word2vec
2013年提出的word2vec的方法是一种非常方便得到高质量词向量的方式,其主要思想是:一个词的上下文可以很好的表达出词的语义,它是一种通过无监督的学习文本来用产生词向量的方式。word2vec中有两个非常经典的模型:skip-gram和cbow
- cbow:已知周围词,预测中心词。
-
skip-gram:已知中心词,预测周围词。
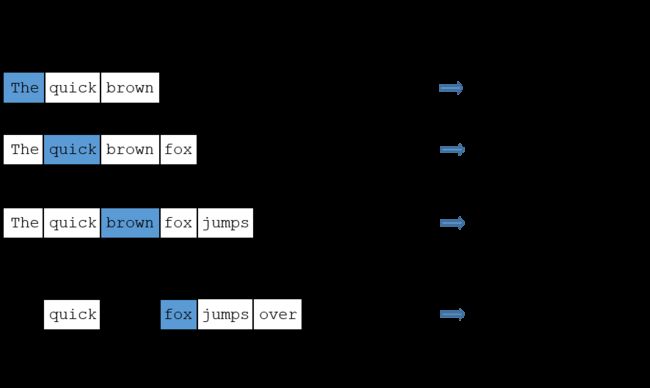 cbow VS. skip-gram with instance
cbow VS. skip-gram with instance
模型结构
skip-gram、cbow的模型架构都是单层的神经网络,神经网络的参数就是最后得到的词向量,神经网络训练过程就是学习词向量(网络参数)的过程。

Fasttext
gensim 中Fasttext 模型架构和Word2Vec的模型架构差几乎一样,只不过在模型词的输入部分使用了词的n-gram的特征。所谓n-gram特征,举个例子,如果原词是一个很长的词:你吃了吗。jieba分词结果为["你","吃了","吗"]。
- unigram(1-gram)的特征:["你","吃了","吗"]
- bigram(2-gram) 的特征: ["你吃了","吃了吗"]
n-gram的意思将词中连续的n个词连起来组成一个单独的词。 如果使用unigram和bigram的特征,词的特征就会变成:["你","吃了","吗","你吃了","吃了吗"]。使用n-gram的词向量使得Fast-text模型可以很好的解决未登录词(OOV, out-of-vocabulary)的问题。
gensim实战
语料包准备
这里我选用维基百科作为词向量模型的训练语料,如果还不知道怎么去处理维基百科数据,可以参考下面这篇文章,为了效率,我选择了个小的语料,当然对于词向量的训练,语料越大训练出来的结果越好:
https://dumps.wikimedia.org/zhwiki/


其中,我们选择zhwiki-xxxxxxxx-pages-articles-multistream.xml.bz2就好,这里只做测试。下载得到一个.bz2的包。通过以下步骤进行提取:
1.wikipedia extractor提取语料
https://github.com/attardi/wikiextractor
- 安装wikipedia extractor
pip install wikiextractor - 提取语料
python WikiExtractor.py -b 500M -o output_filename input_filename.bz2
这里需要说明:
- WikiExtractor.py里面存放Wikipedia Extractor代码;
- -b 1000M表示的是以1000M为单位进行切分,有时候可能语料太大,我们可能需要切分成几个小的文件(默认),这里由于我需要处理的包只有198M,所以存入一个文件就行了,所以只需要设置的大小比198M大即可;
- output_filename:需要将提取的文件存放的路径;
- input_filename.bz2:需要进行提取的.bz2文件的路径;
2.opencc将繁体字转换为简体字
https://github.com/BYVoid/OpenCC
- 安装opencc
pip install opencc - python脚本,这里直接用我的脚本即可,只需把两个路径修改为自己的路径即可:
import opencc
converter = opencc.OpenCC('t2s.json')
with open("./wiki_00") as f:
with open("./jt_wiki_00", "w") as f1:
for line in f:
print('*' * 100)
print(line)
c_line = converter.convert(line)
print(c_line)
f1.write(c_line)得到的中文语料以后,最重要的就是要进行分词的操作了,这里使用jieba分词工具对语料进行分词
导入python包
首先导入必要的python包,jieba,gensim等必要的包。
import jieba
import logging
import os.path
import sys
import multiprocessing
from gensim.models import Word2Vec, fasttext
from gensim.models.word2vec import LineSentencejieba分词
这里用的是某个比赛的一些评论文本数据,读入评论文本数据之后对每一条评论进行分词。代码如下:
with open(input_path) as f:
with open(output_path, "w") as f1:
for num, line in enumerate(f):
print('---- processing ', num, ' article----------------')
line_seg = " ".join(jieba.cut(line))
f1.write(line_seg)其中input_path、output_path分别为输入语料的路径与存储分词结果的路径。

