天天生鲜(Django4.0版本) + 开发遇到的问题及解决
目录
1、项目来源及开发介绍
1.1、天天生鲜介绍
1.2、Web开发流程介绍
1.2.1、需求分析
1.2.2、项目架构概览
1.2.3、SKU与SPU概念
2、项目架构
3、数据库表结构
4、用户认证模型
5、类视图
6、用户模块开发
6.1、Django4.0认证系统文档
6.2、用户注册
6.2.1、django发送邮件
6.2.2、Celery异步任务队列
6.3、用户激活
6.3.1、加密用户身份信息
6.3.2、解密用户身份信息验证
6.4、用户登录
6.4.1、配置redis作为Django缓存和session后端
6.4.2、登录判断装饰器login_required
6.5、用户退出
6.6、用户地址
6.7、用户个人信息
6.7.1 redis存储历史浏览记录分析
6.7.2、django-redis获取redis链接
7、商品模块开发
7.1、了解FastDFS分布式文件系统
7.2、python对接fastdfs
7.3、项目上传图片和使用图片流程
7.4、Django二次开发对接FastDFS
7.5、商品首页
7.5.1、基本页面处理
7.5.2、保存购物车信息的数据设计
7.5.3 页面静态化
7.5.4、使用缓存
7.6、商品详情页
7.7、商品列表页
7.7.1、分页
7.7.2、页码控制
7.8、商品搜索
7.8.1、安装和配置
7.8.2、索引文件生成
7.8.3、全文检索的使用
7.8.4、改变分词方式
8、购物车模块开发
8.1、添加到购物车
8.2、购物车页面
8.3、购物车记录更新
8.4、购物车记录删除
9、订单模块开发
9.1、提交订单页面
9.2、订单生成
9.2.1、mysql事务
9.2.2、订单并发处理
9.3、用户中心-订单页
9.4、订单支付
10、项目部署
10.1、uwsgi
10.1.1、uwsgi的安装
10.1.2、uwsgi的配置
10.1.3、uwsgi的启动和停止
10.2、nginx
10.2.1、nginx 配置转发请求给uwsgi
10.2.2、nginx配置处理静态文件
10.2.3 nginx转发请求给另外地址
10.2.4、nginx配置upstream实现负载均衡
10.2.5、部署项目流程图
11、开发过程中遇到的bug个人总结
1、在模板中载入静态文件前需要在配置文件settings.py中加入配置
2、django新版本中查询数据库后对象不存在报错的异常类是core.exceptions的ObjectDoesNotExist
3、加密用户身份信息当做url的token值,用authlib包代替itsdangerous,可以指定签名算法HS256
4、celery不支持window10,安装eventlet包,使用celery -A celery_tasks.tasks worker -l info -P eventlet -E命令或者建议使用下面的命令就用安装eventlet包
5、django自带的login()报错:redis输入了一个空类型的值
6、Django的authenticate已经包含了is_active判断,即使用户名密码正确,is_active为0也会返回空,所以需要在setting.py中加配置
7、FastDFS只支持Linux,可以把fastDFS运行在云服务器上,Windows本地电脑上运行FastDFS客户端fdfs-client-py
8、window启动nginx,先到文件夹中启动nginx.exe,再到cmd中输入nginx.exe。停止nginx,在cmd中完整有序停止用nginx -s quit,再用taskkill /f /t /im nginx.exe
9、is_authenticated在Django4.0中是一个属性而不是一个方法
10、Django4.0已经移除ungettext,所以在引入haystack的时候会报错,修改haystack文件夹下的admin.py把ungettext三处地方修改为ngettext
11、Django4.0已经移除smart_text,修改haystack文件夹下的form.py俩处地方把smart_text修改为smart_str
12、配置为乐观锁时,需要设置MySQL默认的隔离级别(可重复读)为(读取提交内容),在MySQL配置文件skip-ex,,,下添加一行transaction-isolation = READ-COMMITTED
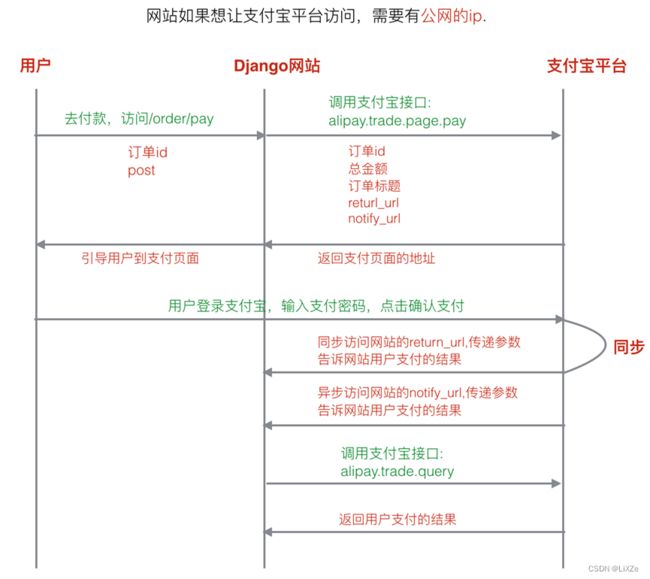
13、网站如果想让支付宝平台访问(获取支付后的结果),需要有公网IP
14、安装alipay-sdk-python 提示安装pycrypto 问题:
15、支付宝沙箱测试不需要重新设置密钥和公钥,直接使用默认。
16、使用支付宝交易查询接口要使用AlipayTradeQueryResponse来获取解析后响应的结果
17、win10上没法部署uwsgi,可以通过其它方式间接使用uwsgi,但没必要,最终都是要部署在Linux系统。
18、Django网站响应慢(修改数据库查询方式)
19、指定表名,不用一定和应用名相连,class Meta: db_table = '表名'
20、发布网站时需要在settings.py中把debug改为false,allowed_host = ['*']
22、session
23、模板中的自定义过滤器参数只能是一个或俩个
24、csrf防护(跨站请求伪造攻击):
25、url反向解析:
1、项目来源及开发介绍
修改后的天天生鲜(Django4.0版本):
GitHub - LiXZe/dailyfreshContribute to LiXZe/dailyfresh development by creating an account on GitHub. https://github.com/LiXZe/dailyfresh
https://github.com/LiXZe/dailyfresh
1.1、天天生鲜介绍
