爬虫学习笔记
爬虫 2022年7月4日
-
python Python 教程 (w3school.com.cn)
-
爬虫教程 Python爬虫教程(从入门到精通) (biancheng.net)
-
教学视频(主) 2021年最新Python爬虫教程+实战项目案例(最新录制)_哔哩哔哩_bilibili
-
代码
-
代码,csdn
-
笔记,typora,markdown
总结
-
2022年7月11日 -
之前学习过一点爬虫,但当时没有学习前端之类的知识,导致学习效果很差。
-
这次学习是在我学习过前端,java后端和其他的知识又一次的想要学习爬虫
-
视频教程的老师很棒,学到很多,偏实战,很适合有编程基础的同学学习
-
祝福大家在编程的道路上,不断学习,不断进步,加油!!!
开胃案例
import urllib.request as req
url = "http://www.baidu.com"
# urlopen 进行url跳转,并获得页面源代码
resp = req.urlopen(url)
# 按照爬出的网页编码格式,进行解码,一般在网页头中可以看到编码格式。
print(resp.read().decode("utf-8"))
# 将爬出的页面保存成文件,可以点击进行访问
with open("test01.html", mode='w', encoding='utf-8') as f:
f.write(resp.read().decode("utf-8"))
-
编码格式,一般在网页源代码的头部进行定义

-
一定要进行解码,在window中的默认编码是gbk
-
网页源码:

requests
- 安装requests库

get请求
import requests
url = "https://www.sogou.com/web?query=周杰伦"
# 在此次请求如果不添加,user-agent会被拦截,此字段会标识本机为浏览器访问,信息是在浏览器中进行查找,添加进来的
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44"
}
resp = requests.get(url, headers=headers)
print('state',resp)# 打印的请求状态,200,404等
print("req", resp.text)# 打印的才是网页源代码
- user-agent字段
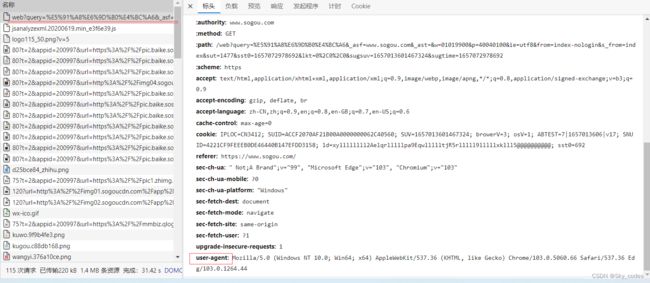
- resp.text 打印结果

post请求
百度翻译,用浏览器请求后,F12查看时,会发现真正请求是在https://fanyi.baidu.com/sug下进行,
post请求,翻译文本需要放在body中。
import requests as req
# post 请求
url = "https://fanyi.baidu.com/sug"
body_json = {
'kw': '狗'
}
resp = req.post(url, data=body_json)
print(resp.json())

- resp.json 返回结果

抓取豆瓣分类电影
import requests as req
# 抓取豆瓣分类中的电影,如科幻分类
url = "https://movie.douban.com/j/new_search_subjects"
# get请求参数的另一种写法,在调用req.get方法时传入,自动拼接
params = {
'sort': "T",
'range': [0, 10],
'tags': '',
'start': '0',
'genres': '科幻'
}
# 请求头,处理反爬的首选,先添加user-agent
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44"
}
resp = req.get(url, params=params, headers=headers)
print(resp.json())
with open("douBan.json", mode='w') as f:
f.write(str(resp.json()))
resp.close()
Fetch/XHR是页面处理异步信息的请求,ajax/axios等,信息是由此发起请求
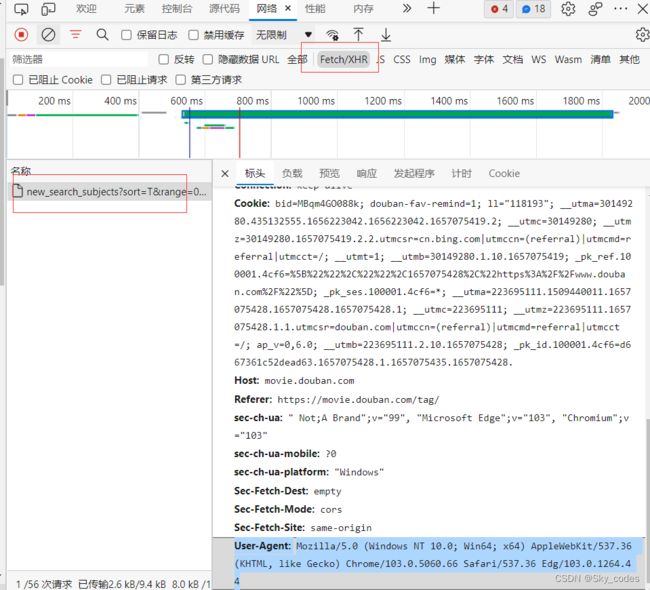
负载是本次请求携带的参数信息

