Hive3.1.2+大数据引擎Tez0.9.2安装部署到使用测试(踩坑详情)
写在前面的话:本篇博客为原创,如果安装版本号和我一样的可以直接在我公众号下载我编译好的,回复tez即可,欢迎讨论
欢迎关注公众号:后来X
安装tez的过程可谓是坑有点多,编译还是相对简单的。现在复盘一下,以下是我的版本号
| 框架 | 版本号 |
|---|---|
| Hadoop | 3.1.3 |
| Hive | 3.1.2 |
| Tez | 0.10.1 |
能看到这篇文章的,说明各位也能知道tez是干啥的,这里就不介绍了,直接开始安装
我们可以在官网看到,Hadoop3.X版本要使用Tez引擎是需要自己编译的(对于0.8.3和更高版本的Tez,Tez需要Apache Hadoop的版本为2.6.0或更高。对于0.9.0及更高版本的Tez,Tez需要Apache Hadoop为2.7.0或更高版本。)
如果大家在编译过程中遇到一些问题,也可以直接联系我(l970306love),说不定你的这个问题我正好遇到过,可以节省很多没必要的时间,哈哈。
1、编译Tez0.10.1过程:遵循官网流程(我这里以Tez0.9.2举例,版本号和我一样的可以直接下载我编译好的,下面贴链接)
链接:https://pan.baidu.com/s/1FQQh_bPrq0pu6CUe12nSxQ
提取码:hi3j
- 下载tez的src.tar.gz源码包,附官方下载链接(http://tez.apache.org/releases/index.html),下载之后上传到linux系统中,并且解压出来,我以下载的是 0.9.2举例,新版的tez0.10.1需要在github下载,附链接(https://github.com/apache/tez)


- 需要在pom.xml中更改hadoop.version属性的值,以匹配所使用的hadoop分支的版本。我这里是Apache Hadoop 3.1.3

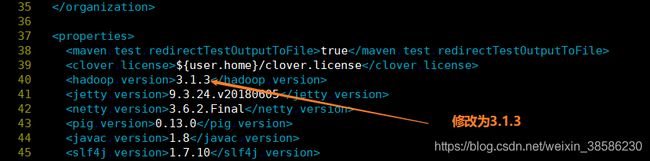
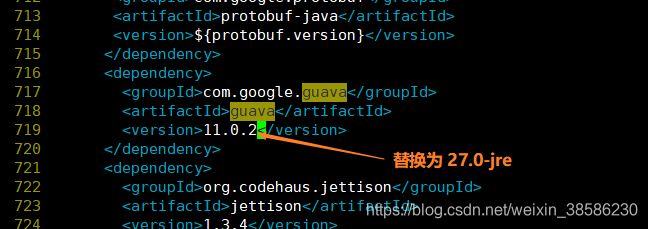
- ,还有就是guava的版本,这个插件的版本也是至关重要,希望大家提前修改,把这个问题扼杀在摇篮里,我们可以看到hadoop 3.1.3使用的guava版本是27.0-jre,而tez默认的是11.0.2,所以一定要修改,否则后期在装好tez也会不能用。
[later@bigdata101 lib]# cd /opt/module/hadoop-3.1.3/share/hadoop/common/lib/
[later@bigdata101 lib]# ls |grep guava
guava-27.0-jre.jar
listenablefuture-9999.0-empty-to-avoid-conflict-with-guava.jar

- 还有就是在tez编译时,tez-ui这个模块是耗时耗力不讨好,而且没啥用,所以我们可以直接跳过

- 这一步结束后就是开始编译了,首先要有编译环境是必须的,所以要安装maven,安装git,这两块参考我之前的文章(https://blog.csdn.net/weixin_38586230/article/details/105725346),最后安装编译工具
### 安装编译工具
yum -y install autoconf automake libtool cmake ncurses-devel openssl-devel lzo-devel zlib-devel gcc gcc-c++
- 先安装protobuf(官网让安装2.5.0版本的),下载链接(https://github.com/protocolbuffers/protobuf/tags)下好源码包后,解压,并且编译protobuf 2.5.0
./configure
make install
- 开始编译Tez(这个过程的时间就因人而异了)
mvn clean package -DskipTests=true -Dmaven.javadoc.skip=true`
- 编译成功后,包会在apache-tez-0.9.2-src/tez-dist/target/目录下,我们需要的是这连两个,我截图的是0.10.1,不过除了版本号其余的是一样的

2、为Hive配置Tez了
- 将tez安装包拷贝到集群,并解压tar包,注意解压的是minimal
mkdir /opt/module/tez
tar -zxvf /opt/software/tez-0.10.1-SNAPSHOT-minimal.tar.gz -C /opt/module/tez
- 上传tez依赖到HDFS(上传的是不带minimal的那个)
hadoop fs -mkdir /tez(集群创建/tez路径,然后再上传,注意路径)
hadoop fs -put /opt/software/tez-0.10.1-SNAPSHOT.tar.gz /tez
- 新建tez-site.xml在$HADOOP_HOME/etc/hadoop/路径下(注意,不要放在hive/conf/目录下,不生效),记得把tez-site.xml同步到集群其他机器。
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 注意你的路径以及文件名是否和我的一样 -->
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.10.1-SNAPSHOT.tar.gz</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.am.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.am.resource.cpu.vcores</name>
<value>1</value>
</property>
<property>
<name>tez.container.max.java.heap.fraction</name>
<value>0.4</value>
</property>
<property>
<name>tez.task.resource.memory.mb</name>
<value>1024</value>
</property>
<property>
<name>tez.task.resource.cpu.vcores</name>
<value>1</value>
</property>
</configuration>
- 修改Hadoop环境变量,添加以下内容
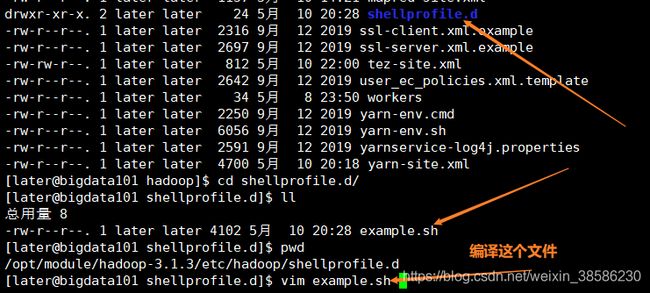
hadoop_add_profile tez
function _tez_hadoop_classpath
{
hadoop_add_classpath "$HADOOP_HOME/etc/hadoop" after
hadoop_add_classpath "/opt/module/tez/*" after
hadoop_add_classpath "/opt/module/tez/lib/*" after
}
效果如图
- 修改hive的计算引擎,vim $HIVE_HOME/conf/hive-site.xml
添加以下内容
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<property>
<name>hive.tez.container.size</name>
<value>1024</value>
</property>
- 在hive-env.sh中添加tez的路径

export TEZ_HOME=/opt/module/tez #是你的tez的解压目录
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
export HIVE_AUX_JARS_PATH=/opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.21-SNAPSHOT.jar$TEZ_JARS
注意你的jar包路径是不是和我的一样,需要编译lzo的看我另一篇博客安装编译lzo,附链接(https://blog.csdn.net/weixin_38586230/article/details/106035660)
- 解决日志Jar包冲突
rm /opt/module/tez/lib/slf4j-log4j12-1.7.10.jar
- 到此为止,hive的配置算是搞定了,我们先来跑一下官方给的测试案例,需要大家在本地先随便写个文件,然后上传到hdfs上,我这里写了个word.txt,上传到了hdfs上


## 把这个文件上传到hdfs
hadoop fs -put word.txt /tez/

## 开始测试wordcount,注意你的jar包路径
/opt/module/hadoop-3.1.3/bin/yarn jar /opt/module/tez/tez-examples-0.10.1-SNAPSHOT.jar orderedwordcount /tez/word.txt /tez/output/
跑完的结果如下

在yarn上也能看到这个任务
![]()
- 到这里就再开始测试hive中能不能使用tez引擎
1)启动Hive
[later@bigdata101 hive]$ hive
2)创建表
hive (default)> create table student(
id int,
name string);
3)向表中插入数据
hive (default)> insert into student values(1,"zhangsan");
4)如果没有报错就表示成功了
hive (default)> select * from student;
1 zhangsan
**
这里记得设置一下 set mapreduce.framework.name = yarn;
**
踩坑1

Application application_1589119407952_0003 failed 2 times due to AM Container for appattempt_1589119407952_0003_000002 exited with exitCode: -103
Failing this attempt.Diagnostics: [2020-05-10 22:06:09.140]Container [pid=57149,containerID=container_e14_1589119407952_0003_02_000001] is running 759679488B beyond the 'VIRTUAL' memory limit. Current usage: 140.9 MB of 1 GB physical memory used; 2.8 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_e14_1589119407952_0003_02_000001 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 57149 57147 57149 57149 (bash) 0 2 118079488 368 /bin/bash -c /opt/module/jdk1.8.0_211/bin/java -Djava.io.tmpdir=/opt/module/hadoop-3.1.3/tmp/nm-local-dir/usercache/later/appcache/application_1589119407952_0003/container_e14_1589119407952_0003_02_000001/tmp -server -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx1024m -Dlog4j.configuratorClass=org.apache.tez.common.TezLog4jConfigurator -Dlog4j.configuration=tez-container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1589119407952_0003/container_e14_1589119407952_0003_02_000001 -Dtez.root.logger=INFO,CLA -Dsun.nio.ch.bugLevel='' org.apache.tez.dag.app.DAGAppMaster --session 1>/opt/module/hadoop-3.1.3/logs/userlogs/application_1589119407952_0003/container_e14_1589119407952_0003_02_000001/stdout 2>/opt/module/hadoop-3.1.3/logs/userlogs/application_1589119407952_0003/container_e14_1589119407952_0003_02_000001/stderr
|- 57201 57149 57149 57149 (java) 871 158 2896457728 35706 /opt/module/jdk1.8.0_211/bin/java -Djava.io.tmpdir=/opt/module/hadoop-3.1.3/tmp/nm-local-dir/usercache/later/appcache/application_1589119407952_0003/container_e14_1589119407952_0003_02_000001/tmp -server -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx1024m -Dlog4j.configuratorClass=org.apache.tez.common.TezLog4jConfigurator -Dlog4j.configuration=tez-container-log4j.properties -Dyarn.app.container.log.dir=/opt/module/hadoop-3.1.3/logs/userlogs/application_1589119407952_0003/container_e14_1589119407952_0003_02_000001 -Dtez.root.logger=INFO,CLA -Dsun.nio.ch.bugLevel= org.apache.tez.dag.app.DAGAppMaster --session
[2020-05-10 22:06:09.222]Container killed on request. Exit code is 143
[2020-05-10 22:06:09.229]Container exited with a non-zero exit code 143.
For more detailed output, check the application tracking page: http://bigdata101:8088/cluster/app/application_1589119407952_0003 Then click on links to logs of each attempt.
. Failing the application.
这个错误还是比较 明细的,就是说tez检查内存不够了,这个解决办法两个,
-
关闭虚拟内存检查
(1)关掉虚拟内存检查,修改yarn-site.xml
yarn.nodemanager.vmem-check-enabled
false
(2)修改后一定要分发,并重新启动hadoop集群。 -
把内存调大(hive-site.xml)如下图

踩坑2
tez跑任务报错:
java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfiguration
at java.lang.Class.getDeclaredMethods0(Native Method)
at java.lang.Class.privateGetDeclaredMethods(Class.java:2570)
at java.lang.Class.getMethod0(Class.java:2813)
at java.lang.Class.getMethod(Class.java:1663)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.(ProgramDriver.java:59)
at org.apache.hadoop.util.ProgramDriver.addClass(ProgramDriver.java:103)
at org.apache.tez.examples.ExampleDriver.main(ExampleDriver.java:47)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.ClassNotFoundException: org.apache.tez.dag.api.TezConfiguration
看起来是告诉我配置什么的找不到,那不就是相当于意味着我的tez配置有问题啊,所以我把tez-site.xml放到了$HADOOP_HOME/etc/hadoop/下,以前是放在hive/conf/目录下不生效
踩坑3
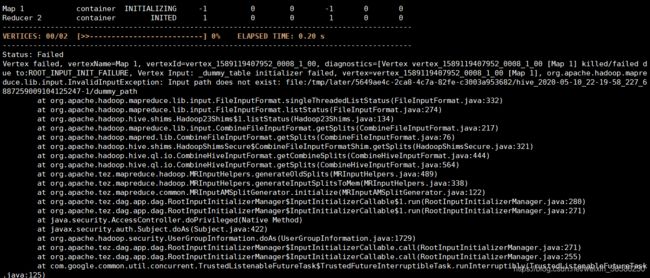
Status: Failed
Vertex failed, vertexName=Map 1, vertexId=vertex_1589119407952_0008_1_00, diagnostics=[Vertex vertex_1589119407952_0008_1_00 [Map 1] killed/failed due to:ROOT_INPUT_INIT_FAILURE, Vertex Input: _dummy_table initializer failed, vertex=vertex_1589119407952_0008_1_00 [Map 1], org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/tmp/later/5649ae4c-2ca8-4c7a-82fe-c3003a953682/hive_2020-05-10_22-19-58_227_6887259009104125247-1/dummy_path
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:332)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:274)
at org.apache.hadoop.hive.shims.Hadoop23Shims$1.listStatus(Hadoop23Shims.java:134)
at org.apache.hadoop.mapreduce.lib.input.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:217)
at org.apache.hadoop.mapred.lib.CombineFileInputFormat.getSplits(CombineFileInputFormat.java:76)
at org.apache.hadoop.hive.shims.HadoopShimsSecure$CombineFileInputFormatShim.getSplits(HadoopShimsSecure.java:321)
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getCombineSplits(CombineHiveInputFormat.java:444)
at org.apache.hadoop.hive.ql.io.CombineHiveInputFormat.getSplits(CombineHiveInputFormat.java:564)
at org.apache.tez.mapreduce.hadoop.MRInputHelpers.generateOldSplits(MRInputHelpers.java:489)
at org.apache.tez.mapreduce.hadoop.MRInputHelpers.generateInputSplitsToMem(MRInputHelpers.java:338)
at org.apache.tez.mapreduce.common.MRInputAMSplitGenerator.initialize(MRInputAMSplitGenerator.java:122)
at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable$1.run(RootInputInitializerManager.java:280)
at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable$1.run(RootInputInitializerManager.java:271)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)
at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable.call(RootInputInitializerManager.java:271)
at org.apache.tez.dag.app.dag.RootInputInitializerManager$InputInitializerCallable.call(RootInputInitializerManager.java:255)
at com.google.common.util.concurrent.TrustedListenableFutureTask$TrustedFutureInterruptibleTask.runInterruptibly(TrustedListenableFutureTask.java:125)
at com.google.common.util.concurrent.InterruptibleTask.run(InterruptibleTask.java:57)
at com.google.common.util.concurrent.TrustedListenableFutureTask.run(TrustedListenableFutureTask.java:78)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
]
在hive中执行插入语句时,报错,看起来时某某路径不存在,但实际上分析是由于“ mapreduce.framework.name = local”(Hadoop 3.2.1中的默认设置)引起的。通过“ set mapreduce.framework.name = yarn”解决。

踩坑4

Application application_1589119407952_0002 failed 2 times due to AM Container for appattempt_1589119407952_0002_000002 exited with exitCode: 1
Failing this attempt.Diagnostics: [2020-05-10 22:05:49.552]Exception from container-launch.
Container id: container_e14_1589119407952_0002_02_000001
Exit code: 1
[2020-05-10 22:05:49.652]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/tmp/nm-local-dir/filecache/10/tez-0.10.1-SNAPSHOT.tar.gz/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
[2020-05-10 22:05:49.652]Container exited with a non-zero exit code 1. Error file: prelaunch.err.
Last 4096 bytes of prelaunch.err :
Last 4096 bytes of stderr :
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/tmp/nm-local-dir/filecache/10/tez-0.10.1-SNAPSHOT.tar.gz/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
For more detailed output, check the application tracking page: http://bigdata101:8088/cluster/app/application_1589119407952_0002 Then click on links to logs of each attempt.
. Failing the application.
这个问题是这里面最头疼的问题了,看不出来任何bug,只知道tez session不能访问AM,遇到这个情况,我们在启动hive的时候我们就使用
hive --hiveconf hive.root.logger=DEBUG,console
来让它打印出所有的日志信息,方便找到问题在哪里,我遇到的这个在打印日志的时候一直打印 dest目标路径不存在,虽然是INFO日志,最后输出一会儿就卡住不动了,是这么个页面

那么这个时候你如果你不管它空不空白,直接再写sql查询的时候,它就会正常进入到hive的shell命令行,但就是执行插入语句,使用到tez的时候会报错,但这个报错会给你详细的日志,我的日志就是上面 踩坑3 中遇到的问题。
如果大家在编译过程中遇到一些问题,也可以直接联系我(l970306love),说不定你的这个问题我正好遇到过,可以节省很多没必要的时间,哈哈。
编译要有一颗平常心,按照一个帖子的方法装就好,不然最后装的乱七八糟的。加油。
下载我编译好的tez jar包,关注我的公众号“后来X”,回复tez