机器学习笔记:Transformer
1 传统Seq2Seq的不足
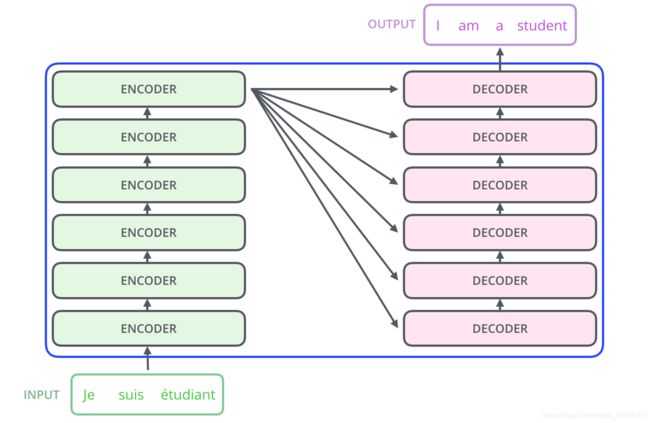
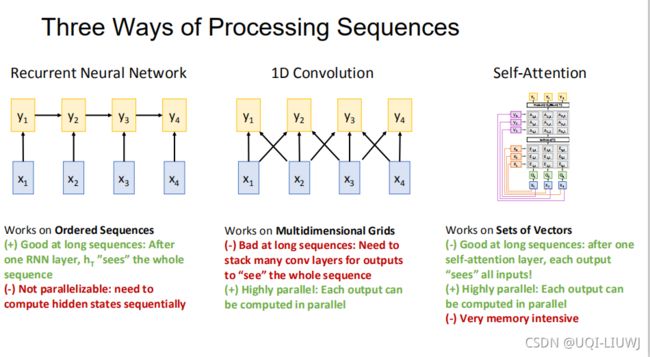
传统seq2seq 使用 bi-direction RNN,那么生成每个b的时候,对于输入的整个序列,模型都需要看过一遍。
问题在于,这样的用bi-direction RNN 实现的seq2seq,它却没有办法并行操作,也就是说,我b1~b4必须一个一个计算。
1.1 改进1 使用CNN代替RNN
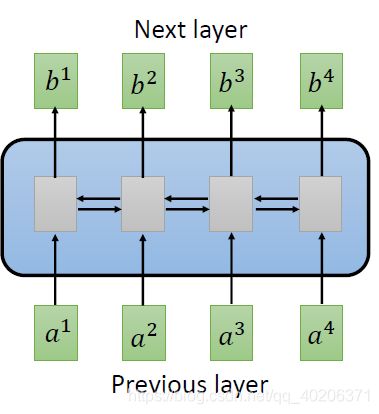
一个三角形代表一个filter,每个filter处理输入的一小段(在这里,比如说我每个filter处理输入的单个vector,输出一个数值)

