衡量目标检测模型性能--mAP(mean average precision)
使用机器学习解决常见目标检测问题通常有多个模型可用,每个模型基于不同的因素性能表现存在差异。
每个模型通过在数据集(训练、验证集)上的评判性能指标,性能衡量通过不同的统计特征进行评价--accuracy,precision,recall等等,统计参数的选择依赖于应用场景和案例。对于每一个应用,找到一个衡量指标对比模型的性能非常有必要。
这里讨论的是目标检测问题中常见的度量方法--mean average precision,mAP
目标检测器尽管能检测到图像中有一只猫,如果没有找到猫在什么位置,这也是不行的。基于语义甚至实例的分割检测方法需要预测图像中的目标位置,这时就用到mAP。
目标检测涉及到对不同类型的目标的分类和定位,即localisation + classifying
Gronud truth
对于任何算法,评价其性能时都需要与ground turth进行比较。我们仅仅知道训练集,验证集和测试集的ground truth信息。对于目标检测问题,ground truth包括图像,图像中的目标类,每一个类的真实的bounding box

例如这里的一张图像,以及一些注释信息(bounding box,class text)
而下图是模型在训练时的图像
3个数量的几何定义了ground truth:
| Class | X coordinate | Y coordinate | Box Width | Box Height |
|---|---|---|---|---|
| Dog | 100 | 600 | 150 | 100 |
| Horse | 700 | 300 | 200 | 250 |
| Person | 400 | 400 | 100 | 500 |
让我们亲自动手,看看如何计算mAP。
我将在另一篇文章中介绍各种对象检测算法,它们的方法和性能。 现在,假设我们有一个训练有素的模型,我们正在验证集上评估其结果。
mAP
让我们说原始图像和GT注释就像我们在上面看到的那样。 训练和验证数据以相同的方式注释所有图像。
该模型将返回大量预测,但在这些预测中,其中大多数将具有非常低的置信度得分,因此我们仅考虑高于某个报告的置信度得分的预测。
我们通过模型运行原始图像,这是在置信度阈值处理后对象检测算法返回的带bounding box的图像:
现在,由于我们人类是专家物体探测器,我们可以说这些探测是正确的。 但是我们如何量化呢?
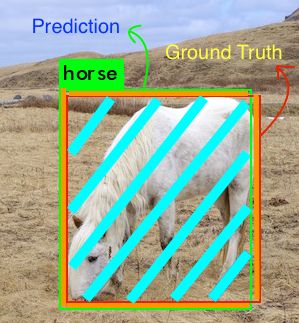
我们首先需要知道判断每个检测的正确性。 给定边界框正确性的度量标准是 - IoU -。 这是一个非常简单的视觉量。
就单词而言,有些人会说这个名字是自我解释的,但我们需要更好的解释。 需要详细解释,有一篇非常好的文章,可以参考。
IOU
iou: ∩∪比:

- mAP: mean Average Precision, 即各类别AP的平均值
- AP: PR曲线下面积,后文会详细讲解
- PR曲线: Precision-Recall曲线
- Precision: TP / (TP + FP)
- Recall: TP / (TP + FN)
- TP: IoU>0.5的检测框数量(同一Ground Truth只计算一次)
- FP: IoU<=0.5的检测框,或者是检测到同一个GT的多余检测框的数量
- FN: 没有检测到的GT的数量
识别正确的检测并计算精度percision和召回率recall
对于计算精度和召回,与所有机器学习问题一样,我们必须识别真阳性,误报,真阴性和假阴性。
为了得到真正的肯定和误报,我们使用IoU。使用IoU,我们现在必须确定检测(正)是否正确(真)或不正确(假)。最常用的阈值是0.5 - 即如果IoU> 0.5,则认为是真阳性,否则它被认为是假阳性。 COCO评估指标建议跨越各种IoU阈值进行测量,但为简单起见,我们将坚持使用0.5,这是PASCAL VOC指标。
为了计算Recall,我们需要负数的计数。由于我们没有预测某个物体的图像的每个部分都被认为是负面的,因此测量“真实”负片有点徒劳。所以我们只测量“假”否定词即。我们模型错过的对象。
此外,另一个需要考虑的因素是模型为每次检测报告的置信度。通过改变我们的置信度阈值,我们可以改变预测框是正面还是负面。基本上,高于阈值的所有预测(Box + Class)都被认为是Positive box,而它下面的所有预测都是Negatives。
