导致封闭形式的边际可能性,该边际可能性衡量给定参数集下数据的期望值。通过找到深层内核的参数,我们可以最大化边际可能性。按照我们的方法,无需估计特定于任务的参数的后验分布,这意味着可以跳过中间推理步骤直接计算后验预测分布。我们认为,这种方法在少样本设置中非常有效,相对于元学习方法,显著降低了模型的复杂性,同时保留了贝叶斯方法 (例如不确定性估计) 的优势,具有最先进的性能。
2 背景
2.1 Few-shot Learning
由于文献中使用的定义冲突,描述少样本学习设置的术语是分散的;请读者参阅Chen等人(2019)进行比较。这里,我们使用的术语来源于写作时最流行的元学习文献。令 S = { ( x l , y l ) } l = 1 L \mathcal S=\{(x_l,y_l)\}_{l=1}^L S={(xl,yl)}l=1L是包含输入输出对的支持集,其中 L L L 等于1 (1-shot) 或5 (5-shot),并且 Q = { ( x m , y m ) } m = 1 M \mathcal Q=\{(x_m,y_m)\}_{m=1}^M Q={(xm,ym)}m=1M 是查询集 (有时在文献中称为目标集),M通常比L大一个数量级。为了便于表示,支持和查询集被分组为任务 T = { S , Q } \mathcal T=\{\mathcal {S, Q}\} T={S,Q},数据集 D = { T t } t = 1 N \mathcal D=\{\mathcal T_t\}_{t=1}^N D={Tt}t=1N 被定义为这些任务的集合。模型在从 D \mathcal D D 中取样的随机任务上进行训练,然后给定一个从测试集取样的新任务 T ∗ = { S ∗ , Q ∗ } T_*=\{S_∗,Q_∗\} T∗={S∗,Q∗},目的是将模型以支持集 S ∗ S_∗ S∗ 的样本为条件,以估计查询集合 Q ∗ Q_* Q∗中样本的隶属度。在最常见的情况下,训练、验证和测试数据集各自由不同的任务组成,这些任务是从相同的任务总体分布中抽取的。请注意,目标值 y y y 可以是一个连续值(回归),也可以是一个离散值(分类),不过以前的工作大多集中在分类上。 我们还考虑了跨域的情况,在这种情况下,测试任务的取样与训练任务的分布不同;这有可能更能代表许多现实世界的情况。
2.2 Kernels
给定两个输入实例 x x x 和 x ′ x' x′ 以及一个函数 f ( ⋅ ) f(·) f(⋅),核 k ( x , x ′ ) k(x,x') k(x,x′) 是一个协方差函数,它表示两点输出的相关性如何取决于它们在输入空间中的两个位置之间的关系
k ( x , x ′ ) = c o v ( f ( x ) , f ( x ′ ) ) (1) k(x,x') = cov(f(x), f(x')) \tag{1} k(x,x′)=cov(f(x),f(x′))(1)
最简单的核有一个线性表达式 k L I N ( x , x ′ ) = v ⟨ x , x ′ ⟩ k_{LIN}(x,x')=v\left \langle x, x'\right \rangle kLIN(x,x′)=v⟨x,x′⟩ ,其中 ⟨ ⋅ ⟩ \left \langle \cdot \right \rangle ⟨⋅⟩ 表示内积, v v v 是方差超参数。使用线性核在计算上是很方便的,它诱导了一种贝叶斯线性回归的形式,然而这往往是过于简单的。因此,文献中提出了多种其他内核: 径向基函数核 (RBF),Matern核,余弦相似核 (CosSim) 和光谱混合核。有关本工作中使用的内核的详细信息,请参见附录A。在深度核学习中,输入向量 x \mathbf x x 通过一个非线性函数 F ϕ ( x ) → h \mathcal F_{\phi}(\mathbf x)→\mathbf h Fϕ(x)→h(例如一个神经网络)映射到一个潜在向量 h \mathbf h h 上,该函数由一组权重 ϕ \large \phi ϕ 作为参数。 