深度学习与ArcGIS概述(1)
深度学习与ArcGIS概述
- 1、深度学习与ArcGIS基础概念介绍
- 2、ArcGIS使用的深度学习框架
- 3、ArcGIS深度学习处理流程和优势
课程整体概况:arcgis10.8深度学习介绍课程梳理
1、深度学习与ArcGIS基础概念介绍


三者的区别和联系:
机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术。
深度学习,作为目前最热的机器学习方法,但并不意味着是机器学习的终点。起码目前存在以下问题:
深度学习模型需要大量的训练数据,才能展现出神奇的效果,但现实生活中往往会遇到小样本问题,此时深度学习方法无法入手,传统的机器学习方法就可以处理;深度学习在计算机视觉、自然语言处理领域的应用远超过传统的机器学习方法,这就是深度学习火得发红发紫的原因。
有些领域,采用传统的简单的机器学习方法,可以很好地解决了,没必要非得用复杂的深度学习方法;
深度学习的思想,来源于人脑的启发,但绝不是人脑的模拟,举个例子,给一个三四岁的小孩看一辆自行车之后,再见到哪怕外观完全不同的自行车,小孩也十有八九能做出那是一辆自行车的判断,也就是说,人类的学习过程往往不需要大规模的训练数据,而现在的深度学习方法显然不是对人脑的模拟。
神经网络的发展分为了三个不同的阶段:
最早的神经网络的思想起源于1943年的MCP人工神经元模型,当时是希望能够用计算机来模拟人的神经元反应的过程,该模型将神经元简化为了三个过程:输入信号线性加权,求和,非线性激活(阈值法)
现代DL大牛Hinton在1986年发明了适用于多层感知器(MLP)的BP算法,并采用Sigmoid进行非线性映射,有效解决了非线性分类和学习的问题。
也是在1989年,LeCun发明了卷积神经网络-LeNet,并将其用于数字识别,且取得了较好的成绩,不过当时并没有引起足够的注意。
爆发期(2012~至今)2012年,Hinton课题组为了证明深度学习的潜力,首次参加ImageNet图像识别比赛,其通过构建的CNN网络Al。
AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。也正是由于该比赛,CNN吸引到了众多研究者的注意

图像分类:给定一张输入图像,图像分类任务旨在判断该图像所属类别
目前较为流行的图像分类架构是卷积神经网络(CNN)——将图像送入网络,然后网络对图像数据进行分类。卷积神经网络从输入“扫描仪”开始,该输入“扫描仪”也不会一次性解析所有的训练数据。比如输入一个大小为 100*100 的图像,你也不需要一个有 10,000 个节点的网络层。相反,你只需要创建一个大小为 10 10 的扫描输入层,扫描图像的前 1010 个像素。然后,扫描仪向右移动一个像素,再扫描下一个 10 *10 的像素,这就是滑动窗口。
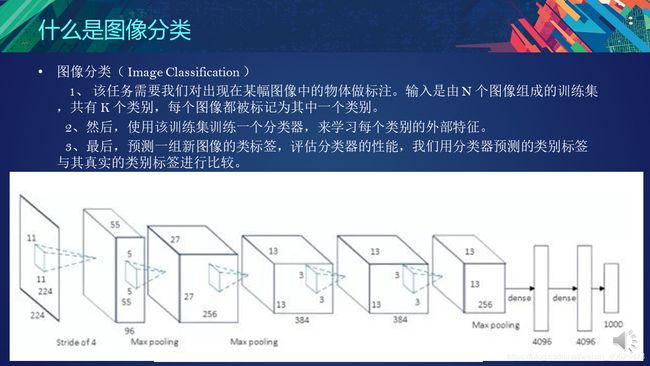
AlexNet的创新点: (1)首次采用ReLU激活函数,极大增大收敛速度且从根本上解决了梯度消失问题;(2)由于ReLU方法可以很好抑制梯度消失问题,AlexNet抛弃了“预训练+微调”的方法,完全采用有监督训练。也正因为如此,DL的主流学习方法也因此变为了纯粹的有监督学习;(3)扩展了LeNet5结构,添加Dropout层减小过拟合,LRN层增强泛化能力/减小过拟合;(4)首次采用GPU对计算进行加速;2013,2014,2015年,通过ImageNet图像识别比赛,DL的网络结构,训练方法,GPU硬件的不断进步,促使其在其他领域也在不断的征服战场
MNIST 将初学者领进了深度学习领域,而 ImageNet 数据集对深度学习的浪潮起了巨大的推动作用。深度学习领域大牛 Hinton 在2012年发表的论文《ImageNet Classification with Deep Convolutional Neural Networks》在计算机视觉领域带来了一场“革命”,此论文的工作正是基于 ImageNet 数据集。
ImageNet 数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,
目标定位:在图像分类的基础上,我们还想知道图像中的目标具体在图像的什么位置,通常是以包围盒的(bounding box)形式。
对象识别:在目标定位中,通常只有一个或固定数目的目标,而目标检测更一般化,其图像中出现的目标种类和数目都不定。因此,目标检测是比目标定位更具挑战性的任务。
(2) 基于候选区域的目标检测算法
使用不同大小的窗口在图像上滑动,在每个区域,对窗口内的区域进行目标定位。两步:第一步是从图像中提取深度特征,第二步是对每个候选区域进行定位(包括分类和回归)。其中,第一步是图像级别计算,一张图像只需要前馈该部分网络一次,而第二步是区域级别计算,每个候选区域都分别需要前馈该部分网络一次。
(3) 基于直接回归的目标检测算法
基于候选区域的方法由于有两步操作,虽然检测性能比较好,但速度上离实时仍有一些差距。基于直接回归的方法不需要候选区域,直接输出分类/回归结果。这类方法由于图像只需前馈网络一次,速度通常更快,可以达到实时。

目前的分割任务主要有两种: 语义分割和实例分割。那语义分割和实例分割具体都是什么含义呢?二者又有什么区别和联系呢?语义分割是对图像中的每个像素都划分出对应的类别,即实现像素级别的分类; 而类的具体对象,即为实例,那么实例分割不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例。

语义分割的任务描述:
搞清楚语义分割的输入输出都是什么。我们输入当然是一张原始的RGB图像或者单通道的灰度图,但是输出不再是简单的分类类别或者目标定位,而是带有各个像素类别标签的与输入同分辨率的分割图像。简单来说,我们的输入输出都是图像,而且是同样大小的图像。
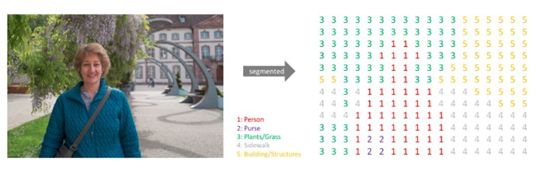
从输入到输出语义标签(from https://www.jeremyjordan.me/semantic-segmentation)
类似于处理分类标签数据,对预测分类目标采用像素上的 one-hot 编码,即为每个分类类别创建一个输出的 channel 。如下图所示:
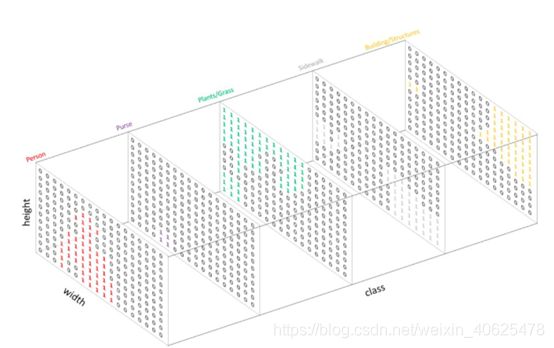
下图是将分割图添加到原始图像上的效果验证。这里有个概念需要明确一下——mask,在图像处理中我们将其译为掩膜,如 mask-rcnn 中的 mask。mask 可以理解为我们将预测结果叠加到单个 channel 时得到的该分类所在区域。

由于语义分割需要输入输出都是图像,所以与之前经典的图像分类和目标检测网络在分割任务上就不大适用了。在此前的经典网络中,经过多层卷积和池化之后输出的特征图尺寸会逐渐变小,所以对于语义分割任务我们需要将逐渐变小的特征图给还原到输入图像的大小。
网络结构与编码解码:为了实现上述目标,现有的语义分割等图像分割模型的一种通用做法就是采用编码和解码的网络结构,此前的多层卷积和池化的过程可以视作是图像编码的过程,也即不断的下采样的过程。那解码的过程就很好理解了,可以将解码理解为编码的逆运算,对编码的输出特征图进行不断的上采样逐渐得到一个与原始输入大小一致的全分辨率的分割图。

编码的过程就是卷积和池化的过程。
实例分割(Instance Segmentation)
相较于语义分割,实例分割不仅要做出像素级别的分类,还要在此基础上将同一类别不同个体分出来,即做到每个实例的分割。这对分割算法提出了更高的要求。好在我们此前积累足够的目标检测算法基础。实例分割的基本思路就是在语义分割的基础上加上目标检测,先用目标检测算法将图像中的实例进行定位,再用语义分割方法对不同定位框中的目标物体进行标记,从而达到实例分割的目的。

以 mask R-CNN 为例
Mask R-CNN 将 Fast R-CNN 的 ROI Pooling 层升级成了 ROI Align 层,并且在边界框识别的基础上添加了分支FCN层,即mask层,用于语义 Mask 识别,通过 RPN 网络生成目标候选框,然后对每个目标候选框分类判断和边框回归,同时利用全卷积网络对每个目标候选框预测分割。Mask R-CNN 本质上一个实例分割算法(Instance Segmentation),相较于语义分割(Semantic Segmentation),实例分割对同类物体有着更为精细的分割。
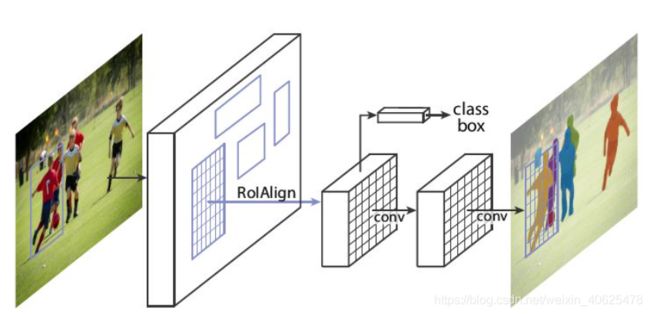
mask R-CNN 开源实现参考:https://github.com/matterport/Mask_RCNN


TensorFlow:2015年11月谷歌(Google)出品,基于Python和C++编写。GitHub上最热,谷歌搜索最多,使用人数最多;如果你最终想找一份深度学习的工作,最好学习下TensorFlow
Keras:2015年3月首次发布,拥有“为人类而不是机器设计的API”,得到Google的支持。它是一个用于快速构建深度学习原型的高层神经网络库,由纯Python编写而成,以TensorFlow,CNTK,Theano和MXNet为底层引擎,提供简单易用的API接口,能够极大地减少一般应用下用户的工作量。如果你是深度学习的初学者,想要快速入门,建议从Keras开始。
PyTorch:PyTorch于2016年10月发布,是一款专注于直接处理数组表达式的低级API。 前身是 Torch(一个基于 Lua 语言的深度学习库)。Facebook 人工智能研究院对PyTorch提供了强力支持。 PyTorch 支持动态计算图,为更具数学倾向的用户提供了更低层次的方法和更多的灵活性,目前许多新发表的论文都采用PyTorch作为论文实现的工具,成为学术研究的首选解决方案。如果你是一名科研工作者,倾向于理解你的模型真正在做什么,那么就考虑选择PyTorch。
Caffe/Caffe2.0:
Caffe的全称是Convolutional Architecture for Fast Feature Embedding,它是一个清晰、高效的深度学习框架,于2013年底由加州大学伯克利分校开发,核心语言是C++。它支持命令行、Python和MATLAB接口。Caffe的一个重要特色是可以在不编写代码的情况下训练和部署模型。
如果您是C++熟练使用者,并对CUDA计算游刃有余,你可以考虑选择Caffe
2、ArcGIS使用的深度学习框架
数十年来,机器学习工具一直是 GIS 空间分析的核心组件。您已经能够在 ArcGIS 中使用机器学习来执行图像分类、通过聚类来丰富数据或对空间关系进行建模。机器学习是人工智能的一个分支,将在机器学习中使用算法来处理结构化数据以解决问题。传统结构化数据需要用户标记数据,例如猫和狗的图片,以便能够在算法中理解每种动物类型的特定要素,然后在其他图片中识别这些动物。
深度学习是机器学习的子集,它以神经网络的形式使用多层算法。通过不同的网络层来分析输入数据,每一层都定义数据中的特定要素和模式。例如,如果您希望识别诸如建筑物和道路等要素,则将使用不同建筑物和道路的图像来训练深度学习模型,通过神经网络内的层来处理图像,然后找到对建筑物或道路进行分类所需的标识符。
Esri 开发了工具和工作流,以利用深度学习中的最新创新来回答 GIS 和遥感应用程序中的一些难题。计算机视觉或者计算机从数字图像或视频中获取理解的能力这一领域已经从传统机器学习算法转变为深度学习方法。在 ArcGIS Pro 中将深度学习应用于影像之前,了解深度学习在计算机视觉中的不同应用非常重要。

3、ArcGIS深度学习处理流程和优势
ArcGIS Pro 允许使用统计或机器学习分类方法对遥感影像进行分类。深度学习是一种机器学习,依赖于多图层的非线性处理以便进行模型中描述的要素识别和图案识别。深度学习模型可以与 ArcGIS Pro 集成,用于对象检测、对象分类和影像分类。
使用分类和深度学习工具在 ArcGIS Pro 中生成感兴趣要素或对象的训练样本。这些训练样本用于通过地理处理工具来训练深度学习模型,生成的模型定义文件或深度学习模型包 (DLPK) 用于运行推断地理处理工具以提取特定对象位置、对对象进行分类或标注,或对影像中的像素进行分类。也可以在 ArcGIS Pro 外部使用外部第三方框架训练模型,然后使用模型定义文件运行推断地理处理工具。模型定义文件和 DLPK 可以多次用作地理处理工具的输入,从而可以在训练模型后可轻松评估不同位置和时间段的多个影像。

深度学习步骤 1
使用标注对象以供深度学习窗格创建训练样本,然后使用导出训练数据进行深度学习工具将样本转换为深度学习训练数据。
深度学习步骤 2
使用 训练深度学习模型工具通过 PyTorch 训练模型,或在 ArcGIS Pro 外部使用支持的第三方 深度学习框架训练模型。
深度学习步骤 3
使用训练模型运行使用深度学习检测对象工具、使用深度学习分类像素工具或使用深度学习分类对象以生成输出。
处理流程梳理

ArcGIS 深度学习提供了一个完整的空间数据科学平台、强大的空间分析处理能力,包含了大量的工具箱,涉及到地理空间分析的方方面面,用新的方式来处理新的GIS问题。面向数据科学家、数据分析师等角色主要用来满足基于空间数据进行数据处理、建模、挖掘与分析、ArcGIS平台管理和运维等方面的工作。同时ArcGIS提供集成化的环境,结合ArcGIS平台海量的地理数据资源,让用户随心所欲进行数据建模、数据分析、数据挖掘等工作流,其强大的集成化环境,为数据科学领域用户提供强有力的技术支撑。
