【人工智能】传统机器学习算法(QDU)
- 【人工智能】不确定性推理(QDU)
- 【人工智能】传统机器学习算法(QDU)
- 【人工智能】非线性分类器(QDU)
- 【人工智能】机器学习基础(QDU)
- 【人工智能】深度学习(QDU)
线性分类器
涉及内容:
- Fisher 线性判别
- 感知器算法
分类器与准则
分类器的作用:
常规任务是利用给定的类别、已知的训练数据来学习分类规则和分类器,然后对未知数据进行分类(或预测)。逻辑回归(logistics)、SVM等常用于解决二分类问题,对于多分类问题(multi-class classification),比如识别手写数字,它需要10个分类,同样也可以用逻辑回归或SVM,只是需要多个二分类来组成多分类,但这样容易出错且效率不高,常用的多分类方法有softmax。
分类算法可以按不同的方式划分:
- 基于概率密度的方法和基于判别函数的方法。
- 基于概率密度的分类算法通常借助于贝叶斯理论体系,采用潜在的类条件概率密度函数的知识进行分类; 在基于概率密度的分类算法中,有著名的贝叶斯估计法、最大似然估计,这些算法属于有参估计,需要预先假设类别的分布模型,然后使用训练数据来调整概率密度中的各个参数。另外,如 Parzen窗、Kn邻近等方法属于无参估计,此类方法可从训练样本中直接估计出概率密度。 基于判别函数的分类方法使用训练数据估计分类边界完成分类,无需计算概率密度函数。
- 基于判别函数的方法则假设分类规则是由某种形式的判别函数表示,而训练样本可用来表示计算函数中的参数,并利用该判别函数直接对测试数据进行分类。此类分类器中,有著名的Fisher准则、感知器方法、最小平方误差法、SVM法、神经网络方法以及径向基(RBF)方法等。
- 根据监督方式划分分类算法,分类学习问题可分为三大类:有监督分类、半监督分类和无监督分类。
- 有监督分类是指用来训练分类器的所有样本都经过了人工或其他方式的标注,有很多著名的分类器算法都属于有监督的学习方式,如AdaBoost[51],SVM,神经网络算法以及感知器算法。
- 无监督分类是指所有的样本均没有经过标注,分类算法需利用样本自身信息完成分类学习任务,这种方法通常被称为聚类,常用的聚类算法包括期望最大化(EM)算法和模糊C均值聚类算法等。
- 半监督分类指仅有一部分训练样本具有类标号,分类算法需要同时利用有标号样本和无标号样本学习分类,使用两种样本训练的结果比仅使用有标注的样本训练的效果更好。这类算法通常由有监督学习算法改进而成,如SemiBoost、流形正则化、半监督SVM等。
线性(二)分类器的定义:线性分类器就是用一个“超平面”将正、负样本隔离开。
常见的线性分类器有:LR,贝叶斯分类,单层感知机、线性回归,SVM(线性核)等。
非线性分类器的定义:非线性分类器就是用一个“超曲面”或者多个超平(曲)面的组合将正、负样本隔离开(即,不属于线性的分类器)。
常见的非线性(二)分类器:决策树、RF、GBDT、多层感知机、SVM(高斯核)等。
准则:
以线性分类器为例,在基于判别函数的方法中,准则用于构建合适的判别函数,或者是为判别函数确定最佳参数。
线性判别准则中比较经典的是,FIsher准则、感知机准则、最小二乘(最小均方误差)准则。
注:在许多博客中不区分LDA(Linear Discriminant Analysis)与FDA(Fisher Discriminant Analysis),所以这部分就不细致区分了。只要理解线性判别分析中包含了哪些准则以及准则的内容即可。
下文中若未作特别说明,则不区分“FDA”、“LDA”、“Fisher线性判别分析”、“Fisher准则”之间的细致概念,即同义。
引入:K-邻近算法的局限性
K-Nearest Neighbor分类器(K-邻近算法)进行分类存在很多不足:
- 分类器必须记住所有训练数据并将其存储起来,以便于未来测试数据用于比较。这在存储空间上是低效的,数据集很容易过大。
- 对一个测试图像进行分类需要和所有训练图像作比较,算法计算资源耗费高。
因为K-邻近算法的这些不足,我们引入了线性分类器。
Fisher准则
要学习线性判别绝对不能一上来就学习其函数,要先从整体思路上掌握!
基本思想
FDA是一种监督学习的降维技术,以二维数据集的二分类为例(通俗点讲二维数据集就是平面直角坐标系中的散点,二分类就是这些数据集要么是第一类,要么是第二类),有很多种方法对这些点进行分类,比如我们可以找一条直线去分隔两类点,线左边的是第一类,线右边的是第二类等等方法。而线性判别要做的是找一条直线,让这些散点都投影到该直线上,让同一类的点尽可能在直线上分布地近点,而不同类的点在直线上分布尽可能地远点。
可能还是有点抽象,我们先看看最简单的情况。假设我们有两类数据 分别为红色和蓝色,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。

上图提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的红色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。
在实际应用中,散点类别的确定往往不能仅由两种特征来确定,这就需要将FDA扩展到高维了。对于高维而言也是类似的,无非就是要去确定一个超平面,使得高维坐标系中的点投影到该超平面上同一类点尽可能近,不同类点尽可能远。降维就是FDA的主要思想。
判别函数
线性判别函数需要确定 W W W和 w 0 w_0 w0可以用于判断某个样本 X X X所在的类
判别函数: g ( X ) = W T X + w 0 g(X) = W^TX+w_0 g(X)=WTX+w0
其中, X X X为样本的特征(即样本点在高维坐标系下的坐标); W W W为权向量(即待求参数), w 0 w_0 w0为阈值权,是个常数。
在二分类中,判别函数的意义在于确定一个决策面(决策面就是用于分隔每类散点的超平面),决策面的一侧为第一类点,另一侧为第二类点,在面上的点我们可以将该点归为第一类也可以归为第二类,也可以选择不对这些点分类。根据其意义,可以总结出判别规则:
