机器学习:图文详细总结马尔科夫链及其性质(附例题分析)
目录
- 0 写在前面
- 1 从一个实例出发
- 2 马尔科夫链
- 3 马氏链的基本性质
- 4 C-K方程
- 5 平稳状态分布
- 6 遍历性与例题分析
0 写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广”在分析多个机器学习模型:决策树、支持向量机、贝叶斯与马尔科夫决策、强化学习等。强基计划实现从理论到实践的全面覆盖,由本人亲自从底层编写、测试与文章配套的各个经典算法,不依赖于现有库,可以大大加深对算法的理解。
详情:机器学习强基计划(附几十种经典模型源码)
1 从一个实例出发
例1:如图所示随机过程,在时刻 i i i有 p 0 ( i ) p_{0}^{\left( i \right)} p0(i)概率转移到状态
0,有 p 1 ( i ) p_{1}^{\left( i \right)} p1(i)概率转移到状态1,问:时刻 N N N该随机过程所处状态的概率分布?
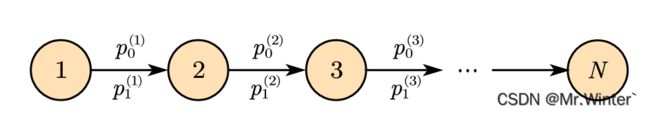
每个时刻该随机过程状态都产生转移,不妨用 N N N位状态码表示截至时刻 N N N时的一个可能路径,例如00…00表示从初始时刻到时刻 该随机过程始终处于状态0。
最朴素的想法是完整精确地计算时刻 N N N所处状态的概率分布,例如通过路径00…00使时刻 N N N转移到状态0的概率是 P = ∏ i p 0 ( i ) P=\prod\nolimits_i^{}{p_{0}^{\left( i \right)}} P=∏ip0(i)。然而,这种描述方式的空间复杂度是指数阶 O ( 2 N ) O\left( 2^N \right) O(2N)的,容易造成维数灾难,本质原因是每次计算都考虑过往状态的联合分布。
2 马尔科夫链
为避免维数灾难引入如下假设:
P ( X n + 1 = x n + 1 ∣ X 1 = x 1 , X 2 = x 2 , ⋯ , X n = x n ) = P ( X n + 1 = x n + 1 ∣ X n = x n ) P\left( X_{n+1}=x_{n+1}|X_1=x_1, X_2=x_2,\cdots , X_n=x_n \right) =P\left( X_{n+1}=x_{n+1}|X_n=x_n \right) P(Xn+1=xn+1∣X1=x1,X2=x2,⋯,Xn=xn)=P(Xn+1=xn+1∣Xn=xn)
其中 S = { s 1 , s 2 , ⋯ , s l } \mathcal{S}=\left\{ s_1,s_2,\cdots ,s_l \right\} S={s1,s2,⋯,sl}为状态空间, x i x_i xi为时刻 i i i的状态且 x i ∈ S x_i\in \mathcal{S} xi∈S。
该式称为马尔科夫链(Markov Chain),其特性是无后效性(马尔科夫性),即任意一个状态 包含了所有历史状态的信息,每个状态的推演只与上一个状态有关。根据无后效性,马尔科夫链将所有过往状态的联合分布简化为上一状态的边缘分布,因此避免了维数灾难,在工程技术上得到广泛应用。
马尔科夫链中一般由一组条件概率描述所有相邻状态相关关系,进而衍生整个过程,称为状态转移矩阵(State Transition Matrix) P t ( n ) \boldsymbol{P}_{t}^{\left( n \right)} Pt(n),其中每一项称为状态转移概率
p i j , t ( n ) = Δ P ( X t + n = s j ∣ X t = s i ) p_{ij,t}^{\left( n \right)}\xlongequal{\Delta}P\left( X_{t+n}=s_j|X_t=s_i \right) pij,t(n)ΔP(Xt+n=sj∣Xt=si)
表示处于 t t t时刻的状态 s i s_i si经 n n n步后转移为状态 s j s_j sj的概率,满足 p i j ⩾ 0 p_{ij}\geqslant 0 pij⩾0且 ∑ j p i j = 1 \sum\nolimits_j^{}{p_{ij}}=1 ∑jpij=1。特别地,当 n = 1 n=1 n=1时称为单步转移概率。连续概率分布可类似定义状态转移函数。
