【建模算法】KNN分类(Python实现)
【建模算法】KNN分类(Python实现)
01 算法用途
KNN(K- Nearest Neighbor)法即K最邻近法,最初由 Cover和Hart于1968年提出,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。KNN算法的核心思想是,如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
02 实例分析
用经典iris莺尾花标准数据集为例,最后一列class为分类结果,一共有3类,标签设置为(0,1,2),把前面几个特征指标作为自变量进行类别判定。
| sepal_length_cm | sepal_width_cm | petal_length_cm | petal_width_cm | class |
|---|---|---|---|---|
| 6.4 | 2.8 | 5.6 | 2.2 | 2 |
| 5.0 | 2.3 | 3.3 | 1.0 | 1 |
| 4.9 | 2.5 | 4.5 | 1.7 | 2 |
| 4.9 | 3.1 | 1.5 | 0.1 | 0 |
03 原理解析
KNN的算法原理通俗易懂,已知带有不同类别标签的数据,有测试数据要根据特征进⾏判别。计算测试数据到所有已知标签数据的距离,确定⼀个值K,将距离从小到⼤排序,识别前K个最⼩距离(通常采⽤欧式距离)分别属于哪类,统计前K个最小距离中不同类别的个数,哪类出现次数最多就被判定为哪类。
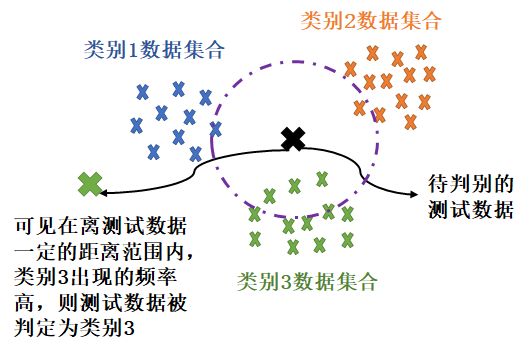
算法步骤:
(1)计算待测试数据与各训练数据的距离
(2)将计算的距离进行由小到大排序
(3)找出距离最小的k个值
(4)计算找出的值中每个类别的频次
(5) 返回频次最高的类别
Python源码:
#完整代码:
import csv
import random
import numpy as np
import operator
from sklearn.neighbors import KNeighborsClassifier
def openfile(filename):
"""
打开数据集,进行数据处理
:param filename: 数据集的路径
:return: 返回数据集的数据,标签,以及标签名
"""
with open(filename) as csv_file:
data_file = csv.reader(csv_file)
temp = next(data_file)
# 数据集中数据的总数量
n_samples = int(temp[0])
# 数据集中特征值的种类个数
n_features = int(temp[1])
# 标签名
target_names = np.array(temp[2:])
# empty()函数构造一个未初始化的矩阵,行数为数据集数量,列数为特征值的种类个数
data = np.empty((n_samples, n_features))
# empty()函数构造一个未初始化的矩阵,行数为数据集数量,1列,数据格式为int
target = np.empty((n_samples,), dtype=np.int)
for i, j in enumerate(data_file):
# 将数据集中的将数据转化为矩阵,数据格式为float
# 将数据中从第一列到倒数第二列中的数据保存在data中
data[i] = np.asarray(j[:-1], dtype=np.float64)
# 将数据集中的将数据转化为矩阵,数据格式为int
# 将数据集中倒数第一列中的数据保存在target中
target[i] = np.asarray(j[-1], dtype=np.int)
# 返回 数据,标签 和标签名
return data, target, target_names
def random_number(data_size):
"""
该函数使用shuffle()打乱一个包含从0到数据集大小的整数列表。因此每次运行程序划分不同,导致结果不同
改进:
可使用random设置随机种子,随机一个包含从0到数据集大小的整数列表,保证每次的划分结果相同。
:param data_size: 数据集大小
:return: 返回一个列表
"""
number_set = []
for i in range(data_size):
number_set.append(i)
random.shuffle(number_set)
return number_set
def split_data_set(data_set, target_data, rate=0.25):
"""
说明:分割数据集,默认数据集的25%是测试集
:param data_set: 数据集
:param target_data: 标签数据
:param rate: 测试集所占的比率
:return: 返回训练集数据、训练集标签、训练集数据、训练集标签
"""
# 计算训练集的数据个数
train_size = int((1-rate) * len(data_set))
# 获得数据
data_index = random_number(len(data_set))
# 分割数据集(X表示数据,y表示标签),以返回的index为下标
x_train = data_set[data_index[:train_size]]
