风格迁移篇---SAnet:风格注意网络下的任意风格转换
这里写目录标题
- Abstract
- 1. Introduction
- 2. Related Work
- 3. Method
-
- 3.1. Network Architecture
- 3.2. SANet for Style Feature Embedding
- 3.3. Full System
- 4. Experimental Results
-
- 4.1. Experimental Settings
- 4.2. Comparison with Prior Work
- 4.3. Ablation Studies
- 4.4. Runtime Controls
- 5. Conclusions
- Acknowledgments.
- References
论文地址: http://arxiv.org/abs/1812.02342
代码地址: https://github.com/GlebSBrykin/SANET
Abstract
任意风格转换旨在合成具有图像风格的内容图像,以创建以前从未见过的第三个图像。最近的任意风格转换算法发现平衡内容结构和风格模式很有挑战性。此外,由于基于补丁的机制,很难同时维护全局和局部样式的模式。在本文中,我们介绍了一种新的风格注意网络(SANet),该网络根据内容图像的语义空间分布高效灵活地集成局部风格模式。新的身份丢失函数和多级特征嵌入使我们的SANet和解码器能够在丰富样式模式的同时尽可能保留*指示等贡献内容结构。实验结果表明,我们的算法实时合成的样式化图像的质量高于最先进的算法生成的图像。
1. Introduction
艺术风格转移是一种通过在内容图像上均匀地从给定风格图像合成全局和局部风格图案,同时保持其原始结构来创建艺术的技术。最近,Gatys等人[5]的开创性工作表明,从预训练的深度神经网络中提取的特征之间的相关性可以很好地捕捉风格模式。Gatys等人[5]的方法是1 arXiv:1812.02342v5[cs.CV]2019年5月23日,足够灵活,可以组合任意图像的内容和样式,但由于迭代优化过程,速度太慢。
为了降低这一过程的计算成本,已经做出了重大努力。基于前馈网络,开发了几种方法[1、8、12、22、3、14、19、26、29]。前馈方法可以有效地合成样式化图像,但仅限于固定数量的样式或提供的视觉质量不足。
对于任意样式转换,一些方法[13、7、20]整体调整内容特征,以匹配样式特征的二阶统计量。AdaIN[7]简单地调整内容图像的均值和方差,以匹配样式图像的均值和方差。虽然AdaIN通过传输特征统计信息有效地结合了内容图像的结构和样式模式,但由于该方法过于简化,其输出质量受到影响。WCT[13]使用协方差而不是方差,通过白化和着色过程将内容特征转换为样式特征空间。通过在预先训练的编码器-解码器模块中嵌入这些风格化特征,无风格解码器合成了风格化图像。然而,如果特征具有大量维度,则WCT将相应地需要计算昂贵的操作。Avatar Net[20]是一个基于补丁的样式装饰器模块,它将内容特征映射为样式模式的特征,同时保持内容结构。阿凡达网不仅考虑整体风格分布,还考虑局部风格模式。然而,尽管做出了宝贵的努力,这些方法仍然不能反映风格图像的细节纹理,扭曲内容结构,或者无法平衡局部和全局风格模式。
在这项工作中,我们提出了一种新的任意风格传输算法,该算法实时合成高质量的风格化图像,同时保留内容结构。这是通过一种新型的注意力网络(SANet)和一种新的身份丢失函数实现的。对于任意风格转换,我们的前馈网络由sanet和解码器组成,通过根据内容特征在空间上重新排列风格特征来学习内容特征和风格特征之间的语义相关性。