首先,此次天天生鲜项目来源是黑马程序员Python就业班的Web开发项目,虽是几年前的项目,但在Python商城项目里也算是功能比较齐全,什么异步任务处理、页面静态化、搜索引擎、高并发库存问题、邮件发送激活、购物车缓存、分布式文件存储、服务器部署、支付宝支付接口调用这些都有,适合拿来学习Python的Web开发练练手,此篇博客的内容也是我对原先项目笔记的修改,有些图片是原先黑马项目的图片。
其次,原先天天生鲜项目使用的是Django1.8.2版本,我自己改成了新版本Django4.0版本的,使用的虚拟环境是anaconda,不论学习什么语言和框架,一定要会看框架对应的开发文档,从1.8.2到4.0版本的变动挺多的,就需要自己去查看Django4.0的开发文档,附上Django4.0中文的开发文档对应链接:
Django 文档 | Django 文档 | Django https://docs.djangoproject.com/zh-hans/4.0/
https://docs.djangoproject.com/zh-hans/4.0/
最后文末,是我在开发过程中遇到的各种问题,然后我就记了下来,附上了我的解决方法(由于我这个项目是在win10环境下写的,所以遇到的问题会更多。
先上网站运行后截图:
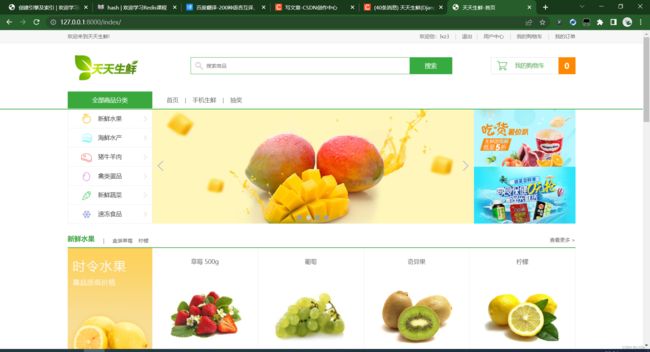
首先是主页:
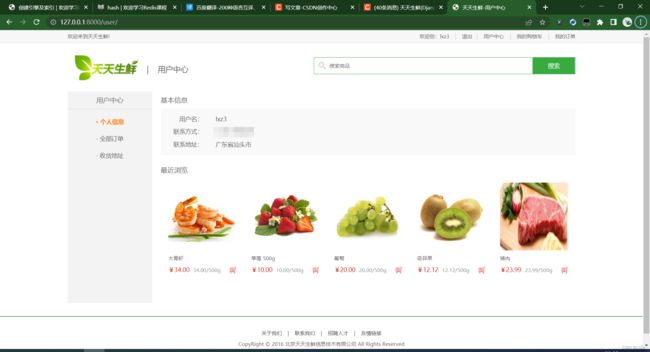
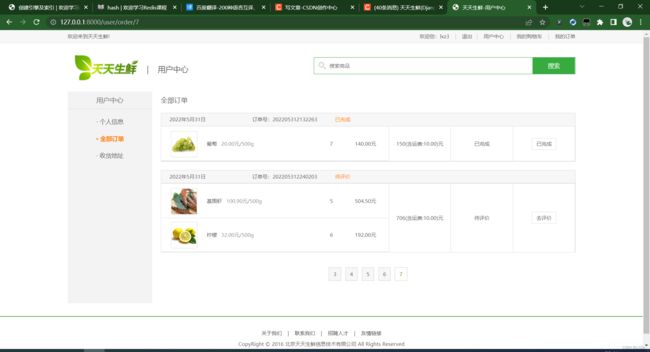
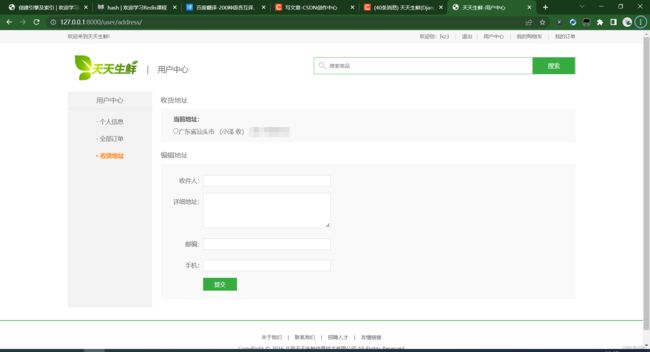
用户中心的3个功能页面:
购物车页面:
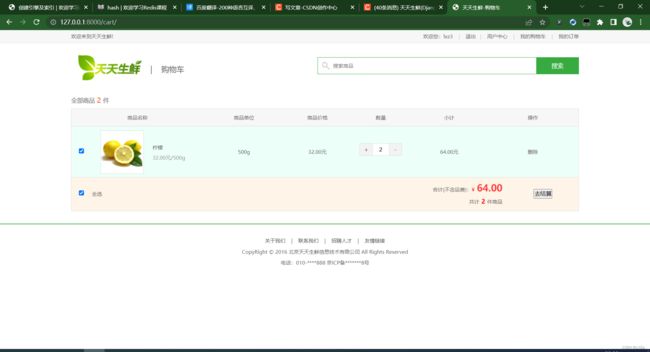
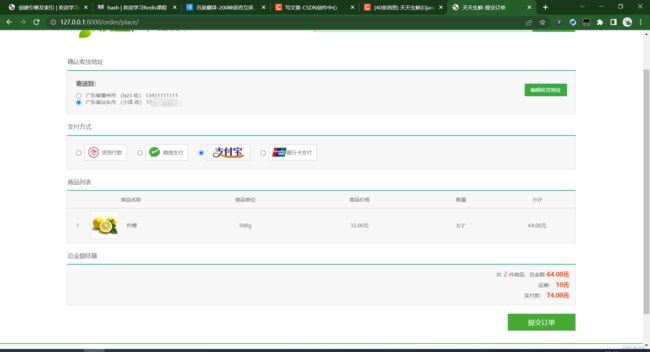
订单支付:

商品详情:
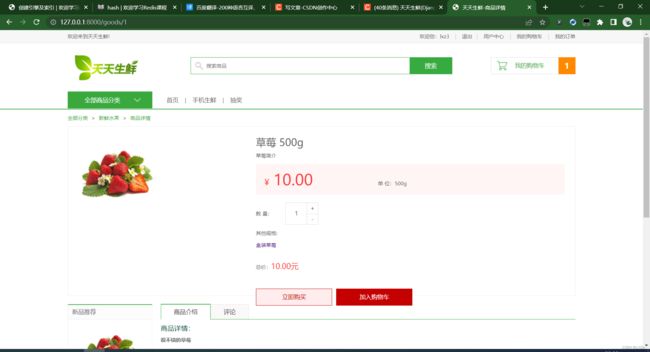
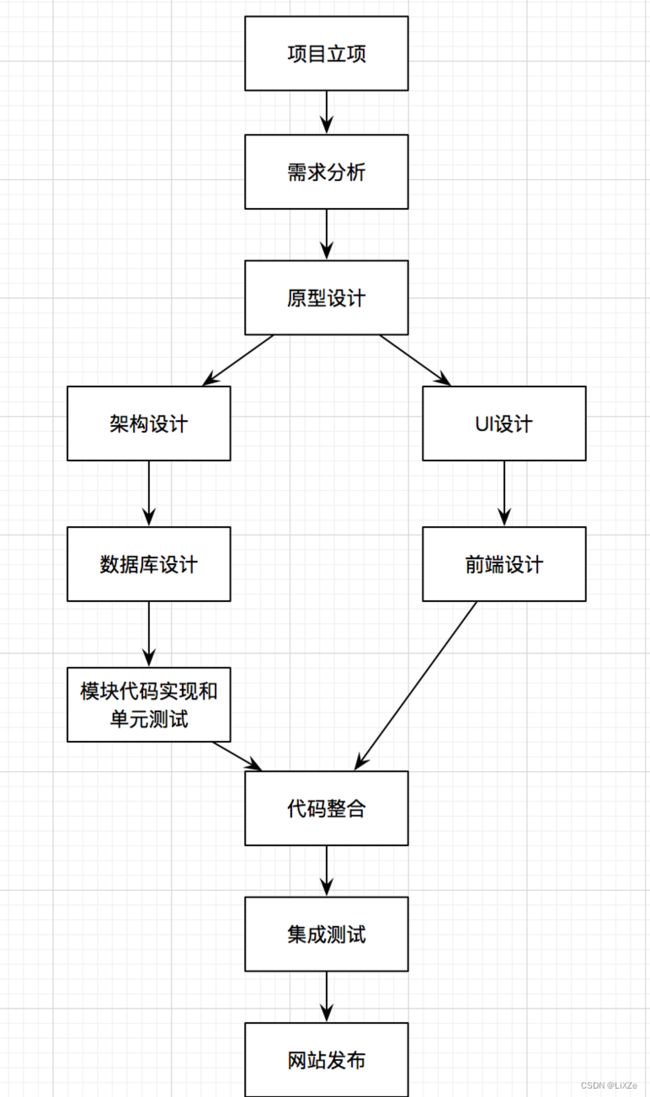
1.2、Web开发流程介绍
在正式学习商城项目开发前,先介绍一下常见Web商城项目的开发流程:
1.2.1、需求分析
1.2.1.1、用户模块
1.注册页
- 注册时校验用户名是否已被注册。
- 完成用户信息的注册。
- 给用户的注册邮箱发送邮件,用户点击邮件中的激活链接完成用户账户的激活。
2.登录页
- 实现用户的登录功能。
3.用户中心
- 用户中心信息页:显示登录用户的信息,包括用户名、电话和地址,同时页面下方显示出用户最近浏览的商品信息。
- 用户中心地址页:显示登录用户的默认收件地址,页面下方的表单可以新增用户的收货地址。
- 用户中心订单页:显示登录用户的订单信息。
4.其他
- 如果用户已经登录,页面顶部显示登录用户的信息。
1.2.1.2、商品相关
1.首页
- 动态指定首页轮播商品信息。
- 动态指定首页活动信息。
- 动态获取商品的种类信息并显示。
- 动态指定首页显示的每个种类的商品(包括图片商品和文字商品)。
- 点击某一个商品时跳转到商品的详情页面。
2.商品详情页
- 显示出某个商品的详情信息。
- 页面的左下方显示出该种类商品的2个新品信息。
3.商品列表页
- 显示出某一个种类商品的列表数据,分页显示并支持按照默认、价格、和人气进行排序。
- 页面的左下方显示出该种类商品的2个新品信息。
4.其他
- 通过页面搜索框搜索商品信息。
1.2.1.3、购物车相关
- 列表页和详情页将商品添加到购物车。
- 用户登录后,首页,详情页,列表页显示登录用户购物车中商品的数目。
- 购物车页面:对用户购物车中商品的操作。如选择某件商品,增加或减少购物车中商品的数目。
1.2.1.4、订单相关
- 提交订单页面:显示用户准备购买的商品信息。
- 点击提交订单完成订单的创建。
- 用户中心订单页显示用户的订单信息。
- 点击支付完成订单的支付。
1.2.2、项目架构概览
1.2.2.1、页面图:
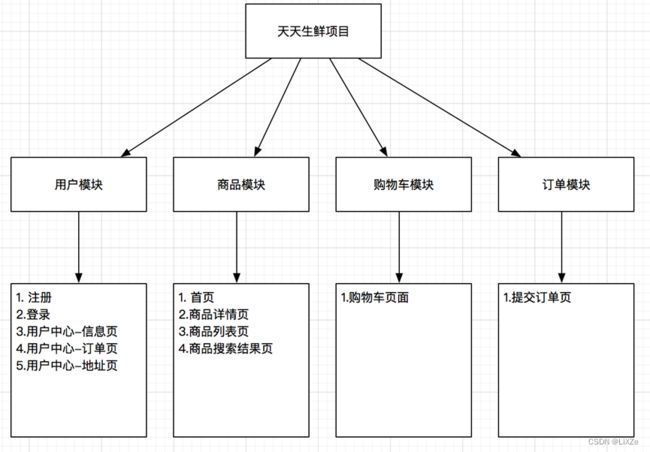
1.2.2.2、功能图:
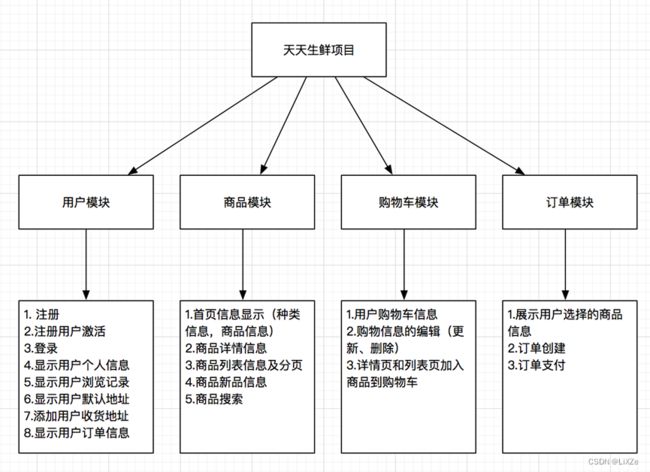
1.2.2.3、部署图:
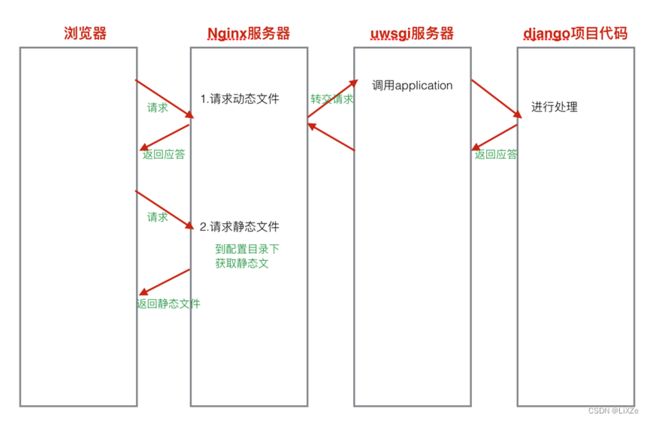
1.2.3、SKU与SPU概念
SPU = Standard Product Unit (标准产品单位)
SPU 是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述 了一个产品的特性。通俗点讲,属性值、特性相同的商品就可以称为一个 SPU。 例如:iphone7 就是一个 SPU,与商家,与颜色、款式、套餐都无关。
SKU=stock keeping unit(库存量单位)
SKU 即库存进出计量的单位, 可以是以件、盒、托盘等为单位。 SKU 是物理上不可分割的最小存货单元。在使用时要根据不同业态,不同管理模式来处理。 在服装、鞋类商品中使用最多最普遍。 例如:纺织品中一个 SKU 通常表示:规格、颜色、款式。
2、项目架构
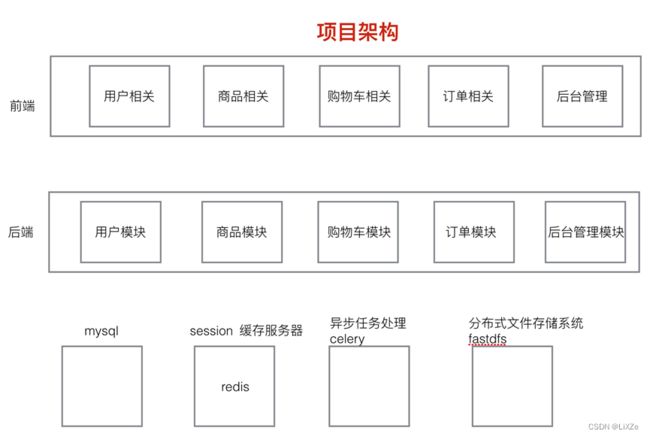
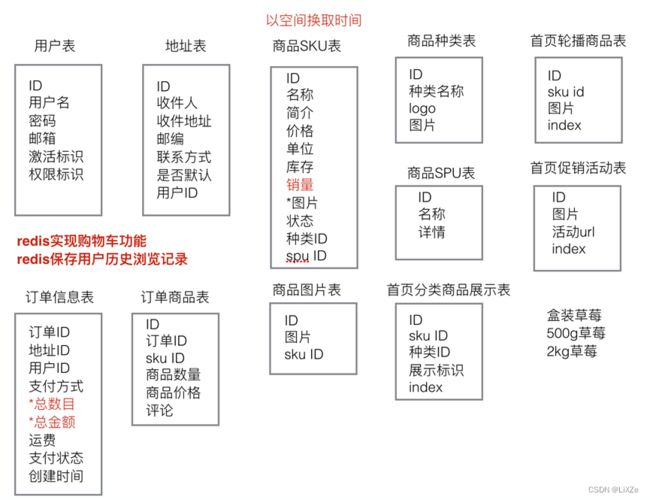
3、数据库表结构
4、用户认证模型
5、类视图
将视图view以类的形式定义
通用类视图基类:
django.views.generic.View ( 与django.views.generic.base.View 是同一个)
urls.py中配置路由使用类视图的as_view()方法
由dispatch()方法具体将请求request分发至对应请求方式的处理方法中(get、post等)
类视图资料:内置基于类的视图 API | Django 文档 | Django
6、用户模块开发
6.1、Django4.0认证系统文档
django-admin 和 manage.py | Django 文档 | Django
| 方法名 |
备注 |
| create_user |
创建用户 |
| authenticate |
登录验证 |
| login |
记录登录状态 |
| logout |
退出用户登录 |
| is_authenticated |
判断用户是否登录 |
| login_required装饰器 |
进行登录判断 |
6.2、用户注册
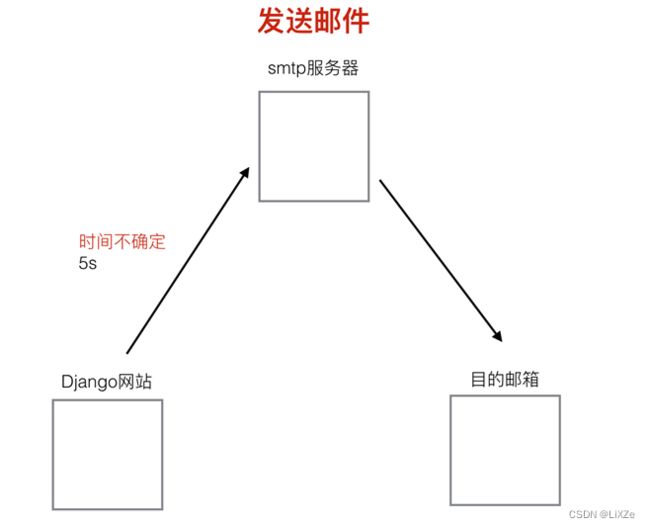
6.2.1、django发送邮件
6.2.2、Celery异步任务队列
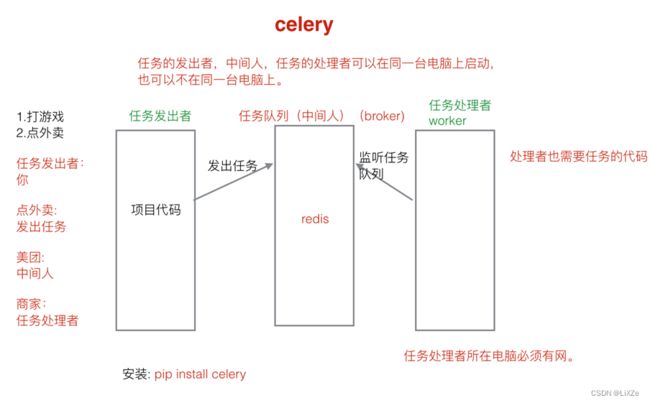
6.2.2.1、使用
在项目根目录下新建一个celery_task文件夹,文件夹下新建一个task文件:
# 使用celery
from django.core.mail import send_mail
from django.conf import settings
from celery import Celery
import time
from django.template import loader
# 在任务处理者一端加这几句
import os
import django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "dailyfresh.settings")
django.setup()
from goods.models import GoodsType, IndexGoodsBanner, IndexPromotionBanner, IndexTypeGoodsBanner
# 创建一个Celery类的实例对象
app = Celery('celery_tasks.tasks', broker='redis://mast:[email protected]:6379/1') # 使用我本地电脑的redis的1号数据库当做celery的broker,此段代码在注册视图函数中,异步实现发送邮件功能:
# 发送激活邮件,包含激活链接: http://127.0.0.1:8000/user/active/token值
# 激活链接中需要包含用户的身份信息, 并且要把身份信息进行加密
"""加密用户的身份信息,生成激活token,使用authlib代替itsdangerous"""
data = {'confirm': user.id}
header = {'alg': 'HS256'} # 签名算法
token = jwt.encode(header=header, payload=data, key=settings.SECRET_KEY) # byte类型
token = token.decode()
# 发送邮箱:使用celery异步处理发送邮件,加入到任务队列(broker)中
send_register_active_email.delay(email, username, token)
# 返回应答, 跳转到首页
return redirect(reverse('goods:index'))6.2.2.2、发出任务

6.2.2.3、启动worker
重新打开一个终端,输入命令celery -A celery_tasks.tasks worker -l info --pool solo
6.3、用户激活
使用authlib加密用户的身份信息,而不是使用原先项目自带的itsdangerous。
authlib的使用:
参考资料:
JSON Web Token (JWT) — Authlib 1.0.1 documentation
6.3.1、加密用户身份信息
from authlib.jose import jwt, JoseError
"""加密用户的身份信息,生成激活token,使用authlib代替itsdangerous"""
data = {'confirm': user.id}
header = {'alg': 'HS256'} # 签名算法
token = jwt.encode(header=header, payload=data, key=settings.SECRET_KEY) # byte类型
token = token.decode()6.3.2、解密用户身份信息验证
# 进行解密,获取要激活的用户信息
try:
info = jwt.decode(token, settings.SECRET_KEY)
print(info)
# 获取待激活用户的id
user_id = info['confirm']
# 根据id获取用户信息
user = User.objects.get(id=user_id)
user.is_active = 1
user.save()6.4、用户登录
6.4.1、配置redis作为Django缓存和session后端
django-redis文档:django-redis 中文文档 — Django-Redis 4.7.0 文档
配置:
# Django的缓存配置
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/2", # 使用2号数据库
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"PASSWORD": "yourpassword"
}
}
}6.4.2、登录判断装饰器login_required
可以在用户模块的地址配置直接使用:
urlpatterns = [
path('register/', RegisterView.as_view(), name='register'), # 使用视图类
re_path(r'active/(?P.*)$', ActiveView.as_view(), name='active'), # 激活用户
path('login/', LoginView.as_view(), name='login'),
path('', UserInfoView.as_view(), name='user'), # 用户信息-中心
re_path(r'order/(?P\d+)$', UserOrderView.as_view(), name='order'), # 用户信息-订单
path('address/', AddressView.as_view(), name='address'), # 用户信息-地址
path('logout/', LogoutView.as_view(), name='logout'), # 用户注销
path('testcelery/', views.testCelery)
# path('', login_required(UserInfoView.as_view()), name='user'), # 用户信息-中心
# path('order/', login_required(UserOrderView.as_view()), name='order'), # 用户信息-订单
# path('address/', login_required(AddressView.as_view()), name='address'), # 用户信息-地址
# path('register', views.register, name='register'),
# path('register_handle', views.register_handle, name='register_handle')
] 或者修改类LoginRequireMixin中的父类的as_view方法:
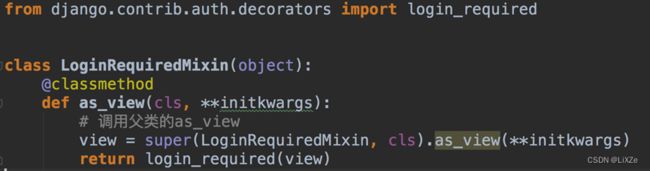
在setting.py中配置未登录时的跳转:

6.5、用户退出
logout函数清除登录用户的session信息。
6.6、用户地址
模型类和模型管理器类: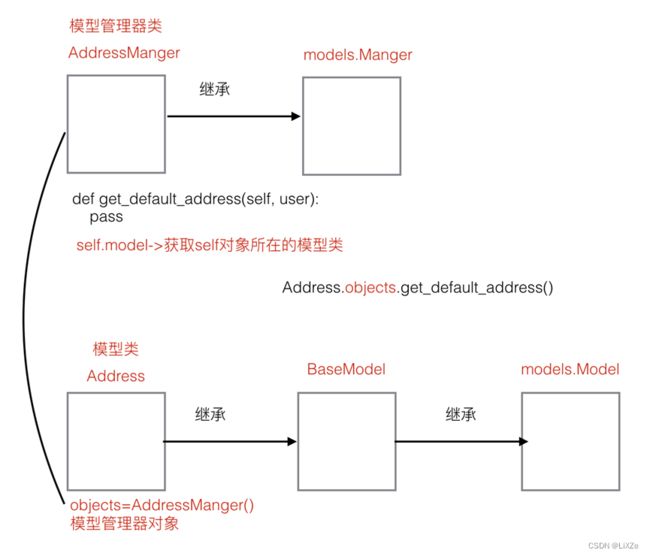
6.7、用户个人信息
6.7.1 redis存储历史浏览记录分析

参考资料:
Redis 命令参考 — Redis 命令参考
Welcome to redis-py’s documentation! — redis-py dev documentation
6.7.2、django-redis获取redis链接
from django_redis import get_redis_connection
on = get_redis_connection('default') # 使用setting.py中默认的redis配置7、商品模块开发
7.1、了解FastDFS分布式文件系统
(我个人是把FastDFS部署在自己的阿里云服务器上,安装到云服务器上去访问是也遇到了很多问题,文末总结问题)
集群
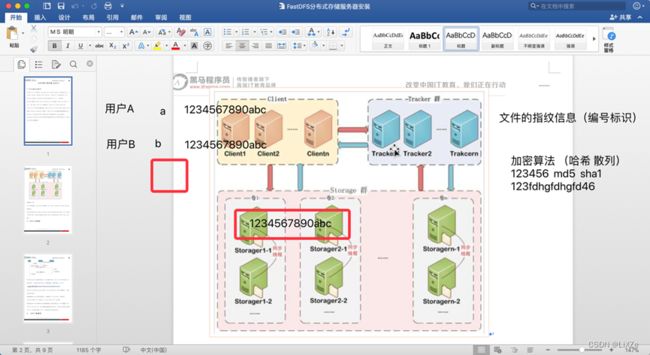
启动FastDFS的方法,需要的操作:
修改如下的配置文件 (在/etc/fdfs目录中)

tracker_server=自己的ip地址:22122
启动tracker、storage、nginx服务:
sudo service fdfs_trackerd start
sudo service fdfs_storaged start
sudo /usr/local/nginx/sbin/nginx
执行如下命令测试是否成功
fdfs_upload_file /etc/fdfs/client.conf 要上传的图片文件
如果返回类似group1/M00/00/00/rBIK6VcaP0aARXXvAAHrUgHEviQ394.jpg的文件id则说明文件上传成功
在浏览器中可以用 127.0.0.1:8888/返回的文件id
访问图片
7.2、python对接fastdfs
(根据视频提供的方法这一步也有出现一些问题,但还是给出,文末总结解决问题)
1. workon django_py3
2. 进入fdfs_client-py-master.zip所在目录
3. pip install fdfs_client-py-master.zip
7.3、项目上传图片和使用图片流程
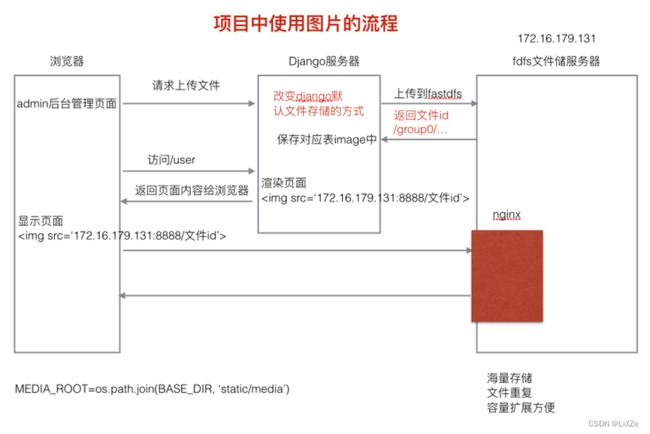
海量存储,存储容量扩展方便。
文件内容重复。
结合nginx提高网站访问图片的效率。
7.4、Django二次开发对接FastDFS
配置文件settings中加入如下配置:
# 设置Django的文件存储类
DEFAULT_FILE_STORAGE = 'utils.fdfs.storage.FDFSStorage'
# 设置fdfs使用的client.conf配置文件
FDFS_CLIENT_CONF = r'D:\django4.0\dailyfresh\utils\fdfs\client.conf'
# 设置我的阿里云服务器上的fdfs的nginx的IP和端口号
FDFS_URL = 'http://121.89.236.181:8888/'创建utils/fdfs 目录:
storage.py文件中自定义文件存储类:
from django.core.files.storage import Storage
from fdfs_client.client import Fdfs_client
from dailyfresh import settings
class FDFSStorage(Storage):
"""自定义fastdfs文件存储类"""
def __init__(self, client_conf=None, base_url=None):
"""动态地对storage类进行配置"""
if client_conf is None:
client_conf = settings.FDFS_CLIENT_CONF
self.client_conf = client_conf
if base_url is None:
base_url = settings.FDFS_URL
self.base_url = base_url
def save(self, name, content, max_length=None): # 一定需要添加参数max_length
"""name为上传文件的名字,content包含上传文件内容的File对象"""
client = Fdfs_client(self.client_conf)
# 上传文件到我的阿里云服务器fastdfs系统中
result = client.upload_by_buffer(content.read())
if result.get('Status') != 'Upload successed.':
# 上传失败
raise Exception('上传文件到云服务器的fastdfs系统失败!')
