二、代码实现深度学习道路训练样本数据的制作(代码部分详解)——重复工作+多次返工的血泪史
使用python读取文件夹对图片进行批量裁剪
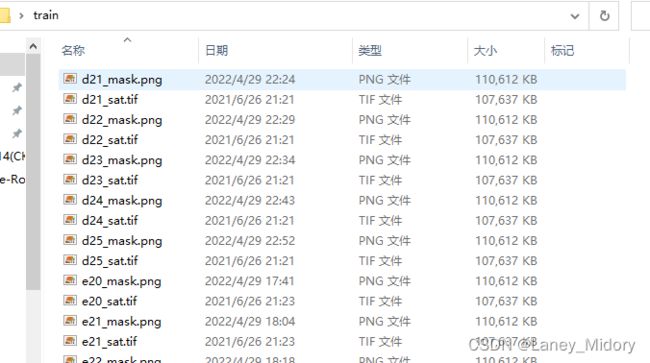
通过第一部分操作arcgis制作了一部分样本数据
分辨率与原相片保持一致
为6060*6060
具体如图所示:
而我们深度学习一般使用的分辨率是1024和512的
这两个数字都无法整除6060
因此我在这里选择裁剪成606
代码参考了这篇博文
感谢大佬!
我在这里进行了稍稍的调整
因为我想保留原图的格式
因此我的代码如下
# -*- coding: utf-8 -*-
import cv2import os
# Cutting the input image to h*w blocks
heightCutNum = 10;
widthCutNum = 10;
# The folder path of input and output
inPath = "C:/Users/Administrator/Desktop/train/"
outPath = "C:/Users/Administrator/Desktop/clip/"
for f in os.listdir(inPath):
path = inPath + f.strip()
print(path)
img = cv2.imread(path)
#print(outPath + str(1) + str(2) + f.strip())
# The size of each input image
height = img.shape[0]
width = img.shape[1]
# The size of block that you want to cut
heightBlock = int(height / heightCutNum)
widthBlock = int(width / widthCutNum)
for i in range(0,heightCutNum):
for j in range(0,widthCutNum):
cutImage = img[i*heightBlock:(i+1)*heightBlock, j*widthBlock:(j+1)*widthBlock]
savePath = outPath + str(i) + str(j) + f.strip()
cv2.imwrite(savePath,cutImage)
print("finish!")
这个代码是直接输入你想把图片分割的块数
这个办法比直接按照某一个大小来设置更好
以后想修改就可以直接改啦
非常方便
输出结果为:

图片也是各自对应的
但是这里有个问题
存在大量纯黑的图片
如何筛选掉纯黑的图片还需要解决
使用python删除掉为全黑的样本
那么就在得到图片之后判断通道的值即可
这里参考了这篇文章
这个方法需要不同的库
from PIL import Image
# 判断是否为全黑图
hands_mask = Image.open(hands_mask_path)
r, g, b = hands_mask.getextrema()
if r[1] == 0 and g[1] == 0 and b[1] == 0:
continue
还有一个检测方法是这个
# open the file with opencv
image = cv2.imread("image.jpg", 0)
if cv2.countNonZero(image) == 0:
print("Image is black")
else:
print("Colored image")
这两个方法都试试
这样确实可以知道这张图片是否是黑色的
但是问题是我也要把它对应的实景图删除该怎么办呢。。。
那么我先开始想的
边判断边保存就不太现实了
因为这样没办法删除对应的实景图
那么就先全部保存
在一张张删除
os.remove(filename1)
于是我对输出文件夹进行一些处理
for f in os.listdir(outPath):
path = outPath + f.strip()
img = cv2.imread(path,0)
if cv2.countNonZero(img) == 0:
print("Image is black")
print(path)
print(outPath + f.strip()[0:6] + "sat.tif")
os.remove(path)
os.remove(outPath + f.strip()[0:6] + "sat.tif")
print("finish!")