我们提出的SANet与化身网络的风格特征装饰器密切相关[20]。然而,有两个主要区别:该模型使用1)学习的相似核而不是固定的相似核;2)软注意而不是硬注意。换言之,为了风格装饰的目的,我们将自注意力机制更改为可学习的基于软注意力的网络。我们的SANet使用可学习的相似性核将内容特征图表示为与其每个位置相似的样式特征的加权和。使用训练过程中的身份丢失,输入相同的图像对,并训练我们的模型以恢复相同的结果。在推理时,用样式图像替换其中一个输入图像,并基于样式特征尽可能多地恢复内容图像。与内容-风格的权衡不同,身份丢失有助于保持内容结构而不损失风格的丰富性,因为它有助于根据风格特征恢复内容。我们工作的主要贡献如下:
- 我们提出了一种新的SANet,可以灵活地将语义最近的样式特征与内容特征相匹配。
- 我们提出了一种由SANets和解码器组成的前馈网络的学习方法,该方法使用传统的重建损失和新的身份损失进行优化。
- 我们的实验表明,我们的方法在合成高质量的样式化图像时效率很高(约为每秒18-24帧,512像素),同时平衡全局和局部样式模式并保留内容结构。
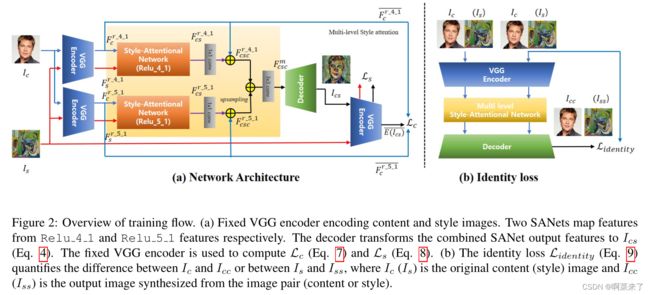
【图2:培训流程概述。(a) 固定VGG编码器编码内容和风格的图像。分别来自Relu 4 1和Relu 5 1特征的两个SANets地图特征。解码器将组合的SANet输出特征转换为IC(等式4)。固定VGG编码器用于计算Lc(等式7)和Ls(等式8)。(b) 身份丢失指数(等式9)量化了Ic和Icc之间或Is和Iss之间的差异,其中Ic(Is)是原始内容(样式)图像,Icc(Iss)是从图像对(内容或样式)合成的输出图像】
2. Related Work
任意样式转换。任意风格转换的最终目标是同时实现并保持泛化、质量和效率。尽管最近取得了一些进展,但现有方法[5、4、1、8、12、22、3、6、10、11、23、24、28、18]在泛化、质量和效率之间进行了权衡。最近,人们提出了几种方法[13、20、2、7]来实现任意样式的转换。AdaIN算法通过传输全局特征统计信息,简单地调整内容图像的均值和方差,以匹配样式图像的均值和方差。WCT执行一对特征变换(白化和着色),用于在预训练的编码器-解码器模块中嵌入特征。Avatar Net引入了基于补丁的特征装饰器,该装饰器将内容特征转换为语义最近的风格特征,同时最小化其整体特征分布之间的差异。在许多情况下,我们观察到WCT和AvatarNet的结果不能充分表示细节纹理或保持内容结构。我们推测,WCT和Avatar Net可能无法合成详细的纹理样式,因为它们预先训练了通用编码器-解码器网络,这些网络是从样式特征差异很大的通用图像(如MS-COCO数据集[15])中学习的。因此,这些方法考虑将样式特征映射到特征空间中的内容特征,但无法控制样式的全局统计信息或内容结构。虽然化身网络可以通过基于补丁的样式装饰器获得局部样式模式,但样式图像中样式模式的规模取决于补丁大小。因此,不能同时考虑全局和局部风格模式。相比之下,AdaIN可以很好地转换纹理和颜色分布,但不能很好地表示局部风格的图案。在这种方法中,存在另一种规模适应的内容和风格损失的组合,在内容和风格之间进行权衡。在本文中,我们尝试使用SANets和提出的身份丢失来解决这些问题。这样,所提出的风格转换网络可以表示全局和局部风格模式,并在不损失风格丰富性的情况下保持内容结构。
自我注意力机制。我们的风格注意力模块与最近用于图像生成和机器翻译的自注意力方法[25,30]有关。这些模型通过关注所有位置并在嵌入空间中取其加权平均值来计算序列或图像中某个位置的响应。该算法通过稍微修改自注意力机制来学习内容特征和风格特征之间的映射。
3. Method
本文提出的风格传递网络由编码器-解码器模块和风格注意模块组成,如图2所示。所提出的前馈网络有效地生成高质量的风格化图像,适当地反映全局和局部风格模式。我们新的身份丢失功能有助于保持内容的详细结构,同时充分反映风格
3.1. Network Architecture