嵌入的定义是使输入的维度大大降低,也就是说,如果 x ∈ R J \mathbf x \in \mathbb R^J x∈RJ 和 h ∈ R K \mathbf h \in \mathbb R^K h∈RK,那么 J ≫ K J \gg K J≫K。一旦输入被编码为 h \mathbf h h,潜伏向量就会被传递给一个内核。当输入是图像时, F ϕ \mathcal F_\phi Fϕ 的常见选择是卷积神经网络 (CNN)。具体来说,我们构建了一个内核
k ( x , x ′ ∣ θ , ϕ ) = k ′ ( F ϕ ( x ) , F ϕ ( x ′ ) ∣ θ ) (2) k(\mathbf {x,x'|\theta,\phi}) = k'(\mathcal F_\phi(\mathbf x),\mathcal F_\phi(\mathbf x')|\mathbf \theta) \tag2 k(x,x′∣θ,ϕ)=k′(Fϕ(x),Fϕ(x′)∣θ)(2)
通过将输入通过非线性函数 F ϕ \mathcal F_\phi Fϕ,从具有超参数 θ \mathbf θ θ 的某个潜在空间核 k ′ k' k′ 中获得。然后通过最大化对数边际似然,反向传播误差,共同学习超参数 θ \mathbf θ θ 和模型参数 ϕ \large \phi ϕ 。
3 方法说明
让我们从将元学习解释为层次模型开始,考虑上层中的一组任务公共参数(在外循环中优化),以及确定下层中的任务特定参数(在内循环中优化的)的过程。例如,在MAML中,外参数是常见的神经网络初始化权重,内参数是最终的网络权重,先验隐含地定义为可以在初始参数的几个梯度步骤中实现特定参数化的概率。通过对内环进行微分以获得外环参数的导数,可以端到端地获得外环和内环。这会导致众所周知的不稳定性问题。
我们的建议是用贝叶斯积分代替内部循环,同时仍对参数进行优化。这通常称为最大似然II型 (ML-II) 方法。我们学习了一组深度内核 (外环) 的参数和超参数,这些参数最大化了所有任务的边际可能性。这种可能性的边际化使用高斯过程的方法对每项任务的特定参数进行整合,用一个内核取代内循环模型。

让任务 t t t 的所有输入数据 (支持和查询) 用 T t x \mathcal T_t^x Ttx 表示,目标数据为 T t y \mathcal T_t^y Tty。让 D x \mathcal D^x Dx 和 D y \mathcal D^y Dy 表示所有任务中这些数据集的各自集合; 此数据按任务分层分组。以任务公共超参数 θ ^ \hat {\mathbf \theta} θ^ 和其他任务公共参数 ϕ ^ \large \hat \phi ϕ^(例如神经网络权重)为条件的贝叶斯分层模型的边际似然将采用以下形式
P ( D y ∣ D x , θ ^ , ϕ ^ ) = Π t P ( T t y ∣ T t x , θ ^ , ϕ ^ ) (3) P(\mathcal D^y|\mathcal D^x,\hat {\mathbf \theta},\hat \phi) = \mathop\Pi_tP(\mathcal T_t^y|\mathcal T^x_t,\hat \theta, \hat \phi) \tag3 P(Dy∣Dx,θ^,ϕ^)=ΠtP(Tty∣Ttx,θ^,ϕ^)(3)
其中 P ( T t y ∣ T t x , θ ^ , ϕ ^ ) P(\mathcal T_t^y|\mathcal T^x_t,\hat \theta, \hat \phi) P(Tty∣Ttx,θ^,ϕ^) 是对每组任务特定参数的边缘化。让任务 t t t 的这些任务特定参数用 ρ t \large ρ_t ρt 表示,那么