我们同一层可以有多个filter,每个filter对每一段输入,输出一个标量数值。
把这些标量concat起来,就成了一个sequence,每个sequence对应了一个输出的vector
但如果CNN的改进只到这里,是没有太多的意义的。因为虽然也是seq2seq,但我们output的每一个只受到相对应的input的影响,我们的output并不会由其他的vector-input左右。
于是这时候我们可以叠加几层CNN(但这样参数就会变多了):
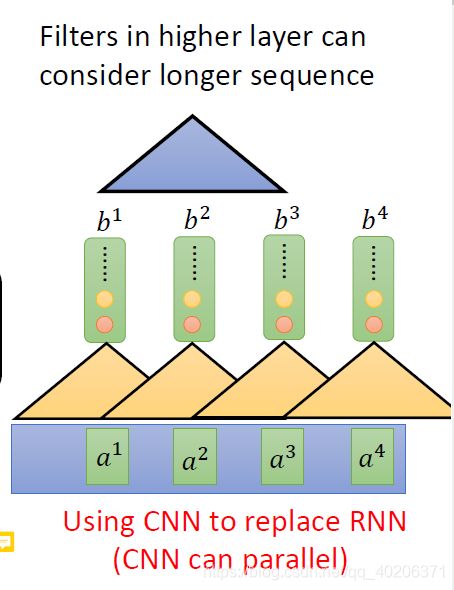
高层CNN可以看到更多的“output vector”(比如这里,我们蓝色的filter处理b1~b3,那么相当于这时候的输出会综合考虑a1~a3的信息)
CNN的问题在于,想要获得更多点的信息,就需要多层CNN,一层肯定是不够的。那么此时的参数量是非常大的。
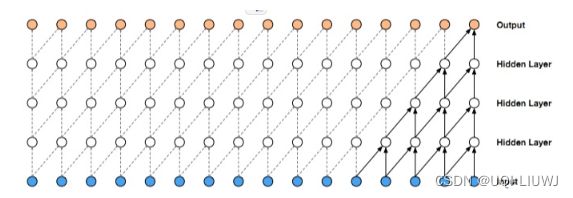
1.1.1 因果卷积 Causal Convolution
上面说的用CNN的操作,我们可以用如下的因果卷积表示
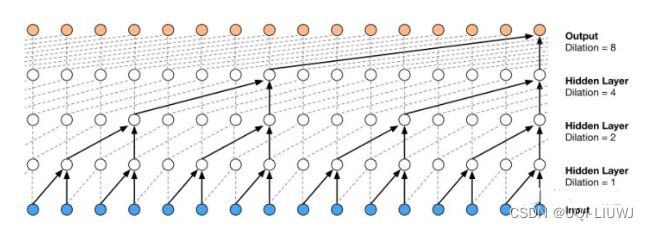
1.1.2 扩展卷积(dilated convolution)
如果我们引入dilation,那么使用的层数会变少/最终output的感受野会变大
2 和self-attention的对比
3 transformer 逐结构讲解
3.1 总览
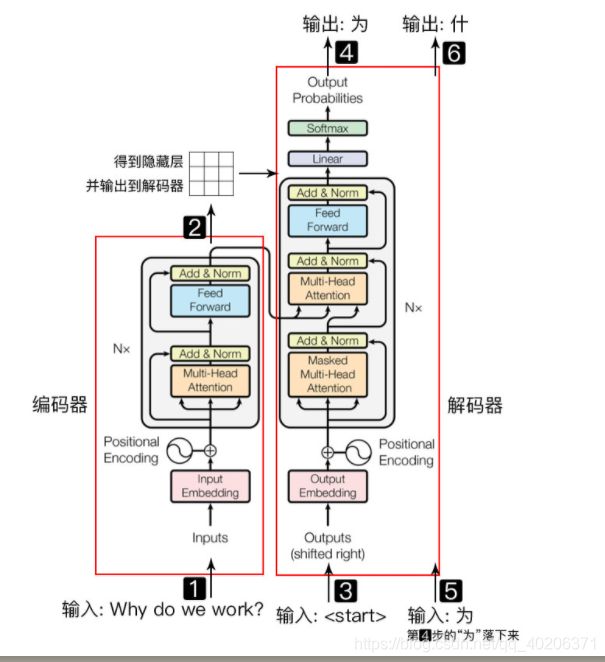