filename = result.get('Remote file_id')
# save方法最后返回的内容为保存在django系统中的图片文件名称
return filename
def url(self, name):
"""返回访问文件的url地址,name为保存在django数据表中的为文件名"""
return self.base_url + name
7.5、商品首页
7.5.1、基本页面处理
动态给对象增加属性

7.5.2、保存购物车信息的数据设计

7.5.3 页面静态化
把原本动态的页面处理结果保存成html文件,让用户直接访问这个生成出来的静态的html页面
配置在管理员页面的方法中:
from django.contrib import admin
from goods.models import GoodsType, IndexTypeGoodsBanner, IndexPromotionBanner, IndexGoodsBanner, GoodsSKU
from django.core.cache import cache
class BaseModelAdmin(admin.ModelAdmin):
def save_model(self, request, obj, form, change):
"""新增或更新表中的数据时调用"""
super().save_model(request, obj, form, change)
# 发出任务,让celery worker重新生成首页静态页
from celery_tasks.tasks import generate_static_index_html
generate_static_index_html.delay()
# 清除首页的缓存数据
cache.delete('index_page_data')
def delete_model(self, request, obj):
"""删除表中的数据时调用"""
super().delete_model(request, obj)
# 发出任务,让celery worker重新生成首页静态页
from celery_tasks.tasks import generate_static_index_html
generate_static_index_html.delay()
# 清除首页的缓存数据
cache.delete('index_page_data')
7.5.4、使用缓存
将处理计算的结果先临时保存起来,下次使用的时候可以先直接使用,如果没有这个备份的数据,重新进行计算处理
将缓存数据保存在内存中 (本项目中保存在redis中)
cache
修改了数据库的数据,直接删除缓存
缓存要设置有效期

7.6、商品详情页
添加历史浏览记录:
# 获取用户购物车中商品的数目
user = request.user
cart_count = 0
if user.is_authenticated:
# 用户已登录
conn = get_redis_connection('default')
cart_key = 'cart_%d' % user.id
cart_count = conn.hlen(cart_key)
# 添加用户的历史记录
conn = get_redis_connection('default')
history_key = 'history_%d' % user.id
# 移除列表中的goods_id
conn.lrem(history_key, 0, goods_id)
# 把goods_id插入到列表的左侧
conn.lpush(history_key, goods_id)
# 只保存用户最新浏览的5条信息
conn.ltrim(history_key, 0, 4)7.7、商品列表页
7.7.1、分页
django有自带的分页器:分页 | Django 文档 | Django


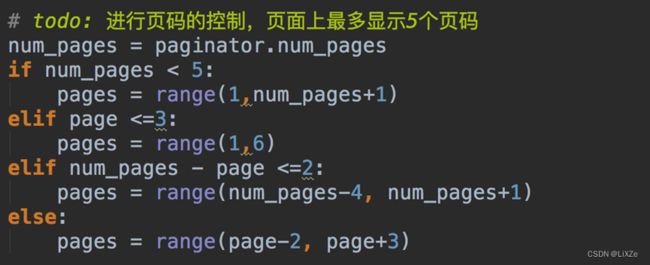
7.7.2、页码控制
7.8、商品搜索
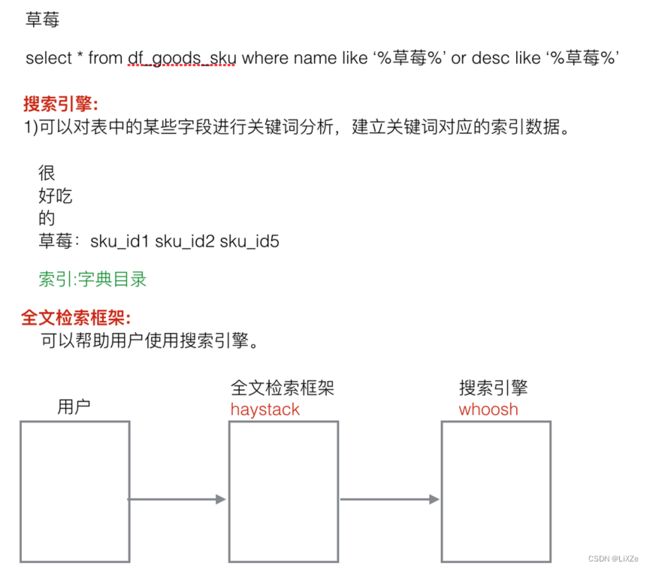
7.8.1、安装和配置
(在win10环境下安装haystack、whoosh和jieba会遇到bug)
安装python包。
pip install django-haystack
pip install whoosh
在settings.py文件中注册应用haystack并做如下配置:
# 全文检索框架的配置
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
# 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine', # 使用自定义用jieba中文分词库修改过的引擎
# 索引文件路径
'PATH': Path.joinpath(BASE_DIR, 'whoosh_index'),
}
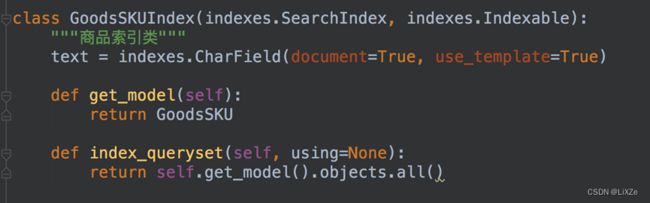
}7.8.2、索引文件生成
在goods应用目录下新建一个search_indexes.py文件,在其中定义一个商品索引类:
在templates下面新建目录search/indexes/goods:
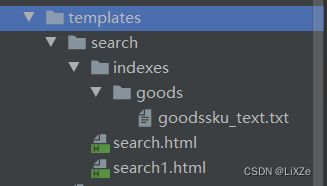
在此目录下面新建一个文件goodssku_text.txt并编辑内容如下:
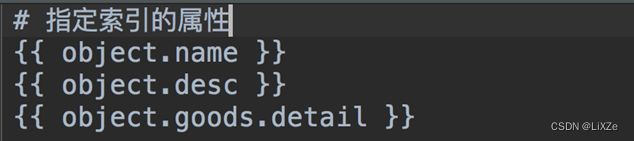
使用命令生成索引文件。
python manage.py rebuild_index
7.8.3、全文检索的使用
1) 在项目目录下的url文件配置url:
urlpatterns = [
path('admin/', admin.site.urls),
# 做url反向解析,动态获取url地址。namespace是放在include里面,include还需要传一个元组,元组内还要有app_name。
path('user/', include(('user.urls', 'user'), namespace='user')), # 用户模块
path('cart/', include(('cart.urls', 'cart'), namespace='cart')), # 购物车模块
path('order/', include(('order.urls', 'order'), namespace='order')), # 订单模块
path('tinymce/', include('tinymce.urls')), # 富文本编辑器
path('search/', include('haystack.urls')), # 全文检索框架
path('', include(('goods.urls', 'goods'), namespace='goods')), # 商品模块,作为主页
]2)表单搜索时设置表单内容如下:

点击标题进行提交时,会通过haystack搜索数据。
全文检索结果:
搜索出结果后,haystack会把搜索出的结果传递给templates/search目录下的search.html,传递的上下文包括:
query:搜索关键字
page:当前页的page对象 –>遍历page对象,获取到的是SearchResult类的实例对象,对象的属性object才是模型类的对象。
paginator:分页paginator对象
通过HAYSTACK_SEARCH_RESULTS_PER_PAGE 可以控制每页显示数量。
7.8.4、改变分词方式
1) 安装jieba分词模块。
pip install jieba去到conda虚拟环境下python的下的haystack目录(因为我是用pip install安装的包):
/home/python/.virtualenvs/bj17_py3/lib/python3.5/site-packages/haystack/backends/在上面的目录中创建ChineseAnalyzer.py文件:
import jiebafrom whoosh.analysis import Tokenizer, Token class ChineseTokenizer(Tokenizer): def __call__(self, value, positions=False, chars=False, keeporiginal=False, removestops=True, start_pos=0, start_char=0, mode='', **kwargs): t = Token(positions, chars, removestops=removestops, mode=mode, **kwargs) seglist = jieba.cut(value, cut_all=True) for w in seglist: t.original = t.text = w t.boost = 1.0 if positions: t.pos = start_pos + value.find(w) if chars: t.startchar = start_char + value.find(w) t.endchar = start_char + value.find(w) + len(w) yield t def ChineseAnalyzer(): return ChineseTokenizer()