P ( T t y ∣ T t x , θ , ϕ ) = ∫ Π k P ( y k ∣ x k , θ , ϕ , ρ t ) d ρ t (4) P(\mathcal T_t^y|\mathcal T^x_t,\theta, \phi) = \int \mathop\Pi_kP(y_k|x_k,\theta,\phi,\rho_t)d\rho_t \tag4 P(Tty∣Ttx,θ,ϕ)=∫ΠkP(yk∣xk,θ,ϕ,ρt)dρt(4)
其中 k k k 列举了 x k ∈ T t x x_k \in \mathcal T_t^x xk∈Ttx 的元素,以及相应的元素 y k ∈ T t y y_k \in T^y_t yk∈Tty。在典型的元学习中,针对任务特定目标(以及优化器的参数),任务特定积分(4)将被内环优化器替代;任何额外的跨任务参数 θ 、 ϕ \theta、\phi θ、ϕ 都将在外循环中进行优化。相反,我们对特定于任务的参数进行完全积分,并仅对跨任务参数 θ , ϕ \theta, \phi θ,ϕ 进行优化。我们通过使用 P ( T t y ∣ T t x , θ ) P(\mathcal T_t^y|\mathcal T^x_t,\theta) P(Tty∣Ttx,θ) 的高斯过程模型来隐式而非显式地实现这一点,这是许多模型类的方程4的解析积分的结果。对于新点 x ∗ x_* x∗ 的值的预测,给定一小部分示例 T t ∗ x , T t ∗ y \mathcal T^x_{t_*}, \mathcal T^y_{t_*} Tt∗x,Tt∗y ,对于新任务 t ∗ t_* t∗ 可以使用预测分布
p ( y ∗ ∣ x ∗ , T t ∗ x , T t ∗ y ) ≈ p ( y ∗ ∣ x ∗ , T t ∗ x , T t ∗ y , θ ^ , ϕ ^ ) (5) p(y_*|x_*,\mathcal T_{t_*}^x, \mathcal T_{t_*}^y)\approx p(y_*|x_*,\mathcal T_{t_*}^x, \mathcal T_{t_*}^y, \hat{\mathbf \theta},\hat\phi)\tag5 p(y∗∣x∗,Tt∗x,Tt∗y)≈p(y∗∣x∗,Tt∗x,Tt∗y,θ^,ϕ^)(5)
我们的主张是,尽管每个任务的数据点数量可能很小,但所有任务中对边际似然(3)有贡献的点的总数足够大,足以使 ML_II 适合寻找一组共享权重和参数,而不会出现欠拟合或过拟合。这些参数为新的看不见的任务提供了一个具有良好泛化能力的模型,无需推断特定于任务的参数 ρ t \rho_t ρt。第5节中的结果表明,我们的建议与更复杂的元学习方法具有竞争力。请注意,这种方法不同于直接的深度内核学习,在深度内核学习中,边缘化覆盖了所有数据;这将忽略任务区别,这在分层模式下至关重要(参见第5.1节中的实验比较)。这个问题也不同于多任务学习,在多任务学习中,任务共享相同的输入值。
对于随机梯度训练,在每次迭代时,从 D \mathcal D D 中采样任务 T = { S , Q } \mathcal {T=\{S,Q\}} T={S,Q},然后在 S ∪ Q \mathcal S \cup \mathcal Q S∪Q (假设 y ∈ Q y \in \mathcal Q y∈Q是待观察的)上估计对数边际似然,即(3)的对数,,并且通过该任务的边际似然目标上的梯度步长来更新核的参数。这个过程允许我们找到一个可以在支持集和查询集上完整表示任务的内核。测试一下时,给定新任务 T ∗ = S ∗ , Q ∗ \mathcal T_* ={\mathcal S_*, \mathcal Q_*} T∗=S∗,Q∗,使用在训练时学习的参数,通过对支持集 S ∗ \mathcal S_* S∗ 进行条件调节,对查询集 $ \mathcal Q_*$ 进行预测。算法1中给出了伪代码。
3.1 回归