这样会出现一个问题
报错,找不到
Traceback (most recent call last):
File “c:/Users/Administrator/Desktop/DeepGlobe-Road-Extraction-link34-py3/clip.py”, line 45, in
os.remove(path)
FileNotFoundError: [WinError 2] 系统找不到指定的文件。: ‘C:/Users/Administrator/Desktop/t/00d21_sat.tif’
这是因为我先开始读取的是整个文件夹图片列表
但是我在这里把sat原图删除了,这样他在按顺序读取时无法读取到这张图片就会报错
因此需要对代码加入
python若图片不存在则跳过这一步骤
代码如下
for f in os.listdir(outPath):
path = outPath + f.strip()
if not os.path.exists(path):
continue;
img = cv2.imread(path,0)
if cv2.countNonZero(img) == 0:
print("Image is black")
print(path)
print(outPath + f.strip()[0:6] + "sat.tif")
os.remove(path)
os.remove(outPath + f.strip()[0:6] + "sat.tif")
但这样做其实不太保险
因为若是你的文件名不是标准形式该怎么办
为了使代码更完美
我这里读取文件名的前缀而不采用上面的方法
这里修改一下为这样:
for f in os.listdir(outPath):
path = outPath + f.strip()
if not os.path.exists(path):
continue;
img = cv2.imread(path,0)
if cv2.countNonZero(img) == 0:
print("Image is black")
print(path)
path2=f.strip().split("_")
print(outPath +path2[0] + "_sat.tif")
os.remove(path)
os.remove(outPath +path2[0] + "_sat.tif")
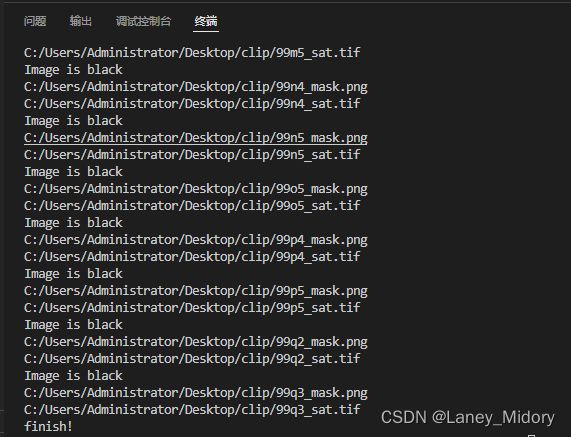
这样输出的都是我们需要删除的图片啦
把上面两个步骤合在一起总代码如下:
# -*- coding: utf-8 -*-
"""
Created on Wed May 4 16:50:20 2022
@author:Laney_Midorycsdn:Laney_Midory
"""
import cv2
import os
# Cutting the input image to h*w blocks
heightCutNum = 10;
widthCutNum = 10;
# The folder path of input and output
inPath = "C:/Users/Administrator/Desktop/train/"
#inPath = "C:/Users/Administrator/Desktop/test/"
outPath = "C:/Users/Administrator/Desktop/clip/"
#outPath = "C:/Users/Administrator/Desktop/t/"
for f in os.listdir(inPath):
path = inPath + f.strip()
print(path)
img = cv2.imread(path)
#print(outPath + str(1) + str(2) + f.strip())
# The size of each input image
height = img.shape[0]
width = img.shape[1]
# The size of block that you want to cut
heightBlock = int(height / heightCutNum)
widthBlock = int(width / widthCutNum)
for i in range(0,heightCutNum):
for j in range(0,widthCutNum):
cutImage = img[i*heightBlock:(i+1)*heightBlock, j*widthBlock:(j+1)*widthBlock]
savePath = outPath + str(i) + str(j) + f.strip()
cv2.imwrite(savePath,cutImage)
for f in os.listdir(outPath):
path = outPath + f.strip()
if not os.path.exists(path):
continue;
img = cv2.imread(path,0)
if cv2.countNonZero(img) == 0:
print("Image is black")
print(path)
path2=f.strip().split("_")
print(outPath +path2[0] + "_sat.tif")
os.remove(path)
os.remove(outPath +path2[0] + "_sat.tif")
print("finish!")