复制whoosh_backend.py文件,改为如下名称。
whoosh_cn_backend.py打开复制出来的新文件,引入中文分析类,内部采用jieba分词。
from .ChineseAnalyzer import ChineseAnalyzer更改词语分析类:
查找 analyzer=StemmingAnalyzer() 改为 analyzer=ChineseAnalyzer()
修改settings.py文件中的配置项。
重新创建索引数据
python manage.py rebuild_index8、购物车模块开发
8.1、添加到购物车
确定前端是否传递数据,传递什么数据,什么格式
确定前端访问的方式(get post)
确定返回给前端的什么数据,什么格式
8.2、购物车页面
购物车页面js
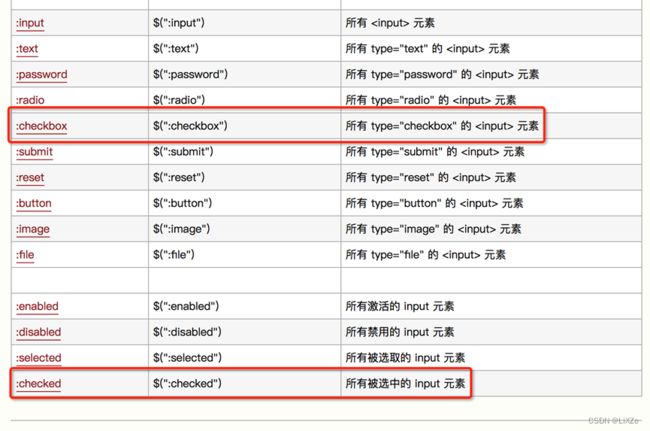
Jquery选择器参考资料:
http://www.w3school.com.cn/jquery/jquery_ref_selectors.asp
8.3、购物车记录更新
采用ajax post请求
前端需要传递的参数:商品id(sku_id) 商品数量(count)

8.4、购物车记录删除
采用ajax post请求
前端需要传递的参数:商品id(sku_id)
9、订单模块开发
9.1、提交订单页面
9.2、订单生成

9.2.1、mysql事务
- 事务概念
一组mysql语句,要么执行,要么全不不执行。
事务的特点
1、原子性:一组事务,要么成功;要么撤回。
2、稳定性 :有非法数据(外键约束之类),事务撤回。
3、隔离性:事务独立运行。一个事务处理后的结果,影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
4、可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和高速度不可兼得, innodb_flush_log_at_trx_commit 选项 决定什么时候吧事务保存到日志里。
- 事务控制语句
BEGIN或START TRANSACTION;显式地开启一个事务;
COMMIT;也可以使用COMMIT WORK,不过二者是等价的。COMMIT会提交事务,并使已对数据库进行的所有修改称为永久性的;
ROLLBACK;有可以使用ROLLBACK WORK,不过二者是等价的。回滚会结束用户的务,并撤销正在进行的所有未提交的修改;
SAVEPOINT identifier;SAVEPOINT允许在事务中创建一个保存点,一个事务中可以有多个SAVEPOINT;
RELEASE SAVEPOINT identifier;删除一个事务的保存点,当没有指定的保存点时,执行该语句会抛出一个异常;
ROLLBACK TO identifier;把事务回滚到标记点;
- mysql事务隔离级别
SQL标准定义了4类隔离级别,包括了一些具体规则,用来限定事务内外的哪些改变是可见的,哪些是不可见的。低级别的隔离级一般支持更高的并发处理,并拥有更低的系统开销。
Read Uncommitted(读取未提交内容)
在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。本隔离级别很少用于实际应用,因为它的性能也不比其他级别好多少。读取未提交的数据,也被称之为脏读(Dirty Read)。
Read Committed(读取提交内容)
这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)。它满足了隔离的简单定义:一个事务只能看见已经提交事务所做的改变。这种隔离级别 也支持所谓的不可重复读(Nonrepeatable Read),因为同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select可能返回不同结果。
Repeatable Read(可重读)
这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。
Serializable(可串行化)
这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。简言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
这四种隔离级别采取不同的锁类型来实现,若读取的是同一个数据的话,就容易发生问题。例如:
脏读(Drity Read):某个事务已更新一份数据,另一个事务在此时读取了同一份数据,由于某些原因,前一个RollBack了操作,则后一个事务所读取的数据就会是不正确的。
不可重复读(Non-repeatable read):在一个事务的两次查询之中数据不一致,这可能是两次查询过程中间插入了一个事务更新的原有的数据。
幻读(Phantom Read):在一个事务的两次查询中数据笔数不一致,例如有一个事务查询了几行(Row)数据,而另一个事务却在此时插入了新的几行数据,先前的事务在接下来的查询中,就会发现有几行数据是它先前所没有的。
- 设置mysql事务的隔离级别
打开mysql配置文件: sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf, 添加如下行。
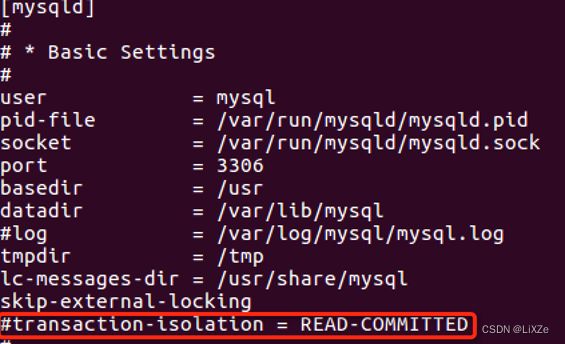
保存配置文件,重启mysql服务。
sudo service mysql restart
9.2.2、订单并发处理

9.2.1.1、悲观锁
select * from df_goods_sku where id=17 for update;
订单创建(悲观锁):
# 前端传递的参数:地址id(addr_id) 支付方式(pay_method) 用户要购买的商品id字符串(sku_ids)
# mysql事务: 一组sql操作,要么都成功,要么都失败
# 高并发:秒杀
# 支付宝支付
class OrderCommitView1(View):
"""订单创建(悲观锁版本)"""
@transaction.atomic
def post(self, request):
"""订单创建"""
# 判断用户是否登录
user = request.user
if not user.is_authenticated:
# 用户未登录
return JsonResponse({'res': 0, 'errmsg': '用户未登录'})
# 接收参数
addr_id = request.POST.get('addr_id')
pay_method = request.POST.get('pay_method')
sku_ids = request.POST.get('sku_ids') # 1,3
# 校验参数
if not all([addr_id, pay_method, sku_ids]):
return JsonResponse({'res': 1, 'errmsg': '参数不完整'})
# 校验支付方式
if pay_method not in OrderInfo.PAY_METHODS.keys():
return JsonResponse({'res': 2, 'errmsg': '非法的支付方式'})
# 校验地址
try:
addr = Address.objects.get(id=addr_id)
except ObjectDoesNotExist:
# 地址不存在
return JsonResponse({'res': 3, 'errmsg': '地址非法'})
# todo: 创建订单核心业务
# 组织参数
# 订单id: 20171122181630+用户id
order_id = datetime.now().strftime('%Y%m%d%H%M%S') + str(user.id)
# 运费
transit_price = 10
# 总数目和总金额
total_count = 0
total_price = 0
# 设置事务保存点
save_id = transaction.savepoint()
try:
# todo: 向df_order_info表中添加一条记录
order = OrderInfo.objects.create(order_id=order_id,
user=user,
addr=addr,
pay_method=pay_method,
total_count=total_count,
total_price=total_price,
transit_price=transit_price)
# todo: 用户的订单中有几个商品,需要向df_order_goods表中加入几条记录
conn = get_redis_connection('default')
cart_key = 'cart_%d' % user.id
sku_ids = sku_ids.split(',')
for sku_id in sku_ids:
# 获取商品的信息
try:
# select * from df_goods_sku where id=sku_id for update;(加锁)
sku = GoodsSKU.objects.select_for_update().get(id=sku_id)
except:
# 商品不存在
transaction.savepoint_rollback(save_id)
return JsonResponse({'res': 4, 'errmsg': '商品不存在'})
print('user:%d stock:%d' % (user.id, sku.stock))
# import time
# time.sleep(10)
# 从redis中获取用户所要购买的商品的数量
count = conn.hget(cart_key, sku_id)
# todo: 判断商品的库存
if int(count) > sku.stock:
transaction.savepoint_rollback(save_id)
return JsonResponse({'res': 6, 'errmsg': '商品库存不足'})
# todo: 向df_order_goods表中添加一条记录
OrderGoods.objects.create(order=order,
sku=sku,
count=count,
price=sku.price)
# todo: 更新商品的库存和销量
sku.stock -= int(count)
sku.sales += int(count)
sku.save()
# todo: 累加计算订单商品的总数量和总价格
amount = sku.price * int(count)
total_count += int(count)
total_price += amount
# todo: 更新订单信息表中的商品的总数量和总价格
order.total_count = total_count
order.total_price = total_price
order.save()
except Exception as e:
transaction.savepoint_rollback(save_id)
return JsonResponse({'res': 7, 'errmsg': '下单失败'})
# 提交事务
transaction.savepoint_commit(save_id)
# todo: 清除用户购物车中对应的记录
conn.hdel(cart_key, *sku_ids)
# 返回应答
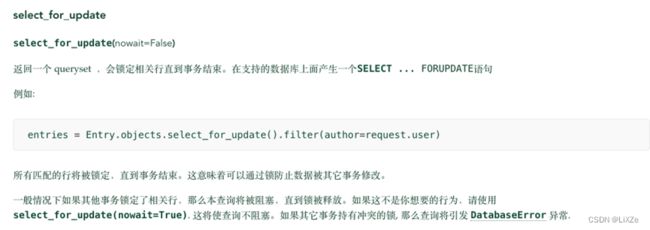
return JsonResponse({'res': 5, 'message': '创建成功'})悲观锁获取数据时对数据行了锁定,其他事务要想获取锁,必须等原事务结束。
- 9.2.2.2、乐观锁
查询时不锁数据,提交更改时进行判断.
update df_goods_sku set stock=0, sales=1 where id=17 and stock=1;
冲突比较少的时候,使用乐观锁。
冲突比较多的时候,使用悲观锁。
订单创建(乐观锁):
class OrderCommitView(View):
"""订单创建(乐观锁版本)"""
@transaction.atomic
def post(self, request):
"""订单创建"""
# 判断用户是否登录
user = request.user
if not user.is_authenticated:
# 用户未登录
return JsonResponse({'res': 0, 'errmsg': '用户未登录'})
# 接收参数
addr_id = request.POST.get('addr_id')
pay_method = request.POST.get('pay_method')
sku_ids = request.POST.get('sku_ids') # 1,3
# 校验参数
if not all([addr_id, pay_method, sku_ids]):
return JsonResponse({'res': 1, 'errmsg': '参数不完整'})
# 校验支付方式
if pay_method not in OrderInfo.PAY_METHODS.keys():
return JsonResponse({'res': 2, 'errmsg': '非法的支付方式'})
# 校验地址
try:
addr = Address.objects.get(id=addr_id)
except ObjectDoesNotExist:
# 地址不存在
return JsonResponse({'res': 3, 'errmsg': '地址非法'})
# todo: 创建订单核心业务
# 组织参数
# 订单id: 20171122181630+用户id
order_id = datetime.now().strftime('%Y%m%d%H%M%S') + str(user.id)
# 运费
transit_price = 10
# 总数目和总金额
total_count = 0
total_price = 0
# 设置事务保存点
save_id = transaction.savepoint()
try:
# todo: 向df_order_info表中添加一条记录
order = OrderInfo.objects.create(order_id=order_id,
user=user,
addr=addr,
pay_method=pay_method,
total_count=total_count,
total_price=total_price,
transit_price=transit_price)
# todo: 用户的订单中有几个商品,需要向df_order_goods表中加入几条记录
conn = get_redis_connection('default')
cart_key = 'cart_%d' % user.id
sku_ids = sku_ids.split(',')
for sku_id in sku_ids:
for i in range(3):
# 获取商品的信息
try:
sku = GoodsSKU.objects.get(id=sku_id)
except:
# 商品不存在
transaction.savepoint_rollback(save_id)
return JsonResponse({'res': 4, 'errmsg': '商品不存在'})
# 从redis中获取用户所要购买的商品的数量
count = conn.hget(cart_key, sku_id)
# todo: 判断商品的库存
if int(count) > sku.stock:
transaction.savepoint_rollback(save_id)
return JsonResponse({'res': 6, 'errmsg': '商品库存不足'})
# todo: 更新商品的库存和销量
orgin_stock = sku.stock
new_stock = orgin_stock - int(count)
new_sales = sku.sales + int(count)
# print('user:%d times:%d stock:%d' % (user.id, i, sku.stock))
# import time
# time.sleep(10)
# update df_goods_sku set stock=new_stock, sales=new_sales
# where id=sku_id and stock = orgin_stock
# 返回受影响的行数
res = GoodsSKU.objects.filter(id=sku_id, stock=orgin_stock).update(stock=new_stock, sales=new_sales)
if res == 0:
if i == 2:
# 尝试的第3次
transaction.savepoint_rollback(save_id)
return JsonResponse({'res': 7, 'errmsg': '下单失败2'})
continue
# todo: 向df_order_goods表中添加一条记录
OrderGoods.objects.create(order=order,
sku=sku,
count=count,
price=sku.price)
# todo: 累加计算订单商品的总数量和总价格
amount = sku.price * int(count)
total_count += int(count)
total_price += amount
# 跳出循环
break
# todo: 更新订单信息表中的商品的总数量和总价格
order.total_count = total_count
order.total_price = total_price
order.save()
except Exception as e:
transaction.savepoint_rollback(save_id)
return JsonResponse({'res': 7, 'errmsg': '下单失败'})
# 提交事务
transaction.savepoint_commit(save_id)
