Python之排序算法
一、前言
现在很多的事情都可以用算法来解决,在编程上,算法有着很重要的地位,将算法用函数封装起来,使程序能更好的调用,不需要反复编写。
python的十大经典算法如下:
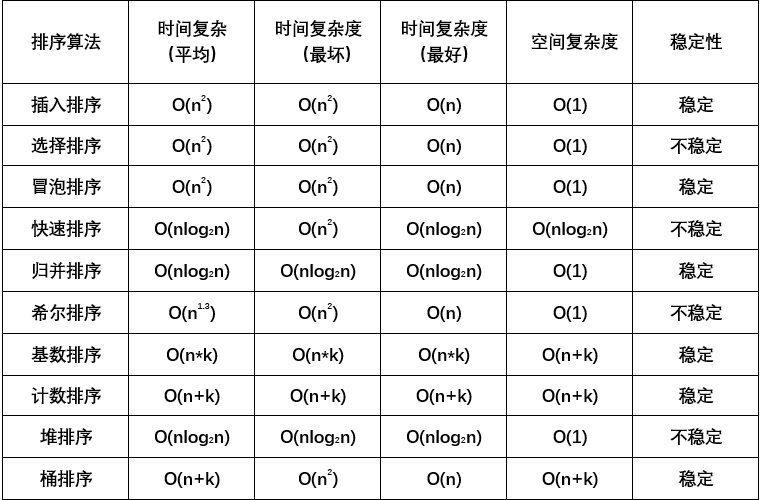
二、算法封装实战:
1、插入排序
def insertion_sort(arr):
'''
插入排序:
从第二个元素开始和前面的元素进行比较,如果前面的元素比当前元素大,则将前面元素后移,
当前元素依次往前,直到找到比它小或等于它的元素插入在其后面,然后选择第三个元素,
重复上述操作,进行插入,依次选择到最后一个元素,插入后即完成所有排序。
:param arr: 传入数组
:return: 返回插入排序的数组
'''
# 第一层for表示循环插入的遍数
for i in range(1, len(arr)):
# 设置当前要插入的元素
current = arr[i]
# 与当前元素比较的比较元素
pre_index = i - 1
while pre_index >= 0 and arr[pre_index] > current:
# 当比较元素大于当前元素则把比较元素后移
arr[pre_index + 1] = arr[pre_index]
# 往前选择下一个比较元素
pre_index -= 1
# 当比较元素小于当前元素,则将当前元素插入在其后面
arr[pre_index + 1] = current
return arr2、选择排序
def selection_sort(arr):
'''
选择排序:
设第一个元素为比较元素,依次和后面的元素比较,比较完所有元素找到最小的元素,
将它和第一个元素互换,重复上述操作,我们找出第二小的元素和第二个位置的元素互换,
以此类推找出剩余最小元素将它换到前面,即完成排序。
:param arr: 传入数组
:return: 返回选择排序的数组
'''
for i in range(len(arr) - 1):
# 将起始元素设为最小元素
min_index = i
# 第二层for表示最小元素和后面的元素逐个比较
for j in range(i + 1, len(arr)):
if arr[j] < arr[min_index]:
# 如果当前元素比最小元素小,则把当前元素标记为最小元素
min_index = j
# 查找一遍后将最小元素与起始元素交换
arr[min_index], arr[i] = arr[i], arr[min_index]
return arr3、冒泡排序
def bubble_sort(arr):
'''
冒泡排序:
从第一个和第二个开始比较,如果第一个比第二个大,则交换位置,然后比较第二个和第三个,
逐渐往后,经过第一轮后最大的元素已经排在最后,所以重复上述操作的话第二大的则会排在倒数第二的位置。
那重复上述操作n-1次即可完成排序,因为最后一次只有一个元素所以不需要比较。
:param arr: 传入数组
:return: 返回冒泡排序的数组
'''
# 第一层for表示循环的遍数
for i in range(len(arr) - 1):
# 第二层for表示具体比较哪两个元素
for j in range(len(arr) - 1 - i):
if arr[j] > arr[j + 1]:
# 如果前面的大于后面的,则交换这两个元素的位置
arr[j], arr[j + 1] = arr[j + 1], arr[j]
return arr
# 冒泡排序方法2
def bubble_sort2(arr):
s = range(1, len(a))[::-1]
print(list(s))
for i in s:
for j in range(i):
if a[j] > a[j + 1]:
a[j], a[j + 1] = a[j + 1], a[j]
print("第 %s 轮交换后数据:%s" % (len(s) - i + 1, a))
print(a)
return arr4、快速排序
def quick_sort(arr):
'''
快速排序:
找出基线条件,这种条件必须尽可能简单,不断将问题分解(或者说缩小规模),直到符合基线条件。
:param arr: 传入数组
:return: 返回快速排序的数组
'''
if len(arr) < 2:
# 基线条件:为空或只包含一个元素的数组是“有序”的
return arr
else:
# 递归条件
pivot = arr[0]
# 由所有小于基准值的元素组成的子数组
less = [i for i in arr[1:] if i <= pivot]
# 由所有大于基准值的元素组成的子数组
greater = [i for i in arr[1:] if i > pivot]
