【mAP】关于目标检测mAP的一些理解
mAP是目标检测中的基本指标,详细理解有助于我们评估算法的有效性,并针对评测指标对算法进行调整。
1.基本概念定义
- 在目标检测中IoU为检测框与GroundTruth重叠的比例,如果大于0.5则算作正确True,小于0.5则算作错误False;
其中0.5是VOC比赛中设定的阈值,具体见论文"The PASCAL Visual Object Classes (VOC) Challenge"Page_11。需要说明的是,阈值的改变会影响检测结果,TP\FP\FN\TN等都会随着阈值的改变而改版。
具体的IoU定义和计算如下图所示:
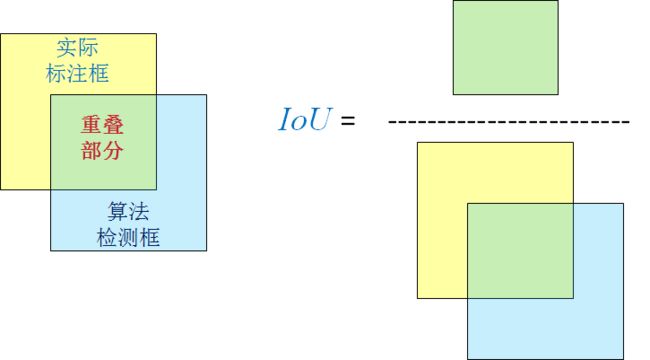
对于目标检测来说,IoU大于阈值、检测到框算作是positive;
- 真阳性TP:正确样本预测为正,在目标检测中为IoU大于阈值记为TP;
- 假阳性FP:错误样本预测为正,检测框的IoU小于阈值记为FP;
- 假阴性FN:正确样本预测为负,没有检测到框;
- 真阴性TN:错误样本预测为负;
对每个样本的检测可以通过上面TP/FP/FN的计数来计算出精度与召回率。
-
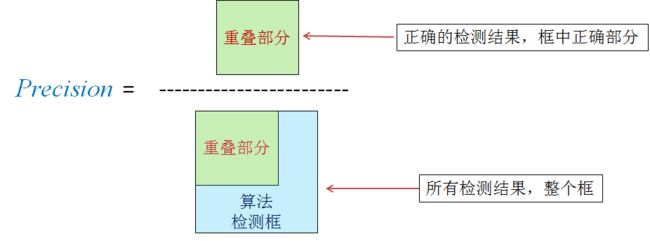
Precision精度,即TP/(TP+FP)。指所有结果中正确的检索所占比例。结果中包含了真阳性结果TP和假阳性结果FP。其含义为所有被预测为正类的结果(其中也包含了被错误预测成正类的FP)中预测正确的结果所占比例。
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP+FP} Precision=TP+FPTP -
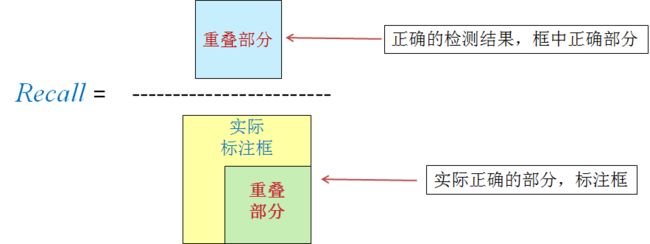
Recall召回率,即TP/(TP+FN)。指模型查找出正确对象的概率。其中包含了正确预测的正类TP,也包括了将正类错误预测成负类的FN。召回率的本质可以理解为查全率,即结果中的正样本占全部正样本的比例。
R e c a l l = T P T P + F N Recall = \frac{TP}{TP+FN} Recall=TP+FNTP -
PR:精度-召回率( P r e c i s i o n − R e c a l l Precision-Recall Precision−Recall)曲线。这条曲线的两个变量程负相关,精度越高,召回率越低;召回率越高,精度越低。如果将所有对象都预测为正类,没有被错误预测成负类的正类(FN为0)那么召回率将为100%;如果将所有对象的预测都为负,没有被错误预测成正的样本,那么精度就将为100%,这两个指标间存在着此消彼长的关系,理想的曲线是向右上方凸出的、包围面积大的曲线。
-
AP均匀精度Average Precision:PR曲线下所围成的面积,面积越大越好;这里的average指的是针对不同recall的平均精度。
-
mAP平均均匀精度,mean Average Precision,指各类计算出AP在不同类别上的均值。这里的mean指的是对于检测算法在数据集上各类对象的表现。
-
Top-1/Top 错误率:指的是预测概率最高的类别输入目标类别的准确率。top1就是最高类别为目标类别的准确率,top5就是最高的五个中命中目标类别的准确率。
2.AP计算
要计算mAP,首先需要计算每一个类别的AP值,主要有两种方法来计算PR曲线下的均值。
- 一种方法是选取 R e c a l l > = [ 0 : 0.1 : 1 ] Recall>=[0:0.1:1] Recall>=[0:0.1:1]等11个值时,其recall>当前recall对应精度precision的最大值,并由这11个最大精度值求取均值即为AP。这种方法也称为11-point interpolated average precision。根据论文对AP的定义:
A P = 1 11 ∑ r ⊂ 0.0.1 , . . . , 1 p i n t e r p ( r ) AP = \frac{1}{11}\sum \limits_{r\subset{0.0.1,...,1}}p_{interp}(r) AP=111r⊂0.0.1,...,1∑pinterp(r)
where: p i n t e r p ( r ) = max r ~ > = r ( r ~ ) p_{interp}(r)=\max \limits_{\tilde{r}>=r}(\tilde{r}) pinterp(r)=r~>=rmax(r~)
举个栗子,如果对于待检测的图像里,我们要检测犬这个类别并计算AP,网络针对这些图片输出了bbox(如果我们取IoU>0.5为正例的话,对应groundTruth为1):
| box num | confidence | label-GT |
|---|---|---|
| 0 | 0.9 | 1 |
| 1 | 0. 85 | 1 |
| 2 | 0. 7 | 0 |
| 3 | 0. 6 | 0 |
| 4 | 0. 7 | 1 |
| 5 | 0. 7 | 0 |
| 6 | 0. 65 | 1 |
| 7 | 0. 78 | 1 |
| 8 | 0. 71 | 1 |
| 8 | 0. 7 | 1 |
| 9 | 0. 8 | 0 |
| 10 | - | 1 |
| 11 | 0.51 | 1 |
那么此时我们可以看到,这是十个独立的框框,其中正例为TP=7(0,1,4,6,7,8,10,11),负例FP=5(2,3,5,9,重复检测的8 也算),GT10(一共有八个GT=1)没有检测到那么FN=1.所以根据上面的计算公式我们将按照执行度排序后给出对应的精度和召回率:
| box num | confidence | label-GT | rank | precision | recall |
|---|---|---|---|---|---|
| 0 | 0.9 | 1 | *1 | pr = 1/(1+0) = 1 | recall = 1/8=0.13 |
| 1 | 0. 85 | 1 | *2 | pr =2/(2+0)=1 | recall =2/8 = 0.25 |
| 9 | 0. 8 | 0 | *3 | pr = 2/(2+1)=0.66 | recall = 2/8 =0.25 |
| 7 | 0. 78 | 1 | *4 | pr = 3/(3+1) = 0.75 | recall =3/8 =0.38 |
| 8 | 0. 71 | 1 | *5 | pr =4/(4+1) =0.8 | recall = 4/8 = 0.5 |
| 2 | 0. 7 | 0 | *6 | pr = 4/(4+2)= 0.66 | recall = 4/8 =0.5 |
| 4 | 0. 7 | 1 | *7 | pr = 5/(5+2) = 0.71 | recall = 5/8 = 0.63 |
| 5 | 0. 7 | 0 | *8 | pr = 5/(5+3) = 0.63 | recall = 5/8 =0.63 |
| 8 | 0. 7 | 1 | *9 | pr = 5/(5+4) =0.55 | recall = 5/8=0.63 |
| 6 | 0. 65 | 1 | *10 | pr =6/(6+4) = 0.6 | recall = 6/8 = 0.75 |
| 3 | 0. 6 | 0 | *11 | pr = 6/(6+5) =0.55 | recall = 6/8= 0.75 |
| 11 | 0.51 | 1 | *12 | pr = 7/(7+5) = 0.54 | recall = 7/8=0.88 |
| 10 | - | 1 | *12 | pr = 7/(7+5)=0.54 | recall = 7/8 =0.88 |
随后计算AP,选取Recall>=[0:0.1:1]精度最大值:1,1,1,0.8,0.8,0.8,0.71,0.6,0.54.0,0,。AP = sum(1,1,1,0.8,0.8,0.8,0.71,0.6,0.54.0,0)/11 = 0.66.