{ i f g ( X ) > 0 , t h e n X ∈ c l a s s 1 i f g ( X ) < 0 , t h e n X ∈ c l a s s 2 i f g ( X ) = 0 , t h e n X ∈ c l a s s 1 o r c l a s s 2 \left\{\begin{array}{l} if \space\space\space\space g(X)>0, \space\space\space\space then \space\space\space\space X∈class_1 \\ if \space\space\space\space g(X)<0, \space\space\space\space then \space\space\space\space X∈class_2 \\ if \space\space\space\space g(X)=0, \space\space\space\space then \space\space\space\space X∈class_1 \space or \space class_2\end{array}\right. ⎩⎨⎧if g(X)>0, then X∈class1if g(X)<0, then X∈class2if g(X)=0, then X∈class1 or class2
那么, g ( X ) = 0 g(X)=0 g(X)=0就是对应的决策面方程,即 W T X + w 0 = 0 W^TX+w_0=0 WTX+w0=0
准则函数
准则函数是用于获取最佳 W W W的函数,通过下面的讲解会发现准则函数是用于确定投影方向的函数
以FDA“同近异远”的主要思想为目标定义Fisher准则函数,当准则函数的值尽可能地大(或者小)时可以使两类尽量分开,同类尽量聚集。也就是说我们要将分类的好坏程度量化,用于量化的函数就是Fisher准则函数(可以理解为损失函数),当其值取最大(或最小)时得到的参数值就是我们的目标参数值,也就是决策面。
获取投影方向 W W W
以二分类为例。
将 X X X空间中的 N N N个具有 d d d个特征(即 d d d维)的样本点 x 1 x_1 x1, x 2 x_2 x2, . . . ... ..., x N x_N xN通过一个 d d d维向量 w w w投影到一维 Y Y Y空间中,其中 N 1 N_1 N1个属于 w 1 w_1 w1类的样本记为子集 Γ 1 \Gamma_1 Γ1, N 2 N_2 N2个属于 w 2 w_2 w2类的样本记为子集 Γ 2 \Gamma_2 Γ2。投影到一维 Y Y Y空间中,对应为 y i = W T x i y_i=W^Tx_i yi=WTxi, i = 1 , 2 , . . . , N i=1,2,...,N i=1,2,...,N。
基本参量:
在 d d d维 X X X空间中,
-
各类样本的均值向量 m i m_i mi
m i = 1 N i ∑ x ∈ Γ i x , i = 1 , 2 m_i=\frac{1}{N_i}\sum_{x∈\Gamma_i}x,\space\space\space\space i=1,2 mi=Ni1x∈Γi∑x, i=1,2 -
样本类内离散度矩阵 S i S_i Si
S i = ∑ x ∈ Γ i ( x − m i ) ( x − m i ) T , i = 1 , 2 S_i=\sum_{x∈\Gamma_i}(x-m_i)(x-m_i)^T,\space\space\space\space i=1,2 Si=x∈Γi∑(x−mi)(x−mi)T, i=1,2S i S_i Si为对称阵
-
总样本类内离散度矩阵 S w S_w Sw
S w = S 1 + S 2 S_w = S_1 + S_2 Sw=S1+S2 -
样本类间离散度矩阵 S b S_b Sb
S b = ( m 1 − m 2 ) ( m 1 − m 2 ) T S_b = (m_1-m_2)(m_1-m_2)^T Sb=(m1−m2)(m1−m2)TS b S_b Sb为对称阵
在一维 Y Y Y空间中,
-
各类样本的均值 m i ~ \tilde{m_i} mi~
m i ~ = 1 N i ∑ x j ∈ Γ i y j , i = 1 , 2 \tilde{m_i} = \frac{1}{N_i}\sum_{x_j∈\Gamma_i}y_j,\space\space\space\space i=1,2 mi~=Ni1xj∈Γi∑yj, i=1,2为了表示方便, m i ~ \tilde{m_i} mi~式中的 x j x_j xj和 y j y_j yj将简写为 x x x和 y y y,含义不变, y y y为 x x x对应的投影值
-
样本类内离散度 S i 2 ~ \tilde{S_i^2} Si2~
S i 2 ~ = ∑ x ∈ Γ i ( y − m i ~ ) 2 , i = 1 , 2 \tilde{S_i^2} = \sum{x∈\Gamma_i}(y-\tilde{m_i})^2, \space\space\space\space i=1, 2 Si2~=∑x∈Γi(y−mi~)2, i=1,2 -
总样本类内离散度 S w ~ \tilde{S_w} Sw~
S w ~ = S 1 2 ~ + S 2 2 ~ \tilde{S_w}=\tilde{S_1^2} + \tilde{S_2^2} Sw~=S12~+S22~ -
总样本类间散度 S b 2 ~ \tilde{S_b^2} Sb2~
S b 2 ~ = ( m 1 ~ − m 2 ~ ) 2 \tilde{S_b^2}=(\tilde{m_1}-\tilde{m_2})^2 Sb2~=(m1~−m2~)2
Fisher准则函数定义为:
m a x J F ( W ) = ( m 1 ~ − m 2 ~ ) 2 S 1 2 ~ + S 2 2 ~ max \space\space J_F(W) = \frac{(\tilde{m_1}-\tilde{m_2})^2}{\tilde{S_1^2} + \tilde{S_2^2}} max JF(W)=S12~+S22~(m1~−m2~)2
表示的含义即为“同近异远”
由各类样本的均值可推出:
m i ~ = 1 N i ∑ x ∈ Γ i y = 1 N i ∑ x ∈ Γ i W T x = W T ( 1 N i ∑ x ∈ Γ i x ) = W T m i \tilde{m_i} = \frac{1}{N_i}\sum_{x∈\Gamma_i}y=\frac{1}{N_i}\sum_{x∈\Gamma_i}W^Tx = W^T(\frac{1}{N_i}\sum_{x∈\Gamma_i}x)=W^Tm_i mi~=Ni1x∈Γi∑y=Ni1x∈Γi∑WTx=WT(Ni1x∈Γi∑x)=WTmi
这样,Fisher准则函数 J F ( W ) J_F(W) JF(W)的分子可写成:
( m 1 ~ − m 2 ~ ) 2 = ( W T m 1 − W T m 2 ) 2 = ( W T m 1 − W T m 2 ) ( W T m 1 − W T m 2 ) T = W T ( m 1 − m 2 ) ( m 1 − m 2 ) T W = W T S b W (\tilde{m_1}-\tilde{m_2})^2\\ =(W^Tm_1-W^Tm_2)^2\\ =(W^Tm_1-W^Tm_2)(W^Tm_1-W^Tm_2)^T\\ =W^T(m_1-m_2)(m_1-m_2)^TW\\ =W^TS_bW (m1~−m2~)2=(WTm1−WTm2)2=(WTm1−WTm2)(WTm1−WTm2)T=WT(m1−m2)(m1−m2)TW=WTSbW
现在再来考察 J F ( w ) J_F(w) JF(w)的分母与 W W W的关系:
S i 2 ~ = ∑ x ∈ Γ i ( y − m i ~ ) 2 = ∑ x ∈ Γ i ( W T x − W T m i ) 2 = W T [ ∑ x ∈ Γ i ( x − m i ) ( x − m i ) T ] W W T S w W \tilde{S_i^2} = \sum_{x∈\Gamma_i}(y-\tilde{m_i})^2\\ =\sum_{x∈\Gamma_i}(W^Tx-W^Tm_i)^2\\ =W^T[\sum_{x∈\Gamma_i}(x-m_i)(x-m_i)^T]W\\ W^TS_wW Si2~=x∈Γi∑(y−mi~)2=x∈Γi∑(WTx−WTmi)2=WT[x∈Γi∑(x−mi)(x−mi)T]WWTSwW
因此,
S 1 2 ~ + S 2 2 ~ = W T ( S 1 + S 2 ) W = W T S w W \tilde{S_1^2} + \tilde{S_2^2} = W^T(S_1+S_2)W=W^TS_wW S12~+S22~=WT(S1+S2)W=WTSwW
将上述各式代入 J F ( w ) J_F(w) JF(w),可得:
J F ( w ) = W T S b W W T S w W J_F(w)=\frac{W^TS_bW}{W^TS_wW} JF(w)=WTSwWWTSbW
最佳变换向量 W ∗ W^* W∗的求取:
为求使 J F ( w ) = W T S b W W T S w W J_F(w)=\frac{W^TS_bW}{W^TS_wW} JF(w)=WTSwWWTSbW取极大值时的 w ∗ w^* w∗,可以采用Lagrange乘数法求解。令分母等于非零常数,即:
W T S w W = c ≠ 0 W^TS_wW=c≠0 WTSwW=c=0
定义Lagrange函数为:
L ( W , λ ) = W T S b W − λ ( W T S w W − c ) L(W, \lambda)=W^TS_bW-\lambda(W^TS_wW-c) L(W,λ)=WTSbW−λ(WTSwW−c)
其中 λ \lambda λ为Lagrange乘子。将上式对 W W W求偏导数,可得:
∂ L ( W , λ ) ∂ w = S b W − λ S w W \frac{∂L(W,\lambda)}{∂ w}=S_bW-\lambda S_wW ∂w∂L(W,λ)=SbW−λSwW
令偏导数为零,则有:
S b W ∗ − λ S w W ∗ = 0 S b W ∗ = λ S w W ∗ S_bW^*-\lambda S_wW^*=0\\ S_bW^*=\lambda S_wW^* SbW∗−λSwW∗=0SbW∗=λSwW∗
其中 W ∗ W^* W∗就是 J F ( W ) J_F(W) JF(W)的极值解。因为 S w S_w Sw非奇异,将上式两边左乘 S W − 1 S_W^{-1} SW−1,可得:
S w − 1 S b W ∗ = λ W ∗ S_w^{-1}S_bW^*=\lambda W^* Sw−1SbW∗=λW∗
上式为求一般矩阵 S w − 1 S b S_w^{-1}S_b Sw−1Sb的特征值问题。利用 S b = ( m 1 − m 2 ) ( m 1 − m 2 ) T S_b=(m_1-m_2)(m_1-m_2)^T Sb=(m1−m2)(m1−m2)T的定义,将上式左边的 S b W ∗ S_bW^* SbW∗写成:
S b W ∗ = ( m 1 − m 2 ) ( m 1 − m 2 ) T W ∗ = ( m 1 − m 2 ) R S_bW^*=(m_1-m_2)(m_1-m_2)^TW^*=(m_1-m_2)R SbW∗=(m1−m2)(m1−m2)TW∗=(m1−m2)R
其中 R = ( m 1 − m 2 ) T W ∗ R=(m_1-m_2)^TW^* R=(m1−m2)TW∗为标量,所以 S b W ∗ S_bW^* SbW∗总在向量 ( m 1 − m 2 ) (m_1-m_2) (m1−m2)的方向上。因此 λ W ∗ \lambda W^* λW∗可写成:
λ W ∗ = S w − 1 ( S b W ∗ ) = S w − 1 ( m 1 − m 2 ) R \lambda W^*=S_w^{-1}(S_bW^*)=S_w^{-1}(m_1-m_2)R λW∗=Sw−1(SbW∗)=Sw−1(m1−m2)R
从而可得:
W ∗ = R λ S w − 1 ( m 1 − m 2 ) W^*=\frac{R}{\lambda}S_w^{-1}(m_1-m_2) W∗=λRSw−1(m1−m2)
由于我们的目的是寻找最佳的投影方向, W ∗ W^* W∗的比例因子对此并无影响,因此可忽略比例因子 R λ \frac{R}{\lambda} λR,有:
W ∗ = S w − 1 ( m 1 − m 2 ) W^*=S_w^{-1}(m_1-m_2) W∗=Sw−1(m1−m2)
W ∗ W^* W∗是使Fisher准则函数 J F ( W ) J_F(W) JF(W)取极大值时的解,也就是 d d d维 X X X空间到一维 Y Y Y空间的最佳投影方向。
获取阈值 w 0 w_0 w0
有了 W ∗ W^* W∗,就可以把 d d d维样本 x x x投影到一维,这实际上是多维空间到一维空间的一种映射,这个一维空间的方向 W ∗ W^* W∗相对于Fisher准则函数 J F ( W ) J_F(W) JF(W)是最好的。利用Fisher准则确定 W W W后,就可以将 d d d维分类问题转化为一维分类问题,然后,只要确定一个阈值 w 0 w_0 w0即可。
阈值 w 0 w_0 w0的选取:
d d d和 N N N很大时, y y y近似正态分布,可在Y空间内用贝叶斯分类器
经验,如:
w 0 = − 1 2 ( m 1 ~ + m 2 ~ ) w_0=-\frac{1}{2}(\tilde{m_1} + \tilde{m_2}) w0=−21(m1~+m2~)
w 0 = − m ~ w_0=-\tilde{m} w0=−m~
