在一个应用程序或库的开发过程中,除了其本身的逻辑以外,开发人员还需要做很多额外的工作,以保证编写的代码可以正确的运行,或者在出错时可以快速定位到错误的位置以及原因,这就需要引入一些额外的工具,trace 就是其中特别好用的一种,下文我将会简单介绍 trace,并以 Rust 为例,演示 trace 在 Rust 中的使用方法。
可观测性
Logs、Metrics 和 Traces 并称为可观测性三大支柱,通过分析它们输出的数据,开发人员能够更好的观测到系统的运行状况,更快的定位问题,从而提高系统的可靠性。
日志(Logs)
日志作为最常用的可观测性数据源之一,相信多数开发者都比较熟悉。其本质上就是一种带有时间戳的离散事件记录,通常用于记录系统的运行状态,日志的使用十分简单,只需要在代码中需要报告信息的点添加一行代码,就可以将这些信息输出到控制台或文件中,但是日志也有很大的缺点,它的输出是离散的,这意味着在记录的时候,无法将日志信息相互关联,也无法知道日志信息的上下文,尤其是在多线程的环境下,最终输出的信息比较混乱,不便于检索和分析。
指标(Metrics)
指标是一种定量衡量,例如平均值、比率和百分比等。其值始终为数字而非文本,可以通过数学方法统计和分析,其主要用于描述系统运行状态的数据,比如 CPU 的使用率、内存的使用率、磁盘的使用率等,这些数据可以用来监控系统的运行状态,也可以用来预警。
追踪(Traces)
追踪是一种用于记录系统中一次请求的完整生命周期的数据,它可以记录下一个请求从开始到结束的所有信息,包括请求的发起者、接收者、请求的路径、请求的状态、请求的耗时、请求的错误信息等,这些信息可以用来分析系统的性能瓶颈,也可以用来分析系统的错误。追踪本质上也是一种日志,他与日志的数据结构十分相似,但是它能够提供比日志更丰富的信息。特别是在分布式系统中,追踪能够跨越多个服务,汇总出一次请求的完整信息,让开发人员能够更方便的找到系统中的问题。
Rust 中的 Trace
Rust 社区中比较有名的 trace 实现有三个:
- tracing 由 tokio 团队维护,目前使用最广泛,生态也比较完善
- rustracing 使用人数相对较少
- minitrace tikv 团队打造,性能最好
接下来就以 tracing 为例,介绍一下trace 的核心概念以及使用方法:
Span
Span 可以说是 trace 中最关键的概念之一,它表示的是一个过程,也就是一段时间内发生的所有事件的集合,其数据结构中包含着 Span 的开始时间和结束时间,在分析数据是可以借助工具直观的看到某次请求或操作的耗时情况。在同一个 trace 流程中的所有 Span 都共享这相同的 Trace Id ,每个 Span 也有着自己的 Span Id,并且 Span 还支持嵌套,嵌套的 Span 中也会保存着相应的父子关系,最终可以靠这些信息,将请求的完整生命周期串联起来,并且不会与相同时间段内的其他请求产生干扰。
use tracing::{span, Level};
fn main() {
let span = span!(Level::INFO, "span");
let _enter = span.enter();
// enter 后进入该 span 的上下文
// 可以记录信息到 span 中
} // 离开作用域后,_enter 被 drop,对应的 span 在此结束
以上代码是创建并使用一个 Span 最简单的方式,除此以外还有几种不同的方式
#[instrument] // tracing 会为当前函数自动创建 span ,该 span 名与函数相同,并且整个函数都在该 span 的上下文内
fn do_something() {
// some event
let span = span!(Level::INFO, "external function");
span.in_scope(|| some_external_function()); //对于无法添加 #[instrument] 的外部函数,也可以使用 in_scope 方法让其在 span 的上下文中执行
}
#[instrument] // 此方法同样对异步函数适用
async fn do_something_async() {
let future = async {
// some async code
};
let span = span!(Level::INFO, "future");
future.instrument(span).await; // 也可以在 future .await 之前将 span 附加给 future
}
// async 代码中要避免以下情况
async fn some_async_code() {
let span = span!(Level::INFO, "span");
let _enter = span.enter();
// 此处进入 span 的上下文,直到 _enter 被 drop 后才会结束
async_fn().await; // .await 时,task 可能会让出当前线程的执行权,而此时 _enter 还没有 drop,因此可能会错误的记录到其他 task 的 enent.
}
Event
Event 与日志类似,表示的是某一个时间点发生的事件,但与日志不同的是,Event 可以将信息记录到 Span 的上下文中,这样在分析数据时,可以直接查看 Span 中发生的所有事件。
use tracing::{event, info, span, Level};
fn main() {
event!(Level::INFO, "event"); // 在 span 的上下文之外记录一个 Leval 为 INFO 的 event
let span = span!(Level::INFO, "span");
let _enter = span.enter();
event!(Level::INFO, "event"); // 在 span 的上下文内记录 event
info!("something with info level"); // 也可以使用和 log 相同的形式记录 event
}
Collector
以上的示例不会有任何可见的输出,因为我们还没有配置 Collector,tracing 中所有的 Span 和 Event 都是通过 Collector 来收集的,Collector 会将 Span 和 Event 以一定的格式输出到指定的地方,比如 stdout、stderr、文件、网络等。tracing-subscriber 的 fmt 模块提供了一个 Collector ,可以方便的输出事件信息。
use tracing::info;
use tracing_subscriber;
fn main() {
// 初始化全局 Collector
tracing_subscriber::fmt::init();
info!("Hello, world!");
}
运行上面这段代码,可以在终端中看到一条 INFO 级别的事件,如果需要将 Trace 信息发送到其他地方,就要用到其他的 Collector 实现,比如 tracing-appender 这个 crate,可以将 Trace 信息输出到文件中。
在 Rust 中使用
tracing 的完整示例
use std::{thread::sleep, time::Duration};
use tracing::{debug, info, info_span, instrument};
#[instrument]
fn expensive_work(secs: u64) {
debug!("doing expensive work");
sleep(Duration::from_secs(secs));
debug!("done with expensive work");
}
fn main() {
tracing_subscriber::fmt()
// enable everything
.with_max_level(tracing::Level::TRACE)
// sets this to be the default, global collector for this application.
.init();
let span = info_span!("root");
let _enter = span.enter();
info!("some info in the root span");
expensive_work(1);
}
运行以上代码将会的到以下输出
2022-12-01T02:50:59.425475Z INFO root: tracing_example: some info in the root span
2022-12-01T02:50:59.425518Z DEBUG root:expensive_work{secs=1}: tracing_example: doing expensive work
2022-12-01T02:51:00.425722Z DEBUG root:expensive_work{secs=1}: tracing_example: done with expensive work
每个事件都已相同的格式输出,此输出模式下,与 log 的输出十分相似,
但 tracing 输出的内容多出了 Span 相关的信息。由 instrument 生成的 Span 还自动添加了函数的参数信息。下面介绍的 OpenTelemetry 和 Jaeger,还可以让我们更加直观的查看 Span 之间的时间关系。
Trace 的标准化
想要让 Trace 跨越多个服务,集成到多种不同的语言,那就必须要规定大家相互调用的规范,要遵守一套相同的协议,才能让 Trace 的数据在不同的系统中都能够正常传递,Trace 早期诞生了两种规范,分别是 OpenTracing 和 OpenCensus,后来为了规范的统一,OpenTracing 和 OpenCensus 合并成了 OpenTelemetry,现在已经成为了 Trace 的事实标准。OpenTelemetry 提供了不同语言的 SDK,可以方便的集成到不同的系统中,对于 Rust ,它提供了一系列相关的 crate 用于集成。tracing 也提供了 tracing-OpenTelemetry 用来将其收集到的信息发送到兼容 OpenTelemetry 的分布式追踪系统中。
Trace 数据的可视化分析
Jaeger 是受到 Dapper 和 OpenZipkin 启发的开源分布式跟踪系统,由 Uber 开发,现已捐赠给 CNCF。Jaeger 通过收集 Trace 数据,将其可视化展示,方便开发者分析系统的问题。下图为 Jaeger 部署的示例。

要将 Trace 数据发送给 Jaeger,需要在我们的应用中添加 jaeger-client 。OpenTelemetry 提供的 crate 中,就包括了响应的 jaeger-clinet 实现: opentelemetry-jaeger。它会将 Span 信息以 UDP 包的形式发送到 jaeger-agent,jaeger-agent 将一段时间内的数据打包分批发送到 jaeger-collector,再由 jaeger-collector 把数据存入数据库内,我们在 jaeger 的 UI 中就可以查询到这些数据。
OpenTelemetry 的仓库中也提供了以上流程的示例,我们可以直接运行这个示例,然后在 jaeger 的前端我们就可以得到下图的内容:
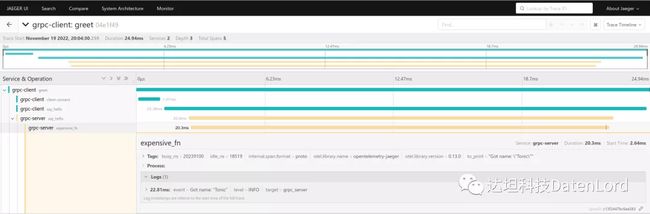
有了这些数据,开发人员就能够快速定位到请求的主要耗时部分,也能够通过其中包含的事件获取到请求内的消息记录。
总结
对于大多数同步程序,用 Log 就能够满足需求,并且使用起来也足够简单,但是一旦涉及到异步程序或其他的一些复杂情况,Log 就会变得不那么好用了,一段时间内的 Log 信息可能来自于多个不同的处理流程,难以快速方便的获取我们需要的信息,而 Trace 则能够很好的解决这个问题。
到此这篇关于Rust 语言的全链路追踪库 tracing的文章就介绍到这了,更多相关Rust 全链路追踪库 内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!