这样就可以输出有信息的样本啦!
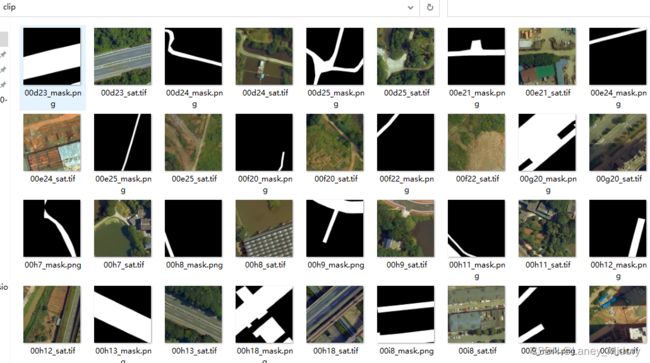
但是把这个样本放进我的道路检测代码中准备运行,出现了问题
ValueError: Using a target size (torch.Size([2, 1, 606, 606])) that is different to the input size (torch.Size([2, 1, 608, 608])) is deprecated. Please ensure they have the same size.
样本与道路提取代码产生的一些问题
torch.Size的问题
我输出了我样本的长宽大小
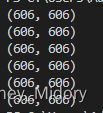
确实是(606,606)不知道为什么他说input size (torch.Size([2, 1, 608, 608]))是这个
这也太艰难了
真的不知道为啥大小有变化了。。。
我去搜索了一下
torch.size()这四个数字
(5, 2, 3, 4)分别表示(batch size, channel, height, width)
我猜测应该是原图跟标签分别是input和target
为了找到到底是原图还是标签出现了问题
我就将一张1024格式的图片替换了原图
报错变成了
ValueError: Using a target size (torch.Size([1, 1, 606, 606])) that is different to the input size (torch.Size([1, 1, 1024, 1024])) is deprecated. Please ensure they have the same size.
因此input是原图,target是标签
这样我总算找到了问题出现在哪儿了
是原图大小发生了什么变化
原图本来是tif格式的
但这个代码需要jpg格式的图片
我是直接将后缀改成了jpg
这种做法想来还是有些问题
虽然长宽还是606,但用torch.size()这样读取我的图片会改变他的长宽大小,多读取一些信息吧

以下是尝试失败的经历:大家可以看个乐呵
因此这里重新用靠谱的方法
把tif图片转为jpg图片
tif图片转为jpg图片
用了一些办法还是报错
比如这篇文章
图片做出来这样
颜色都变了
但还是608的大小。。。
这个方法感觉很复杂还需要安装一个新库
安装gdal库
可以查看这篇文章
解决ModuleNotFoundError: No module named ‘numpy.core._multiarray_umath‘ 错误
这个问题其实只需要更新一下nump即可
查看这篇文章
好吧
更新完了就又有其他地方报错。。。
ImportError: cannot import name ‘_validate_lengths’
查看这篇博文并没能解决我的问题
我是尝试了这个方法安装完后又报错
ValueError: TiffPage 0:
再次安装这个
这次就成功了
真是牵一发而动全身
以上纯属毫无意义的尝试,还是没法解决为什么经过train_loss = solver.optimize()之后img大小出现了问题
我在这一步上面print(img.shape)确实图片大小是torch.Size([1, 3, 606, 606])
但是经过optimize之后大小变了。。。
于是我尝试用可以训练的样本来试试改变他的大小看看对分辨率的要求