我们的风格传递网络以内容图像Ic和任意风格图像为输入,并使用前者的语义结构和后者的特征合成风格化图像Ic。在这项工作中,预训练VGG-19网络[21]被用作编码器,对称解码器和两个SANet被联合训练用于任意样式的传输。我们的解码器遵循[7]的设置。
为了充分结合全局样式模式和局部样式模式,我们将从不同层(Relu 4 1和Relu 5 1)编码的VGG特征映射作为输入,并结合两个输出特征映射,从而集成了两个SANet。从内容图像Ic和样式图像Is对中,我们首先在编码器的特定层(例如,Relu 4 1)提取其各自的VGG特征映射Fc=E(Ic)和Fs=E(Is)。
在对内容和样式图像进行编码后,我们将两个特征映射提供给SANet模块,该模块映射内容特征映射Fc和样式特征映射Fs之间的对应关系,生成以下输出特征映射:

将1×1卷积应用于Fcs并按如下方式对两个矩阵进行元素求和后,我们得到Fcsc:
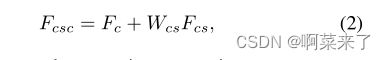
其中“+”表示按元素求和。我们将来自两个SANet的两个输出特征映射合并为:
![]()
其中,F r 4 1csc和F r 5 1csc是从两个SANet获得的输出特征图,conv3×3表示用于组合两个特征图的3×3卷积,F r 5 1csc在上采样后添加到F r 4 1csc。
然后,通过将F mcsc馈送到解码器中来合成样式化的输出图像ic,如下所示:
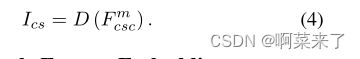
3.2. SANet for Style Feature Embedding
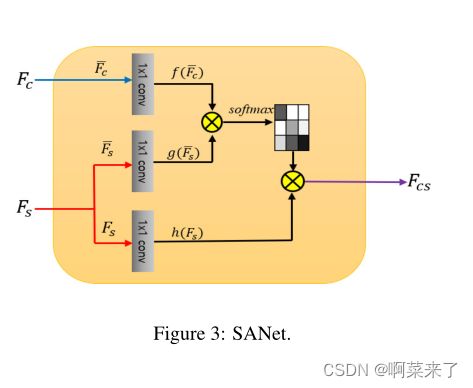
图3显示了使用SANet模块嵌入样式特征。编码器的内容特征映射Fc和样式特征映射Fs被归一化,然后转换为两个特征空间f和g,以计算f ic和f J之间的注意力,如下所示:

其中,f(Fc)=Wf Fc,g(Fs)=WgFs,h(Fs)=WhFs。此外,F表示F的均值-方差通道归一化版本。响应通过系数C(F)=P进行归一化∀j exp(f(f ic)T g(f js))。这里,i是输出位置的索引,j是枚举所有可能位置的索引。在上述公式中,Wf、Wg和Wh是学习的权重矩阵,如[30]中所示,它们被实现为1×1卷积。
我们的SANet的网络结构类似于现有的非局部块结构[27],但输入数据的数量不同(SANet的输入由Fc和Fs组成)。SANet模块可以通过学习映射内容和样式特征图之间的关系(例如亲和力),在内容特征图的每个位置适当嵌入局部样式模式。
3.3. Full System
如图2所示,我们使用编码器(预训练VGG-19[21])来计算用于训练SANet和解码器的损失函数:

其中,内容、风格和身份损失的组成部分分别为Lc、Ls和Lidentity,λc和λs是不同损失的权重。
与[7]类似,内容损失是均值-方差通道方向归一化目标特征F r 4 1c和F r 5 1c与输出图像VGG特征E(Ics)r 4 1和E(Ics)r 5 1的均值-方差通道方向归一化特征之间的欧氏距离,如下所示:
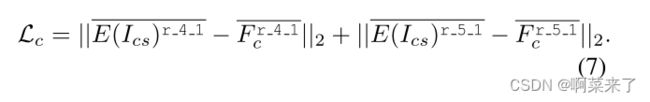
样式损失定义如下:
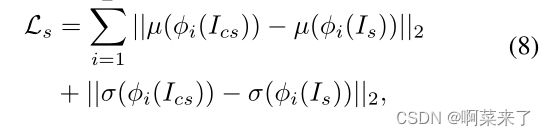
其中,每个φ表示编码器中用于计算样式损失的层的特征图。我们使用等权重的Relu 1 1、Relu 2 1、Relu 3 1、Relu 4 1和Relu 5 1层。我们应用了Gram矩阵损失[5]和AdaIN风格损失[7],但结果表明AdaIN风格损失更令人满意。

【图4:结果详细信息。为了更好地可视化,在最下面一行中由边界框标记的区域在最上面一行中被放大。】

【图5:五种风格转换算法的用户偏好结果】

当Wf、Wg和Wh固定为标识矩阵时,内容特征图中的每个位置都可以转换为样式特征图中语义最近的特征。在这种情况下,系统无法解析足够的样式特征。在SANet中,虽然Wf、Wg和Wh是可学习矩阵,但我们的风格转换模型可以通过只考虑风格损失Ls的全局统计信息来训练。
为了考虑内容特征和风格特征之间的全局统计和语义局部映射,我们定义了一个新的身份丢失函数,如下所示:
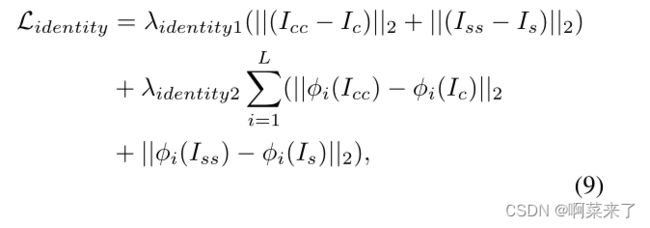
其中,Icc(或Iss)表示从两个相同内容(或样式)图像合成的输出图像,每个φi表示编码器中的一层,λidentity1和λidentity2是身份损失权重。在我们的实验中,加权参数简单地设置为λc=1、λs=3、λidentity1=1和λidentity2=50。
内容和风格损失控制着内容图像结构和风格模式之间的权衡。与其他两种损失不同,身份损失是从相同的输入图像计算的,样式特征没有差异。因此,身份丢失集中保持内容图像的结构,而不是更改样式统计。因此,身份丢失使得能够同时保持内容图像的结构和参考图像的风格特征
4. Experimental Results
图2显示了基于拟议SANets的我们风格的传输网络的概述。演示站点将通过https://dypark86.github.io/SANET/.
4.1. Experimental Settings
我们使用MS-COCO[15]对内容图像进行训练,使用WikiArt[17]对风格图像进行训练。这两个数据集包含大约80000个训练图像。我们使用了Adam优化器[9],学习率为0.0001,批量大小为五个内容风格的图像对。在训练过程中,我们首先将两幅图像的较小维度重新缩放到512,同时保持纵横比,然后随机裁剪256×256像素的区域。在测试阶段,我们的网络可以处理任何输入大小,因为它是完全卷积的。
4.2. Comparison with Prior Work
为了评估我们的方法,我们将其与三种类型的任意样式变换方法进行了比较:Gatys等人[5]提出的迭代优化方法,两种基于特征变换的方法(WCT[13]和AdaIN[7]),以及基于面片的方法Avatar Net[20]。
定性示例。在图11中,我们展示了通过最先进的方法合成的风格转换结果的示例。补充材料中提供了其他结果。注意,在我们的模型训练期间,没有观察到任何测试风格的图像。
基于优化的方法[5]允许任意样式转换,但可能会遇到错误的局部最小值(例如,图11中的第2行和第4行)。AdaIN[7]简单地调整内容特征的均值和方差来合成样式化图像。然而,由于内容和样式之间的权衡,其结果不太吸引人,并且通常保留内容的一些颜色分布(例如,图11中的第1、2和8行)。此外,AdaIN[7]和WCT[13]有时都会产生扭曲的局部样式模式,这是因为整体调整了内容特征,以匹配样式特征的二阶统计量,如图11所示。尽管化身网络[20]根据内容图像的语义空间分布用样式模式装饰图像,并应用多尺度样式转换,但由于其依赖于面片大小,它通常不能同时表示局部和全局样式模式。此外,在大多数情况下,它不能保持内容结构(图11中的第4列)。相反,在大多数示例中,我们的方法可以解析不同的样式模式,例如全局颜色分布、纹理和局部样式模式,同时保持内容的结构,如图11所示。
与其他算法不同,我们的可学习SANet可以灵活地解析足够级别的样式特征,而无需最大程度地对齐内容和样式特征,而无需考虑较大的域差距(图11中的第1行和第6行)。该SANet在语义上区分了内容结构,并将相似的风格模式转移到具有5个相同语义的区域。我们的方法为每种类型的语义内容转换不同的风格。在图11(第3行)中,我们的样式化图像中的天空和建筑物使用不同的样式模式进行样式化,而其他方法的结果在天空和建筑物之间具有模糊的样式边界。
我们还在图4中提供了结果的详细信息。我们的结果展示了多尺度风格模式(例如,颜色分布、灌木笔划以及风格图像中粗糙纹理的白色和红色模式)。Avatar Net和WCT会扭曲笔刷笔划,输出模糊的头发纹理,并且不会保留人脸的外观。AdaIN甚至不能保持颜色分布。
用户研究。我们使用了14幅内容图像和70幅风格图像,总共合成了980幅图像。我们为每个受试者随机选择了30种内容和风格组合,并以随机顺序向他们展示了通过五种比较方法获得的风格化图像。然后,我们要求受试者指出他/她最喜欢的每种风格的结果。我们收集了80位用户的2400张选票,并在图5中显示了每种方法的投票百分比。结果表明,与其他方法相比,我们的方法得到的程式化结果更受欢迎。
效率表1显示了该方法和其他方法在两个图像尺度(256和512像素)下的运行时性能。我们测量了运行时性能,包括样式编码的时间。基于优化的方法[5]由于其迭代优化过程,计算成本不现实。相比之下,我们的多尺度模型(Relu 4 1和Relu 5 1)算法对于256和512像素图像分别以59 fps和18 fps的速度运行,而单尺度(仅Relu 4 1)算法对于256和512像素图像分别以83 fps和24 fps的速度运行。因此,我们的方法可以实时处理风格转换。我们的模型比基于矩阵计算的方法(WCT[13]和Avatar Net[20])快7-20倍。
4.3. Ablation Studies
损失分析。在本节中,我们展示了内容风格丧失和身份丧失的影响。图6(a)显示了通过将λidentity1、λidentity2和λs分别固定在0、0和5,同时将λc从1增加到50而获得的结果。图6(b)显示了通过将λc和λs分别固定在0和5,并分别将λidentity1和λidentity2从1增加到100和从50增加到5000而获得的结果。在没有身份丢失的情况下,如果我们增加内容丢失的权重,内容结构会得到保留,但由于内容丢失和样式丢失之间的权衡,样式模式的特征会消失。相反,在不丢失内容的情况下增加身份丢失的权重,可以在保持样式模式的同时尽可能地保留内容结构。然而,内容结构的变化的失真是不可避免的。因此,我们结合了内容风格损失和身份损失来维护内容结构,同时丰富风格模式。

【图6:内容风格损失与身份损失。(a) 通过将λidentity1、λidentity2和λs分别固定在0、0和5,并将λc从1增加到50获得的结果。(b) 通过将λc和λs分别固定在0和5,并将λidentity1和λidentity2分别从1增加到100和从50增加到5000获得的结果。】

【图7:多级特征嵌入。通过在多个层次上嵌入特征,我们可以丰富样式化图像的局部和全局模式。】
多级特征嵌入。图7分别显示了从Relu 4 1和Relu 5 1获得的两个样式化输出。当仅使用Relu 4 1进行样式转换时,可以很好地保持样式特征和内容结构的全局统计信息。然而,当地风格的图案并不常见。相比之下,Relu 5 1有助于添加局部风格模式,例如圆形模式,因为感受野更宽。然而,内容结构被扭曲,笔触等纹理消失。在我们的工作中,为了丰富样式模式,我们将从不同(Relu 4 1和Relu 5 1)层编码的VGG特征映射作为输入,并结合两个输出特征映射,集成了两个SANet
4.4. Runtime Controls
在本节中,我们通过几个应用展示了我们方法的灵活性。

【图8:运行时的内容-风格权衡。我们的算法允许在运行时通过在特征映射F mccc和F mcsc之间插值来调整这种权衡。】

[图9:具有四种不同样式的样式插值。]

[图10:空间控制示例。左:内容图像。中间:样式图像和遮罩。右:来自两个不同样式图像的样式化图像。]
内容-风格权衡。可以在训练期间通过调整等式6中的样式权重λs来控制样式化程度,或者在测试期间通过在馈送到解码器的特征映射之间插值来控制样式化程度。对于运行时控制,我们调整了mcsc的样式化特性← − αF mcsc+(1− α) F mccc和∀α ∈ [0, 1]. 通过将两幅内容图像作为模型的输入,获得了映射F-mccc。当α=0时,网络尝试重建内容图像,当α=1时,尝试合成最具风格的图像(如图8所示)。
样式插值。为了在多个样式图像之间插值,可以将来自不同样式的mcsc的特征映射的凸组合馈入解码器(如图9所示)。
空间控制。图10显示了在空间上控制样式化的示例。此外,还需要一组掩码M(图10第3列)作为输入,以映射内容区域和样式之间的空间对应关系。我们可以通过用M J F mcsc替换F mcsc在每个空间区域中分配不同的样式,其中J是一个简单的maskout操作。
5. Conclusions
在这项工作中,我们提出了一种新的任意风格转换算法,该算法由风格注意网络和解码器组成。我们的算法是有效的。与[20]中基于补丁的样式装饰器不同,我们提出的SANet可以通过使用传统的样式重建损失和身份损失进行学习来灵活地装饰样式特征。此外,提出的身份丢失有助于SANet保持内容结构,丰富局部和全局风格模式。实验结果表明,该方法合成的图像优于其他最先进的任意样式传输算法。
Acknowledgments.
致谢。本研究由文化、体育和旅游部(MCST)和韩国创意内容署(KOCCA)在2019年文化技术(CT)研发计划中提供支持
References
[1] D. Chen, L. Y uan, J. Liao, N. Y u, and G. Hua. StyleBank:
An explicit representation for neural image style transfer. In
Proc. CVPR, volume 1, page 4, 2017.
[2] T. Q. Chen and M. Schmidt. Fast patch-based style transfer
of arbitrary style. arXiv preprint arXiv:1612.04337, 2016.
[3] V . Dumoulin, J. Shlens, and M. Kudlur. A learned represen-
tation for artistic style. In Proc. ICLR, 2017.
[4] L. Gatys, A. S. Ecker, and M. Bethge. Texture synthesis
using convolutional neural networks. In Advances in Neural
Information Processing Systems, pages 262–270, 2015.
[5] L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer
using convolutional neural networks. In Proc. CVPR, pages
2414–2423, 2016.
[6] L. A. Gatys, A. S. Ecker, M. Bethge, A. Hertzmann, and
E. Shechtman. Controlling perceptual factors in neural style
transfer. In Proc. CVPR, 2017.
[7] X. Huang and S. J. Belongie. Arbitrary style transfer in real-
time with adaptive instance normalization. In Proc. ICCV,
pages 1510–1519, 2017.
[8] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for
real-time style transfer and super-resolution. In Proc. ECCV,
pages 694–711. Springer, 2016.
[9] D. P . Kingma and J. Ba. Adam: A method for stochastic
optimization. arXiv preprint arXiv:1412.6980, 2014.
[10] C. Li and M. Wand. Combining Markov random fields and
convolutional neural networks for image synthesis. In Proc.
CVPR, pages 2479–2486, 2016.
[11] C. Li and M. Wand. Precomputed real-time texture synthesis
with Markovian generative adversarial networks. In Proc.
ECCV, pages 702–716. Springer, 2016.
[12] Y . Li, C. Fang, J. Yang, Z. Wang, X. Lu, and M.-H. Yang.
Diversified texture synthesis with feed-forward networks. In
Proc. CVPR, 2017.
[13] Y . Li, C. Fang, J. Yang, Z. Wang, X. Lu, and M.-H. Yang.
Universal style transfer via feature transforms. In Advances
in Neural Information Processing Systems, pages 386–396,
2017.
[14] Y . Li, N. Wang, J. Liu, and X. Hou. Demystifying neural
style transfer. arXiv preprint arXiv:1701.01036, 2017.
[15] T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P . Perona, D. Ra-
manan, P . Dollár, and C. L. Zitnick. Microsoft COCO: Com-
mon objects in context. In Proc. ECCV, pages 740–755.
Springer, 2014.
[16] A. Paszke, S. Chintala, R. Collobert, K. Kavukcuoglu,
C. Farabet, S. Bengio, I. Melvin, J. Weston, and J. Ma-
riethoz. PyTorch: Tensors and dynamic neural net-
works in Python with strong GPU acceleration, Available:
https://github.com/pytorch/pytorch, May 2017.
[17] F. Phillips and B. Mackintosh. Wiki Art Gallery, Inc.: A
case for critical thinking. Issues in Accounting Education,
26(3):593–608, 2011.
[18] E. Risser, P . Wilmot, and C. Barnes. Stable and controllable
neural texture synthesis and style transfer using histogram
losses. arXiv preprint arXiv:1701.08893, 2017.
[19] F. Shen, S. Yan, and G. Zeng. Meta networks for neural style
transfer. arXiv preprint arXiv:1709.04111, 2017.
[20] L. Sheng, Z. Lin, J. Shao, and X. Wang. Avatar-Net: Multi-
scale zero-shot style transfer by feature decoration. In Proc.
CVPR, pages 8242–8250, 2018.
[21] K. Simonyan and A. Zisserman. V ery deep convolutional
networks for large-scale image recognition. arXiv preprint
arXiv:1409.1556, 2014.
[22] D. Ulyanov, V . Lebedev, A. V edaldi, and V . S. Lempitsky.
Texture networks: Feed-forward synthesis of textures and
stylized images. In Proc. ICML, pages 1349–1357, 2016.
[23] D. Ulyanov, A. V edaldi, and V . Lempitsky. Instance normal-
ization: The missing ingredient for fast stylization. arXiv
preprint arXiv:1607.08022, (2016).
[24] D. Ulyanov, A. V edaldi, and V . S. Lempitsky. Improved
texture networks: Maximizing quality and diversity in feed-
forward stylization and texture synthesis. In Proc. CVPR,
volume 1, page 3, 2017.
[25] A. V aswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones,
A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all
you need. In Advances in Neural Information Processing
Systems, pages 5998–6008, 2017.
[26] H. Wang, X. Liang, H. Zhang, D.-Y . Yeung, and E. P . Xing.
ZM-Net: Real-time zero-shot image manipulation network.
arXiv preprint arXiv:1703.07255, 2017.
[27] X. Wang, R. Girshick, A. Gupta, and K. He. Non-local neural
networks. arXiv preprint arXiv:1711.07971, 2017.
[28] X. Wang, G. Oxholm, D. Zhang, and Y .-F. Wang. Multi-
modal transfer: A hierarchical deep convolutional neural net-
work for fast artistic style transfer. In Proc. CVPR, volume 2,
page 7, 2017.
[29] H. Zhang and K. Dana. Multi-style generative network for
real-time transfer. arXiv preprint arXiv:1703.06953, 2017.
[30] H. Zhang, I. Goodfellow, D. Metaxas, and A. Odena. Self-
attention generative adversarial networks. arXiv preprint
arXiv:1805.08318, 2018.