机器学习笔记:神经网络层的各种normalization_UQI-LIUWJ的博客-CSDN博客
layer normalization:每个变量分别进行归一化

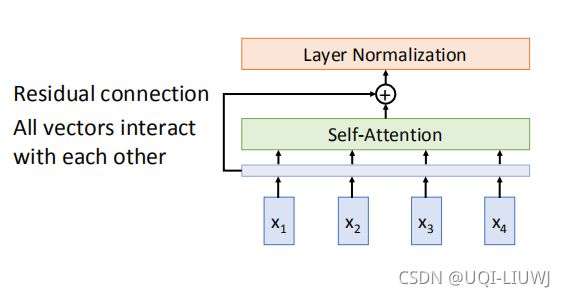



3.2 input embedding

输入一个句子(batch_size,sequence_length)【后者表示一个sequence有几个字】,
再经过一个字编码 ,把维度变成三维的(batch_size,sequence_length,embedding_dimension) 【每一个字编码长度为 embedding dimension】
3.3 positional encoding
在前面的self-attention中,我们发现,我们并没有利用到input的各个元素的位置信息(就是不管你在哪个位置,不管两个点是远还是近,两个点谁在前面等等,我只做加权求和而已)。
为了使用vector-input 的位置信息,我们引入了positional encoding(每个字位置嵌入的维数和词向量的维数是一样的,都是embedding_dimension)。
我们从xi 经过input embedding后,得到ai。然后对每个ai加上一个位置嵌入ei,将这个求和结果进行之后的运算,生成的q,k,v。
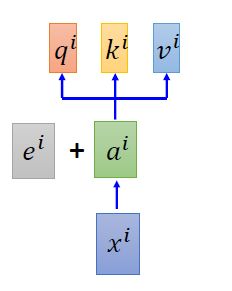
理论上ei也可以学,在“attention is all you need”中,ei直接人为设定了。
3.3.1 台大李宏毅教授对ei的理解
假设每个位置一开始我们有一个one-hot的embedding pi。哪个位置为1,就表示它在那个位置。
我们把pi 拼接到原来的xi下面 将整个vector进行embedding(乘上的矩阵W,一部分是xi需要乘的W,另一部分是pi相对应的Wp)
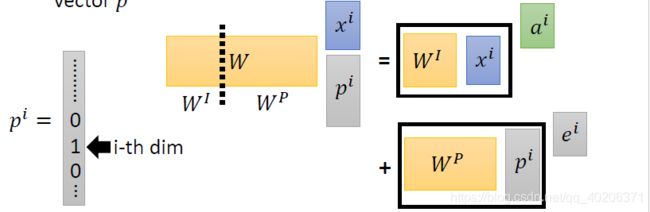
那么结果一部分是input embedding ai,另一部分是positional embedding ei
3.3.2 位置嵌入的思想
比较容易想到的第一个方法是取 [0,1] 之间的数分配给每个字,其中 0 给第一个字,1 给最后一个字,具体公式就是 PE=pos/(seq_l−1)。
这样做的问题在于,假设在较短文本中任意两个字位置编码的差为 0.0333,同时在某一个较长文本中也有两个字的位置编码的差是 0.0333。假设较短文本总共 30 个字,较长文本总共 90 个字。那么较短文本中的这两个字其实是相邻的,而较长文本中这两个字中间实际上隔了两个字。
这显然是不合适的,因为相同的差值,在不同的句子中却不是同一个含义。
另一个想法是线性的给每个时间步分配一个数字,也就是说,第一个单词被赋予 1,第二个单词被赋予 2,依此类推。
这种方式也有很大的问题:
1. 它比一般的字嵌入的数值要大,难免会抢了字嵌入的「风头」,对模型可能有一定的干扰;
2. 最后一个字比第一个字大太多,和字嵌入合并后难免会出现特征在数值上的倾斜。
3.3.3 理想情况下的位置嵌入
理想情况下,位置嵌入的设计应该满足以下条件:
- 它应该为每个字输出唯一的编码
- 不同长度的句子之间,任何两个字之间的差值应该保持一致
- 它的值应该是有界的
3.3.4 位置编码的实现
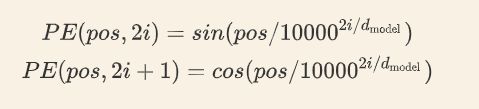
pos是一句话中某个字的位置,取值范围是[0,max_sequence_length](一个输入sequence的最大长度,理论上所有的sequence都需要补齐至这个长度)。
i 指的是字向量的维度序号,取值范围是 [0, embedding_dimension/2)。位置嵌入随着维度序号的增大,周期性变化会越来越慢(周期变大)。
dmodel指的就是 embedding_dimension 的值。
也就是说,我这个字在sequence中是第几位确定了之后,字里面的每一位信息我们都需要进行处理(奇数归奇数,偶数归偶数)。
每一个位置在 embedding dimension 维度上都会得到不同周期的 sin 和 cos 函数的取值组合,从而产生独一的纹理位置信息,最终使得模型学到位置之间的依赖关系和自然语言的时序特性。
3.3.5 位置编码举例
举一个例子,假设我们每一个word用16维表示(embedding_dimension),一个sequence最大100个word(max_sequence_length),那么我们positional encoding的维度为(100,16)
import matplotlib.pyplot as plt
import numpy as np
def getPositionEncoding(seq_len,dim,n=10000):
PE = np.zeros(shape=(seq_len,dim))
for pos in range(seq_len):
for i in range(int(dim/2)):
denominator = np.power(n, 2*i/dim)
PE[pos,2*i] = np.sin(pos/denominator)
PE[pos,2*i+1] = np.cos(pos/denominator)
return PE
PE = getPositionEncoding(seq_len=30, dim=100)
plt.matshow(PE)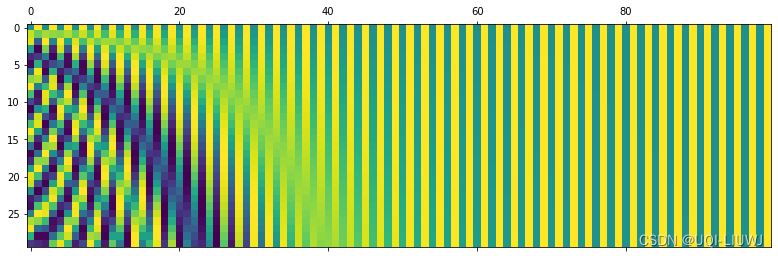
3.4 SELF-ATTENTION
对于输入的句子 X,通过 WordEmbedding 得到该句子中每个字的字向量,同时通过 Positional Encoding 得到所有字的位置向量。将两者相加(维度相同,可以直接相加),得到该字真正的向量表示。第 t 个字的向量记作 xt。
接着我们定义三个矩阵 Wq,Wk,Wv,使用这三个矩阵分别对所有的字向量进行三次线性变换,于是所有的字向量又衍生出三个新的向量 qt,kt,vt。(乘以一个矩阵,相当于一次线性变换)
我们将所有的 qt 向量拼成一个大矩阵,记作查询矩阵 Q。

至于这边除以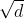 ,论文里面是这么说的:
,论文里面是这么说的:
![]()
我算出来是![]() ,不知道哪里出问题了
,不知道哪里出问题了
3.4.1 self-attention举例:
记q1=[1,0,2] 、K=[[0,4,2], [1,4,3], [1,0,1]]
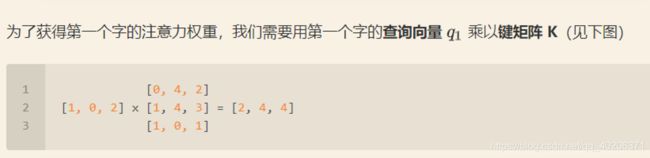
之后还需要将得到的值经过 softmax,使得它们的和为 1(见下图)。为了方便起见,我们将权重设置为[0,0.5,0.5]
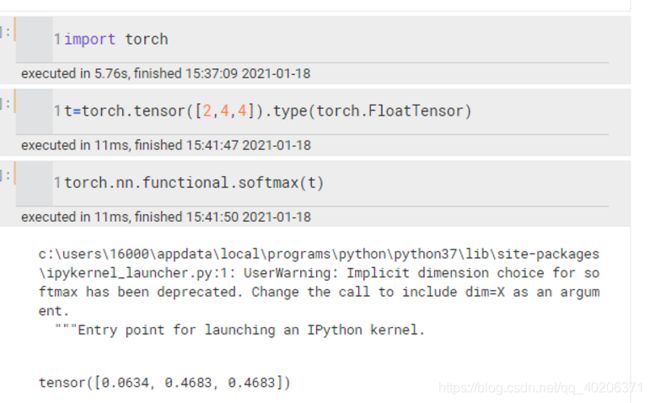
即V=[[1,2,3] , [2,8,0], [2,6,3]]

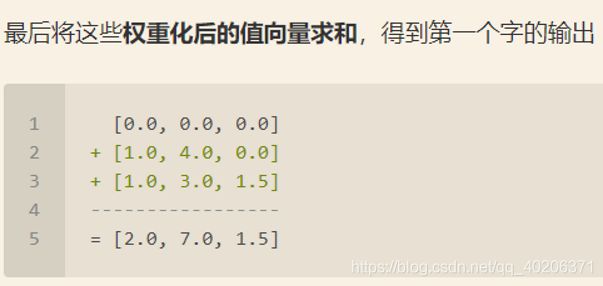
对其它的输入向量也执行相同的操作,即可得到通过 self-attention 后的所有输出。
3.4.2 self-attention 矩阵计算
第一步就不是计算某个时刻的 qt,kt,vt 了,而是一次计算所有时刻的 Q,K 和 V。计算过程如下图所示,这里的输入是一个矩阵 X,矩阵第 t 行表示第 t 个词的向量表示 xt。
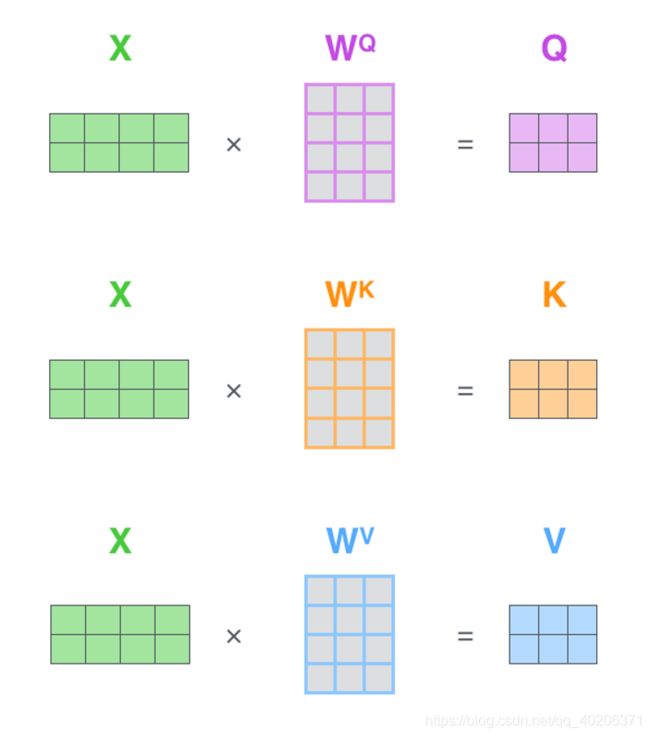

(这里配图错了,V应该在softmax的左边,左乘softmax的结果
Z的每一行都是X的每一个sequence的embedding
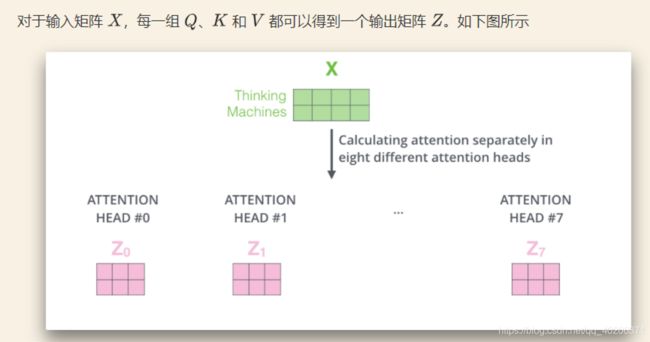
3.4.3 Multi-Head Attention
"Attention is all you need"中说到,进行 Multi-head Attention 的原因是将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息,最后再将各个方面的信息综合起来。
其实直观上也可以想到,如果自己设计这样的一个模型,必然也不会只做一次 attention,多次 attention 综合的结果至少能够起到增强模型的作用,也可以类比 CNN 中同时使用多个卷积核的作用。
直观上讲,多头的注意力有助于网络捕捉到更丰富的特征 / 信息。

3.4.4 padding mask
上面 Self Attention 的计算过程中,我们通常使用 mini-batch 来计算,也就是一次计算多句话。 X 的维度是 [batch_size, sequence_length],sequence_length 是句长,而一个 mini-batch 是由多个不等长的句子组成的。我们需要按照这个 mini-batch 中最大的句长(也就是3.3.4中所说的max_sequence_length)对剩余的句子进行补齐,一般用 0 进行填充,这个过程叫做 padding。
但这时在进行 softmax 就会产生问题。回顾 softmax 函数![]() ,其中
,其中![]() =1,是有值的。这样的话 softmax 中被 padding 的部分就参与了运算,相当于让无效的部分参与了运算,这可能会产生很大的隐患。
=1,是有值的。这样的话 softmax 中被 padding 的部分就参与了运算,相当于让无效的部分参与了运算,这可能会产生很大的隐患。
因此需要做一个 mask 操作,让这些无效的区域不参与运算(也就是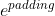 为0),一般是给无效区域加一个很大的负数偏置,即
为0),一般是给无效区域加一个很大的负数偏置,即

原来的矩阵(比如):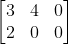
padding矩阵(padding的部分填负无穷,原来有值的部分填0):![]()
mask之后的结果:![]()
这样![]() ,所以padding部分不参与权重的计算(计算权重的时候是softmax,也就是Q和K乘积的结果,但是X padding部分为负无穷,进行线性变化后还是负无穷。传到Q和K里面还是负无穷。乘积结果也是负无穷。所以到softmax的时候也是负无穷)
,所以padding部分不参与权重的计算(计算权重的时候是softmax,也就是Q和K乘积的结果,但是X padding部分为负无穷,进行线性变化后还是负无穷。传到Q和K里面还是负无穷。乘积结果也是负无穷。所以到softmax的时候也是负无穷)
3.5 残差连接
这是一个cv ResNet里面的应用,这边就直接搬运过来了。
我们在上一步得到了经过 self-attention 加权之后的输出,也就是 Attention(Q, K, V),然后把他和原来X的embedding加起来做残差连接。

3.6 layer normalization

layer normalization的作用——每一个特征都满足标准正态分布
batch normalization的作用——每一个training example的各个特征之间满足正态分布
3.7 feed forward
linear——>relu——>linear
作用是提取特征(先维度增加,再维度减少,以保证输出和输入的维度一模一样【因为还要送入下一个encoder】)
3.8 decoder-masked self-attention
decoder的大部分在前面 Encoder 里我们已经介绍过了,但是 Decoder 由于其特殊的功能,因此在训练时会涉及到一些和encoder不同的细节。
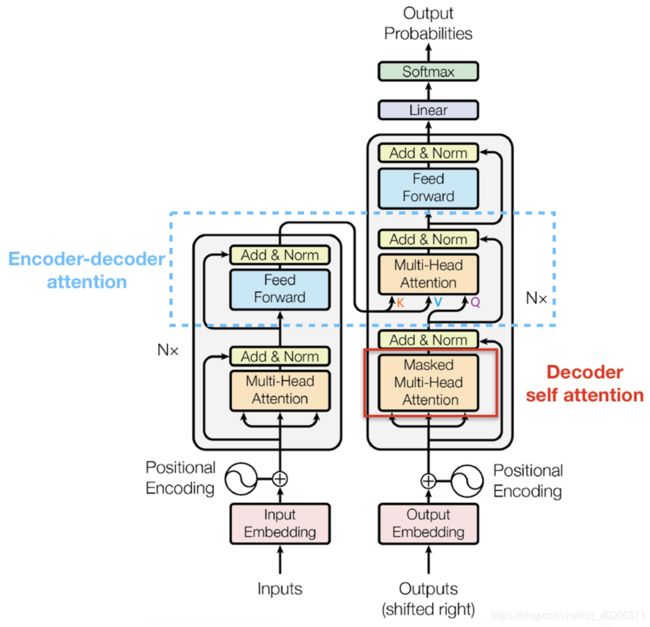
具体来说,传统 Seq2Seq 中 Decoder 使用的是 RNN 模型,因此在训练过程中输入 t 时刻的词,模型无论如何也看不到未来时刻的词,因为循环神经网络是时间驱动的,只有当 t 时刻运算结束了,才能看到 t+1 时刻的词。
而 Transformer Decoder 抛弃了 RNN,改为 Self-Attention,由此就产生了一个问题,在训练过程中,整个 ground truth 的sequence都暴露在 Decoder 中,不过不加以限制的话,任何时刻decoder都可以看到整个序列。这显然是不对的,我们需要对 Decoder 的输入进行一些处理,该处理被称为 decoder的Mask。



记V=
| V11 | V12 | V13 | V14 |
| V21 | V22 | V23 | V24 |
| V31 | V32 | V33 | V34 |
| V41 | V42 | V43 | V44 |
然后V左乘softmax的结果
| V11 | V12 | V13 | V14 | 1 | 0 | 0 | 0 | |
| V21 | V22 | V23 | V24 | × | 0.37 | 0.62 | 0 | 0 |
| V31 | V32 | V33 | V34 | 0.26 | 0.31 | 0.43 | 0 | |
| V41 | V42 | V43 | V44 | 0.21 | 0.26 | 0.26 | 0.26 |
第一个元素送入decoder之后,两者相乘的方式如下所示。也就是说,第一个送入decoder的元素,会影响到之后所有的output(因为之后的元素都可以知道这个元素的信息)
| V11 | V12 | V13 | V14 | 1 | 0 | 0 | 0 | |
| V21 | V22 | V23 | V24 | × | 0.37 | 0.62 | 0 | 0 |
| V31 | V32 | V33 | V34 | 0.26 | 0.31 | 0.43 | 0 | |
| V41 | V42 | V43 | V44 | 0.21 | 0.26 | 0.26 | 0.26 |
第二个元素送入decoder之后,两者相乘的方式如下所示。也就是说,第二个送入decoder的元素,会影响到之后所有的output(因为之后的元素都可以知道这个元素的信息)。但不可以影响第一个元素的output,因为第一个元素送入decoder的时候,还不知道第二个元素的信息。
| V11 | V12 | V13 | V14 | 1 | 0 | 0 | 0 | |
| V21 | V22 | V23 | V24 | × | 0.37 | 0.62 | 0 | 0 |
| V31 | V32 | V33 | V34 | 0.26 | 0.31 | 0.43 | 0 | |
| V41 | V42 | V43 | V44 | 0.21 | 0.26 | 0.26 | 0.26 |
3.9 Decoder-Masked Encoder-Decoder Attention
前面的masked self-attention指的是3.8节的mask方法,即上三角矩阵都是-inf。
4 transformer 总结
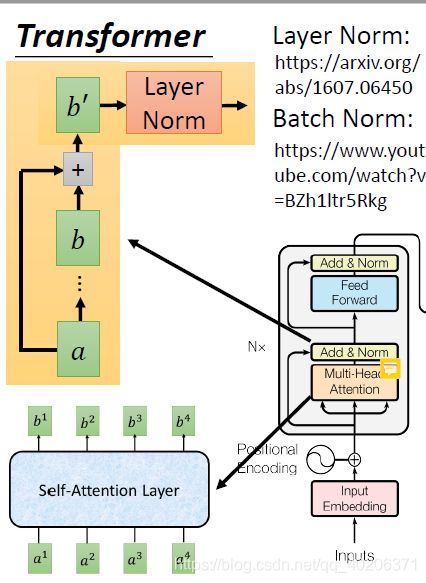
->encoder板块,我们的input先进行embedding,然后加上位置向量ei。
->之后的结果放入mult-head attention。
->接着进行add&layer norm(基本上RNN有的地方都有layer norm,transformer和RNN作用上可以互相代替)。

->decoder板块,首先我们最底下的输入是上一个time step的输出(一开始就是句子起始符)。
->然后也是加上位置向量ei。
->结果放入masked multihead attention
为什么要masked呢,因为我们输出的部分是一点一点变多的,这里我们只能看到我们目前已经生成了的部分的sequence。
->将这个sequence和encoder的输出放到一块,经过一个mult-head attention
->然后又是add&layer norm Linear output等等
4.1 stacked
输入 x1,x2 经 self-attention 层之后变成 z1,z2,然后和输入 x1,x2 进行残差连接,经过 LayerNorm 后输出给全连接层。
全连接层也有一个残差连接和一个 LayerNorm,最后再输出给下一个 Encoder(每个 Encoder Block 中的 FeedForward 层权重都是共享的)。

decoder也是一样,每层decoder将自己的输出,以及encoder的输出并在一块,送给下一个decoder,作为下一层decoder的Q,K,V。