3 马氏链的基本性质
马氏链的基本性质如下:
-
非时变性/齐次性
若马氏链的状态转移矩阵不随时间 t t t发生变化,即满足对 ∀ t 1 , t 2 \forall t_1,t_2 ∀t1,t2有 p i j , t 1 ( n ) = p i j , t 2 ( n ) p_{ij,t_1}^{\left( n \right)}=p_{ij,t_2}^{\left( n \right)} pij,t1(n)=pij,t2(n),则称马氏链非时变或齐次,此时转移概率简记为 p i j ( n ) p_{ij}^{\left( n \right)} pij(n)。
-
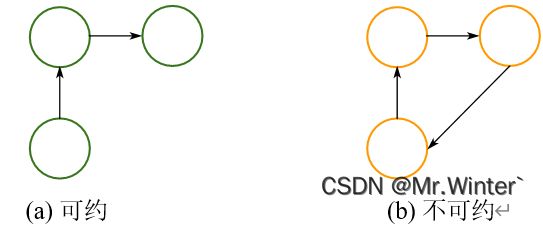
可约性
若马氏链可以从任意状态经过有限步到达其他任何状态,则称该马氏链不可约
-
周期性
从马氏链某个状态出发,所有可能返回路径的集合为 L L L,若 L L L中耗费时间步的最大公因数为 T T T,则称该状态具有周期 T T T。特别地,当 T = 1 T=1 T=1时称为非周期状态——若所有状态都是非周期,则整个马氏链非周期。对于不可约马氏链,若存在非周期状态,则该马氏链非周期。
4 C-K方程
切普曼-柯尔莫哥洛夫方程(Chapman-Kolmogorov)是马尔科夫链中很重要的性质体现,具体地,若马氏链齐次,则满足方程
P ( m + k ) = P ( m ) P ( k ) \boldsymbol{P}^{\left( m+k \right)}=\boldsymbol{P}^{\left( m \right)}\boldsymbol{P}^{\left( k \right)} P(m+k)=P(m)P(k)
简单证明如下
p i j ( m + n ) = P ( X m + n = s j ∣ X 0 = s i ) = ∑ k P ( X m + n = s j ∣ X m = s k , X 0 = s i ) P ( X m = s k ∣ X 0 = s i ) = ∑ k P ( X m + n = s j ∣ X m = s k ) P ( X m = s k ∣ X 0 = s i ) = ∑ k p i k ( m ) p k j ( n ) \begin{aligned}p_{ij}^{\left( m+n \right)} &=P\left( X_{m+n}=s_j|X_0=s_i \right)\\ &=\sum\nolimits_k^{}{P\left( X_{m+n}=s_j|X_m=s_k,X_0=s_i \right) P\left( X_m=s_k|X_0=s_i \right)}\\ &=\sum\nolimits_k^{}{P\left( X_{m+n}=s_j|X_m=s_k \right) P\left( X_m=s_k|X_0=s_i \right)}\\ &=\sum\nolimits_k^{}{p_{ik}^{\left( m \right)}p_{kj}^{\left( n \right)}}\end{aligned} pij(m+n)=P(Xm+n=sj∣X0=si)=∑kP(Xm+n=sj∣Xm=sk,X0=si)P(Xm=sk∣X0=si)=∑kP(Xm+n=sj∣Xm=sk)P(Xm=sk∣X0=si)=∑kpik(m)pkj(n)
定义向量 p t = [ P ( X t = s 1 ) P ( X t = s 2 ) ⋯ P ( X t = s l ) ] T \boldsymbol{p}_t=\left[ \begin{matrix} P\left( X_t=s_1 \right)& P\left( X_t=s_2 \right)& \cdots& P\left( X_t=s_l \right)\\\end{matrix} \right] ^T pt=[P(Xt=s1)P(Xt=s2)⋯P(Xt=sl)]T为马氏链在时刻 t t t的一维分布向量;定义 P ( X 1 = x 1 , X 2 = x 2 , ⋯ , X n = x n ) P\left( X_1=x_1,X_2=x_2,\cdots ,X_n=x_n \right) P(X1=x1,X2=x2,⋯,Xn=xn)为马氏链 n n n个时刻的 n n n维概率分布
C-K方程说明初始分布和状态转移矩阵可完全确定齐次马氏链统计学性质,具体体现为:
- 马氏链的动力学特性由一步状态转移矩阵唯一确定 P ( n ) = P n \boldsymbol{P}^{\left( n \right)}=\boldsymbol{P}^n P(n)=Pn;
- 马氏链一维分布向量的演变完全由初始分布和单步状态转移矩阵确定 p n T = p 0 T P ( n ) \boldsymbol{p}_{n}^{T}=\boldsymbol{p}_{0}^{T}\boldsymbol{P}^{\left( n \right)} pnT=p0TP(n);
- 马氏链 n n n维概率分布完全由初始分布和转移概率决定
P ( X n 1 = s i 1 , X n 2 = s i 2 , ⋯ , X n k = s i k ) = ( p 0 T P n 1 ) i 1 ( P n 2 − n 1 ) i 1 i 2 ⋯ ( P n k − n k − 1 ) i k − 1 i k P\left( X_{n_1}=s_{i_1},X_{n_2}=s_{i_2},\cdots ,X_{n_k}=s_{i_k} \right) =\left( \boldsymbol{p}_{0}^{T}\boldsymbol{P}^{n_1} \right) _{i_1}\left( \boldsymbol{P}^{n_2-n_1} \right) _{i_1i_2}\cdots \left( \boldsymbol{P}^{n_k-n_{k-1}} \right) _{i_{k-1}i_k} P(Xn1=si1,Xn2=si2,⋯,Xnk=sik)=(p0TPn1)i1(Pn2−n1)i1i2⋯(Pnk−nk−1)ik−1ik
5 平稳状态分布
对于非周期不可约齐次马氏链,存在不依赖于初始状态的极限概率
lim n → ∞ p i j ( n ) = π j ⇔ lim n → ∞ P ( n ) = [ π 1 π 2 ⋯ π j ⋯ π 1 π 2 ⋯ π j ⋯ ⋮ ⋮ ⋱ ⋮ ⋮ π 1 π 2 ⋯ π j ⋯ ⋮ ⋮ ⋮ ⋮ ⋮ ] = [ π T π T ⋮ π T ⋮ ] ⇔ lim n → ∞ p n T = π T \underset{n\rightarrow \infty}{\lim}p_{ij}^{\left( n \right)}=\pi _j\Leftrightarrow \underset{n\rightarrow \infty}{\lim}\boldsymbol{P}^{\left( n \right)}=\left[ \begin{matrix} \pi _1& \pi _2& \cdots& \pi _j& \cdots\\ \pi _1& \pi _2& \cdots& \pi _j& \cdots\\ \vdots& \vdots& \ddots& \vdots& \vdots\\ \pi _1& \pi _2& \cdots& \pi _j& \cdots\\ \vdots& \vdots& \vdots& \vdots& \vdots\\\end{matrix} \right] =\left[ \begin{array}{l} \boldsymbol{\pi }^T\\ \boldsymbol{\pi }^T\\ \vdots\\ \boldsymbol{\pi }^T\\ \vdots\\\end{array} \right] \Leftrightarrow \underset{n\rightarrow \infty}{\lim}\boldsymbol{p}_{n}^{T}=\boldsymbol{\pi }^T n→∞limpij(n)=πj⇔n→∞limP(n)=⎣⎢⎢⎢⎢⎢⎢⎡π1π1⋮π1⋮π2π2⋮π2⋮⋯⋯⋱⋯⋮πjπj⋮πj⋮⋯⋯⋮⋯⋮⎦⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎡πTπT⋮πT⋮⎦⎥⎥⎥⎥⎥⎥⎤⇔n→∞limpnT=πT
其中 π \boldsymbol{\pi } π为平稳状态分布(Stationary Distribution),根据收敛性,马尔科夫链进入平稳状态后就会维持稳定的状态演化模式。
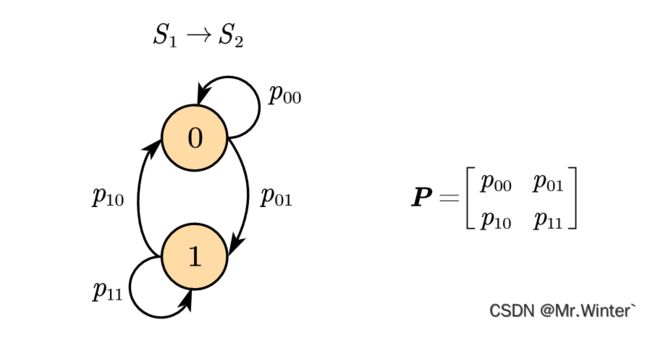