Word2vec模型训练
Word2Vec这个API的一些重要参数。 + size: 表示词向量的维度,默认值是100。 + window:决定了目标词会与多远距离的上下文产生关系,默认值是5。 + sg: 如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model = word2vec.Word2Vec(sens_list,min_count=1,iter=20)
model.save("word2vec.model")这里采用默认参数。即采用CBOW模型——通过周围词预测中心词的方式训练词向量。数据有多少个词,便得到多少个词向量。
Fasttext模型训练
fasttext.FastText API一些重要参数: + size: 表示词向量的维度,默认值是100。 + window:决定了目标词会与多远距离的上下文产生关系,默认值是5。 + sg: 如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
上方参数和word2vec.Word2Vec API的参数一模一样。 + word_ngrams :({1,0}, optional) 1表示使用n-gram的信息,0代表不使用n-gram的信息,如果设置为0就等于CBOW或者Skip-gram。
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model1 = fasttext.FastText(sens_list,min_count=1,iter=20)
model1.save("fast_text.model")实战代码
# 1.os.path.basename('g://tf/code') ==>code
# 2.sys.argv[0]获取的是脚本文件的文件名称
program = os.path.basename(sys.argv[0])
# 指定name,返回一个名称为name的Logger实例
logger = logging.getLogger(program)
# 1.format: 指定输出的格式和内容,format可以输出很多有用信息,
# %(asctime)s: 打印日志的时间
# %(levelname)s: 打印日志级别名称
# %(message)s: 打印日志信息
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
# 打印这是一个通知日志
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 4:
print(globals()['__doc__'] % locals())
sys.exit(1)
# inp:分好词的文本
# outp1:训练好的模型
# outp2:得到的词向量
inp, outp1, outp2 = sys.argv[1:4]
'''
LineSentence(inp):格式简单:一句话=一行; 单词已经过预处理并被空格分隔。
size:是每个词的向量维度;
window:是词向量训练时的上下文扫描窗口大小,窗口为5就是考虑前5个词和后5个词;
min-count:设置最低频率,默认是5,如果一个词语在文档中出现的次数小于5,那么就会丢弃;
workers:是训练的进程数(需要更精准的解释,请指正),默认是当前运行机器的处理器核数。这些参数先记住就可以了。
sg ({0, 1}, optional) – 模型的训练算法: 1: skip-gram; 0: CBOW
alpha (float, optional) – 初始学习率
iter (int, optional) – 迭代次数,默认为5
'''
# word2vec模型
# model = Word2Vec(LineSentence(inp), size=400, window=5,
# min_count=5, workers=multiprocessing.cpu_count())
# fasttext模型
model = fasttext.FastText(LineSentence(inp), size=200, window=5,
min_count=5, workers=multiprocessing.cpu_count())
model.save(outp1)
# 不以C语言可以解析的形式存储词向量
model.wv.save_word2vec_format(outp2, binary=False)一些训练词向量的调参技巧:
- 选择的训练word2vec的语料要和要使用词向量的任务相似,并且越大越好,论文中实验说明语料比训练词向量的模型更加的重要,所以要尽量收集大的且与任务相关的语料来训练词向量;
语料小(小于一亿词,约 500MB 的文本文件)的时候用 Skip-gram 模型,语料大的时候用 CBOW 模型; - 设置迭代次数为三五十次,维度至少选 50,常见的词向量的维度为256、512以及处理非常大的词表的时候的1024维;
通过下面命令来执行Python文件:
python word2vec_model.py seg_filename model_name word2vec.vector
- word2vec_model.py:存放训练代码的Python文件;
- seg_filename:分好词的训练语料;
- model_name:训练好的模型的名称;
- word2vec.vector:得到的词向量;
测试代码-找出相似度最高的词
testwords = ['金融', '上', '股票', '跌', '经济', '人工智能']
for i in range(len(testwords)):
res = en_wiki_word2vec_model.most_similar(testwords[i])
print(testwords[i])
print(res)实验结果
