语音识别 从入门到进阶 一 文末附项目/源码
嗨,大家我,欢迎来到AI+语音专栏,本专栏长期更新,每篇文章必备干货,文章附带大量的算法原理+代码实现教学,欢迎关注,一起AI。
语音识别原理
首先是语音识别和语音唤醒等任务。一听到你就会想起科大讯飞,中国百度等平台,由于
这两家企业在中国语音领域占用80+市场,所以他们做得很优秀,不过由于高精技术无法开源,其他企业只得花费大量的金钱去购买其API,而无法研究语音识别等应用,导致民间语音识别发展较慢,今天我们来一饱眼福吧!

信号处理,声学特征提取
我们都知道声音信号是连续的模拟信号,要让计算机处理首先要转换成离散的数字信号,进行采样处理。正常人听觉的频率范围大约在20Hz~20KHz之间,为了保证音频不失真影响识别,同时数据又不会太大,通常的采样率为16KHz。

语音采样
在数字化的过程中,我们首先要判断端头,确定语音的开始和结束,然后要进行降噪和过滤处理(除了人声之外,存在很多的噪音),保证让计算机识别的是过滤后的语音信息。获得了离散的数字信号之后,为了进一步的处理我们还需要对音频信号 分帧。因为离散的信号单独计算数据量太大了,按点去处理容易出现毛刺,同时从微观上来看一段时间内人的语音信号一般是比较平稳的,称为 短时平稳性,所以会需要将语音信号分帧,便于处理。
我们的每一个发音,称为一个 音素,是语音中的最小单位,
比如普通话发音中的元音,辅音。不同的发音变化是由于人口腔肌肉的变化导致的,
这种口腔肌肉运动相对于语音频率来说是非常缓慢的,所以我们为了保证信号的短时平稳性,
分帧的长度应当小于一个音素的长度,当然也不能太小否则分帧没有意义。
通常一帧为20~50毫秒,同时帧与帧之间有交叠冗余,避免一帧的信号在两个端头被削弱了影响识别精度。常见的比如 帧长为25毫秒,两帧之间交叠15毫秒,也就是说每隔25-15=10毫秒取一帧,帧移为10毫秒,分帧完成之后,信号处理部分算是完结了。
随后进行的就是整个过程中极为关键的特征提取。将原始波形进行识别并不能取得很好的识别效果,而需要进行频域变换后提取的特征参数用于识别。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。
实际应用中,这一步有很多细节,声学特征也不止有MFCC这一种,具体这里不讲,但是各种特征提取方法的核心目的都是统一的:尽量描述语音的根本特征,尽量对数据进行压缩。
比如下图示例中,每一帧f1,f2,f3…转换为了14维的特征向量,然后整个语音转换为了14*N(N为帧数)的向量矩阵。
一帧一帧的向量如果不太直观,还可以用下图的频谱图表示语音,每一列从左到右都是一个25毫秒的块,相比于原始声波,从这种数据中寻找规律要容易得多。
不过频谱图主要用作语音研究,语音识别还是需要用一帧一帧的特征向量。
识别字符,组成文本
特征提取完成之后,就进入了特征识别,字符生成环节。这部分的核心工作就是从 每一帧当中找出当前说的音素,再由多个音素组成单词,再由单词组成文本句子。 其中最难的当然是从每一帧中找出当前说的音素,因为我们每一帧是小于一个音素的,多个帧才能构成一个音素,如果最开始就错了则后续很难纠正。
怎么判断每一个帧属于哪个音素了?最容易实现的办法就是概率,看哪个音素的概率最大,则这个帧就属于哪个音素。那如果每一帧有多个音素的概率相同怎么办,毕竟这是可能的,每个人口音、语速、语气都不同,人也很难听清楚你说的到底是Hello还是Hallo。而我们语音识别的文本结果只有一个,不可能还让人参与选择进行纠正。
这时候多个音素组成单词的统计决策,单词组成文本的统计决策就发挥了作用,它们也是同样的基于概率:音素概率相同的情况下,再比较组成单词的概率,单词组成之后再比较句子的概率。
写——「Hello」、「Hullo」和「Aullo」,最终根据单词概率我们会发现Hello是最可能的,所以输出Hello的文本。上面的例子很明确的描述怎么从帧到音素,再从音素到单词,概率决定一切,那这些概率是怎么获得的了?难道为了识别一种语言我们把人类几千上百年说过的所有音素,单词,句子都统计出来,然后再计算概率?傻子都知道这是不可能的,那怎么办,这时我们就需要模型:
声学模型
发声的基本音素状态和概率,尽量获得不同人、不同年纪、性别、口音、语速的发声语料,同时尽量采集多种场景安静的,嘈杂的,远距离的发声语料生成声学模型。为了达到更好的效果,针对不同的语言,不同的方言会用不同的声学模型,在提高精度的同时降低计算量。
语言模型
单词和语句的概率,使用大量的文本训练出来。如果模型中只有两句话“今天星期一”和“明天星期二”,那我们就只能识别出这两句,而我们想要识别更多,只需要涵盖足够的语料就行,不过随之而来的就是模型增大,计算量增大。所以我们实际应用中的模型通常是限定应用域的,同比如智能家居的,导航的,智能音箱的,个人助理的,医疗的等等,降低计算量的同时还能提高精度,
词汇模型
针对语言模型的补充,语言词典和不同的发音标注。比如定期更新的地名,人名,歌曲名称,热词,某些领域的特殊词汇等等。
语言模型和声学模型可以说是语音识别中最重要的两个部分,语音识别中一个很重要的工作就是训练模型,有不识别的句子我们就加进去重新训练。
这时我们有很多简化但是有效的方法进行计算,比如说HMM隐马尔科夫模型Hidden Markov Model。
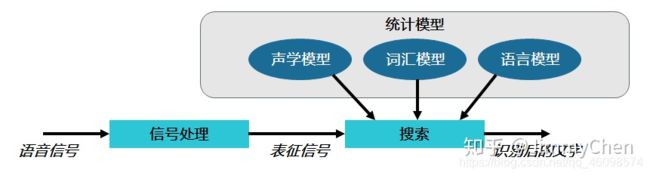
如此一来整个语音识别的流程就很清晰了,再来回顾以下整个步骤:
信号处理:模数转换,识别端头,降噪等等。信号表征:信号分帧,特征提取,向量化等等。
模式识别:寻找最优概率路径,声学模型识别音素,词汇模型和语言模型识别单词和句子。
中国顶级语音技术是怎么样的?
现在演示的是识别音频文件的内容。
token获取见官网,这边调包没什么含金量。
Python 技术篇-百度语音API鉴权认证获取Access Token
注:下面的 token 是我自己申请的,建议按照我的文章自己来申请专属的。
import requests
import os
import base64
import json
apiUrl='http://vop.baidu.com/server_api'
filename = "16k.pcm" # 这是我下载到本地的音频样例文件名
size = os.path.getsize(filename) # 获取本地语音文件尺寸
file1 = open(filename, "rb").read() # 读取本地语音文件
text = base64.b64encode(file1).decode("utf-8") # 对读取的文件进行base64编码
data = {
"format":"pcm", # 音频格式
"rate":16000, # 采样率,固定值16000
"dev_pid":1536, # 普通话
"channel":1, # 频道,固定值1
"token":"24.0c828682d414bf79b08f89c4c7dcd83a.2592000.1562739150.282335-16470175", # 重要,鉴权认证Access Token,需要自己来申请
