港中文&Adobe提出:开放式实体分割 Open-World Entity Segmentation
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文作者:diddo | 来源:知乎(已授权)
https://zhuanlan.zhihu.com/p/394621314
大家好,介绍一个我们的新工作 "Open-World Entity Segmentation". 这篇工作是我们在图像分割领域一个思考,和MaskFormer属于同期工作、思想有些类似但是出发角度不太相同。
 主页:http://luqi.info/Entity_Web/ 论文:https://arxiv.org/abs/2107.14228 代码(刚刚开源): https://github.com/dvlab-research/Entity
主页:http://luqi.info/Entity_Web/ 论文:https://arxiv.org/abs/2107.14228 代码(刚刚开源): https://github.com/dvlab-research/Entity
在这个工作中,我们的出发点是想解决语义/实例/全景分割在某些落地场景中实际存在的一些问题。例如大家经常使用Adobe的Photoshop来进行图像编辑,在此过程中往往需要软件对图像进行分"块"而无需对这些"块"进行分类识别。而这种"块"的定义是我们人类对类别和实例区分的一个主观反应。在实际产品部署中,我们一般使用分割模型进行分"块"处理。然而现有的语义/实例/全景分割模型往往都要考虑类别信息,这导致在此类图像编辑场景中出现了一些不可避免的问题,如下图所示:
(1) 类别的歧义性导致模型对同一个"块"有两种解读,例如水和河,沙地和贫瘠的土地。
(2)网络无法预测出训练阶段为标注的类别,缺少一定的泛化能力,例如卷发梳、笔和电话。这两种现象均是在实际业务中真实存在的。为什么我们会确定这种现象真实存在。。。因为这篇工作就是和Adobe的研究团队一起合作完成的。

对于上面所描述的两种现象,我们认为这些现象与训练中考虑类别有很大的关系。假如我们在训练阶段不考虑这些类别,是否能消除这两种现象?与此同时,不考虑类别信息可以让我们的网络更多地关注每一个"块"的分割效果,这也更符合Photoshop这类软件的实际使用情况。基于这个思考,我们提出了实体(Entity)分割任务,实体也就是我们刚刚所描述的”块“。与全景分割相比,每一个实体是一个不考虑类别信息的thing或者stuff。这样的话,我们很容易直接使用已标注的panoptic数据进行探索。由于实体是一个很主观的概念,我们做了大量的用户调研来判断我们对实体"块"的定义是合理的。具体的用户调研结果,请查看我们的附录文件。

接下来的任务需要我们确定具体指标去衡量我们的分割结果。在这里我们考虑了两点需求:一是对每一个实体的确信程度,这样能够保证优先考虑最确信的mask,二是每一个实体不存在覆盖的关系。借鉴成熟的目标检测和实例分割的衡量指标 AP, 我们提出了预测实体mask之间没有相互覆盖的 APe 衡量指标。只需要简单修改cocoapi的几行代码,就可以顺利将 AP转换成APe。其思路是将cocoapi的分类信息全部置为1,并且在预测的时候保证mask之间没有overlap。同时 AP也能够衡量预测实体的确信程度,因为 AP与我们预测的mask得分排序息息相关。
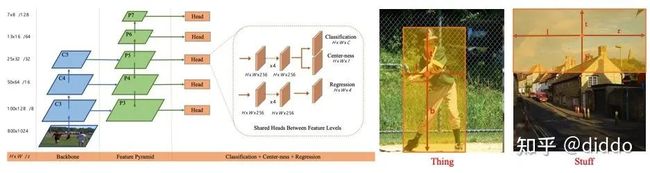
最后是我们具体方法的设计。没有类别信息,我们无法知道什么是thing什么是stuff?所以在这里更需要我们对实体(Entity)建立统一表达。对于统一表达,我们的设计初衷是简单有效不复杂。在全景分割任务中有很多文章对这方面进行了探索,然而很多文章使用了强悍的transformer结构。相比transformer结构,CNN的结构会更加容易收敛加速训练时间。因此,最终决定用CNN结构建立统一表达。PanopticFCN是一个典型的全景分割CNN结构,至少在我们投稿阶段,PanopticFCN是全景分割的SOTA。然而PanopticFCN也没有完全做到stuff和thing的的统一表达,例如在kernel处理的方式以及最后贴图的顺序上。因此,没有合适的模型更激发了我们用CNN结构进行统一表达的兴趣。在整个探索过程中,我们特别惊奇地发现中心点能够很好地表达不考虑类别的thing和stuff。如下是我们利用FCOS检测器进行entity detection的实验记录。
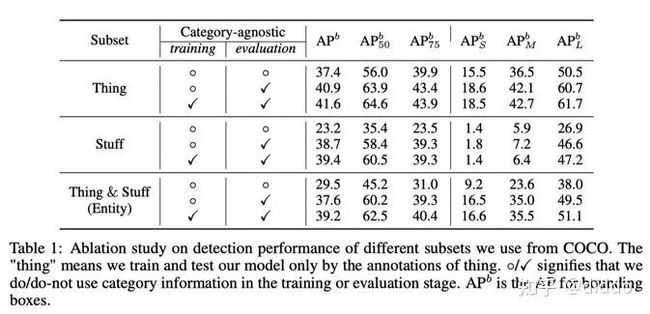
这个实验表格清晰地表明了,不需要修改一阶段的目标检测器就可以很好的定位出不考虑类别的stuff或者entity。在FCOS上良好的实体(Entity)检测效果,直接导致我们使用Condinst作为baseline进行实体分割。在FCOS的基础上,Condinst在正样本点的对应位置产生动态卷积核卷积低层feature map上做entity segmentation。良好的实体检测效果保证了Condinst良好的实体分割效果。
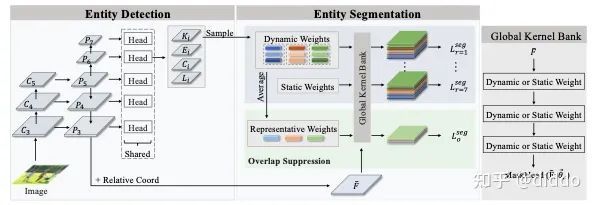
在Condinst的基础上,我们提出了两个模块来更加适应实体分割这项具体任务。Global kernel bank利用静态卷积让我们的网络能够捕捉到所有实体(Entity)的共性,而overlap suppression利用softmax的强约束关系保证两个mask之间不具有overlap。最重要的是,我们提出的这两个模块仅仅作用在训练阶段,而不会改变Condinst原有的推理过程,因此也不会在推理阶段增加计算量。这两个模块的具体设计及其简单,具体可参照我们的论文。
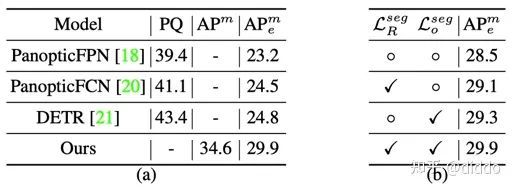
在具体的量化指标上,我们首先对训练及推理在同一数据源下进行了评测。左图为我们的方法和投稿前其他优秀的panoptic segmentation框架的对比(不考虑panoptic结果的具体分类即可)。而右图是我们的方法和baseline Condinst的对比,两个模块具有1.5个点的提高。
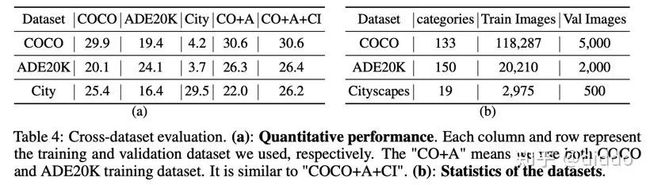
考虑到泛化能力,我们对跨数据集也进行了评测。左图每一列和行分别代表所使用的训练数据和测试数据。可以看到,我们这种方法不仅在跨数据集上的评测指标不错,也可以合并所有的数据集进行统一的训练最终在三个数据集下都有不错的效果。
当然从量化指标上无法看到这个实体分割任务在泛化性能的优势,因此我们将在COCO上训练的模型进行了跨数据集的可视化。下图所示为我们在ImageNet的可视化结果,可以看到我们的模型能够很好的分割出在COCO上未标注的类别,例如蜥蜴,猴子或者火柴等等。对于更多的跨数据集可视化效果(ADE20K, Cityscapes, Object365以及Places2),请参考我们的附录文件。

目前,我们的paper已经放在了Arxiv上,感兴趣的小伙伴可以下载一下。由于考虑不周,我们的v1版本将正文和附录(大量跨数据集的可视化结果)合并在了一起,导致文件大小有45M,请小伙伴耐心下载一下。我们也会尽快分离出正文和附录提供一个v2的版本。这个工作的代码已全部开源,欢迎试用。在代码库中,我们提供了很多训练好的模型链接方便大家直接可视化使用,这些模型所使用的backbone包含了ResNet,Swin-Trasformer以及Segformer中的backbone MiT系列。
https://github.com/dvlab-research/Entity
些许思考:(1) 从模型角度出发,实体分割的建模方式与目前的目标检测和实例分割接近,因此在模型的设计上理论上检测涨点的结构、NMS-free的结构同样适用于实体分割任务。(2)从任务出发,实体分割具有很强的泛化能力进行无类别的全图分割,这或许有很强的潜力去做有类别的识别任务,例如全景分割,few shot或者长尾分布的分割。Mask都已分好,识别是不是也会变得容易很多?目前我们也在基于这个结构对全景分割进行尝试,PQ指标也几乎和PanopticFCN持平。因此实体分割也可以做为pretrain的模型承担一些任务的上游任务。
这些思考也仅仅代表自己的想法,可能也是错误的,请大家多多指教。
上面论文和代码下载
后台回复:Entity,即可下载上述论文和代码
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-图像分割交流群成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看