现在,对于每个图像,我们都有地面实况数据,它告诉我们该图像中给定类的实际对象的数量。
我们现在为模型报告的每个正检测框计算具有基础事实的IoU。使用此值和我们的IoU阈值(比如0.5),我们计算图像中每个类的正确检测数(A)。这用于计算每个类的精度[TP /(TP + FP)]
精度= TP /(TP + FP)
由于我们已经计算了正确预测的数量(A)(真阳性)和错过的检测(假阳性)因此我们现在可以使用该公式计算该类的模型的召回(A / B)。
召回= TP /(TP + FN)
计算mAP
使用Pascal VOC challenge评估度量
平均精度是一个具有不同定义的术语。 此度量标准通常用于信息检索和目标检测的域中。 这两个域都有不同的计算mAP的方法。 我们今天将讨论与物体检测相关的mAP。
mAP的对象检测定义首先在PASCAL视觉对象类(VOC)挑战中形式化,其中包括各种图像处理任务。 对于确切的论文,请参阅此。
我们使用相同的方法计算精度和召回,如上一节所述。
但是,如上所述,我们至少还有2个其他变量决定了Precision和Recall的值,它们是IOU和置信度阈值。
IOU是一个简单的几何度量标准,我们可以轻松地将其标准化,例如PASCAL VOC challange基于50%IOU评估mAP,而COCO Challenge更进一步评估mAP在5%至95%的各种阈值范围内。 另一方面,置信因子在不同的模型中有所不同,我的模型设计中50%的置信度可能相当于对其他人的模型设计的80%信心,这会改变精确回忆曲线的形状。 因此,PASCAL VOC组织者提出了一种解释这种变化的方法。
我们现在需要一个度量标准来以模型无关的方式评估模型。
paper中提出计算一种称为AP的度量:平均精度
For a given task and class, the precision/recall curve is
computed from a method’s ranked output. Recall is defined
as the proportion of all positive examples ranked above a
given rank. Precision is the proportion of all examples above
that rank which are from the positive class. The AP summarises
the shape of the precision/recall curve, and is de-
fined as the mean precision at a set of eleven equally spaced
recall levels [0,0.1,...,1]:
这意味着我们选择了11个不同的置信度阈值(确定“等级”)。 阈值应该是这些置信度值的Recall为0,0.1,0.2,0.3,......,0.9和1.0。 现在,AP被定义为这些所选11个Recall值的Precision值的平均值。 这使得mAP成为整个精确回忆曲线的整体视图。
本文进一步详细说明了计算上述计算中使用的精度。
The precision at each recall level r is interpolated by taking
the maximum precision measured for a method for which
the corresponding recall exceeds r:
基本上我们使用给定召回值的最大精度。
因此,mAP是上面测量的所有类别中所有平均精度值的平均值。
这实际上是如何计算物体检测评估的平均平均精度。 有时可能会有一些变化,例如COCO评估更严格,使用各种IOU和对象大小强制执行各种指标(此处有更多详细信息)。
比较mAP值时要注意的一些要点:
mAP始终在数据集上计算。
虽然解释模型输出的绝对量化并不容易,但是mAP通过一个非常好的相对度量来帮助我们。 当我们在流行的公共数据集上计算此度量标准时,该度量标准可以轻松用于比较新旧对象检测方法。
根据类在训练数据中的分布方式,平均精度值可能会从某些类(具有良好训练数据)的非常高到非常低(对于数据较少/较差的类)。 所以你的mAP可能是适中的,但你的模型可能对某些类非常好,对某些类来说真的很糟糕。 因此,建议在分析模型结果时查看单个类别的平均精度。 这些值也可以作为添加更多训练样本的指标。
一些详解见知乎回答