随后,对于猫猫、狗狗、浣熊、熊猫等等各个类别的AP都求出来以后在类别上做平均就是mAP值了。
- 另一种方法是针对每一个不同Recall值(M个正例就有M个recall值),选取大于Recall时的最大精度值,并基于这些值计算AP,也即计算每一个recall区间对应pr曲线下的面积。
上面例子中有八个正例,对于的recall就出recall>=对应recall(包括0,1)的精度最大值:
r e c a l l : 0 , 0.13 , 0.25 , 0.38 , 0.5 , 0.63 , 0.75 , 0.88 , 1 recall:0,0.13,0.25,0.38,0.5,0.63,0.75,0.88,1 recall:0,0.13,0.25,0.38,0.5,0.63,0.75,0.88,1
p r e c i s i o n m a x : 1 , 0.8 , 0.8 , 0.8 , 0.71 , 0.6 , 0.54 , 0 precisionmax:1,0.8,0.8,0.8,0.71,0.6,0.54,0 precisionmax:1,0.8,0.8,0.8,0.71,0.6,0.54,0
A P = ( 0.13 − 0 ) ∗ 1 + ( 0.25 − 0.13 ) ∗ 0.8 + ( 0.38 − 0.25 ) ∗ 0.8 + ( 0.5 − 0.38 ) ∗ 0.8 + ( 0.63 − 0.5 ) ∗ 0.71 + ( 0.75 − 0.63 ) ∗ 0.6 + ( 0.88 − 0.75 ) ∗ 0.54 + ( 1 − 0.88 ) ∗ 0 = 0.6605 AP = (0.13-0)*1+(0.25-0.13)*0.8+(0.38-0.25)*0.8+(0.5-0.38)*0.8+(0.63-0.5)*0.71+(0.75-0.63)*0.6+(0.88-0.75)*0.54+(1-0.88)*0 = 0.6605 AP=(0.13−0)∗1+(0.25−0.13)∗0.8+(0.38−0.25)∗0.8+(0.5−0.38)∗0.8+(0.63−0.5)∗0.71+(0.75−0.63)∗0.6+(0.88−0.75)∗0.54+(1−0.88)∗0=0.6605
ref
https://www.zhihu.com/question/53405779/answer/419532990
https://datascience.stackexchange.com/questions/25119/how-to-calculate-map-for-detection-task-for-the-pascal-voc-challenge
3.mAP计算
mAP指的是对所有类别都计算好AP,然后在类别上求平均即可得到mAP
∑ c l a s s i n A P i \sum^{n}_{class_i}AP_i classi∑nAPi
4.实际代码(以Gluon为例)
#line 194
#https://github.com/dmlc/gluon-cv/blob/master/gluoncv/utils/metrics/voc_detection.py
def _recall_prec(self):
""" get recall and precision from internal records """
n_fg_class = max(self._n_pos.keys()) + 1
prec = [None] * n_fg_class #每个类别中样本数量的字典,定义精度prec
rec = [None] * n_fg_class #定义召回率recall
for l in self._n_pos.keys():
score_l = np.array(self._score[l]) #confidence,预测bbox的置信度
match_l = np.array(self._match[l], dtype=np.int32) #预测结果,后面用于匹配正样本和负样本,match上的为正例,预测正确。
#self._score,self._match,self._n_pos,参考代码的line 43-45,来自于from collections import defaultdict