预览中是返回结果
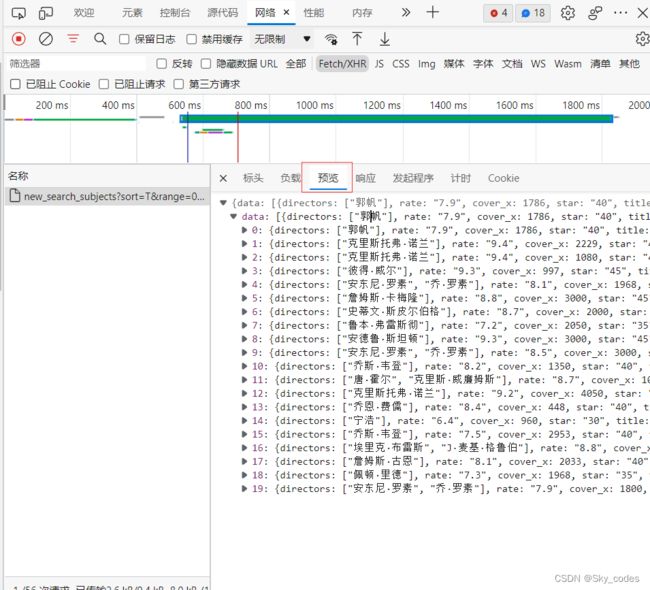
- 处理结果
![]()
正则表达式
元字符

量词
- 控制在量词前出现的元字符的个数

匹配
![]()
re模块

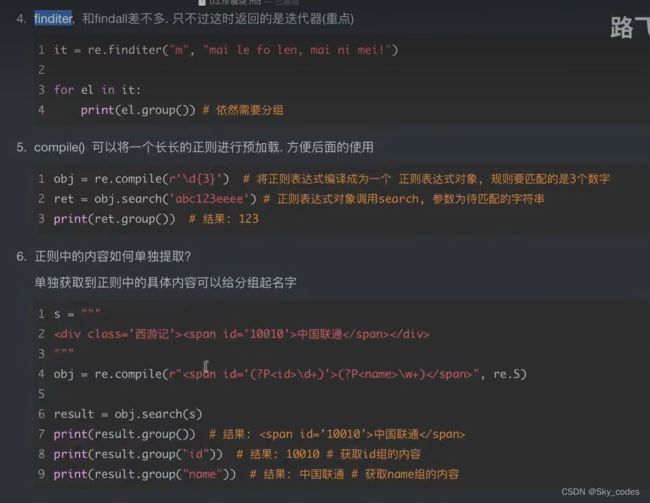
(?P<组名>)可以在匹配完成后,在迭代器中进行此组的查询,查询出需要的信息
text与content的不同
response.text和 response.content两者的区别
requests对象的get和post方法都会返回一个Response对象, 这个对象里面存的是服务器返回的所有信息,包括响应头,响应状态码等。其中返 回的网页部分会存在.content和.text 两个对象中两者区别在于,content中间存的是字节流数据 ,而text中存的是根据requests模块自己猜测的编码方式将content内容编码成 Unicode,常常我们使用requests.content输出的内容是需要解码的(因为网页上的内容是编码而成的,而在Python中字符串形式是以Unicode形式存在的,当然我们只想看到那些字符串,不想看到那些乱七八糟的字节,所以我们爬下来的东西才需要去解码)
原文链接:https://blog.csdn.net/m0_46397094/article/details/105349772
豆瓣Top250
import requests as req
import re
import csv
import time
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44"
}
def get_t250(start):
params = { # 不同的页面,循环爬取
'start': start
}
resp = req.get(url, headers=headers, params=params)
obj = re.compile(r'.*?.*?(?P.*?)'
r'.*?.*?
(?P.*?) .*?'
r'
r'.*?(?P.*?)人评价 ',
re.S)
result = obj.finditer(resp.content.decode('utf-8'))
# for it in result:
# print(it.group("movieName"))
# print(it.group("movieYear").strip())
# print(it.group("movieRate"))
# print(it.group("people"))
# 保存到csv中 newline=''写入一行后取消自动换行,不然没写入一条会多出一行空白
f = open("t250.csv", mode='a', encoding='utf-8', newline='')
cf = csv.writer(f)
for it in result:
ditc = it.groupdict()
ditc['movieYear'] = ditc['movieYear'].strip()
# print(ditc.values())
cf.writerow(ditc.values())
f.close()
print("已写入", start)
# 睡眠三秒
time.sleep(3)
if __name__ == '__main__':
for start in range(0, 10):
get_t250(start * 25)
- top250.csv文件

盗版天堂
import requests as req
import re
# 盗版天堂
url = 'https://dy.dytt8.net/index2.htm'
resp = req.get(url, verify=False) # verify=False 取消安全验证
# 查看网页中的charset为gb2312
web = resp.content.decode("gb2312")
obj = re.compile(r'.*?2022新片精品.*?(?P.*?)
',
re.S)
# 分出2022新片中的每个影片的链接地址
obj2 = re.compile(r",
re.S)
# 跳转到每个电影页面时,获取下载链接及其片名
obj3 = re.compile(r'译 名 (?P.*?)
'
r'.*?下载地址2:,
re.S)
# 将2022新片整体切出
result = obj.finditer(web)
# 保存完整的影片url
hrefs = []
# url_global = https://dy.dytt8.net
url_global = url.replace('/index2.htm', '')
for it in result:
movie2022 = it.group("movie")
result2 = obj2.finditer(movie2022)
for it2 in result2:
mto = it2.group('mto')
mto = url_global + mto
hrefs.append(mto)
# 2022年7月6日 第一个不是电影链接,移除
hrefs.pop(0)
for href in hrefs:
# print(href)
resp = req.get(href, verify=False)
resp.encoding = 'gb2312'
web = resp.text
result = obj3.finditer(web)
for it in result:
print(it.group("name"))
print(it.group("down_url"))
- 结果,
2022年7月6日,网页下载链接是跳到另外一个网站,不是磁力链接,不过无伤大雅。