我们想为回归情况找到(3)的封闭形式表达式。假设我们感兴趣的是一个连续的输出 y ∗ y_* y∗,它是由一个被方差为 σ 2 σ^2 σ2 的同方差高斯噪声 ϵ \epsilon ϵ 污染的干净信号 f ∗ ( x ∗ ) f_∗(x^∗) f∗(x∗)产生的。我们感兴趣的是观测输出和测试位置处的函数值的联合分布。为了便于标记,让我们定义 k ∗ = k ( x ∗ , x ) k_∗ = k(x_∗,x) k∗=k(x∗,x) 来表示 x ∗ x_∗ x∗ 和 D \mathcal D D 中的 N N N 个训练点之间的协方差的 N N N 维向量。类似地,对于 x ∗ x_{*} x∗ 的方差,我们写为 k ∗ ∗ = k ( x ∗ , x ∗ ) k _{**}= k(x _*, x _*) k∗∗=k(x∗,x∗)和 K \mathbf K K 来识别 D \mathcal D D 中的训练输入的协方差矩阵。预测分布 p ( y ∗ ∣ x ∗ , D ) p(y_*| x_*, \mathcal D) p(y∗∣x∗,D)是通过贝叶斯规则获得的,并且给定先验的共轭性,这是一个高斯函数,其均值和协方差指定为
E [ f ∗ ] = k ∗ T ( K + σ 2 I ) − 1 y (6a) \mathbb E[f_*] = k_*^T(\mathbf K + \sigma^2\mathbf I)^{-1}\mathbf y \tag{6a} E[f∗]=k∗T(K+σ2I)−1y(6a)
c o v ( f ∗ ) = k ∗ ∗ − k ∗ T ( K + σ 2 I ) − 1 k ∗ (6b) cov(f_*) = k_{**} - k_*^T(\mathbf K + \sigma^2\mathbf I)^{-1}\mathbf k_* \tag{6b} cov(f∗)=k∗∗−k∗T(K+σ2I)−1k∗(6b)
注意,(6)定义了一个分布函数,它假设在任何有限点集合处收集的值具有联合高斯分布。在此,我们将噪声 σ 2 I \sigma^2\mathbf I σ2I 吸收到协方差矩阵 K \mathbf K K 中,并将其视为可学习参数 θ \theta θ 的向量的一部分,该可学习参数 θ \theta θ 还包括核的超参数(例如,线性核的方差)。
让我们将任务 t t t 的所有目标数据项收集到向量 y t \mathbf y_t yt中,并用 K t K_t Kt 表示所有任务输入之间的内核。由此得出,等式(3)的边际似然性可以重写为
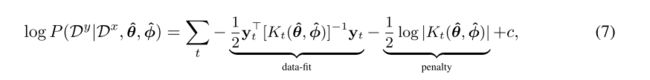
其中 c c c 是常数。通过梯度上升的ML-II最大化(7)来估计参数。在实践中,我们使用随机梯度上升,每个批次包含单个任务的数据。
3.2 分类
分类情况的贝叶斯处理并非毫无问题,因为非高斯似然性破坏了共轭性。例如,在二元分类的情况下,伯努利似然性导致证据的难以处理的边缘化,因此不可能以封闭形式估计后验。处理这一问题的常用方法(例如MCMC或变分方法),对于小样本学习会产生大量的计算成本:对于每个新任务,通过近似或采样来估计后验,引入内循环,将时间复杂度从常数 O ( 1 ) \mathcal O(1) O(1) 增加到线性 O ( K ) \mathcal O(K) O(K) ,其中 K K K 是内循环的数量。另一种解决方案是将分类问题视为回归问题,从而恢复到证据和后验的分析表达式。在文献中,这被称为 标签回归(LR)或最小二乘分类(LSC)。在实验上,LR和LSC在二元和多类环境中都比其他方法更有效。在这里,我们导出了一个基于LR的分类器,该分类器计算成本低且易于实现。
