音视频+人脸识别实战项目规划!
前言:
大家好,关注我的老铁都知道,我还没真正意义上的给大家分享过自己的实战项目,所以这期文章,真正给大家分享一下后面我准备用心做的一个实战项目:音视频+人脸识别实战开发,里面目前基本会用到ffmpeg、opencv、sqlite3等相关基础知识,还会利用到虹软的sdk,目前整个项目已经可以基本可以跑了,基本的框架如下:
本项目核心是在Linux平台上利用摄像头采集人脸,并进行人脸识别。这个项目使用的是FFMPEG+OPENCV+虹软框架完成。FFMPEG的主要工作是负责采集摄像头的数据并把摄像头数据发送给opencv。Opencv的主要工作则是把摄像头数据转换成矩阵数据。虹软的主要功能则是利用Opencv的数据进行数据检测和识别并且和人脸数据库进行比较,如果识别成功则显示这个人的姓名,并把数据显示出来!
上面是我们现在已经实现的一部分功能(暂时是一个非常简单的demo,代码量目前不多!),后期会把这个移植到rk、hi等芯片平台上去,同时我们会在这些平台上进行做扩展功能,比如:
1、瑞芯微人脸识别项目(通过瑞芯微API进行视频采集并进行人脸识别,并输出到设备上)
2、瑞芯微目标识别项目(通过瑞芯微API进行视频采集并进行目标识别,并输出到设备上)
3、瑞芯微音视频推流项目(通过瑞芯微API进行音视频的采集并编码并结合FFMPEG推流到RTMP服务器上面)
在海思平台上也是类似的,这个我会做扩展,只是对应的api不一样而已;其实上面的不管是人脸识别还是物体识别,这块我在自己的公司实际产品里面,有搞过一部分和接触过一部分adas、dms、bsd这个也是专门做识别的,主要是为了纠正驾驶员的不良驾驶行为,然后采用了第三方训练好的算法模型,这里面和咱们这个,涉及到音视频的东西几乎很少。我们这个可以接触到大量的音视频的东西,甚至可以在opencv这块自己可以去加深扩展,这个就根据需求去大开脑洞了。
这里也说一下,带大家做这个实战项目,一方面可以给大家在简历上可以有项目可以写,特别是在校生即将毕业找工作的,还有就是把我们平时学习的音视频理论知识,真正可以用到项目当中去,加强锻炼和理解!
好了,这里就先说这么多,这里我当前的开发环境准备好,现在大家可以根据本篇文章,先把项目跑起来,剩下的东西,我这边还有一个合作小伙伴已经在开始写代码了,代码这几天就可以发出来,所以大家这几天有空要赶紧把开发环境搭建起来!
开发环境搭建:
这个开发环境,我在之前的一篇文章里面简单提过,不过经过仔细思考,照顾一些基础比较差的朋友,所以必须要详细完善一下,当然这里一些opencv、ffmpeg源码搭建的环境搭建有参考网上的一些朋友的资料,还有就是群里有朋友已经跑通了项目,也共享了一些自己的搭建心得,在此非常感谢!
开发环境准备:
ubuntu16.04的环境,这个大家只要安装好Ubuntu16.04就行,这个很简单!
FFmpeg4.2源码安装,为啥要源码安装呢,而命令安装呢,主要是这里面会涉及一些编码的动态库,所以要必须源码安装。
opencv3.4.12源码安装
虹软的sdk注册和激活
好了,我们下面来说详细的搭建环境:
我们下载源码到这个目录下,为啥是这个目录,主要是为了配合我们这个工程的Makefile里面写的路径,我这里先指定这个目录,是为了减少您的工作,所有需要的源码安装的库和源码,您直接从下面这个里面下载就行:
链接:https://pan.baidu.com/s/1NfUVzWx8tsa8dKpHL4SI2g
提取码:qyn1当然这里ffmpeg源码,您最好是下载4.1d的版本,直接用这个命令下载就行:
wget -O ffmpeg-4.1.tar.bz2 https://ffmpeg.org/releases/ffmpeg-4.1.tar.bz2
如果失效了,可以找我拿就行!这里也感谢群里的朋友无私汇总!
然后先开始ffmpeg源码的搭建,您搭建的路径放在这个目录下:
root@txp-virtual-machine:/usr/local#然后其他库的安装,直接参考下面这个就行:
http://blog.yundiantech.com/?log=blog&id=35一般是没啥问题,如遇到问题,可以找我!
然后是opencv的搭建:
这个您可以在您的任意目录下建立一个OpenCV的文件夹,可以参考我的路径:

在开始搭建之前,您需要准备安装这些库和工具:
1、 sudo apt-get install cmake
2、sudo apt-get install build-essential libgtk2.0-dev libavcodec-dev libavformat-dev libjpeg.dev libtiff5.dev libswscale-dev libjasper-dev接着把刚刚下载的OpenCV源码通过samba共享,您可以拷贝到这个目录下,然后再进行解压,再进入这个目录下去开始编译:


最后按照下面步骤编译安装即可:
创建build文件夹
mkdir build进入build文件夹
cd build使用cmake编译参数
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..使用make创建编译
sudo make -j4执行命令
sudo make install修改 opencv.conf 文件
sudo gedit /etc/ld.so.conf.d/opencv.conf打开后的文件是空的,添加 opencv 库的安装路径:/usr/local/lib ,保存退出:
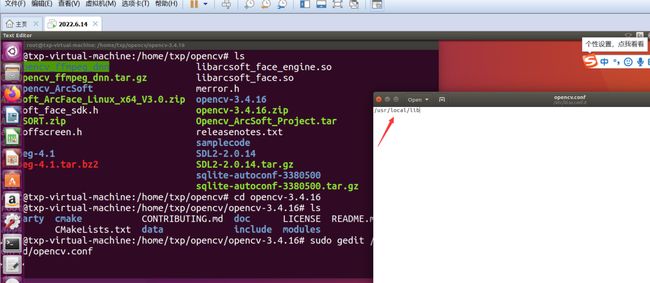
执行如下命令使得刚才的配置路径生效
sudo ldconfig修改 bash.bashrc 文件
sudo gedit /etc/bash.bashrc在bash.bashrc 文件最末尾添加
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
保存退出,执行如下命令使得配置生效
source /etc/bash.bashrc更新一下
sudo updatedb现在所有的配置都搞完,可以看是否搭建成功:
pkg-config --modversion opencv
最后一个环境搭建步骤,我们还要去虹软官网注册sdk和授权,这是它的官网,您可以跟着下面的照片操作就行:
https://www.arcsoft.com.cn/product/depth-camera-solutions-on-smart-phone.html



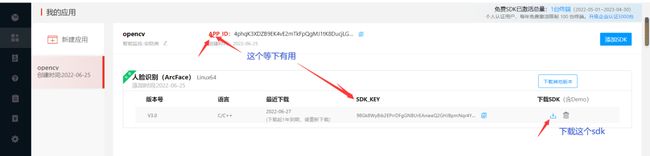
最后一张图片里面的APP_ID和SDK_KEY是有用的,这个要根据您的注册得到的为主,我这里只是演示一下:
APP_ID:4phqK3XDZB9EK4vE2mTkFpQgMJ1tK8DucjLGZYTMtsNNSDK_KEY:98Gk8WyBib2EPrrDFgGNBUrEAnieeQ2GHJBpmNqr4YXH好了,最为基本的开发环境就搭建好了!
把项目跑起来:
在这个项目的整个项目代码如下:
最新代码上传到gitee
git clone https://gitee.com/harry12345123/ffmpeg_arc_face-recognize.git
用户名:Harry12345123
密码:Aa123456
git clone https://gitee.com/harry12345123/FFMPEG_DNN_Project.git
用户名:Harry12345123
密码:Aa123456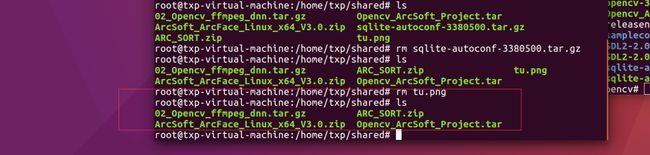
我们先解压虹sdk,这里有有一些头文件和.so的动态库,等下我们要用到:
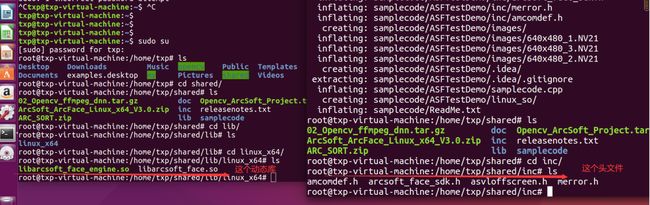
这两个动态库,要拷贝到目录/usr/local/lib目录下:
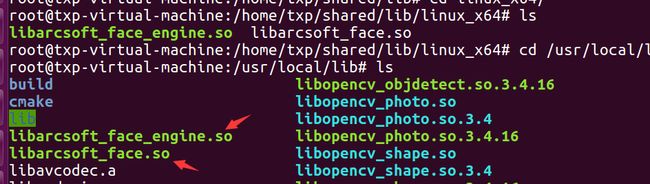
为了让等下我们的项目在编译的时候,能够生效,所以我们这里还有配置一下:
先打开vi /etc/ld.so.conf,在里面添加这个就可以

然后执行这个,让这个配置生效:
/sbin/ldconfig -v接着我们第一个要运行的主程序时这个:
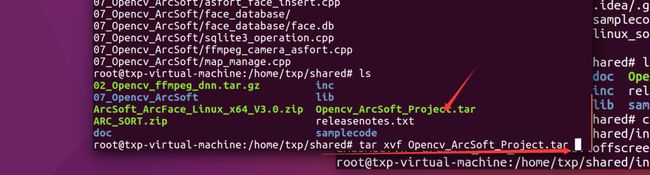
然后把刚才说的那个虹软的sdk里面有四个头文件拷贝进来:

同时这里有头文件:sqlite.h,您可以从我上面分享的sqlite源码里面拷贝过来就行!
这里准备好了,还有一个非常重要的步骤就是,把上面在虹软上注册的APP_ID和SDK_KEY替换到我们的工程里面去:
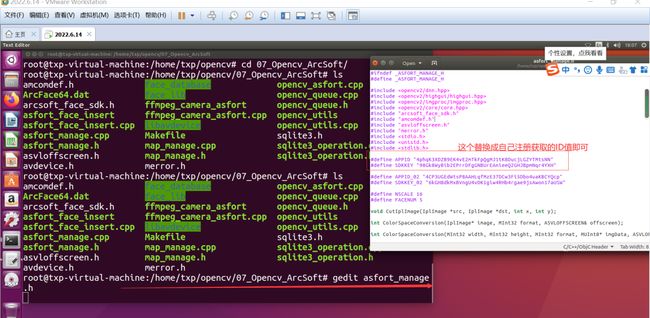
然后同时您还需要一张自己的自拍照片放入到这个目录下即可:
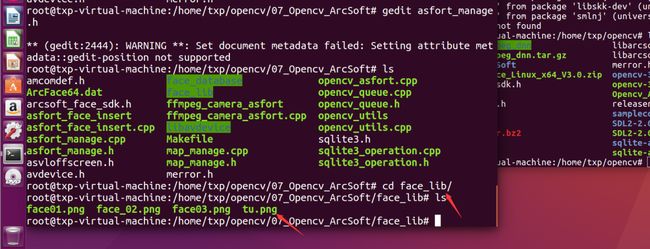
然后就可以直接编译我们的工程了,直接make就行:

开始执行,当您看到这个,就说明运行成功了:
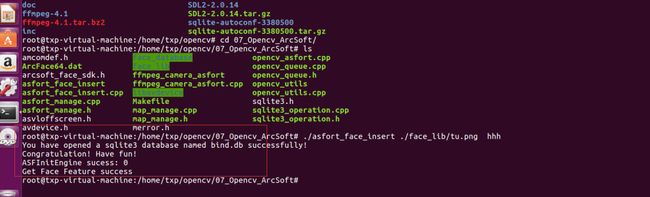
//这里的后缀名字可以随便输入
./asfort_face_insert ./face_lib/tu.png hhh然后最后可以运行我们的人脸识别主程序:
./ ffmpeg_camera_asfort注意:在运行ffmpeg_camera_asfort的时候,一定要在Linux虚拟机里面把摄像头打开,打开方式:
首选项->可移动设备->选择摄像头设备的名称(这里的摄像头名称各有不同,以自己电脑的名称为主,如我的摄像头名称是:IMC Networks Integrated Camera)->再选择连接。此时在虚拟机里面摄像头就已经打开了。这一步非常重要,如果没有这一步,程序直接报错。
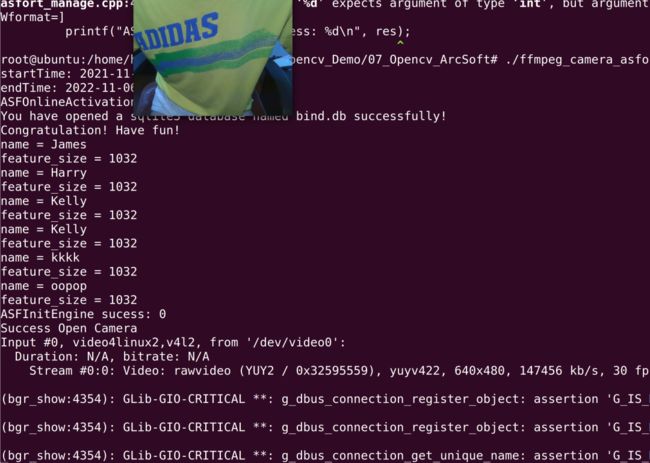
最后,我们的整个工程就跑通了!
总结:
这里说明一下,整个项目的运营,还有一位小伙伴:陈工;而且后期的rk平台代码扩展,会由他主导,我会扩展其他方面的实战开发,比如ui这块等等!
因为搞一个实战项目实在不容易,而且我们都是抽出自己的空闲时间来全力搞这个项目,白天我们也要上班,晚上下班加周末,我们两的时间几乎都花在这上面,所以这里我们目前是收取一定的费用的,希望大家理解,目前费用还不是很高,暂时定价在60元,后期随着实战代码写的越多,可能会提高入门费用!
我这里我也说明一下,在嵌入式领域的音视频这块,这里的知识,是一定会用到的,同时这块的实战的知识点,是在市面上找不到的,而且陈工他的经验比我丰富多了,参与过冬奥会的音视频项目,所以这块大家可以放心!
同时,学习这个项目的好处,我在开头说了,你可以写到你的简历里面去,同时提高自己的实战能力!
最后大家感兴趣的话,可以加入下面的星球,加入了星球可以加我微信,然后进入解答群答疑:
tu18879499804 //这是我的个人微信!