"cuid":"DC-85-DE-F9-08-59", # 随便一个值就好了,官网推荐是个人电脑的MAC地址
"len":size, # 语音文件的尺寸
"speech":text, # base64编码的语音文件
}
try:
r = requests.post(apiUrl, data = json.dumps(data)).json()
print(r)
print(r.get("result")[0])
except Exception as e:
print(e)
第二的话,我们还可以体验一下百度的接口,下面,cv君给你们找了一个好东西,大家可以体验一下百度的水平。
网址,大家可以申请一下,然后进入里面有许多接口,申请一下,最后可以得到想要的程序,例如:
https://console.bce.baidu.com/ai/?_=1624804122867&fromai=1#/ai/speech/overview/index
分为在线识别: 通过调用百度在Web端部署好的语音模型及其服务 ,来返回结果。
离线命令词识别: 通过在百度上配置离线的服务,可以实现在这款APP上实现离线的语音识别,cv君后期也会发布离线语音的算法,毕竟离线的会更有优势和通用。
其中唤醒词:通过百度接口实现唤醒词的准备和训练,然后就可以通过官方的指引进行唤醒词的部署。
接下来,大家可以通过上方链接,找到教学以及成功部署一个自己的离线在线语音识别项目,比如我们在安卓中实现,安装好APP, 打开APP就能看到这主界面,每个环节都是不同的算法,大家可以添加或者删减任务项。

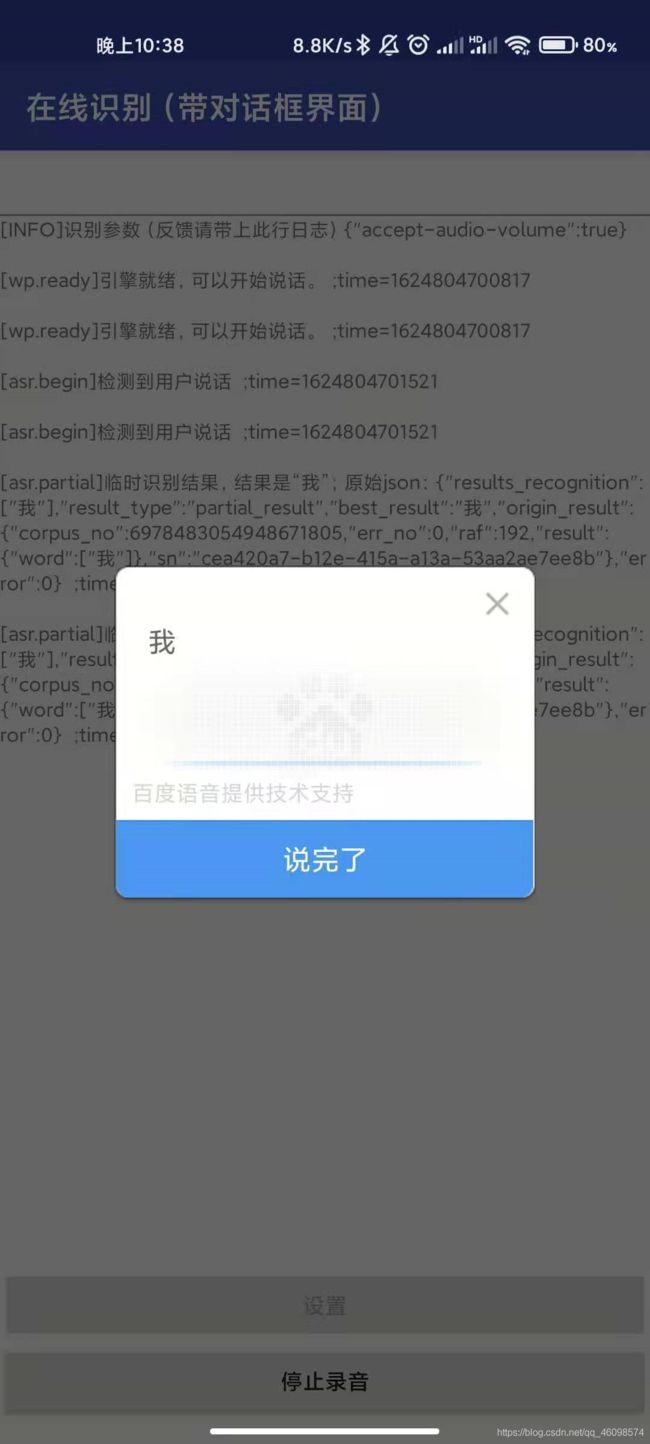
接下来,看看在线识别模块,在 在线识别项目中,我们的语音流 ,一般情况下会转换成base64等的web流,传输至服务器,服务器会解析,将base64等流解码转换成语音流,然后就可以通过服务器的识别算法(封装成了服务),对语音流识别,然后 就可以成功得到语音识别结果,并且能返回到APP中了。
大家可以看到下面我的演示中,语音识别,我讲述了一句话“我爱语音识别” 当我说到我爱的时候,他CTC解码后使用隐马尔可夫链等方式能够实现识别结果从TOP K 中找到TOP 1 的识别结果,他在前后语序的连贯性中发挥了强大的作用。
在离线命令词中,大家应当知道何谓 离线,就是说,完全脱机离线就能完成语音识别,也就是说,正常情况下,我们就能实现识别任务,并且就可以反馈给前后端~
不过,大家都知道,真正意义上的离线识别,就是需要全部模块,从初始到最后,都不需要网络的,但是,百度这款,首次使用是需要联网下载文件的,所以并不意味真正的离线,而且离线模式远差于在线的模式,因为他们的在线模式的模型部署在服务器中,能支持大型模型,而大型模型往往很大,不适合在APK中部署。
这边在线识别部分,他们提供了识别界面。
到了唤醒词部分,大家应该知道,在唤醒词中,我么应该知道,唤醒词的目的是,我们需要像小爱同学,siri那样的唤醒词,唤醒词通过大量逻辑和相关算法,实现:既能识别关键唤醒词,又能省电,不是时时刻刻都在执行项目和算法,需要极限省电,cv君后续会给大家带来唤醒词的识别和教学,欢迎关注~

链接:https://pan.baidu.com/s/12utb69Nkqb_G4I8T1r4-0Q
提取码:deep
我给大家分享上面的模型和apk,欢迎安卓和鸿蒙等设备安装使用~
总结
今天分享语音识别的基本知识和简单应用,欢迎大家学习关注~本专栏将长期更新,和大家一起,学习语音技术,实现入门进阶与升华。