让我们定义一个二元分类设置,其中类是伯努利随机变量 c ∈ { 0 , 1 } c \in \{0,1\} c∈{0,1}。模型被训练为回归变量,目标 y + = 1 y_+ = 1 y+=1 表示 c = 1 c = 1 c=1 , y − = − 1 y_− = −1 y−=−1 表示 c = 0 c = 0 c=0 。即使 y ∈ { − 1 , 1 } y \in \{−1, 1\} y∈{−1,1},也不能保证 f ( x ) ∈ [ y − , y + ] f(x) \in [y_-,y_+] f(x)∈[y−,y+]。预测是通过计算预测平均值并将其传递给一个sigmoid函数来进行的,从而产生概率解释。注意,仍然可以使用ML-II对 θ θ θ 和 ϕ \phi ϕ 进行点估计。当推广到多标签任务时,我们应用一对一方案,其中使用 C个二进制分类器 对每个类和所有其他类进行分类。对数边际似然性,即等式(3)的对数,被C个单独类输出 y c \mathbf y_c yc 中的每一个的边际之和代替,如下
log p ( y ∣ x , θ ^ , ϕ ^ ) = ∑ c = 1 C log p ( y c ∣ x , θ ^ , ϕ ^ ) (8) \log p(\mathbf{y} \mid \mathbf{x}, \hat{\boldsymbol{\theta}}, \hat{\boldsymbol{\phi}})=\sum_{c=1}^C \log p\left(\mathbf{y}_c \mid \mathbf{x}, \hat{\boldsymbol{\theta}}, \hat{\boldsymbol{\phi}}\right) \tag{8} logp(y∣x,θ^,ϕ^)=c=1∑Clogp(yc∣x,θ^,ϕ^)(8)
给定一个新的输入 x ∗ x_* x∗ 和所有二元分类器的 C 个输出,通过选择具有最高概率的输出 c ∗ = a r g m a x c ( σ ( m c ( x ∗ ) ) ) c_* = argmax_c(\sigma(m_c(x_*))) c∗=argmaxc(σ(mc(x∗))) 来做出决策,其中 m ( x ) m(x) m(x) 是预测均值, σ ( ⋅ ) \sigma(\cdot) σ(⋅) 是 sigmoid 函数,并且 c ∗ ∈ { 1 , . . . , C } c_* \in \{1,...,C\} c∗∈{1,...,C}。
4 相关工作
关于特征转移的文献非常丰富。作为少样本学习的基线,标准程序由两个阶段组成:预训练和微调。在预训练期间,网络和分类器在基类的样本上进行训练。微调时,网络参数是固定的,并在新类别上训练一个新的分类器。这种方法有其局限性;模型的一部分必须为每个新任务从头开始训练,经常会过拟合。Chen等人(2019)提出使用样本之间的余弦距离(称为Baseline++)来扩展这一点。然而,这仍然依赖于一个假设,即固定的微调协议将正确平衡每个任务的偏差-方差权衡。
或者,人们可以在学习到的度量空间中比较新示例。匹配网络(MatchingNets, Vinyals等人,2016)使用余弦距离上的softmax作为注意力机制,并使用LSTM对支持集上下文中的输入进行编码,将其视为序列。原型网络(ProtoNets, Snell等人,2017)基于学习度量空间,其中分类是通过计算到原型的距离来执行的,其中每个原型是属于其类的嵌入式支持点的平均向量。关系网络(RelationNets, Sung等人,2018)使用嵌入模块来生成查询图像的表示,关系模块将这些表示与支持集进行比较,以识别匹配的类别。元学习(Bengio等人,1992;Schmidhuber, 1992;Hospedales et al., 2020)方法在少样本学习任务中非常流行。MAML (Finn et al., 2017)被提出作为一种在许多任务中对模型参数进行元学习的方法,因此初始参数是适应新任务的良好起点。MAML为许多元学习方法提供了灵感。