我之前用的是1024大小的样本
我使用上面的图片裁剪代码把图片分成四块
得到512*512大小的图片
扔进去是可以跑起来的
于是在这里我有个大胆的想法会不会是这个optimize的过程不适合于其它分辨率
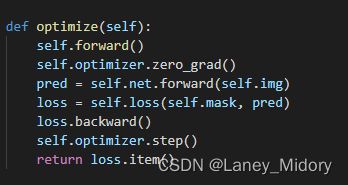
师姐告诉我这是由于这个过程进行了多次下采样
最好是2的次方数
因为我们不知道他进行了多少次下采样
所以对于分辨率为606的样本和原图来说
只能进行一次下采样303就失败了
经过尝试我们的猜测是正确的
这个模型能够使用1024以及512大小的图片来进行训练
因此下面我要固定图片分辨率来对图像进行裁剪
需要修改一下上面的代码
因为这次不是固定剪切块数
而是固定图像分辨率
批量处理将图片裁剪为固定分辨率的小图片
不知道为啥可能代码太长了
总是没法一下子粘贴到csdn上
这个编辑器确实有时候不太好用
我这里把我修改的部分放上来
大家对比我上面的代码改动一下就好了
把上面的注释掉
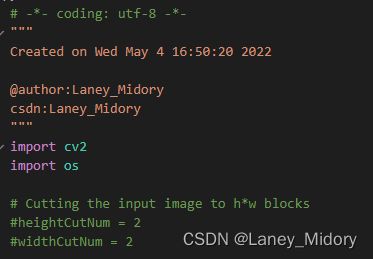
然后对下面的进行一点改动
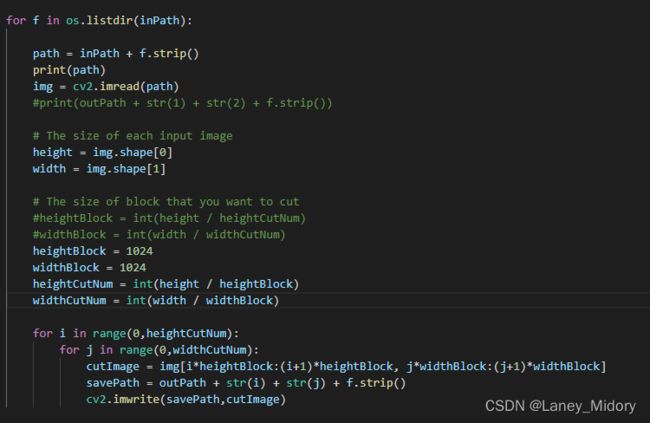
在这里固定分辨率大小

去除黑块部分代码不变
这样就可以成功啦
继续做了一些样本
用软件做的是保存的tif格式
这是由于只有保存为tif格式再转换成png可以保留样本的坐标
如果直接保存成png则无法保留坐标
那么这样就产生一个问题
如何从我的样本中找到mask结尾的图片并且把他们批量全部转为png格式呢
将样本中的特定后缀的tif图片批量转为png格式
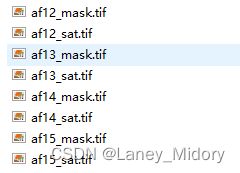
如图还是把mask后缀的tif图片转为png格式
分析了一下
直接改后缀其实就可以了
因此这里用到了shutil把我的样本转过去以防止覆盖出现问题
这个代码可以成功
# -*- coding: utf-8 -*-
"""
Created on Fri May 27 18:14:56 2022
@author:Laney_Midory
csdn:Laney_Midory
"""
import cv2
import numpy as np
from data import ImageFolder
import os
import shutil
imgdir = r"C:\Users\Administrator\Desktop\train" #tif文件所在的【文件夹】
savedir=r"C:\Users\Administrator\Desktop\png" #转为jpg后存储的【文件夹】
imagelist = filter(lambda x: x.find('mask')!=-1, os.listdir(imgdir))
for name in imagelist: # 获取图片文件全路径
img_path = os.path.join(imgdir, name) #获取文件名,不包含扩展名
filename = os.path.splitext(name)[0]
savefilename = filename+".png" #文件存储全路径
savepath = os.path.join(savedir, savefilename)
shutil.copy(imgdir+'\\'+name,savedir+'\\'+savefilename)
print("完成所有标签图片转换!")