w 0 = − 1 2 ( m 1 ~ + m 2 ~ ) − 1 N 1 + N 2 − 2 l n P ( w 1 ) P ( w 2 ) w_0=-\frac{1}{2}(\tilde{m_1} + \tilde{m_2})-\frac{1}{N_1+N_2-2}ln\frac{P(w_1)}{P(w_2)} w0=−21(m1~+m2~)−N1+N2−21lnP(w2)P(w1)
在实际工作中还可以对 w 0 w_0 w0进行逐次修正的方式,选择不同的 w 0 w_0 w0值,计算其对训练样本集的错误率,找到错误率较小的 w 0 w_0 w0值
感知器算法
基本思想
对于线性判别函数,当模式的维数已知时,判别函数的形式实际上就已经确定下来,线性判别的过程即是确定权向量。感知器是一种神经网络模型,其特点是随意确定判别函数初始值,在对样本分类训练过程中,针对分类错误的样本不断进行权值修正,逐步迭代直至最终分类符合预定标准,从而确定权向量值。可以证明感知器是一种收敛算法,只要模式类别是线性可分的,就可以在有限的迭代步数里求出权向量的解。
判别函数
设样本 d d d维特征空间中描述,则两类别问题中线性决策面的一般形式可表示成: g ( X ) = W T X + w 0 g(X) = W^TX+w_0 g(X)=WTX+w0
将线性判别函数齐次化为: g ( X ) = W T X + w 0 = α T y g(X) = W^TX+w_0=\alpha^Ty g(X)=WTX+w0=αTy
其中, y = [ x 1 ] y=\left[\begin{matrix} x \\ 1 \end{matrix}\right] y=[x1]称为增广样本向量, α = [ w w 0 ] \alpha=\left[\begin{matrix} w \\ w_0 \end{matrix}\right] α=[ww0]称为增广权向量。
线性判别函数的齐次简化使特征空间增加了一维,但保持了样本间的欧氏距离不变, 对于分类效果也与原决策面相同,只是在Y空间中决策面是通过坐标原点的。
判别规则(与Fisher中类似):
g ( X ) = α T y { i f g ( X ) > 0 , t h e n X ∈ c l a s s 1 i f g ( X ) < 0 , t h e n X ∈ c l a s s 2 i f g ( X ) = 0 , t h e n X ∈ c l a s s 1 o r c l a s s 2 g(X) = \alpha^Ty\space\space\space\space \left\{\begin{array}{l} if \space\space\space\space g(X)>0, \space\space\space\space then \space\space\space\space X∈class_1 \\ if \space\space\space\space g(X)<0, \space\space\space\space then \space\space\space\space X∈class_2 \\ if \space\space\space\space g(X)=0, \space\space\space\space then \space\space\space\space X∈class_1 \space or \space class_2\end{array}\right. g(X)=αTy ⎩⎨⎧if g(X)>0, then X∈class1if g(X)<0, then X∈class2if g(X)=0, then X∈class1 or class2
反过来说,如果存在一个权向量 α \alpha α,使得对于任何 y ∈ c l a s s 1 y∈class_1 y∈class1都有 α T > 0 \alpha^T>0 αT>0, 而对任何 y < c l a s s 2 y
y<class2 ,都有 α T y < 0 \alpha^Ty<0 αTy<0, 则称这组样本集为线性可分的,否则称样本集为线性不可分的。
准则函数
样本的规范化
根据线性可分的定义,如果样本集 y 1 , y 2 , . . . , y N y_1,y_2,...,y_N y1,y2,...,yN是线性可分的,则必存在某个或某些权向量 α \alpha α,使得
g ( X ) = α T y { > 0 , 对 于 一 切 X ∈ c l a s s 1 < 0 , 对 于 一 切 X ∈ c l a s s 2 g(X) = \alpha^Ty\space\space\space\space \begin{cases}>0, \space\space\space\space 对于一切X∈class_1 \\ <0, \space\space\space\space 对于一切X∈class_2 \\ \end{cases} g(X)=αTy {>0, 对于一切X∈class1<0, 对于一切X∈class2
如果将第二类样本都取其反向向量,则有:
y ′ = { y , i f y ∈ c l a s s 1 − y , i f y ∈ c l a s s 2 y' = \begin{cases} \space\space\space y, \space\space\space\space if \space\space\space\space y∈class_1 \\ -y, \space\space\space\space if \space\space\space\space y∈class_2 \\ \end{cases} y′={ y, if y∈class1−y, if y∈class2
也就是说不管样本原来的类别标识,只要找到一个对全部样本都满足 α T y i ′ > 0 , i = 1 , 2 , . . , N \alpha^Ty'_i>0,\space\space i=1,2,..,N αTyi′>0, i=1,2,..,N的权向量 α \alpha α即可。
注:为了方便,下文中使用 y y y表示上文中的 y ′ y' y′
感知器准则函数
本质是用对所有错分样本的求和来表示对错分样本的惩罚。
如果样本 y k y_k yk被错分,则有 α T y k < 0 \alpha^Ty_k<0 αTyk<0,因此可定义如下的感知准则函数:
J P ( α ) = ∑ y j ∈ γ k ( − α T y j ) J_P(\alpha)=\sum_{y_j∈\gamma^k} (-\alpha^Ty_j) JP(α)=yj∈γk∑(−αTyj)