在几项研究中,MAML被解释为贝叶斯层次模型(Finn等人,2018;Grant等人,2018;Jerfel et al., 2019)。贝叶斯MAML (Yoon等人,2018)将高效的基于梯度的元学习与非参数变分推理相结合,同时保持了一种与应用无关的方法。Gordon等人(2019)最近提出了一种平摊网络,它将少样本学习数据集作为输入,并输出特定任务参数的分布,可用于预测的元学习概率推理。Xu等人(2019)使用具有编码器-解码器架构的条件神经过程将标记数据投影到无限维函数表示中。
对于回归案例,Harrison等人(2018)提出了一种名为ALPaCA的方法,该方法使用样本函数数据集来学习特定领域的编码和先验权重。Tossou等人(2019)提出了高斯过程核学习的一种变体,称为自适应深度核学习(ADKL),它使用任务编码器网络为每个任务找到核。我们的方法和ADKL之间的区别在于,我们不需要额外的模块来进行任务编码,因为我们可以依赖一组共享的通用超参数。
5 实验
在少样本设置中,方法之间的公平比较经常被每种算法在实现细节上的实质性差异所混淆。Chen等人(2019)最近发布了一个开源基准,以便在方法之间进行公平的比较。我们使用PyTorch和GPyTorch将算法集成到此框架中(Gardner等人,2018)。在所有实验中,所提方法都被标记为DKT。培训细节见附录B(补充材料)。

图1:(a)未知函数逼近的不同方法比较(超出范围,5个支撑点)。DKT更好地拟合(红线)真实函数(蓝色实线)和训练时从未见过的越界部分(蓝色虚线)。不确定性(红色阴影)在低置信区域增加。(b)对图像中头部轨迹估计中的异常值(切出噪声,红色帧)的不确定性估计。DKT能够估计一个接近真实值(蓝色圆圈)的平均值(红线),显示出很大的方差。特征迁移在同一位置表现不佳。
5.1 回归
我们考虑两个任务:未知周期函数的振幅预测和图像中的头部姿态轨迹估计。Finn et al.(2017)将前者视为小样本回归问题,以激励MAML:支持和查询标量从振幅∈[0.1,5.0]、相位∈[0,π]、范围∈[-5.0,5.0]和高斯噪声(µ=0,σ=0.1)的周期波中均匀采样。训练集由5个支持和5个查询点组成,测试集由5种支持和200个查询点构成。我们首先在 in-range 进行测试:与Finn等人(2017)中的训练集相同的领域。我们还考虑了更具挑战性的 out-of-range 回归,测试点取自扩展域[-5.0,10.0],其中在训练时未看到范围[5.0,10.0]的部分。
对于头部姿势回归,我们使用伦敦玛丽女王大学的多视图面部数据集(QMUL,Gong等人,1996),它包括37人(32个训练,5个测试)的灰度人脸图像。每个人有133张面部图像,覆盖偏转±90 °和倾斜±30 °(增量为10 °)的视野。每个任务由取自该离散流形的随机采样轨迹组成,其中 in-range 包括整个流形,out-of-range 允许仅在最左边的10个角度上训练,并且在整个流形上测试;目标是预测倾斜。对于周期函数预测实验,我们将我们的方法与特征转移和MAML进行了比较(Finn等人,2017)。此外,我们报告了ADKL(Tossou等人,2019年)、R2-D2(Bertinetto等人,2019)和ALPaCA(Harrison等人,2018年)在类似任务(如Yoon等人,2019中所定义)中获得的结果。为了强调内核转移的重要性,我们添加了一个基线,其中在没有转移的情况下,从每个传入任务的支持点开始训练深度内核(DKBaseline),这对应于标准的深度内核学习(Wilson等人,2016)。很少有方法处理图像的小样本回归,因此在头部姿态轨迹估计中,我们将其与特征传递和MAML进行比较。作为度量,我们使用预测值和真实值之间的平均均方误差(MSE)。其他详细信息见附录B。
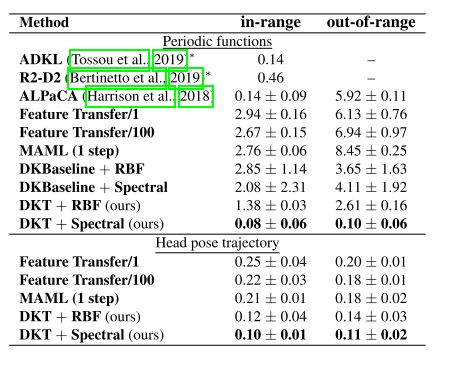