-
注 re.S是也匹配换行。
在字符串a中,包含换行符\n,在这种情况下:
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始。
而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
-
除了使用requests.content.decode("XXX"),也可以使用requests.encoding="XXX"配合resp.text 实现解码。
Bs4解析
-
安装bs4
conda activate paC # 切换到自己的虚拟环境
pip install bs4 # 安装bs4

优美图库
- 【优美图库】美女图片大全_性感美图_好看的图片大全 (umei.cc)
import requests as req
from bs4 import BeautifulSoup
import time
# 优美图库
url = 'https://www.umei.cc/bizhitupian/xiaoqingxinbizhi/'
resp = req.get(url)
# 网页编码为utf-8
resp.encoding = 'utf-8'
source = resp.text
# 将主页面传给bs4
main_page = BeautifulSoup(source, 'html.parser')
# 寻找需要的特定的标签 find
# 包含需要图片链接的div
div = main_page.find("div", class_="swiper-wrapper after")
# 获取链接列表,方便提取出子页面链接
a_list = div.find_all("a")
# href保存的不是完整地址,需要拼接
# 可以在浏览器中进行比较,发现需要拼接哪些
son_head_url = "https://www.umei.cc/"
for i, a in enumerate(a_list):
# get方法可以拿到属性值 href就是a标签的一个属性值
# 得到子页面的链接
son_url = son_head_url + a.get("href")
resp = req.get(son_url)
resp.encoding = 'utf-8'
source = resp.text
son_page = BeautifulSoup(source, 'html.parser')
# 得到图片的下载地址
img_url = son_page.find('section', class_='img-content') \
.find('img') \
.get('src')
# 访问图片地址,返回的只要图片本身的资源,保存即可
img = req.get(img_url)
# content 得到的二进制数据,用.jpg保存到本地
# wb是以二进制写
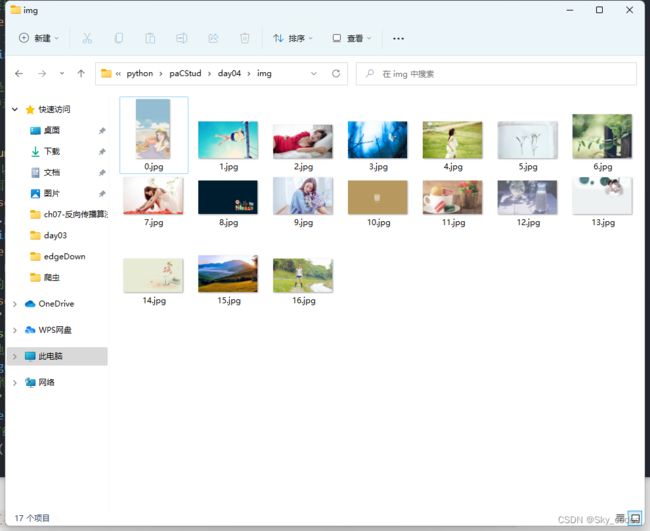
with open('./img/' + str(i) + '.jpg', mode='wb') as f:
f.write(img.content)
print('已下载', i)
time.sleep(2)
-
这些网站一直在更新维护,爬取时可能会有所不同,要观察网页源码及其规律,进行灵活的更换信息。
-
爬取结果
Xpath解析
-
安装lxml模块
-
lxml 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档
-
教程 lxml 库教程_w3cschool
conda activate paC
pip install lxml

- 常用表达式
截取自w3c

猪八戒
2022年7月7日 爬取地址 【IT行业行业-】项目外包_方案定制_专业服务众包平台-猪八戒网 (zbj.com)
import requests as req
from lxml import etree
# 猪八戒
url = 'https://task.zbj.com/hall/list/h1'
resp = req.get(url)
resp.encoding = 'utf-8'
# print(resp.text)
# 解析
html = etree.HTML(resp.text)
result = html.xpath('/html/body/div[1]/div[6]/div/div[2]/div[2]/div/div[1]/div')
for r in result:
print('名称', r.xpath('./div[1]/h4/a/text()')[0])
print('地址', r.xpath('./div[3]/span[4]/text()')[0])
# print(r.xpath('./div[4]/span/@class')[0])# @class 是获取标签里的属性值,@href等
print('价格', str(r.xpath('./div[4]/span/text()')[0]).split('¥')[1])
- 获取xpath路径,可以在浏览器中直接复制即可,相对路径去掉前面的多余部分即可。

Cookie信息
7k小说网
-
网址 我的书架 -17K小说网
-
2022年7月7日 无法找到明文登录的地址

-
直接使用浏览器登录后生成的cookie进行登录
import requests as req
# 17k小说
url = 'https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919'
headers = {
'Accept': '*/*',
'Cookie': 'GUID=609c1c07-ed71-4ba6-858c-9de4c1b07a2b; sajssdk_2015_cross_new_user=1; c_channel=0; c_csc=web; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F08%252F28%252F45%252F97254528.jpg-88x88%253Fv%253D1657197644000%26id%3D97254528%26nickname%3D%25E4%25B9%25A6%25E5%258F%258BeC7wcqJb4%26e%3D1672749993%26s%3D8c82b9b4468bbcb4; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2297254528%22%2C%22%24device_id%22%3A%22181d8a144baddc-0990c93200813e-4a617f5c-1328640-181d8a144bb1563%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E5%BC%95%E8%8D%90%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fgraph.qq.com%2F%22%2C%22%24latest_referrer_host%22%3A%22graph.qq.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%22609c1c07-ed71-4ba6-858c-9de4c1b07a2b%22%7D',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44'
}
resp = req.get(url, headers=headers)
resp.encoding = 'utf-8'
print(resp.json())
- 结果

data、headers、params
data: 是对于使用post进行请求时携带的信息
headers: 是用于携带user-agent、cookie等信息,是响应头携带的认证信息,get post请求均可使用
params: 是get请求需要携带的信息,一般是拼接在url后,也可以使用params进行传递
梨视频
- 地址 梨视频官网-做最好看的资讯短视频-Pear Video
- 反爬链
Referer说白了就是记录你是从哪一个网页跳转过来的,存放在请求头headers中
import requests as req
# 梨视频
url = 'https://www.pearvideo.com/video_1765348'
# 获取视频id
vid = url.split('_')[1]
# 是在xhr中,异步请求
v_url = 'https://www.pearvideo.com/videoStatus.jsp?contId=1765348&mrd=0.10915277937466228'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36 Edg/103.0.1264.44',
# 反爬链,说白了就是记录你是从哪一个网页跳转过来的
# 与上面的url一致
'Referer': url # 'https://www.pearvideo.com/video_1765348'
}
resp = req.get(v_url, headers=headers)
resp.encoding = 'utf-8'
# 得到是json数据,是视频相关的信息
# print(resp.json())
# 得到json数据中,携带的视频原链接,
# 此链接并不能直接使用,
# 观察页面浏览器最终的源代码,定位到video标签,会发现两者的不同
# json中的:https://video.pearvideo.com/mp4/short/20220614/1657245404127-15895948-hd.mp4
# 源码中的:https://video.pearvideo.com/mp4/short/20220614/cont-1765348-15895948-hd.mp4
# 要以源码中的为准,将json中的重新拼接得到源码中的地址形式
# json中与源码不同的信息可以在json中找到,目前名称为'systemTime': '1657245404127'
# 而源码中,cont-后面的是视频的id,在上面已经提取
systemTime = str(resp.json()['systemTime'])
srcUrl = str(resp.json()['videoInfo']['videos']['srcUrl'])
v_srcUrl = srcUrl.replace(systemTime, 'cont-' + (str(vid)))
# 可以打印出地址,看能否访问
print(v_srcUrl)
# 保存视频 以二进制写入到本地
with open('video/lsp.mp4', mode='wb') as f:
f.write(req.get(v_srcUrl).content)
- 爬取结果

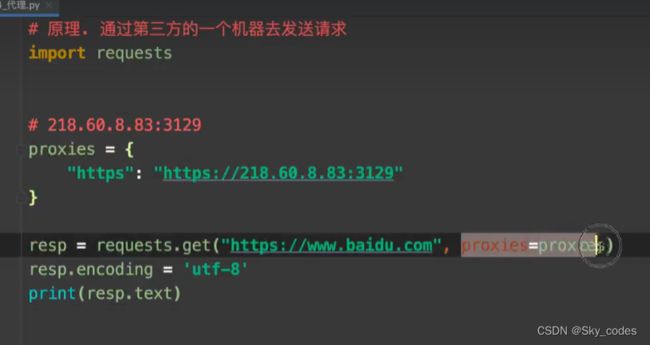
代理
- 要找到可以进行代理的ip
- 代理ip网站 站大爷 - 企业级高品质Http代理IP_Socks5代理服务器_免费代理IP (zdaye.com)
网易云评论
pycrypyto安装失败- 安装
pycrypytodome,加密方式
conda activate paC
pip install pycrypytodome

- 算了,等我再看看,现在可以直接得到评论,在源码里,没有加密
2022年7月8日。
多线程
from threading import Thread
# 方法1
def fun(id):
for i in range(100):
print('fun', id, i)
if __name__ == '__main__':
# 参数不能直接在target=fun()传递,借助args,格式是元组
t1 = Thread(target=fun, args=('t1',))
t2 = Thread(target=fun, args=('t2',))
t1.start()
t2.start()
for i in range(100):
print('main', i)
# ==================================================
from threading import Thread
# 方法2
class D(Thread):
def __init__(self, id):
super().__init__()
self.id = id
def run(self):
for i in range(100):
print('t', self.id, i)
if __name__ == '__main__':
t1 = D(1)
t2 = D(2)
t1.start()
t2.start()
线程池
# 线程池
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def fn(name):
for i in range(100):
print(name, i)
if __name__ == "__main__":
# 创建线程池
with ThreadPoolExecutor(50) as t:
for i in range(100):
t.submit(fn, name=f'线程{i}')
print("线程全部完成")
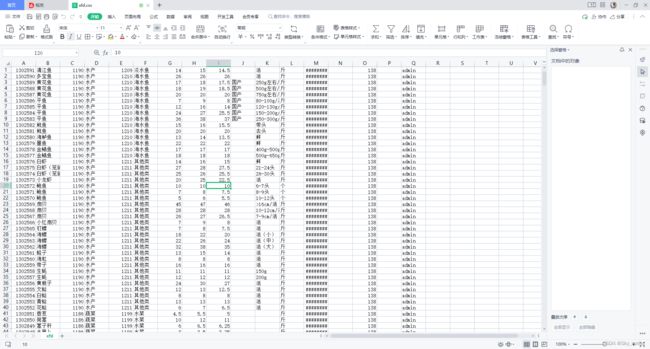
新发地-线程池
- 地址 新发地-价格行情 (xinfadi.com.cn)
open(‘xfd.csv’, mode=‘w’, encoding=‘utf-8’, newline=‘’)
newline 参数设置为’',是为了csv文件写入一行时不会产生一行空白行
import requests as req
import csv
import time
from concurrent.futures import ThreadPoolExecutor
# 北京新发地
# 写入csv文件中
f = open('xfd.csv', mode='w', encoding='utf-8', newline='')
cf = csv.writer(f)
def download(current):
# 相关变化参数,设置在函数内部,不然会被线程公用同一时间读取的参数一致时,导致下载数据重复
url = 'http://www.xinfadi.com.cn/getPriceData.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49'
}
params = {
'limit': 20,
'current': current,
'pubDateStartTime': '',
'pubDateEndTime': '',
'prodPcatid': '',
'prodCatid': '',
'prodName': ''
}
resp = req.get(url, headers=headers, params=params)
resp.encoding = 'utf-8'
one_page = resp.json()['list']
for one in one_page:
cf.writerow(one.values())
print("已完成", params['current'])
time.sleep(1)
if __name__ == '__main__':
# for i in range(2):
# params['current'] = i+1
# download(url, headers, params)
# 线程池
with ThreadPoolExecutor(50) as t:
for i in range(100):
# 页码从1开始
current = i + 1
args = [current]
t.submit(lambda p: download(*p), args)
- params位置

- 结果
协程
- 安装
conda activate paC
pip install asyncio
import asyncio
# 异步协程
async def f(url):
# 爬取请求
await asyncio.sleep(2) # 网络请求
print('hello', str(url))
async def main():
urls = [
'www.baidu.com',
'www.bilibili.com'
]
tasks = []
for url in urls:
t = f(url)
tasks.append(t)
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
aiohttp
-
异步requests
-
安装
conda activate paC
pip install aiohttp
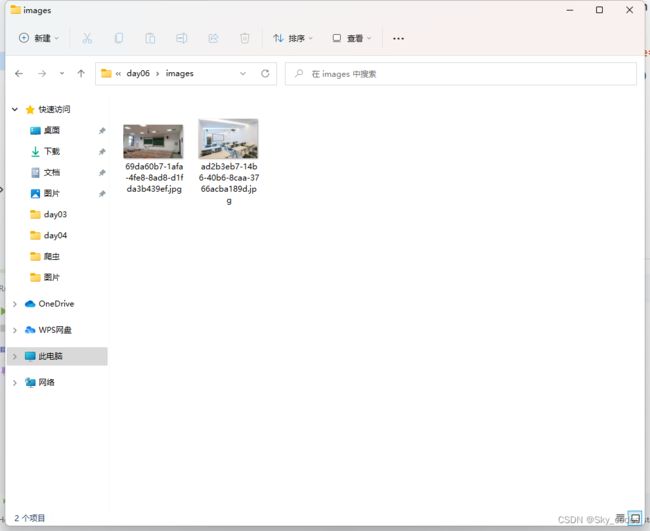
- 地址 教室管理系统
import aiohttp
import asyncio
urls = [
# 自己的毕设网站
'http://106.14.219.106:20918/images/69da60b7-1afa-4fe8-8ad8-d1fda3b439ef.jpg',
'http://106.14.219.106:20918/images/ad2b3eb7-14b6-40b6-8caa-3766acba189d.jpg'
]
async def download(url):
name = url.rsplit(r'/', 1)[1]
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
with open('images/' + str(name), mode='wb') as f:
f.write(await resp.content.read()) # 此处的resp.content.read()与之前的resp.content()一样
async def main():
tasks = []
for url in urls:
tasks.append(download(url))
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
- 结果
西游记
-
地址 西游记_百度小说 (baidu.com)
-
获取全本小说
-
安装aiofiles
conda activate paC
pip install aiofiles
-
json.dumps()的作用 将字典转化为带双引号的json格式

-
代码
import requests as req
import asyncio
import aiohttp
import aiofiles
import json
# 西游记
async def download(url, gid, index, info):
data = {
'book_id': str(gid),
'cid': f'{gid}|{info["cid"]}',
'need_book': 1
}
# 转化为带双引号的json格式
data = json.dumps(data)
url = url + data
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
content = await resp.json()
async with aiofiles.open('novel/' + str(index + 1) + info['title'] + '.txt',
mode='w',
encoding='utf-8')as f:
await f.write(content['data']['novel']['content'])
print('已完成', info['title'])
async def main(gid):
# 拿到章节信息
url = 'https://dushu.baidu.com/api/pc/getCatalog?data={"book_id"' + ':"' + str(gid) + '"}'
resp = req.get(url)
resp.encoding = 'utf-8'
# 得到章节名和章节cid,cid下载链接需要使用
catalogue = resp.json()['data']['novel']['items']
tasks = []
cUrl = 'https://dushu.baidu.com/api/pc/getChapterContent?data='
for index, Info in enumerate(catalogue):
tasks.append(download(cUrl, gid, index, Info))
await asyncio.wait(tasks)
if __name__ == '__main__':
# asyncio.run(main(4306063500))
# 解决 RuntimeError: Event loop is closed
loop = asyncio.get_event_loop()
loop.run_until_complete(main(4306063500))
- 结果

- 其实不用这种也是可以的,线程池、最初使用单线程循环也是可以完成的
- 其实对于爬取之前学习的就可以完成,这里是优化爬取速度而已。
91看剧
简单版
-
地址 正在播放一起同过窗 第三季第01集-一起同过窗 第三季详情介绍-一起同过窗 第三季在线观看-一起同过窗 第三季迅雷下载 - 91看剧网 (48ys.top)
-
现在(2022年7月10日)需要读取两次m3u8文件才可以得到真正的.ts的下载地址,和教学视频中略有不同 。
-
代码
import requests as req
import re
import time
url = 'https://play.xn--55q3u83bh7en9loko5ta801klezbe5aw98bnjblz1e.com/index.php?url=https://cdn7.caoliqi.com:65/20220708/3pwt0JO3/index.m3u8'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49"
}
resp = req.get(url, headers=headers)
resp.encoding = 'utf-8'
# 需要的链接在script里,使用re正则
# 注意源码中url两侧的单引号,cao
obj = re.compile(r"url: '(?P.*?)',"
, re.S)
result = obj.search(resp.text)
m3u8_url = result.group('m3u8_url')
resp.close()
print('url', result['m3u8_url'])
resp = req.get(m3u8_url, headers=headers, verify=False)
# 写入存放m3u8真正地址的文件
with open('really.m3u8', mode='wb') as f:
f.write(resp.content)
with open('really.m3u8', mode='r') as f:
# 得到真正m3u8的地址,和之前不同了
content = f.readlines()
# print(content[2]) 地址 /20220708/3pwt0JO3/1215kb/hls/index.m3u8
# 得到真正的m3u8完整地址
# split 得到https://cdn7.caoliqi.com:65/20220708/3pwt0JO3/index.m3u8
# rsplit 得到https://cdn7.caoliqi.com:65
# +str 得到https://cdn7.caoliqi.com:65/20220708/3pwt0JO3/1215kb/hls/index.m3u8
m3u8_url = url.split('=')[1] \
.rsplit('/', 3)[0] \
+ str(content[2])
resp.close()
print('m3u8_url', m3u8_url.strip())
# 得到影片真正完整的m3u8
# 记得去除多余空格,我是中招了,做了也不费劲
resp = req.get(m3u8_url.strip(), headers=headers, verify=False)
# print(resp.content)
with open('easy.m3u8', mode='wb') as f:
f.write(resp.content)
resp.close()
# 查看浏览器的抓包中的.ts文件,可以看到现在的url是需要进行拼接
# 请求 URL: https://cdn7.caoliqi.com:65/20220708/3pwt0JO3/1215kb/hls/qjMM5WuJ.ts
# 拼接所需要的是https://cdn7.caoliqi.com:65 网站前缀
# 和上面得到m3u8_url前两步相同
pre_url = url.split('=')[1].rsplit('/', 3)[0]
with open('easy.m3u8', 'r') as f:
index = 0
for line in f:
line = line.strip()
# 不需要井号开头的
if (line.startswith("#")):
continue
# 完整.ts的url
down_url = pre_url + line
resp = req.get(down_url, headers=headers)
with open(f'./video/easy/{index + 1}.ts', mode='wb') as f2:
f2.write(resp.content)
print(f"已完成{index + 1}")
index = index + 1
time.sleep(0.5)
- 结果

- 拼接 可以的ok
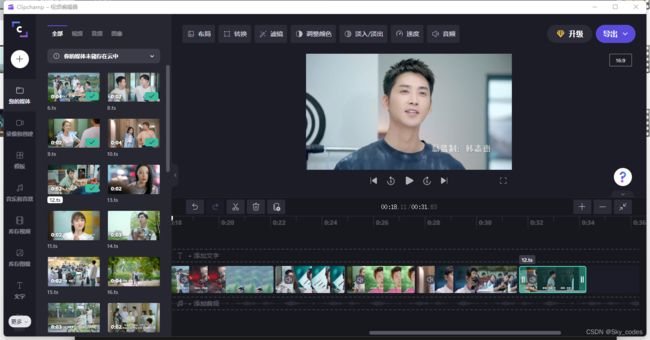
- 注,可以从主页面跳到上面的url中
- (http://48ys.top/vodplay/5E7JJJJN-1-1.html) —> https://play.xn–55q3u83bh7en9loko5ta801klezbe5aw98bnjblz1e.com/index.php?url=https://cdn7.caoliqi.com:65/20220708/3pwt0JO3/index.m3u8
- 写的时候没有找到
- 下午才看到,藏得比较深,不修改代码了
- 也不难,可以用之前学习的正则,ba4或者Xpath都可以从url提取出这个需要的链接
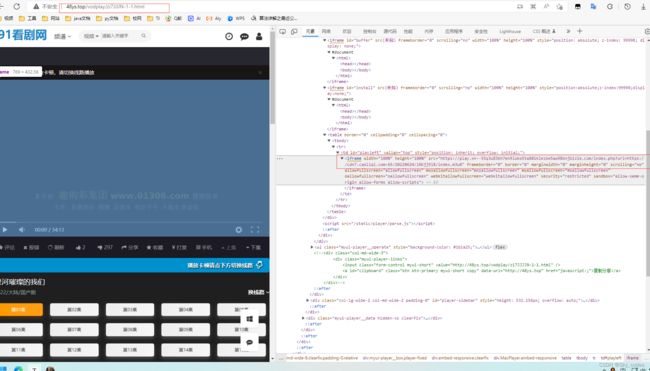
协程版
- 和上面同一个网址
import requests as req
import re
import time
import asyncio
import aiofiles
import aiohttp
url = 'https://play.xn--55q3u83bh7en9loko5ta801klezbe5aw98bnjblz1e.com/index.php?url=https://cdn7.caoliqi.com:65/20220708/3pwt0JO3/index.m3u8'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49"
}
resp = req.get(url, headers=headers)
resp.encoding = 'utf-8'
obj = re.compile(r"url: '(?P.*?)',"
, re.S)
result = obj.search(resp.text)
m3u8_url = result.group('m3u8_url')
resp.close()
print('url', result['m3u8_url'])
resp = req.get(m3u8_url, headers=headers, verify=False)
with open('really.m3u8', mode='wb') as f:
f.write(resp.content)
with open('really.m3u8', mode='r') as f:
content = f.readlines()
m3u8_url = url.split('=')[1] \
.rsplit('/', 3)[0] \
+ str(content[2])
resp.close()
print('m3u8_url', m3u8_url.strip())
resp = req.get(m3u8_url.strip(), headers=headers, verify=False)
# print(resp.content)
with open('xc.m3u8', mode='wb') as f:
f.write(resp.content)
resp.close()
pre_url = url.split('=')[1].rsplit('/', 3)[0]
# 协程
async def download(session, url, name):
async with session.get(url) as resp:
async with aiofiles.open('video/xc/' + name, mode='wb') as f:
ts = await resp.content.read()
await f.write(ts)
print('已完成', name)
async def main():
tasks = []
async with aiohttp.ClientSession() as session:
async with aiofiles.open('xc.m3u8', mode='r') as f:
async for line in f:
line = line.strip()
# 不需要井号开头的
if (line.startswith("#")):
continue
# 完整.ts的url
down_url = pre_url + line
name = str(line).rsplit('/', 1)[1]
task = asyncio.create_task(download(session, down_url, name))
tasks.append(task)
await asyncio.wait(tasks)
if __name__ == '__main__':
# asyncio.run(main())
# 解决 RuntimeError: Event loop is closed
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
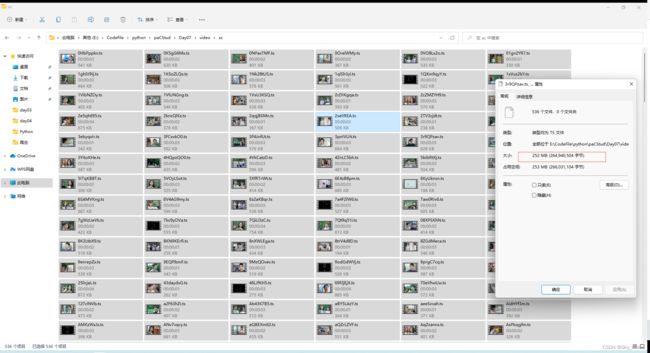
- 家里的网速跑满了!!

- 结果
- 踩坑
- 这两句要分开写,并且都要加上await,如果写成
await f.write(resp.content.read())会报错TypeError: a bytes-like object is required, not ‘coroutine’
ts = await resp.content.read()
await f.write(ts)
合并
- 使用windows命令行的方式
- 需要对下载数据进行编号排序,方便批处理
- 命令
copy/b *.ts tv.mp4
2022年7月10日 视频没有加密,直接合并

- 代码,进行编号命名,不使用ts命名,
- 还是上面协程版的代码,只是添加了命名方式
import requests as req
import re
import time
import asyncio
import aiofiles
import aiohttp
import os
url = 'https://play.xn--55q3u83bh7en9loko5ta801klezbe5aw98bnjblz1e.com/index.php?url=https://cdn7.caoliqi.com:65/20220708/3pwt0JO3/index.m3u8'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.49"
}
resp = req.get(url, headers=headers)
resp.encoding = 'utf-8'
obj = re.compile(r"url: '(?P.*?)',"
, re.S)
result = obj.search(resp.text)
m3u8_url = result.group('m3u8_url')
resp.close()
print('url', result['m3u8_url'])
resp = req.get(m3u8_url, headers=headers, verify=False)
with open('really.m3u8', mode='wb') as f:
f.write(resp.content)
with open('really.m3u8', mode='r') as f:
content = f.readlines()
m3u8_url = url.split('=')[1] \
.rsplit('/', 3)[0] \
+ str(content[2])
resp.close()
print('m3u8_url', m3u8_url.strip())
resp = req.get(m3u8_url.strip(), headers=headers, verify=False)
# print(resp.content)
with open('xc.m3u8', mode='wb') as f:
f.write(resp.content)
resp.close()
pre_url = url.split('=')[1].rsplit('/', 3)[0]
# 协程
async def get_name(name):
if name < 10:
return '00' + str(name) + '.ts'
if name < 100:
return '0' + str(name) + '.ts'
return str(name) + '.ts'
async def download(session, url, name):
async with session.get(url) as resp:
name = await get_name(name)
async with aiofiles.open('video/xc/' + name, mode='wb') as f:
ts = await resp.content.read()
await f.write(ts)
print('已完成', name)
async def main():
tasks = []
index = 0
async with aiohttp.ClientSession() as session:
async with aiofiles.open('xc.m3u8', mode='r') as f:
async for line in f:
line = line.strip()
# 不需要井号开头的
if (line.startswith("#")):
continue
# 完整.ts的url
down_url = pre_url + line
# name = str(line).rsplit('/', 1)[1]
index = index + 1
name = index
task = asyncio.create_task(download(session, down_url, name))
tasks.append(task)
await asyncio.wait(tasks)
if __name__ == '__main__':
# asyncio.run(main())
# 解决 RuntimeError: Event loop is closed
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
- 结果

selenium
- 安装 selenium
conda activate paC
pip install selenium

-
下载浏览器驱动
- 链接 Selenium之浏览器驱动下载和配置使用_Nonevx的博客-CSDN博客_selenium浏览器驱动
- 下载完成后解压,将里面的exe文件copy到使用的python编译环境下,比如我一直使用的paC,
- 我是在anaconda里建立的paC环境,所在目录在
D:\Python\Anaconda3\envs\paC和使用的python.exe在同样目录下即可,就不需要添加环境变量了
- 不要修改解压后的exe文件名
-
代码
from selenium.webdriver import Edge
# 创建浏览器对象
web = Edge()
web.get('http://www.bilibili.com')
print(web.title)
- 结果

爬抓钩
-
地址 互联网求职招聘找工作-上拉勾招聘-专业的互联网求职招聘网站 (lagou.com)
-
代码,xpath路径要灵活应变
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# 抓拉钩
url = 'https://www.lagou.com/'
web = Edge()
web.get(url)
# 查找某个元素
el = web.find_element(By.XPATH, '//*[@id="changeCityBox"]/p[1]/a')
el.click()
# 等待浏览器跳转
time.sleep(1)
# 获取输入框
el = web.find_element(By.XPATH, '//*[@id="search_input"]')
# 输入java 并按下enter
el.send_keys("java", Keys.ENTER)
# 获取列表内容
els = web.find_elements(By.XPATH, '//*[@id="jobList"]/div[1]/div')
for el in els:
name = el.find_element(By.XPATH, './div[1]/div[1]/div/a').text
money = el.find_element(By.XPATH, './div[1]/div[1]/div[2]/span').text
company = el.find_element(By.XPATH, './div[1]/div[2]/div[1]/a').text
print(company, name, money)
- 结果
申通排前面,xdm不用我多说了吧

跳转页面
-
还是抓拉钩网
-
代码
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
# 跳转窗口
url = 'https://www.lagou.com/'
web = Edge()
web.get(url)
# 跳转到全国
web.find_element(By.XPATH, '//*[@id="changeCityBox"]/p[1]/a').click()
time.sleep(1)
# 输入java,并跳转
web.find_element(By.XPATH, '//*[@id="search_input"]').send_keys("java", Keys.ENTER)
time.sleep(0.5)
# 第一条信息,跳转
web.find_element(By.XPATH, '//*[@id="jobList"]/div[1]/div[1]/div[1]/div[1]/div[1]/a').click()
time.sleep(1)
# 会出现新窗口,跳转到新窗口,-1代表最后出现的窗口
web.switch_to.window(web.window_handles[-1])
# 获取完整的职业描述
desc = web.find_element(By.XPATH, '//*[@id="job_detail"]/dd[2]/div').text
print(desc)
# 关闭当前窗口
web.close()
# 回到列表信息之前的窗口
web.switch_to.window(web.window_handles[0])
# 打印岗位名称信息
print(
web.find_element(By.XPATH,
'/html/body/div/div[1]/div/div[2]/div[3]/div/div[1]/div[1]/div[1]/div[1]/div[1]/a')
.text)
- 结果

iframe

艺恩年度票房排行
-
地址 艺恩-数据智能服务商_年度票房 (endata.com.cn)
-
下拉框、无头浏览器(不显示浏览器界面)
-
代码
from selenium.webdriver import Edge
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.select import Select
import time
# 设置为不跳出浏览器界面
opt = Options()
opt.add_argument('--headless')
opt.add_argument('--disable-gpu')
# 艺恩年度票房
url = 'https://www.endata.com.cn/BoxOffice/BO/Year/index.html'
web = Edge(options=opt)
web.get(url)
# 定位到下拉框
select = web.find_element(By.XPATH, '//*[@id="OptionDate"]')
# 包装成下拉菜单,以便于下面进行遍历循环
select = Select(select)
# 选择下拉中的每个选项,
# 并取出对应年份的年度票房信息
for index in range(len(select.options)):
# 通过索引获取
select.select_by_index(index)
# 通过下拉菜单中的每项option中的value取
# select.select_by_value()
time.sleep(2)
# 得到整个票房table
table = web.find_element(By.XPATH, '//*[@id="TableList"]/table')
print(table.text)
print("========================================================")
web.close()
- 结果

web.page_source 获取js、ajax渲染后源代码
超级鹰 验证码
-
地址 超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大 (chaojiying.com)
-
官方案例测试,从官网下载python的demo,修改里面的账号、密码、软件号
-
结果

超级鹰干超级鹰
-
超级鹰登录时,有验证码,练手
-
地址 用户登录-超级鹰验证码识别代答题平台 (chaojiying.com)
-
如果导包使用超级鹰,登录后,会闪退,但是把代码粘贴到和自己编写代码一起,就没有这个问题
-
代码
from selenium.webdriver import Edge
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import requests
from hashlib import md5
##############超级鹰代码########################
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
headers=self.headers)
return r.json()
def PostPic_base64(self, base64_str, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
'file_base64': base64_str
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
'''自己编写的代码'''
# 登录超级鹰
url = 'https://www.chaojiying.com/user/login/'
web = Edge()
web.get(url)
# 获取验证码图片
img = web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/div/img').screenshot_as_png
cjy = Chaojiying_Client('xxxxxx', 'xxxxxxx', 'xxxxxxx')
# 1902 是超级鹰设置的验证码识别级别,官网有
# 返回的是字典
# 如 {'err_no': 0, 'err_str': 'OK', 'pic_id': '6183315380917750001', 'pic_str': '7261', 'md5': '9e3c3e61269be7091c01e983aae746f1'}
verify_data = cjy.PostPic(img, 1902)
verify_code = verify_data['pic_str']
# 输入登录信息
# 账号
web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input').send_keys("xxxxxxx")
# 密码
web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input').send_keys("xxxxxx")
# 验证码
web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input').send_keys(verify_code)
# 为了看到登录信息填写完成的全过程,等待
time.sleep(5)
# 登录
web.find_element(By.XPATH, '/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input').click()
12306 无
-
地址 中国铁路12306
-
官方不采用验证码登录了,算了。。。