其中, γ k \gamma^k γk是被 α \alpha α错分样本的集合。当且仅当 J P ( α ∗ ) = m i n J P ( α ) = 0 J_P(\alpha^*)=minJ_P(\alpha)=0 JP(α∗)=minJP(α)=0时,无错分样本。
感知器准则函数求解
梯度下降法(非单样本修正法):
α ( k + 1 ) = α ( k ) − ρ k ∇ J \alpha(k+1)=\alpha(k)-\rho_k\nabla J α(k+1)=α(k)−ρk∇J
其中, α ( k ) \alpha(k) α(k)表示第 k k k次迭代, ρ k \rho_k ρk为步长。表示下一时刻的权向量是把当前时刻的权向量向目标函数的负梯度方向调整一个修正量。
其中,
∇ J = ∂ J P ( α ) / ∂ α = ∑ y j ∈ γ k ( − y j ) \nabla J=∂J_P(\alpha)/∂\alpha=\sum_{y_j∈ \gamma^k}(-y_j) ∇J=∂JP(α)/∂α=yj∈γk∑(−yj)
因此,
α ( k + 1 ) = α ( k ) + ρ k ∑ y j ∈ γ k ( − y j ) \alpha(k+1)=\alpha(k)+\rho_k\sum_{y_j∈ \gamma^k}(-y_j) α(k+1)=α(k)+ρkyj∈γk∑(−yj)
表示每一步迭代时把错分的样本按照某个系数加到权向量上。
单样本修正法:
不难看出,梯度下降法(非单样本修正法)每次迭代必须遍历全部样本点,才能得到 α ( k ) \alpha(k) α(k)下的错分样本集 γ k \gamma^k γk,这是十分低效的,更 常用是每次只修正一个样本或一批样本的固定增量法。
单样本修正法把样本集看做一个不断重复出现的序列而逐个加以考虑。对于任意权向量 α ( k ) \alpha(k) α(k),如果把某个样本分错了, 则对 α ( k ) \alpha(k) α(k)做一次修正。
单样本修正法的修正过程:
-
固定增量法
(1)初值 α ( 0 ) \alpha(0) α(0)任意
(2)对样本 y j y_j yj,若 α ( k ) T y j < 0 \alpha(k)^Ty_j<0 α(k)Tyj<0,则 α ( k + 1 ) = α ( k ) + ρ k y j \alpha(k+1)=\alpha(k)+\rho_ky_j α(k+1)=α(k)+ρkyj,其中 ρ k \rho_k ρk一般取 1 1 1
(3)对所有样本重复(2),直至 J P = 0 J_P=0 JP=0
-
变增量法
ρ k \rho_k ρk会变化。
例如绝对修正法: ρ k = ∣ α ( k ) T y j ∣ ∣ ∣ y j ∣ ∣ 2 \rho_k=\frac{|\alpha(k)^Ty_j|}{||y_j||^2} ρk=∣∣yj∣∣2∣α(k)Tyj∣
不进行细致讲解。
收敛:对线性可分样本集,经过有限次修正后一定可以找到一个解 α ∗ \alpha^* α∗
计算题
题目
已知有两类样本
w 1 = ( x 1 , x 2 ) = { ( 1 , 0 , 1 ) T , ( 0 , 1 , 1 ) T } w_1=(x_1,x_2)=\{\space(1,0,1)^T,\space (0,1,1)^T\space\} w1=(x1,x2)={ (1,0,1)T, (0,1,1)T }
w 2 = ( x 3 , x 4 ) = { ( 1 , 1 , 0 ) T , ( 0 , 1 , 0 ) T } w_2=(x_3,x_4)=\{\space(1,1,0)^T,\space(0,1,0)^T\space\} w2=(x3,x4)={ (1,1,0)T, (0,1,0)T }
假设初始权向量 a 1 = ( 1 , 1 , 1 , 1 ) T a_1=(1,1,1,1)^T a1=(1,1,1,1)T , ρ k = 1 ρ_k=1 ρk=1
试用感知准则函数法求判别函数?
解答
-
对样本进行变换,变成增广向量。
x 1 = ( 1 , 0 , 1 , 1 ) T x_1 = (1,0,1,1)^T x1=(1,0,1,1)T
x 2 = ( 0 , 1 , 1 , 1 ) T x_2 = (0,1,1,1)^T x2=(0,1,1,1)T
x 3 = ( 1 , 1 , 0 , 1 ) T x_3=(1,1,0,1)^T x3=(1,1,0,1)T
x 4 = ( 0 , 1 , 0 , 1 ) T x_4=(0,1,0,1)^T x4=(0,1,0,1)T
-
对样本进行规范化。
x 1 = ( 1 , 0 , 1 , 1 ) T x_1 = (1,0,1,1)^T x1=(1,0,1,1)T
x 2 = ( 0 , 1 , 1 , 1 ) T x_2 = (0,1,1,1)^T x2=(0,1,1,1)T
x 3 = − ( 1 , 1 , 0 , 1 ) T x_3=-(1,1,0,1)^T x3=−(1,1,0,1)T
x 4 = − ( 0 , 1 , 0 , 1 ) T x_4=-(0,1,0,1)^T x4=−(0,1,0,1)T
-
初始权向量 a 1 = ( 1 , 1 , 1 , 1 ) T a_1=(1,1,1,1)^T a1=(1,1,1,1)T , ρ k = 1 ρ_k=1 ρk=1
-
第一次迭代:
a 1 T x 1 = ( 1 , 1 , 1 , 1 ) ( 1 , 0 , 1 , 1 ) T = 3 > 0 a_1^Tx_1=(1,1,1,1)(1,0,1,1)^T=3>0 a1Tx1=(1,1,1,1)(1,0,1,1)T=3>0
∴ ∴ ∴ 不修正, a 2 = a 1 = ( 1 , 1 , 1 , 1 ) T a_2 = a_1 = (1,1,1,1)^T a2=a1=(1,1,1,1)T
a 2 T x 2 = ( 1 , 1 , 1 , 1 ) ( 0 , 1 , 1 , 1 ) T = 3 > 0 a_2^Tx_2=(1,1,1,1)(0,1,1,1)^T=3>0 a2Tx2=(1,1,1,1)(0,1,1,1)T=3>0
∴ ∴ ∴ 不修正, a 3 = a 2 = ( 1 , 1 , 1 , 1 ) T a_3 = a_2 = (1,1,1,1)^T a3=a2=(1,1,1,1)T
a 3 T x 3 = − ( 1 , 1 , 1 , 1 ) ( 1 , 1 , 0 , 1 ) T = − 3 < 0 a_3^Tx_3=-(1,1,1,1)(1,1,0,1)^T=-3<0 a3Tx3=−(1,1,1,1)(1,1,0,1)T=−3<0
∴ ∴ ∴ 修正, a 4 = a 3 + ρ k x 3 = ( 0 , 0 , 1 , 0 ) T a_4 = a_3 + ρ_k x_3= (0,0,1,0)^T a4=a3+ρkx3=(0,0,1,0)T