结果图如下
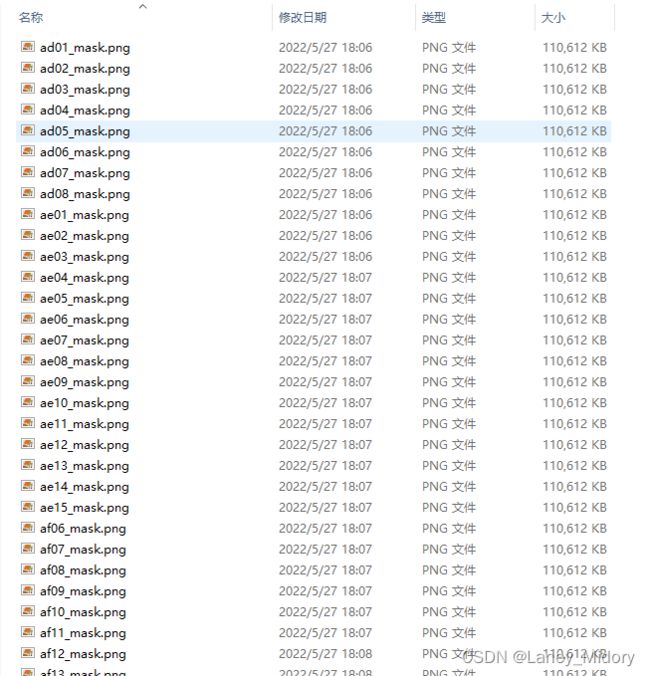
终于运行起来了
心累
慢慢训练吧
我现在是搞了72个样本
png格式的标签和tif格式的原图一共144张
所占内存巨大
确实训练会很慢
裁剪之后总共2402个数据
是1024分辨率的图片
不知道效果怎么样得等等看了
还是跟之前一样记录一下我可怜机器训练所用时间吧
现在是2022年5月6日15:05:00
看看什么时候能结束
在无聊的等待中我尝试了一下
用其他样本训练出来的模型,就是在之前博文中我训练的模型
这里可以直接跳转我之前的连续剧一样的博文
来predict我的新样本
发现结果并不是很好
大部分预测值都是黑的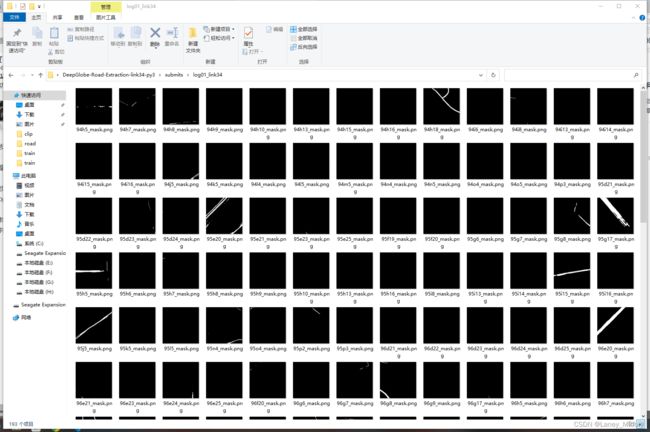
5月8日星期六去看了一下
我可怜的电脑还是承担不了这种折磨
强制关机了。。。
深度学习还是得买个服务器来跑
靠我这台式机电脑还是有点悬
但是实在没有办法
只能强制试试了
于是我把图片切分成了512分辨率来试试效果
这样切分一共有8332个样本
扔进去跑了周日一天
5月9日周一早上11:45:20训练已经结束
这里使用一些样本来作为test样本看看效果