回归实验结果总结见表1,定性比较见图1a和补充材料。在两个实验中,DKT获得了比特征转移和MAML更低的MSE。对于未知周期函数估计,使用谱核给出了比RBF更大的优势,在范围内和范围外都更精确(1.38对0.08,和2.61对0.10MSE)。不确定度在点密度较低的区域中得到正确估计,在 out-of-range 的区域中总体上增加。相反,特征传递严重欠拟合(1步,2.94 MSE)或过拟合(100步,2.67),并且无法建模超出范围的点(6.13和6.94)。MAML在范围内有效(2.76),但在范围外显著更差(8.45)。ADKL、R2-D2和ALPaCA(0.14、0.46、0.14)优于带RBF内核的DKT(1.38),但差于带频谱内核的DKT(0.08)。这表明适当的核函数与我们的方法相结合比自适应方法更有效。DKBaseline在所有条件下的性能都明显比DKT差,这证实了使用内核传输解决少发问题的必要性。图1a中的定性比较表明,特征传递和MAML都不能拟合真函数,特别是在范围外;附录C中报告了其他样品。我们观察到头部姿势估计的类似结果,DKT在所有情况下报告较低的MSE(表1)。在附录C中,我们还检查了由RBF和谱核生成的潜在空间。
表1:周期函数(上图)和头部姿势轨迹(下图)的Fewshot回归的平均均方误差(MSE)和标准差(三次运行),使用10个样本进行训练,5个样本进行测试。相同的域标记为范围内,扩展的不可见域标记为范围外。最小误差以粗体显示。※ Tossou等人(2019)报告的结果。
Uncertainty quantification (regression) 在数据少的情况下,考虑到预测中的不确定性至关重要; DKT是为数不多的能够做到这一点的方法之一。为了突出我们的方法相对于其他方法的优势,我们进行了一项实验,量化不确定性,采样头部姿势轨迹,并使用Cutout(DeVries和Taylor,2017)破坏一个输入,随机覆盖95%的图像。定性结果见图1b。对于损坏的输入,DKT预测接近真实值的值,同时给出高水平的不确定性(红色阴影)。特征传递执行得很差,预测的姿势不真实。
5.2 分类
我们考虑两个具有挑战性的数据集:加州理工学院-UCSD鸟类(CUB-200,Wah等人,2011年)和迷你ImageNet(Ravi和Larochelle,2017年)。所有实验均为5向(5个随机类),具有1或5次激发(支持集中每个类1或5个样本)。为查询集提供了每个类别总共16个样本。附录B(补充)中的其他详细信息材料)。我们比较以下内核:linear,RBF,Matérn,Polynomial,CosSim和BNCosSim。 BNCosSim是CosSim的变体,其特征通过BatchNorm(BN)统计数据集中(Ioffe和Szegedy,2015),这已证明可提高性能(Wang等人,2019年)。我们将我们的方法与几种最先进的方法进行了比较,如MAML(Finn等人,2017)、ProtoNets(斯内尔等人,2017年)、MatchingNet(Vinyals等人,2016年)和关系网(Sung等人,2018年)。我们进一步比较了Chen等人(2019)的特征转移和基线++。所有这些方法都是用相同的主干和学习计划从头开始训练的。我们还报告了具有可比较的训练过程和卷积结构的方法的结果(Mishra等人,拉维和拉罗谢尔,2017年; Wang等人,2019),包括最近的分层贝叶斯方法(Gordon等人,2019年; Grant等人,2018年; Jerfel等人,2019年)。我们排除了使用更深层主干或更复杂学习计划的方法(Antoniou和Storkey,2019;Oreshkin等人,2018;Qiao等人,2018年;Ye等人,2018),以便可以与基础区别模型的能力分开评估算法的质量。
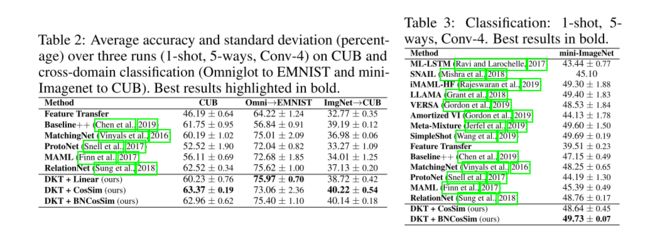