return quick_sort(less) + [pivot] + quick_sort(greater)5、归并排序
def merge_sort(arr):
'''
归并排序:
归并排序是分治法的典型应用。分治法(Divide-and-Conquer):将原问题划分成 n 个规模较小而结构与原问题相似的子问题;
递归地解决这些问题,然后再合并其结果,就得到原问题的解,分解后的数列很像一个二叉树。
具体实现步骤:
1、使用递归将源数列使用二分法分成多个子列
2、申请空间将两个子列排序合并然后返回
3、将所有子列一步一步合并最后完成排序
4、注:先分解再归并
:param arr: 传入数组
:return: 返回归并排序数组
'''
if len(arr) == 1:
return arr
# 使用二分法将数列分两个
mid = len(arr) // 2
left = arr[:mid]
right = arr[mid:]
# 使用递归运算
return marge(merge_sort(left), merge_sort(right))
def marge(left, right):
# 排序合并两个数列
result = []
# 两个数列都有值
while len(left) > 0 and len(right) > 0:
# 左右两个数列第一个最小放前面
if left[0] <= right[0]:
result.append(left.pop(0))
else:
result.append(right.pop(0))
# 只有一个数列中还有值,直接添加
result += left
result += right
return result6、希尔排序
def shell_sort(arr):
'''
希尔排序:
希尔排序的整体思想是将固定间隔的几个元素之间排序,然后再缩小这个间隔。这样到最后数列就成为了基本有序数列。
具体步骤:
1、计算一个增量(间隔)值
2、对元素进行增量元素进行比较,比如增量值为7,那么就对0,7,14,21…个元素进行插入排序
3、然后对1,8,15…进行排序,依次递增进行排序
4、所有元素排序完后,缩小增量比如为3,然后又重复上述第2,3步
5、最后缩小增量至1时,数列已经基本有序,最后一遍普通插入即可
:param arr: 传入数组
:return: 返回希尔排序数组
'''
#
# 取整计算增量(间隔)值
gap = len(arr) // 2
while gap > 0:
# 从增量值开始遍历比较
for i in range(gap, len(arr)):
j = i
current = arr[i]
# 元素与他同列的前面的每个元素比较,如果比前面的小则互换
while j - gap >= 0 and current < arr[j - gap]:
arr[j] = arr[j - gap]
j -= gap
arr[j] = current
# 缩小增量(间隔)值
gap //= 2
return arr7、基数排序
def radix_sort(arr, d):
'''
基数排序:
属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,
顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,
基数排序法是属于稳定性的排序,其时间复杂度为O (nlog(r)m),其中r为所采取的基数,
而m为堆数,在某些时候,基数排序法的效率高于其它的稳定性排序法。
:param arr: 传入数组
:param d: d轮顺序
:return: 返回基数排序数组
'''
for k in range(d): # d轮排序
# 每一轮生成10个列表
s = [[] for i in range(10)] # 因为每一位数字都是0~9,故建立10个桶
for i in arr:
# 按第k位放入到桶中
s[i // (10 ** k) % 10].append(i)
# 按当前桶的顺序重排列表
arr = [j for i in s for j in i]
return arr8、计数排序
def conuting_sort(arr):
'''
计数排序:
对每一个输入元素x,确定小于x的元素个数。利用这一信息,就可以直接把x 放在它在输出数组上的位置上了,
运行时间为O(n),但其需要的空间不一定,空间浪费大。
:param arr: 传入数组
:return: 返回计数排序数组
'''
k = max(arr) # arr的最大值,用于确定C的长度
C = [0] * (k + 1) # 通过下表索引,临时存放A的数据
B = (len(arr)) * [0] # 存放arr排序完成后的数组
