数据挖掘——关联规则(Association Rule)Apriori算法和python代码实现
关联规则(Association Rule)
-
- 什么是关联规则
- 一些基本概念
- 任务是什么
- Apriori 算法
-
-
- 核心思想
- 步骤与流程图
- 如何找到候选集
-
- python代码实现
什么是关联规则
关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术,用于从大量数据中挖掘出有价值的数据项之间的相关关系。
用一些例子来说明一下:
当我们在超市进行购物时,超市中有琳琅满目的商品,在每一次购物结束之后,我们会拥有一个购物车然后去结账,然后产生购物小票,购物小票中记录了我们购买的每件商品的信息,如此日积月累,所有的这些记录就会产生海量的用户购买行为。从这些购买行为中,我们特别希望能够发掘出类似买了面包的人就会去购买牛奶这样的规则。
这种规则,在数据挖掘中有很多,比如著名的啤酒和尿布的例子:在美国,一些年轻的父亲下班后经常要到超市去买婴儿尿布,而他们中有30%~40%的人同时也为自己买一些啤酒。产生这一现象的原因是:美国的太太们常叮嘱她们的丈夫下班后为小孩买尿布,而丈夫们在买尿布后又随手带回了他们喜欢的啤酒。

买了一样商品就会去买另外一件商品,这就是一种关联规则。
一些基本概念
Items(项)
实际上就是一些商品,面包,牛奶,巧克力,啤酒,尿布… 每一个都是一个 i t e m item item。
Transaction(交易)
一条交易记录(购物小票),是所有商品的非空子集。可以买一件商品,两件商品… 但是集合不能是空集。
Itemset(项集)
同时购买的一组东西。 i t e m s e t itemset itemset有大有小,购买的东西有可能有1个,2个, k k k个,如果有 k k k个,那么 itemset 就被称作 k − i t e m s e t k-itemset k−itemset。
Dataset(数据库)
包含一系列的 t r a n s a c t i o n transaction transaction
下面给出一个例子:
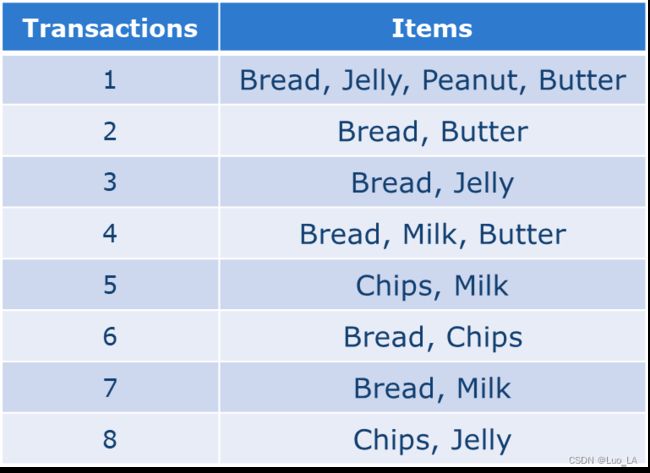
Bread是一个 i t e m item item,Butter也是一个 i t e m item item,而第1、2、4交易记录中,同时购买的Bread和Butter,就组成一个 2 − i t e m s e t 2-itemset 2−itemset。
Support(支持度)
可以理解成是一种频率,就是在一些 t r a n s a c t i o n transaction transaction 当中某一个 i t e m ( 或 者 i t e m s e t ) item( 或者 itemset) item(或者itemset)出现的频率。
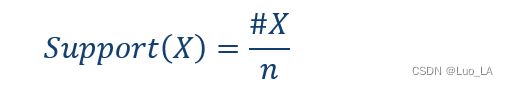
例如上表中的 Bread$ 的support就是6/8,Bread与Butter的 s u p p o r t support support是3/8,Bread、Butter和Chips的 s u p p o r t support support是0
关联规则 x − > y x -> y x−>y的支持度就是一些交易中同时包含 x x x和 y y y的频率。
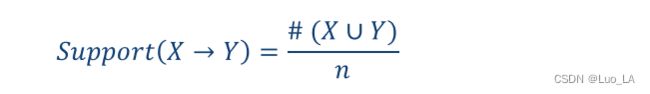
Confidence(置信度)
关联规则 x − > y x -> y x−>y的置信度就是一些交易中 同时包含 x x x和 y y y的数量与 x x x的数量的比。
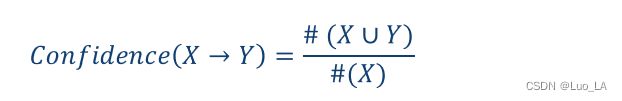
也可以被写作下面的公式:

置信度也可以被理解为是一种条件概率 P ( X ∣ Y ) P(X | Y) P(X∣Y),比如当我购买牛奶这个事件发生的时候,又购买面包这个事件发生的概率是多少。
引用上表的例子,如
Bread − > -> −> Milk 的 s u p p o r t support support = 2/8 , c o n f i d e n c e confidence confidence = 1/3
Milk − > -> −> Bread 的 s u p p o r t support support = 2/8 , c o n f i d e n c e confidence confidence = 2/3
我们需要的规则,它必须是一种强规则,而且要频繁。 s u p p o r t support support度量了一条规则的频繁程度, c o n f i d e n c e confidence confidence度量了一条规则的强度。我们定义两个阈值来量化这条规则的频繁程度和强度:
m i n i m u m minimum minimum s u p p o r t support support:σ
m i n i m u m minimum minimum c o n f i d e n c e confidence confidence:Φ
Frequent itemset(频繁集)
一个itemset,它的 s u p p o r t > σ support > σ support>σ
Strong rule(强规则)
一个规则 x − > y x->y x−>y,它既要是频繁的 ( s u p p o r t > σ support > σ support>σ),而且要 c o n f i d e n c e > Φ confidence > Φ confidence>Φ
任务是什么
当已知 I t e m s , d a t a s e t , σ , Φ Items,dataset,σ,Φ Items,dataset,σ,Φ,我们要做的就是从 d a t a s e t dataset dataset中挖掘出类似于 x − > y x->y x−>y的所有的 Strong rule。
要找出所有的强规则,方法就是:
- 找出所有的 f r e q u e n t frequent frequent i t e m s e t s itemsets itemsets
- 运用 f r e q u e n t frequent frequent i t e m s e t s itemsets itemsets ,对于每一个 f r e q u e n t frequent frequent i t e m item item,生成它的所有的非空子集,然后利用这些非空子集找出所有可能的关联规则,然后对这些规则进行校验 s u p p o r t support support 和 c o n f i d e n c e confidence confidence。
例如:根据集合 a , b , c {a,b,c} a,b,c,找出其所有可能的关联规则。
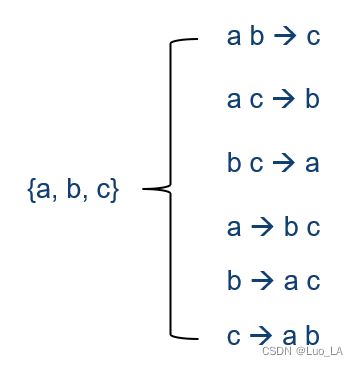
根据上面的2个步骤可以找出强规则。但是假如我们共有 d d d种商品,那么所有可能的 i t e m s e t s itemsets itemsets的个数就是 2 d − 1 2^d-1 2d−1,这是一个指数级的数字,想象一下,商品的数量如果有成百上千种,那么 i t e m s e t itemset itemset的数量是不可估计的。所以问题的关键就是,如何高效率的找出所有的 f r e q u e n t frequent frequent i t e m s e t s itemsets itemsets,下面介绍的就是解决这个核心问题的一个算法: Apriori 算法
Apriori 算法
核心思想
首先介绍两个核心思想:
- 一个频繁集的子集一定是频繁集,
{Milk, Bread, Coke} is frequent -> {Milk, Coke} is frequent - 一个 i t e m s e t itemset itemset不是频繁集,那么它的所有的超级一定不是频繁集,
{Battery} is infrequent -> {Milk, Battery} is infrequent
例如下图,我们知道B不是一个频繁集,那么所有标记为绿色的 i t e m s e t itemset itemset都不是频繁集。
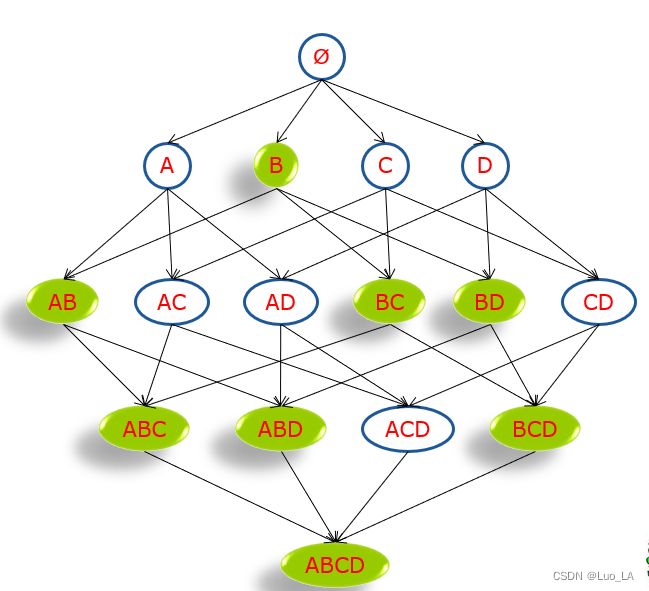
步骤与流程图
下面介绍Apriori的核心思路:
(1) 先生成某一个特定大小的 i t e m s e t s itemsets itemsets,一般从1开始,如{牛奶},{面包},{巧克力}
(2) 扫描数据库,观察这些 i t e m s e t s itemsets itemsets 哪些是频繁的,即频繁集,不频繁的 i t e m s e t itemset itemset直接舍弃
(3) 运用这些频繁集,组合成数量加1个大小的 i t e m s e t s itemsets itemsets(被称为 c a n d i d a t e candidate candidate i t e m s e t s itemsets itemsets 候选集),例如{牛奶,面包},{面包,巧克力},{牛奶,巧克力}。然后重复上面的第(2)步扫描数据库,舍弃不频繁的 i t e m s e t s itemsets itemsets,之后重复(2),(3)步。 i t e m s e t s itemsets itemsets的大小逐一增加。
(4) 综上,核心思想就是尽量避免去生成不频繁的 c a n d i d a t e candidate candidate i t e m s e t s itemsets itemsets
算法流程图:
定义:
C k C_k Ck:大小为 k k k的 c a n d i d a t e candidate candidate i t e m s e t s itemsets itemsets
L k L_k Lk:大小为 k k k的 f r e q u e n t frequent frequent i t e m s e t itemset itemset

首先找出所有的 f r e q u e n t frequent frequent i t e m s items items,长度是一。里面的小循环是扫描数据库中的每一条记录,根据已知的 c a n d i d a t e candidate candidate i t e m s e t itemset itemset,我们在每一条记录中查看一下是否存在这样一个 c a n d i d a t e candidate candidate i t e m s e t itemset itemset,如果存在,那么就 c o u n t + + count++ count++ 计数,也就是说在所有的记录中,有多少条记录包括这样一个特定的 i t e m s e t itemset itemset。里面的循环走完之后,我们就开始过滤操作,比较一下 s u p p o r t support support,如果> 我们之前设置的阈值 σ σ σ,那么就把这个 i t e m s e t itemset itemset留下,否则抛弃。然后外面的大循环,是把这些频繁集进行组合,组合成更大的 c a n d i d a t e candidate candidate i t e m s e t s itemsets itemsets,生成可能频繁的候选集,步数是1。
上面的算法中,最为关键的一步就是如何从 L k L_k Lk生成 C k + 1 C_{k+1} Ck+1
L k L_k Lk是一个集合,集合里面所有的 i t e m s e t itemset itemset 中的 i t e m item item 个数都是一样的,都是 k k k个,而且这些 i t e m s e t itemset itemset都是频繁的
C k + 1 C_{k+1} Ck+1也是一个集合,其中的 i t e m s e t itemset itemset 中的 i t e m item item 个数都是比 L k L_k Lk中的多一个
如何从 L k L_k Lk生成 C k + 1 C_{k+1} Ck+1,要做到必须把所有的频繁集都找到,同时又不能生成太多的冗余的
用下面这个例子进行讲述:
已知 L 1 L_1 L1:{1,2,3,4,5}, L 2 L_2 L2:{ {1,2},{2,3} },即1,2,3,4,5都是频繁的,{1,2},{2,3}也是频繁的。如何利用 L 1 L_1 L1, L 2 L_2 L2生成 C 3 C_3 C3?
如何找到候选集
方法一
把一个频繁的加入到两个频繁的,就生成了所有3个的可能频繁的 i t e m s e t itemset itemset
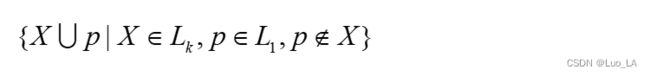
所以用这个方法得到的 C 3 C_3 C3就是{ {1,2,3},{1,2,4},{1,2,5},{2,3,4},{2,3,5} }
这个方法得到的 C 3 C_3 C3不能说是错误的,但是效率太低。例如我们看到 C 3 C_3 C3中的 {1,2,5},其中它的子集 {1,5}是不在 L 2 L_2 L2当中的,说明{1,5}是不频繁的,而 {1,2,5} 是它的超集,则说明 {1,2,5} 也是不频繁的。因此我们可以清楚的看到方法一生成的 C 3 C_3 C3会有大量的冗余。
方法二
从 L 2 L_2 L2 中找两个 i t e m s e t itemset itemset, x x x和 y y y,这两个 i t e m s e t itemset itemset要满足一个条件,他们中的 i t e m item item只有一个是不同的。然后把 x x x和 y y y拼起来。

用方法二,我们发现我们 L 2 L_2 L2中的两个 i t e m s e t itemset itemset,它们的2是相同的,1和3是不同的,就可以得到 C 3 C_3 C3就是{ {1,2,3} }。方法二的效率要比方法一的效率高很多。但是我们仔细观察会发现,这个{1,2,3}也是不频繁的,因为它的子集{1,3}不在 L 2 L_2 L2当中,所以{1,3}也是不频繁的。
方法三
首先对所有的 i t e m item item 做一个排序,然后从 L 2 L_2 L2 中找两个 i t e m s e t itemset itemset, x x x和 y y y,这两个 i t e m s e t itemset itemset要满足一个条件, x x x和 y y y的前 k − 1 k-1 k−1项都是相同的,第 k k k项是不同的,然后把 x x x和 y y y第 k k k项与前 k − 1 k-1 k−1项拼起来,组成 k + 1 k+1 k+1大小的 i t e m s e t itemset itemset。
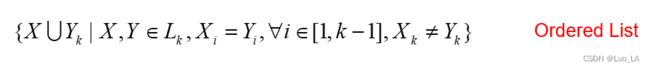
用方法三我们就可以发现,对于上述的 L 2 L_2 L2我们找不出满足方法三的两个itemset,因此得到 C 3 C_3 C3是 {}
如果 L 2 L_2 L2是{ {1,2},{1,3},{2,3} },生成的 C 3 C_3 C3就是 { {1,2,3} },因为我们可以找到两个满足方法三的 i t e m s e t itemset itemset {1,2} 和 {1,3} ,他们的第一位都是1,第2位不相同分别是2和3,由此可以得到 C 3 C_3 C3中的一个满足条件的 i t e m s e t itemset itemset {1,2,3}
但是如果 L 2 L_2 L2是{ {1,2},{1,3} },生成的 C 3 C_3 C3也是 { {1,2,3} },但是我们清楚地知道这个生成的{1,2,3}是不可能频繁的,因为它的子集{2,3}不在 L 2 L_2 L2当中。所以虽然方法三是效率最高的,但是我们在生成了 C 3 C_3 C3之后也要做进一步的验证,即验证它的子集是否都在 L 2 L_2 L2中。
下面是一个具体的例子:

python代码实现
下面使用python实现上面的Apriori算法,其中通过频繁集生成候选集采用的是方法三。
计算支持率
#计算支持率
def support(item,T):
n=len(T) # 事务集合的长度
l=len(item)
count=0
for x in T:
if len(set(x)&set(item)) == l: # 判断是否有交集,有交集,分子加1
count=count+1
return 1.0*count/n
生成候选集
def produce_Candinate(L, k):
candinate = [] # 首先创建一个空的集合
for x in range(len(L)): # 每两个元素集合进行比较
for y in range(x + 1, len(L)):
flag = True
x_item = L[x]
y_item = L[y]
for i in range(k):
if x_item[k - 1] == y_item[k - 1]: # 如果两个元素集合的最后一项相同 ,候选集为空
flag = False
break
elif x_item[i] != y_item[i] and i < k-1: # 如果前面 k-1 项有不相同的,候选集为空
flag = False
if flag:
temp = x_item.copy()
temp.append(y_item[k - 1]) # 将q中的最后一项添加到p中
temp.sort()
if has_frequent_subset(temp, L, k):
candinate.append(temp)
print("候选", k + 1, "-项集:", candinate)
return candinate
# 判断候选集子集是否是频繁集
def has_frequent_subset(c, freq_items, n):
num = len(c) * n #
count = 0
flag = False
for c_item in freq_items:
if set(c_item).issubset(set(c)): #判断上一层的频繁集中的每一项是否是计算出来的候选集的子集
count += n # 如果是就把count加上n
if count == num: # 如果最后相等(候选集的每个子集都在频繁集当中),就说明这个候选集中的每个子集都是频繁集
flag = True
return flag
Apriori算法挖掘频繁项集
#Apriori算法挖掘频繁项集
def Apriori(T,min):
k=1
#结果集,用于保存所有的频繁集
out=[]
#生成1-候选集
C=[]
for x in T:
C=list(set(x)|set(C))
#生成1频繁项集
F=[]
for i in C:
if support(list(i),T) >= min:
F.append([i])
#迭代
while (len(F)>0):
out.append(F)
#生成k+1候选集
C=produce_Candinate(F,k)
#生成k+1频繁项集
F=[]
for i in C:
if support(i,T) >=min:
F.append(i)
k=k+1
return out
主函数调用
T = [['A','B','C','D'], ['B','C','E'], ['A','B','C','E'], ['B','D','E'], ['A','B','C','D'] ]
out = Apriori(T,0.3)
print('频繁项集')
for i in out:
print(i)
打印结果

以上就是Apriori算法的全部内容,其中知识点部分参考了b站清华大学-数据挖掘 ,代码部分参考了多篇文章,并加入了一些的注释和自己的理解,有疑问欢迎评论区讨论!