x_test = data_set[data_index[train_size:]]
y_train = target_data[data_index[:train_size]]
y_test = target_data[data_index[train_size:]]
return x_train, x_test, y_train, y_test
def data_diatance(x_test, x_train):
"""
:param x_test: 测试集
:param x_train: 训练集
:return: 返回计算的距离
"""
# sqrt_x = np.linalg.norm(test-train) # 使用norm求二范数(距离)
distances = np.sqrt(sum((x_test - x_train) ** 2))
return distances
def knn(x_test, x_train, y_train, k):
"""
:param x_test: 测试集数据
:param x_train: 训练集数据
:param y_train: 测试集标签
:param k: 邻居数
:return: 返回一个列表包含预测结果
"""
# 预测结果列表,用于存储测试集预测出来的结果
predict_result_set=[]
# 训练集的长度
train_set_size = len(x_train)
# 创建一个全零的矩阵,长度为训练集的长度
distances = np.array(np.zeros(train_set_size))
# 计算每一个测试集与每一个训练集的距离
for i in x_test:
for indx in range(train_set_size):
# 计算数据之间的距离
distances[indx] = data_diatance(i, x_train[indx])
# 排序后的距离的下标
sorted_dist = np.argsort(distances)
class_count = {}
# 取出k个最短距离
for i in range(k):
# 获得下标所对应的标签值
sort_label = y_train[sorted_dist[i]]
# 将标签存入字典之中并存入个数
class_count[sort_label]=class_count.get(sort_label, 0) + 1
# 对标签进行排序
sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True)
# 将出现频次最高的放入预测结果列表
predict_result_set.append(sorted_class_count[0][0])
# 返回预测结果列表
return predict_result_set
def score(predict_result_set, y_test):
"""
:param predict_result_set: 预测结果列表
:param y_test: 测试集标签
:return: 返回测试集精度
"""
count = 0
for i in range(0, len(predict_result_set)):
if predict_result_set[i] == y_test[i]:
count += 1
score = count / len(predict_result_set)
return score
if __name__ == "__main__":
iris_dataset = openfile('iris_data.csv')
x_train, x_test, y_train, y_test = split_data_set(iris_dataset[0], iris_dataset[1])
result = knn(x_test,x_train, y_train, 6)
print("原有标签:", y_test)
# 为了方便对比查看,此处将预测结果转化为array,可直接打印结果
print("预测结果:", np.array(result))
score = score(result, y_test)
print("手写KNN算法准确率:%.2f" % score)
# 以下为sklearn库自带KNN算法
# 设置邻居数
knn = KNeighborsClassifier(n_neighbors=6)
# 构建基于训练集的模型
knn.fit(x_train, y_train)
# 对x_test预测结果
prediction=[]
for i in range(len(x_test)):
prediction+=list(knn.predict(x_test[i].reshape(1,4)))
print("原有标签:",y_test)
print("预测结果:",np.array(prediction))
# 得出测试集x_test测试集的分数
print("sklearn库自带KNN算法准确率:{:.2f}".format(knn.score(x_test,y_test)))
以上分别使用原理手写代码和sklearn库自带KNN算法。因为随机选取训练集和测试集,每次结果可能不一样,运行三次结果如下:
第一次运行:

第二次运行:

第三次运行:

可见用原理手写KNN算法和sklearn库自带KNN算法效果是一样的,有时候会更好。