我们在表2和表3中报告了更具挑战性的 1-shot 情况的结果,在补充材料中报告了5-shot 情况的结果。所有实验均为5-ways(5个随机类),具有1-shot或5-shot(支持集中每个类1或5个样本)。DKT在CUB(63.37%)和mini-ImageNet(49.73%)中均实现了最高的准确度,比包括分层贝叶斯方法(如LLAMA(49.40%)和VERSA(48.53%))在内的任何其他方法都更好。一阶内核的最佳性能(表5,附录材料)很可能是由于潜在空间中的神经网络引起的低曲率流形,从而增加了数据的线性可分性。总体而言,我们的结果证实了Chen等人(2019)关于余弦度量有效性的发现,以及Wang等人(2019)关于特征归一化重要性的发现(附录D和E)。在表6(附录材料),我们报告了具有更深主干的结果(ResNet-10,He等人,2016),显示DKT在5次激发(85.64%)中优于所有其他方法,在1-shot (72.27%)中结果次佳。CosSim和BNCosSim之间的性能差异对于更深的主干网来说更大,这表明当向网络添加额外的层时,将特征集中是很重要的。
Uncertainty quantification (classification) 我们提供了CUB数据集上的模型校准结果。我们遵循Guo et al.(2017)估计预期校准误差(ECE)的方案,这是一种标量汇总统计量(越低越好)。我们首先缩放每个模型输出,通过在3000个任务上经由LBFGS最小化logit/label上的NLL来校准温度;然后我们估计测试集的ECE。CUB 1-shot 和 5-shot 测试的完整结果(百分比,三次运行的平均值)见附录D表7。在单次测试中,DKT达到了最低的ECE 2.6%,击败了大多数竞争对手(只有ProtoNet和MAML做得更好)。在5-shot中,我们的模型实现了第二低的ECE 1.1%(ProtoNet做得稍微好一点)。
5.3 跨域分类
跨域分类的目的是训练关于从一个分布采样的任务的模型,该模型然后推广到从不同分布采样的任务。具体地说,我们联合收割机数据集,以便从一个数据集中提取训练分割,从另一个数据集中提取验证和测试分割。我们对mini-ImageNet→CUB(从mini-ImageNet分离训练和从CUB分离瓦尔/测试)和Omniglot→EMNIST进行了实验。我们将我们的方法与之前考虑的方法进行了比较,使用相同的时间点数量和模型选择策略设置(见附录B)。单次激发情况的结果如表2所示。DKT在大多数情况下都能达到最高的精度。在Omniglot→EMNIST中,使用线性核可实现最佳性能(75.97%)。在miniImageNet→CUB中,DKT优于所有其他方法,CosSim(40.22%)和BNCosSim(40.14%)的准确度最高。请注意,大多数竞争方法在此设置中遇到困难,如它们的低准确度和大标准差所示。核函数的比较表明一阶核函数更有效(见附录E,表9)。
6 结论
在这项工作中,我们引入了DKT,一种基于深度核学习的高度灵活的贝叶斯模型。与文献中的一些方法相比,DKT在回归和跨域分类方面表现更好,同时提供了不确定性的度量。基于这些结果,我们认为,许多复杂的元学习例程的小样本学习可以取代一个简单的层次贝叶斯模型,而不会损失准确性。未来的工作可以集中在利用模型在相关设置中的灵活性,特别是那些合并连续和小样本学习的设置(Antoniou等人,2020年),DKT在这里有着蓬勃发展的潜力。
Broader Impact
这项工作的主要动机是设计一个简单而有效的贝叶斯方法来处理少镜头学习设置。如果我们想要拥有能够处理具体现实问题的系统,那么从减少的数据量中学习的能力是至关重要的。应用包括(但不限于):计算资源受限情况下的分类和回归、小数据集的医学诊断、少量图像的生物特征识别等。我们的方法是少数能够提供不确定性测量作为决策者反馈的方法之一。然而,明智地选择系统训练所依据的数据是很重要的,因为低数据区域可能比标准对应区域更容易产生偏差。如果数据有偏差,我们的方法不能保证提供正确的估计;这可能会损害最终用户,应认真加以考虑。