for i in range(0, len(arr)):
C[arr[i]] += 1 # 记录arr有哪些数字,值为arr[i]的共有几个
for i in range(1, k + 1):
C[i] += C[i - 1] # arr中小于i的数字个数为C[i]
for i in range(len(arr) - 1, -1, -1):
B[C[arr[i]] - 1] = arr[i] # C[arr[i]]的值即为arr[i]的值在arr中的次序
C[arr[i]] -= 1 # 每插入一个arr[i],则C[arr[i]]减一
return B9、堆排序
def heap_sort(arr):
'''
堆排序:
堆分为最大堆和最小堆,是完全二叉树。堆排序就是把堆顶的最大数取出,将剩余的堆继续调整为最大堆,
具体过程在第二块有介绍,以递归实现 ,剩余部分调整为最大堆后,再次将堆顶的最大数取出,
再将剩余部分调整为最大堆,这个过程持续到剩余数只有一个时结束。
:param arr: 传入数组
:return: 返回堆排序数组
'''
# 从最后一个有子节点的孩子还是调整最大堆
first = len(arr) // 2 - 1
for i in range(first, -1, -1):
sift_down(arr, i, len(arr) - 1)
# [29, 22, 16, 9, 15, 21, 3, 13, 8, 7, 4, 11]
# print('--------end---', arr)
# 将最大的放到堆的最后一个, 堆-1, 继续调整排序
for end in range(len(arr) - 1, 0, -1):
arr[0], arr[end] = arr[end], arr[0]
sift_down(arr, 0, end - 1)
# print(arr)
return arr
def sift_down(arr, node, end):
root = node
# print(root,2*root+1,end)
while True:
# 从root开始对最大堆调整
child = 2 * root + 1 # left child
if child > end:
# print('break',)
break
# print("v:", root, arr[root], child, arr[child])
# print(arr)
# 找出两个child中交大的一个
if child + 1 <= end and arr[child] < arr[child + 1]: # 如果左边小于右边
child += 1 # 设置右边为大
if arr[root] < arr[child]:
# 最大堆小于较大的child, 交换顺序
tmp = arr[root]
arr[root] = arr[child]
arr[child] = tmp
# 正在调整的节点设置为root
# print("less1:", arr[root],arr[child],root,child)
root = child #
# [3, 4, 7, 8, 9, 11, 13, 15, 16, 21, 22, 29]
# print("less2:", arr[root],arr[child],root,child)
else:
# 无需调整的时候, 退出
break
# print(arr)10、桶排序
def bucket_sort(arr):
'''
桶排序:
为了节省空间和时间,我们需要指定要排序的数据中最小以及最大的数字的值,来方便桶排序算法的运算。
:param arr: 当前数组
:return: 返回桶排序数组
'''
# 设置全为0的数组
all_list = [0 for i in range(100)]
last_list = []
for v in arr:
all_list[v] = 1 if all_list[v] == 0 else all_list[v] + 1
for i, t_v in enumerate(all_list):
if t_v != 0:
for j in range(t_v):
last_list.append(i)
return last_list11、介绍一种自带的排序方法sort, 我这边简单的做了一下封装处理
def sort(arr, sort_type=''):
'''
sort方法排序
:param arr: 传入数组
:param sort_type: 排序类型,默认是正序,传入sort_type为"倒序"排序
:return: 符合排序规则的数组
'''
if sort_type == "倒序":
arr.sort(reverse=True)
else:
arr.sort()
return arr对数组去重处理的封装:
# 去重处理
def de_duplication(arr):
b = list(set(arr))
return b三、写一个main函数
if __name__ == '__main__':
a = [7, 3, 10, 9, 9, 21, 35, 4, 6]
arr = insertion_sort(a)
print("插入排序返回数组:", arr)
arr2 = selection_sort(a)
print("选择排序返回数组:", arr2)
arr3 = bubble_sort(a)
print("冒泡排序返回数组:", arr3)
arr4 = bubble_sort2(a)
print("冒泡排序返回数组:", arr4)
arr5 = quick_sort(a)
print("快速排序返回数组:", arr5)
arr6 = merge_sort(a)
print("归并排序返回数组:", arr6)
arr7 = shell_sort(a)
print("希尔排序返回数组:", arr7)
arr8 = radix_sort(a, 8)
print("基数排序返回数组:", arr8)
arr9 = conuting_sort(a)
print("计数排序返回数组:", arr9)
arr10 = heap_sort(a)
print("堆排序返回数组:", arr10)
arr11 = bucket_sort(a)
print("桶排序返回数组:", arr11)
a = sort(a)
print("正序:", a)
a = sort(a, "倒序")
print("倒序:", a)
b = de_duplication(a)
c = sort(b)
print("去重正序:", c)查看结果:
插入排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
选择排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
冒泡排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
[8, 7, 6, 5, 4, 3, 2, 1]
第 1 轮交换后数据:[3, 4, 6, 7, 9, 9, 10, 21, 35]
第 2 轮交换后数据:[3, 4, 6, 7, 9, 9, 10, 21, 35]
第 3 轮交换后数据:[3, 4, 6, 7, 9, 9, 10, 21, 35]
第 4 轮交换后数据:[3, 4, 6, 7, 9, 9, 10, 21, 35]
第 5 轮交换后数据:[3, 4, 6, 7, 9, 9, 10, 21, 35]
第 6 轮交换后数据:[3, 4, 6, 7, 9, 9, 10, 21, 35]
第 7 轮交换后数据:[3, 4, 6, 7, 9, 9, 10, 21, 35]
第 8 轮交换后数据:[3, 4, 6, 7, 9, 9, 10, 21, 35]
[3, 4, 6, 7, 9, 9, 10, 21, 35]
冒泡排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
快速排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
归并排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
希尔排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
基数排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
计数排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
堆排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
桶排序返回数组: [3, 4, 6, 7, 9, 9, 10, 21, 35]
正序: [3, 4, 6, 7, 9, 9, 10, 21, 35]
倒序: [35, 21, 10, 9, 9, 7, 6, 4, 3]
去重倒序: [3, 4, 6, 7, 9, 10, 21, 35]
Process finished with exit code 0总结:在编程中,算法都是相通的,算法重在算法思想,相当于将一道数学上的应用题的每个条件,区间,可能出现的结果进行分解,分步骤的实现它。算法就是将具体问题的共性抽象出来,将步骤用编程语言来实现。通过这次对排序算法的整理,加深了对各算法的了解,具体的代码是无法记忆的,通过对算法思想的理解,根据伪代码来实现具体算法的编程,才是真正了解算法。