a 4 T x 4 = − ( 0 , 0 , 1 , 0 ) ( 0 , 1 , 0 , 1 ) T = 0 a_4^Tx_4=-(0,0,1,0)(0,1,0,1)^T=0 a4Tx4=−(0,0,1,0)(0,1,0,1)T=0
∴ ∴ ∴ 修正, a 5 = a 4 + ρ k x 4 = ( 0 , − 1 , 1 , − 1 ) T a_5 = a_4 + ρ_k x_4= (0,-1,1,-1)^T a5=a4+ρkx4=(0,−1,1,−1)T
经过第一轮迭代发现权向量有修改,需要进行第二轮迭代。
-
第二次迭代:
a 5 T x 1 = ( 0 , − 1 , 1 , − 1 ) ( 1 , 0 , 1 , 1 ) T = 0 a_5^Tx_1=(0,-1,1,-1)(1,0,1,1)^T=0 a5Tx1=(0,−1,1,−1)(1,0,1,1)T=0
∴ ∴ ∴ 修正, a 6 = a 5 + ρ k x 1 = ( 1 , − 1 , 2 , 0 ) T a_6 = a_5+ρ_k x_1 = (1,-1,2,0)^T a6=a5+ρkx1=(1,−1,2,0)T
a 6 T x 2 = ( 1 , − 1 , 2 , 0 ) ( 0 , 1 , 1 , 1 ) T = 1 > 0 a_6^Tx_2=(1,-1,2,0)(0,1,1,1)^T=1>0 a6Tx2=(1,−1,2,0)(0,1,1,1)T=1>0
∴ ∴ ∴ 不修正, a 7 = a 6 = ( 1 , − 1 , 2 , 0 ) T a_7 = a_6 = (1,-1,2,0)^T a7=a6=(1,−1,2,0)T
a 7 T x 3 = − ( 1 , − 1 , 2 , 0 ) ( 1 , 1 , 0 , 1 ) T = 0 a_7^Tx_3=-(1,-1,2,0)(1,1,0,1)^T=0 a7Tx3=−(1,−1,2,0)(1,1,0,1)T=0
∴ ∴ ∴ 修正, a 8 = a 7 + ρ k x 3 = ( 0 , − 2 , 2 , − 1 ) T a_8 = a_7 + ρ_k x_3= (0,-2,2,-1)^T a8=a7+ρkx3=(0,−2,2,−1)T
a 8 T x 4 = − ( 0 , − 2 , 2 , − 1 ) ( 0 , 1 , 0 , 1 ) T = 0 a_8^Tx_4=-(0,-2,2,-1)(0,1,0,1)^T=0 a8Tx4=−(0,−2,2,−1)(0,1,0,1)T=0
∴ ∴ ∴ 不修正, a 9 = a 8 = ( 0 , − 2 , 2 , − 1 ) T a_9 = a_8 = (0,-2,2,-1)^T a9=a8=(0,−2,2,−1)T
经过第二轮迭代发现权向量有修改,需要进行第三轮迭代。
-
第三次迭代:
a 9 T x 1 = ( 0 , − 2 , 2 , − 1 ) ( 1 , 0 , 1 , 1 ) T = 1 > 0 a_9^Tx_1=(0,-2,2,-1)(1,0,1,1)^T=1>0 a9Tx1=(0,−2,2,−1)(1,0,1,1)T=1>0
∴ ∴ ∴ 不修正, a 10 = a 9 = ( 0 , − 2 , 2 , − 1 ) T a_{10} = a_{9} = (0,-2,2,-1)^T a10=a9=(0,−2,2,−1)T
a 10 T x 2 = ( 0 , − 2 , 2 , − 1 ) ( 0 , 1 , 1 , 1 ) T = − 1 < 0 a_{10}^Tx_2=(0,-2,2,-1)(0,1,1,1)^T=-1<0 a10Tx2=(0,−2,2,−1)(0,1,1,1)T=−1<0
∴ ∴ ∴ 修正, a 11 = a 10 + ρ k x 2 = ( 0 , − 1 , 3 , 0 ) T a_{11} = a_{10} + ρ_k x_2= (0,-1,3,0)^T a11=a10+ρkx2=(0,−1,3,0)T
a 11 T x 3 = − ( 0 , − 1 , 3 , 0 ) ( 1 , 1 , 0 , 1 ) T = 1 > 0 a_{11}^Tx_3=-(0,-1,3,0)(1,1,0,1)^T=1>0 a11Tx3=−(0,−1,3,0)(1,1,0,1)T=1>0
∴ ∴ ∴ 不修正, a 12 = a 11 = ( 0 , − 1 , 3 , 0 ) T a_{12} = a_{11} = (0,-1,3,0)^T a12=a11=(0,−1,3,0)T
a 12 T x 4 = − ( 0 , − 1 , 3 , 0 ) ( 0 , 1 , 0 , 1 ) T = 1 > 0 a_{12}^Tx_4=-(0,-1,3,0)(0,1,0,1)^T=1>0 a12Tx4=−(0,−1,3,0)(0,1,0,1)T=1>0
∴ ∴ ∴ 不修正, a 13 = a 12 = ( 0 , − 1 , 3 , 0 ) T a_{13} = a_{12} = (0,-1,3,0)^T a13=a12=(0,−1,3,0)T
经过第三轮迭代发现权向量有修改,需要进行第四轮迭代。
-
第四次迭代:
a 13 T x 1 = ( 0 , − 1 , 3 , 0 ) ( 1 , 0 , 1 , 1 ) T = 3 > 0 a_{13}^Tx_1=(0,-1,3,0)(1,0,1,1)^T=3>0 a13Tx1=(0,−1,3,0)(1,0,1,1)T=3>0
∴ ∴ ∴ 不修正, a 14 = a 13 = ( 0 , − 1 , 3 , 0 ) T a_{14} = a_{13} = (0,-1,3,0)^T a14=a13=(0,−1,3,0)T
a 14 T x 2 = ( 0 , − 1 , 3 , 0 ) ( 0 , 1 , 1 , 1 ) T = 2 > 0 a_{14}^Tx_2=(0,-1,3,0)(0,1,1,1)^T=2>0 a14Tx2=(0,−1,3,0)(0,1,1,1)T=2>0
∴ ∴ ∴ 不修正, a 15 = a 14 = ( 0 , − 1 , 3 , 0 ) T a_{15} = a_{14} = (0,-1,3,0)^T a15=a14=(0,−1,3,0)T
a 15 T x 3 = − ( 0 , − 1 , 3 , 0 ) ( 1 , 1 , 0 , 1 ) T = 1 > 0 a_{15}^Tx_3=-(0,-1,3,0)(1,1,0,1)^T=1>0 a15Tx3=−(0,−1,3,0)(1,1,0,1)T=1>0
∴ ∴ ∴ 不修正, a 16 = a 15 = ( 0 , − 1 , 3 , 0 ) T a_{16} = a_{15} = (0,-1,3,0)^T a16=a15=(0,−1,3,0)T
a 16 T x 4 = − ( 0 , − 1 , 3 , 0 ) ( 0 , 1 , 0 , 1 ) T = 1 > 0 a_{16}^Tx_4=-(0,-1,3,0)(0,1,0,1)^T=1>0 a16Tx4=−(0,−1,3,0)(0,1,0,1)T=1>0
∴ ∴ ∴ 不修正, a 17 = a 16 = ( 0 , − 1 , 3 , 0 ) T a_{17} = a_{16} = (0,-1,3,0)^T a17=a16=(0,−1,3,0)T
经过第四轮迭代发现权向量没有修改,迭代结束。
因此,最终权向量 a = a 17 = ( 0 , − 1 , 3 , 0 ) T a=a_{17}=(0,-1,3,0)^T a=a17=(0,−1,3,0)T,判别函数为 g ( X ) = a T X = − x 2 + 3 x 3 g(X)=a^TX = -x_2+3x_3 g(X)=aTX=−x2+3x3
多类问题
对于多类问题,模式有 w 1 w_1 w1, w 2 w_2 w2, . . . ... ..., w m w_m wm个类别。可分三种情况:
- 绝对可分(一对多,one-vs-rest, one-over-all)
- 成对可分
- 最大值判决(直接多类分类)
第一种情况:绝对可分
每一模式类与其它模式类间可用单个判别平面把一个类分开, c c c类转化为 c c c个两类问题, w i w_i wi与非 w i w_i wi
简单来说,就是先将 w 1 w_1 w1的样本作为一组, w 2 w_2 w2, . . . ... ..., w m w_m wm的样本作为另一组,根据这两组画一条线将两组分隔;再将 w 2 w_2 w2的样本作为一组, w 1 w_1 w1, w 3 w_3 w3, . . . ... ..., w m w_m wm的样本作为另一组根据这两组再画一条线将两组分隔,以此类推。
缺点:
- 训练样本不均衡而导致分类面有偏(假设多类中各类的训练样本数相当)
- 出现歧义区域,不会恰好得到c个区域(往往过多)
通过下图观察更加直观:

如果 X X X属于 w 1 w_1 w1,则由图可清楚看出,这时 g 1 ( x ) > 0 g_1 (x) >0 g1(x)>0而 g 2 ( x ) < 0 g_2 (x) <0 g2(x)<0, g 3 ( x ) < 0 g_3 (x) <0 g3(x)<0。 w 1 w_1 w1类与其它类之间的边界由 g 1 ( x ) = 0 g_1(x)=0 g1(x)=0确定。
例题: 已知三类 w 1 w_1 w1, w 2 w_2 w2, w 3 w_3 w3的判别函数分别为:
{ g 1 ( x ) = − x 1 + x 2 g 2 ( x ) = x 1 + x 2 − 5 g 3 ( x ) = − x 2 + 1 → 三 个 判 别 边 界 为 : { g 1 ( x ) = − x 1 + x 2 = 0 g 2 ( x ) = x 1 + x 2 − 5 = 0 g 3 ( x ) = − x 2 + 1 = 0 \left\{\begin{array}{l} g_1(x)=-x_1+x_2 \\ g_2(x)=x_1+x_2-5\\ g_3(x)=-x_2+1 \\ \end{array}\right. \space\space\space\space \xrightarrow[]{三个判别边界为:} \space\space\space\space \left\{\begin{array}{l} g_1(x)=-x_1+x_2=0 \\ g_2(x)=x_1+x_2-5=0\\ g_3(x)=-x_2+1=0 \\ \end{array}\right. ⎩⎨⎧g1(x)=−x1+x2g2(x)=x1+x2−5g3(x)=−x2+1 三个判别边界为: ⎩⎨⎧g1(x)=−x1+x2=0g2(x)=x1+x2−5=0g3(x)=−x2+1=0

如果某个 X X X使二个以上的判别函数 g i ( x ) > 0 g_i (x) >0 gi(x)>0,则 X X X就无法作出确切的判决。 如图中 I R 1 IR1 IR1, I R 3 IR3 IR3, I R 4 IR4 IR4区域。另一种情况是 I R 2 IR2 IR2区域,判别函数都为负值。 I R 1 IR1 IR1, I R 2 IR2 IR2, I R 3 IR3 IR3, I R 4 IR4 IR4都为不确定区域。
第二种情况:成对可分
对多类中的每两类构造一个分类器,所以每个模式类和其它模式类间可分别用判别平面分开,因此对于 c c c类就有 c ( c − 1 ) 2 \frac{c(c-1)}{2} 2c(c−1)个决策面。
相较于“一对多”,决策歧义区域相对较小。
判别函数: g i j ( x ) = W i j T x g_{ij}(x)=W^T_{ij}x gij(x)=WijTx
判别边界: g i j ( x ) = 0 g_{ij}(x)=0 gij(x)=0
判别条件: g i j ( x ) { > 0 , 当 x ∈ w 1 < 0 , 当 x ∈ w 2 i ≠ j g_{ij}(x) \left\{\begin{array}{l} >0, \space\space\space\space 当x∈w_1 \\<0, \space\space\space\space 当x∈w_2 \\ \end{array}\right. \space\space\space\space i≠j gij(x){>0, 当x∈w1<0, 当x∈w2 i=j
判别函数性质: g i j ( x ) = g j i ( x ) g_{ij}(x) = g_{ji}(x) gij(x)=gji(x)
还是通过样例来说明:
假设判别函数为: { g 12 ( x ) = − x 1 − x 2 + 5 g 13 ( x ) = − x 1 + 5 g 23 ( x ) = − x 1 + x 2 \left\{\begin{array}{l} g_{12}(x)=-x_1-x_2+5 \\g_{13}(x)=-x_1+5\\g_{23}(x)=-x_1+x_2 \end{array}\right. \space\space\space\space ⎩⎨⎧g12(x)=−x1−x2+5g13(x)=−x1+5g23(x)=−x1+x2
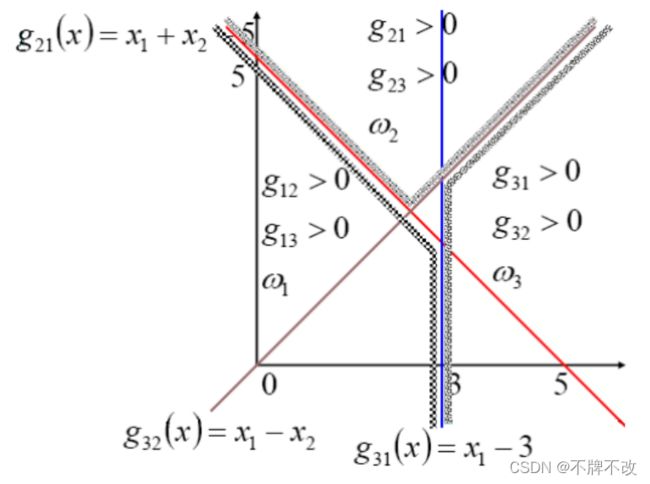
例题: 未知模式 X = ( x 1 , x 2 ) T = ( 4 , 3 ) T X=(x_1 ,x_2 )^T=(4,3)^T X=(x1,x2)T=(4,3)T属于上面的哪一类?
代入判别函数可得: g 12 ( x ) = − 2 g_{1 2}(x) = −2 g12(x)=−2, g 13 ( x ) = − 1 g_{1 3}(x) = −1 g13(x)=−1, g 23 ( x ) = − 1 g_{2 3}(x) = −1 g23(x)=−1
把下标对换可得: g 21 ( x ) = 2 g_{21}(x) = 2 g21(x)=2, g 31 ( x ) = 1 g_{31}(x) = 1 g31(x)=1, g 32 ( x ) = 1 g_{32}(x) = 1 g32(x)=1
因为 g 3 j ( x ) > 0 g_{3 j }(x) > 0 g3j(x)>0,所以 X X X属于 w 3 w_3 w3类
第三种情况:最大值判决
每类都有一个判别函数。
判别函数: g k ( x ) = W k X k = 1 , 2 , . . . , M g_k (x) =W_k X\space\space\space\space\space\space k =1,2,...,M gk(x)=WkX k=1,2,...,M
判别规则: g i ( x ) = W K T X { 最 大 , 当 x ∈ w i 小 , 其 他 g_{i}(x)=W_K^T X \begin{cases} 最大, \space\space\space\space 当x∈w_i \\小, \space\space\space\space 其他 \\ \end{cases} \space\space\space\space gi(x)=WKTX{最大, 当x∈wi小, 其他
判别边界: g i ( x ) = g j ( x ) g_i (x) =g_j (x) gi(x)=gj(x)或 g i ( x ) − g j ( x ) = 0 g_i (x) -g_j (x) =0 gi(x)−gj(x)=0
就是说,要判别模式 X X X属于哪一类,先把 X X X代入 M M M个判别函数中,判别函数最大的那个类别就是 X X X所属类别。
此分类实现方式也称作多类线性机器
多类线性机器不会出现有决策歧义的区域。下图显示三类的情况:

利用感知准则实现多类判别
步骤:
(1)增广样本,但是不用进行规范化(注意和两分类问题的区别)
(2)每一类设定一个初始权向量
(3)对第 i i i类的样本 y i y_i yi,若 w i T y i < = w t T y i w_i^Ty_i<=w_t^Ty_i wiTyi<=wtTyi, t = 1 , . . . , M , t ≠ i t=1,...,M,t≠i t=1,...,M,t=i,则
{ w i ( k + 1 ) = w i ( k ) + y i w t ( k + 1 ) = w t ( k ) − y i t ≠ i \begin{cases}w_i(k+1)=w_i(k)+y_i\\w_t(k+1)=w_t(k)-y_i & t≠i\end{cases} \space\space\space\space {wi(k+1)=wi(k)+yiwt(k+1)=wt(k)−yit=i
(4)对所有样本重复(3),直到满足 w i T y i > w t T y i w_i^Ty_i>w_t^Ty_i wiTyi>wtTyi, t = 1 , . . , M t=1,..,M t=1,..,M, t ≠ i t≠i t=i
注意,当存在修改时,只对不满足条件的 t t t对应的权向量进行修改,并非只要不满足(4)就要对全部权向量进行修改!
例题:
有三类样本 w 1 : { ( 0 , 0 ) T } w_1:\{(0,0)^T\} w1:{(0,0)T}, w 2 : { ( 1 , 1 ) t } w_2:\{(1,1)^t\} w2:{(1,1)t}, w 3 : { ( − 1 , 1 ) T } w_3:\{(-1,1)^T\} w3:{(−1,1)T},采用感知器算法设计判别函数。
解答:
(2)对样本进行变换,变换成增广向量。
x 1 = ( 0 , 0 , 1 ) T x_1=(0,0,1)^T x1=(0,0,1)T
x 2 = ( 1 , 1 , 1 ) T x_2=(1,1,1)^T x2=(1,1,1)T
x 3 = ( − 1 , 1 , 1 ) T x_3=(-1,1,1)^T x3=(−1,1,1)T
(2)初始权向量为 w ( 1 ) = w ( 2 ) = w ( 3 ) = ( 0 , 0 , 0 ) T w(1)=w(2)=w(3)=(0,0,0)^T w(1)=w(2)=w(3)=(0,0,0)T,并令 c = 1 c=1 c=1


此时对于所有样本,全向量不再修改,迭代停止
w 1 = w 1 ( 8 ) = ( 0 , − 2 , 0 ) T w_1=w_1(8)=(0,-2,0)^T w1=w1(8)=(0,−2,0)T
w 2 = w 2 ( 8 ) = ( 2 , 0 , − 2 ) T w_2=w_2(8)=(2,0,-2)^T w2=w2(8)=(2,0,−2)T
w 3 = w 3 ( 8 ) = ( − 2 , 0 , − 2 ) T w_3=w_3(8)=(-2,0,-2)^T w3=w3(8)=(−2,0,−2)T
判别函数:
g 1 ( x ) = − 2 x 2 g_1(x)=-2x_2 g1(x)=−2x2
g 2 ( x ) = 2 x 1 − 2 g_2(x)=2x_1-2 g2(x)=2x1−2
g 3 ( x ) = − 2 x 1 − 2 g_3(x)=-2x_1-2 g3(x)=−2x1−2
REF
线性判别分析LDA原理总结 - 博客园
线性判别分析(LDA)准则:FIsher准则、感知机准则、最小二乘(最小均方误差)准则 - 博客园
机器学习总结之——线性分类器与非线性分类器 - CSDN
分类器 - CSDN
10 模式识别- 感知器分类方法(单样本修正法+非单样本修正法)- CSDN