例1题解:具体地,假设 p 0 T = [ 0.60.4 ] \boldsymbol{p}_{0}^{T}=\left[ 0.6 0.4 \right] p0T=[0.60.4],即初始时刻60%为
0状态,40%为1状态,则
p 1 T = p 0 T P ( 1 ) = [ 0.6 p 00 + 0.4 p 10 0.6 p 01 + 0.4 p 11 ] \boldsymbol{p}_{1}^{T}=\boldsymbol{p}_{0}^{T}\boldsymbol{P}^{\left( 1 \right)}=\left[ \begin{matrix} 0.6p_{00}+0.4p_{10}& 0.6p_{01}+0.4p_{11}\\\end{matrix} \right] p1T=p0TP(1)=[0.6p00+0.4p100.6p01+0.4p11]
即得经过一次演进后,随机过程所处新状态的概率分布。经过若干次演进后,就得到了初始状态经过一个完整随机过程后的状态分布
6 遍历性与例题分析
马尔科夫链的遍历性是指:对齐次马氏链,若存在正整数 k k k使 ( P k ) i j > 0 \left( \boldsymbol{P}^k \right) _{ij}>0 (Pk)ij>0,则该马氏链具有遍历性,存在唯一极限分布 π \boldsymbol{\pi } π使方程 π T = π T P \boldsymbol{\pi }^T=\boldsymbol{\pi }^T\boldsymbol{P} πT=πTP成立。遍历性将马氏链平稳分布的迭代求解转为方程求解。
例2:如图所示,任意给定初态,讨论经若干次随机过程后的概率分布
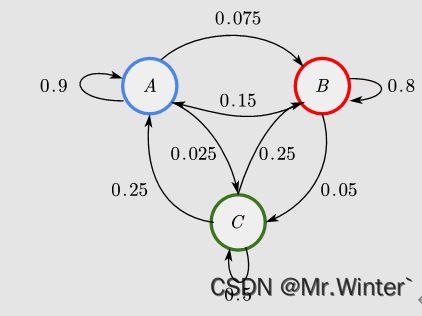
由于演进到任意状态的概率只取决于上一个状态,因此该模型属于马尔科夫链,列出状态转移矩阵如下
P = [ 0.900 0.075 0.025 0.150 0.800 0.050 0.250 0.250 0.500 ] \boldsymbol{P}=\left[ \begin{matrix} 0.900& 0.075& 0.025\\ 0.150& 0.800& 0.050\\ 0.250& 0.250& 0.500\\ \end{matrix} \right] P=⎣⎡0.9000.1500.2500.0750.8000.2500.0250.0500.500⎦⎤
现在给定初始状态 p 0 T = [ 0.3 0.4 0.4 ] \boldsymbol{p}_{0}^{T}=\left[ \begin{matrix} 0.3& 0.4& 0.4\\\end{matrix} \right] p0T=[0.30.40.4],则经过60次随机过程后得到稳定分布状态 π T = [ 0.625 0.3125 0.0625 ] \boldsymbol{\pi }^T=\left[ \begin{matrix} 0.625& 0.3125& 0.0625\\\end{matrix} \right] πT=[0.6250.31250.0625];再任给定初始状态 p 0 T = [ 0.7 0.1 0.2 ] \boldsymbol{p}_{0}^{T}=\left[ \begin{matrix} 0.7& 0.1& 0.2\\\end{matrix} \right] p0T=[0.70.10.2],经过57次随机过程后也得到相同的稳定分布状态。
若用遍历性定理求解,则考虑到存在正整数 n = 1 n=1 n=1使 P ( 1 ) i j > 0 {\boldsymbol{P}^{\left( 1 \right)}}_{ij}>0 P(1)ij>0,故该马氏链具有遍历性,令 π T = π T P \boldsymbol{\pi }^T=\boldsymbol{\pi }^T\boldsymbol{P} πT=πTP解得 π T = [ 0.625 0.3125 0.0625 ] \boldsymbol{\pi }^T=\left[ \begin{matrix} 0.625& 0.3125& 0.0625\\\end{matrix} \right] πT=[0.6250.31250.0625]。
更多精彩专栏:
- 《ROS从入门到精通》
- 《机器人原理与技术》
- 《机器学习强基计划》
- 《计算机视觉教程》
- …