order = score_l.argsort()[::-1] #对预测结果置信度进行排序
match_l = match_l[order] #按照置信度重新排序样本
tp = np.cumsum(match_l == 1) #正例,正确的个数TP
fp = np.cumsum(match_l == 0) #负例,错误的个数FP
# If an element of fp + tp is 0,
# the corresponding element of prec[l] is nan.
with np.errstate(divide='ignore', invalid='ignore'):
prec[l] = tp / (fp + tp) #按照顺序计算精度
# If n_pos[l] is 0, rec[l] is None.
if self._n_pos[l] > 0:
rec[l] = tp / self._n_pos[l] #计算召回率(查全率,分母为所有正确的个数)
return rec, prec
#
# 得到精度和召回率的array后,就可以计算AP了:
#
```python
#方法一
def _average_precision(self, rec, prec):
"""
calculate average precision, override the default one,
special 11-point metric
Params:
----------
rec : numpy.array
cumulated recall
prec : numpy.array
cumulated precision
Returns:
----------
ap as float
"""
if rec is None or prec is None:
return np.nan
ap = 0.
for t in np.arange(0., 1.1, 0.1): #十一个点的召回率,对应精度最大值
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(np.nan_to_num(prec)[rec >= t])
ap += p / 11. #加权平均
return ap
#方法二
def _average_precision(self, rec, prec):
"""
calculate average precision
Params:
----------
rec : numpy.array
cumulated recall
prec : numpy.array
cumulated precision
Returns:
----------
ap as float
"""
if rec is None or prec is None:
return np.nan
# append sentinel values at both ends
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], np.nan_to_num(prec), [0.]))
# 将精度和召回率值全部链接起来
# compute precision integration ladder
# 整数间隔内的最大值,对应正例的recall计算max precision
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# 计算精度
# look for recall value changes
i = np.where(mrec[1:] != mrec[:-1])[0]
# sum (\delta recall) * prec 将所有的精度和召回率加起来得到ap
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
ref:
https://www.zhihu.com/question/53405779/answer/419532990
code:https://github.com/dmlc/gluon-cv/blob/master/gluoncv/utils/metrics/voc_detection.py
Detectron:https://github.com/facebookresearch/Detectron/blob/master/detectron/datasets/voc_eval.py
https://blog.csdn.net/chengyq116/article/details/81290447
https://blog.csdn.net/zdh2010xyz/article/details/54293298
https://blog.csdn.net/littlehaes/article/details/83278256
https://blog.csdn.net/lz_peter/article/details/78133069
https://www.jianshu.com/p/1afbda3a04ab
https://datascience.stackexchange.com/questions/25119/how-to-calculate-map-for-detection-task-for-the-pascal-voc-challenge
https://en.wikipedia.org/wiki/Precision_and_recall
Threshold P11 of VOC :http://homepages.inf.ed.ac.uk/ckiw/postscript/ijcv_voc09.pdf
Voc evalutaion:http://host.robots.ox.ac.uk/pascal/VOC/voc2012/htmldoc/devkit_doc.html#SECTION00044000000000000000
code:https://github.com/dmlc/gluon-cv/blob/master/gluoncv/utils/metrics/voc_detection.py
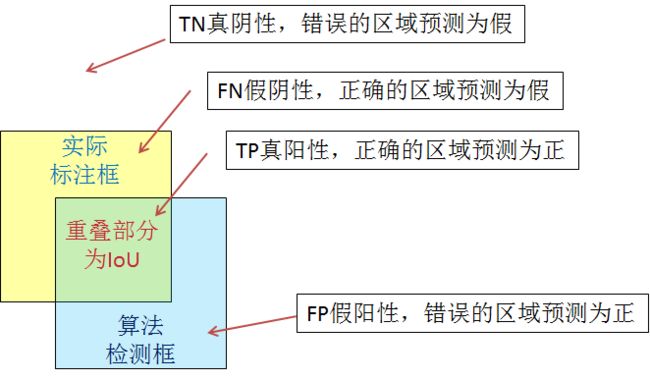
关于TP/FP/FN以及精度召回率的另一种解释
如果使用目标检测的概念来辅助理解的话,我们可以将算法检测框看做是所有预测为正的区域(包含了TP,FP),而将原始标注框看做是所有实际正确的区域(包含了FN,TP):
精度:如果利用目标检测中框的概念来理解可以看做是下图的表示,其中检测框为预测认为Positive的、重叠部分为实际正确的部分:
召回率:而原始的标注框可以表示所有的True、重叠部分为实际正确的部分,也即为召回率: