机器人强化学习——Data-Efficient Hierarchical Reinforcement Learning
1 简介
以前的分层强化学习在一个学习的嵌入空间中表示goal和reward,本文直接使用原始形式的观测数据作为goal。
并且以前的方法使用on-policy学习 生成目标状态,效率低。
离线学习面临的问题:
(1)off-policy算法不稳定
(2)在离线数据中,相同的高维goal不一定对应相同的低维action。具体解释在后面
针对第二个问题,本文提出 off-policy correction。
1.1 高维控制器如何训练?goal标签如何选取?
使用DDPG,goal作为高维控制器的action,由强化学习得到,不用标签。
2 方法
任务场景:四足爬行机器人走到指定的位置。
2.1 低维控制器
方法:off-policy DDPG,唯一的改动是将goal加进policy和Q-function的输入。
reward:在状态 s t s_t st执行action后的奖励为 − ∣ ∣ s t + g t − s t + 1 ∣ ∣ 2 -||s_t+g_t-s_{t+1}||_2 −∣∣st+gt−st+1∣∣2,即 s t + 1 s_{t+1} st+1离目标状态越远,reward越小。
state:机器人base和每个腿足关节的位置和旋转、当前时间步 t t t(作用是什么?)。
action:各关节扭矩。
2.2 高维控制器
本文采用状态的变化值作为高维控制器goal,本质上,goal也相当于action,只不过比低维控制器输出的action更大,从而将高维控制器也建模为强化学习agent,并使用。。。方法进行训练。
与本文不同,李飞飞组的工作将goal就设置为state,将高维控制器建模为
生成模型。
方法:和低维控制器一样,都是DDPG,目标位置与当前状态都输入网络。
action:状态变化
state:当前状态
reward:与低维控制器不同,高维控制器的reward由环境提供,即agent base当前位置与目标位置的L2距离。
为什么高维控制器的reward不是低维控制器reward的累加,而是L2距离的累加?
低维控制器的reward除了包含agent base的位置偏差,还包含base的速度偏差、各关节的位置和速度偏差(就是所有状态)。
低维控制器的目的使agent的状态与目标状态越近越好,而高维控制器只要求agent base位置与target位置越近越好,其他不关心。
用于训练高维控制器的经验轨迹: ( s t , g t , ∑ R t : t + c − 1 , s t + c ) (s_t,g_t,\sum R_{t:t+c-1},s_{t+c}) (st,gt,∑Rt:t+c−1,st+c),其中 R R R和 s t + c s_{t+c} st+c由不同时刻的低维控制器产生。
off-policy训练问题:with 同样的goal g t g_t gt,过去时刻的low控制器和现在的low控制器的行为是不一样的,高维控制器的action是由低维控制器去执行,所以导致相同的st和gt,会产生不同的R和 s t + c s_{t+c} st+c,导致训练标签混乱。
高维控制器和低维控制器是联合迭代训练的,最新的高维和低维控制器又与环境交互产生经验数据,保存在buffer中进行off-policy训练。
与本文不同,李飞飞组的工作将高维和低维控制器单独训练。
off-policy correction:对于以前的高维经验轨迹,修改 g t g_t gt为 g t ~ \tilde{g_t} gt~, g t ~ \tilde{g_t} gt~为最可能使最新的低维控制器产生此高维轨迹中的低维action序列,即 R R R和 s t + c s_{t+c} st+c。优化目标为最大化如下概率:
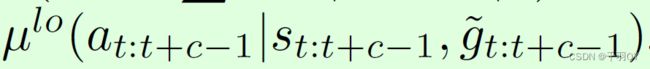

其中, μ l o \mu^{lo} μlo为低维策略,即DDPG的actor。
选10个候选goal,计算其中使概率最大的goal作为 g t ~ \tilde{g_t} gt~:原始 g t g_t gt, s t + c − s t s_{t+c}-s_t st+c−st,另外8个在均值为 s t + c − s t s_{t+c}-s_t st+c−st、标准差为的高斯分布中随机采样8个、
问题的关键在于,在 s t s_t st下执行 g t g_t gt,低维控制器的行为要保持一致,即使经过off-policy correction,以前的经验数据与 g t ~ \tilde{g_t} gt~也不一定完全对应。
3 实验
3.1 与baselines对比
本文结果最好,详细看论文
3.2 消融实验

横轴是训练了多少百万次,第一个图的纵轴是平均奖励,后面图的纵轴是平均成功率。
验证了以下四部分对方法的贡献:
(1)HER:Hindsight Experience Replay
该方法用来增加样本数量,缓解奖励稀疏问题。
实验结果表明,该方法可以加速网络学习,但越到后面效果越不好。
(2)预训练
针对相同的goal可能对应不同的低维action的问题,不使用上文提高的off-policy correction,而是使用预训练。
预训练:先在简单场景中训练低维控制器,然后冻住参数,再单独训练高维控制器。
结果表明,预训练能提高简单场景的性能,在复杂场景中性能不好。
难道不是因为训练低维控制器的样本太简单?
(3)不使用off-policy correction
在简单场景中影响不大,复杂场景中性能下降较多,
(4)不使用分层强化学习
效果很差。