# todo: 清除用户购物车中对应的记录
conn.hdel(cart_key, *sku_ids)
# 返回应答
return JsonResponse({'res': 5, 'message': '创建成功'})9.3、用户中心-订单页
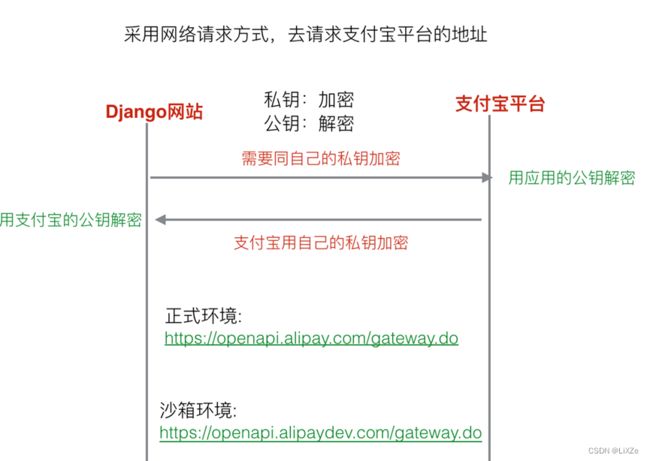
9.4、订单支付
调用支付宝的统一收单下单并支付页面接口:
统一收单下单并支付页面接口 | 网页&移动应用
然后还需要调用支付宝的收单线下交易查询接口:
统一收单线下交易查询接口 | 网页&移动应用
其中需要用到的商家和买家账户信息都在沙箱系统中:
支付宝开放平台
10、项目部署
10.1、uwsgi
遵循wsgi协议的web服务器。
10.1.1、uwsgi的安装
pip install uwsgi
10.1.2、uwsgi的配置
项目部署时,需要修改settings.py文件夹下的:
DEBUG=FALSE
ALLOWED_HOSTS=[‘*’]
uwsgi文件:
[uwsgi] #使用nginx连接时使用 socket=127.0.0.1:8080 #直接做web服务器使用 python manage.py runserver ip:port #http=127.0.0.1:8080 #项目目录 chdir=D:\django4.0\dailyfresh #项目中wsgi.py文件的目录,相对于项目目录 wsgi-file=dailyfresh/wsgi.py #指定启动的工作进程数 processes=4 #指定工作进程中的线程数 threads=2 master=True #保存启动之后主进程的pid pidfile=uwsgi.pid #设置uwsgi后台运行,uwsgi.log保存日志信息 daemonize=uwsgi.log #设置虚拟环境的路径 virtualenv=D:\Anaconda3\envs\dailyfresh
10.1.3、uwsgi的启动和停止
启动:uwsgi –-ini 配置文件路径 例如:uwsgi –-ini uwsgi.ini
停止:uwsgi --stop uwsgi.pid路径 例如:uwsgi –-stop uwsgi.pid
10.2、nginx
10.2.1、nginx 配置转发请求给uwsgi
location / {
include uwsgi_params;
uwsgi_pass uwsgi服务器的ip:port;
}
10.2.2、nginx配置处理静态文件
django settings.py中配置收集静态文件路径:
STATIC_ROOT=收集的静态文件路径 例如:/var/www/dailyfresh/static;
django 收集静态文件的命令:
python manage.py collectstatic
执行上面的命令会把项目中所使用的静态文件收集到STATIC_ROOT指定的目录下。
收集完静态文件之后,让nginx提供静态文件,需要在nginx配置文件中增加如下配置:
location /static {
alias /var/www/dailyfresh/static/;
}
10.2.3 nginx转发请求给另外地址
在location 对应的配置项中增加 proxy_pass 转发的服务器地址。
如当用户访问127.0.0.1时,在nginx中配置把这个请求转发给172.16.179.131:80(nginx)服务器,让这台服务器提供静态首页。
配置如下:
location = /{
proxy_pass http://172.16.179.131;
}
10.2.4、nginx配置upstream实现负载均衡
ngnix 配置负载均衡时,在server配置的前面增加upstream配置项。
upstream dailyfresh {
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}
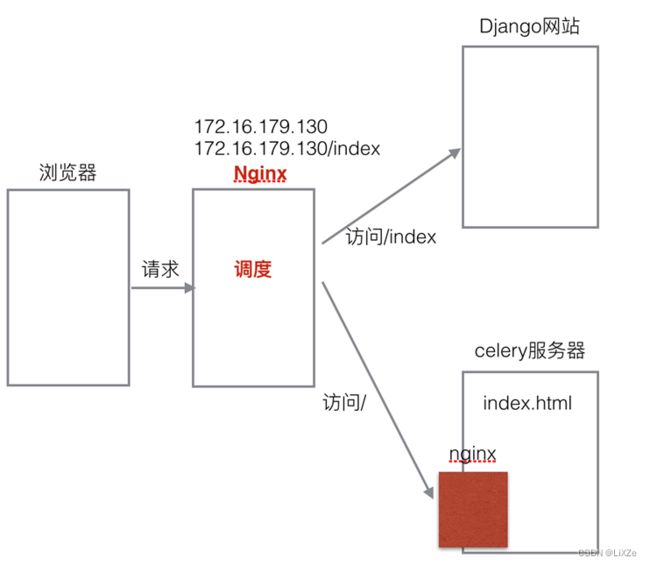
10.2.5、部署项目流程图
- 项目总结
- 生鲜类产品 B2C PC电脑端网页
- 功能模块:用户模块 商品模块(首页、 搜索、商品) 购物车模块 订单模块(下单、 支付)
- 用户模块:注册、登录、激活、退出、个人中心、地址
- 商品模块:首页、详情、列表、搜索(haystack+whoosh)
- 购物车: 增加、删除、修改、查询
- 订单模块:确认订单页面、提交订单(下单)、请求支付、查询支付结果、评论
- django默认的认证系统 AbstractUser
- itsdangerous 生成签名的token (序列化工具 dumps loads)
- 邮件 (django提供邮件支持 配置参数 send_mail)
- celery (重点 整体认识 异步任务)
- 页面静态化 (缓解压力 celery nginx)
- 缓存(缓解压力, 保存的位置、有效期、与数据库的一致性问题)
- FastDFS (分布式的图片存储服务, 修改了django的默认文件存储系统)
- 搜索( whoosh 索引 分词)
- 购物车redis 哈希 历史记录redis list
- ajax 前端用ajax请求后端接口
- 事务
- 高并发的库存问题 (悲观锁、乐观锁)
- 支付的使用流程
- nginx (负载均衡 提供静态文件)
11、开发过程中遇到的bug个人总结
1、在模板中载入静态文件前需要在配置文件settings.py中加入配置
2、django新版本中查询数据库后对象不存在报错的异常类是core.exceptions的ObjectDoesNotExist
3、加密用户身份信息当做url的token值,用authlib包代替itsdangerous,可以指定签名算法HS256
4、celery不支持window10,安装eventlet包,使用celery -A celery_tasks.tasks worker -l info -P eventlet -E命令或者建议使用下面的命令就用安装eventlet包
用celery生成静态页面报django.db.utils.DatabaseError错误,改为celery -A celery_tasks.tasks worker -l info --pool solo启动就不会报错
5、django自带的login()报错:redis输入了一个空类型的值
原因:在setting.py中配置redis(密码)时不能直接放在url中
6、Django的authenticate已经包含了is_active判断,即使用户名密码正确,is_active为0也会返回空,所以需要在setting.py中加配置
7、FastDFS只支持Linux,可以把fastDFS运行在云服务器上,Windows本地电脑上运行FastDFS客户端fdfs-client-py
这里我在自己的服务器上改了很久。我目的是为了把FastDFS安装在服务器上,然后自己本地跑代码测试的时候就就可以从云服务器上把图片拉下来。配置过程要按下面的来。
可以把云服务器上FastDFS的storage.conf, client.conf, mod_fastdfs.conf这3个文件的tracker_ip都设为外网IP。
每次更改后需要对tracker和storage这俩个服务器重启,已经重启nginx服务,然后fdfs_monitor /etc/fdfs/client.conf检查一下监控信息。
本地上传图片到云服务器的FastDFS时的自定义的storage.py代码文件中,参数为路径的方法不能是client.upload_by_file或client.upload_by_filename,否则就会报错。
然后django上传图片到服务器返回来的路径没有后缀,所以要用浏览器的前端代码去解析
8、window启动nginx,先到文件夹中启动nginx.exe,再到cmd中输入nginx.exe。停止nginx,在cmd中完整有序停止用nginx -s quit,再用taskkill /f /t /im nginx.exe
9、is_authenticated在Django4.0中是一个属性而不是一个方法
10、Django4.0已经移除ungettext,所以在引入haystack的时候会报错,修改haystack文件夹下的admin.py把ungettext三处地方修改为ngettext
11、Django4.0已经移除smart_text,修改haystack文件夹下的form.py俩处地方把smart_text修改为smart_str
12、配置为乐观锁时,需要设置MySQL默认的隔离级别(可重复读)为(读取提交内容),在MySQL配置文件skip-ex,,,下添加一行transaction-isolation = READ-COMMITTED
13、网站如果想让支付宝平台访问(获取支付后的结果),需要有公网IP
14、安装alipay-sdk-python 提示安装pycrypto 问题:
直接先pip install pycryptodome,下载alipay-sdk-python-3.3.398放到Lib\site-packages 的文件目录下,
进入到文件中修改 setup.py, 将requires = ["pycrypto","rsa"] 修改成 requires = ["crypto","rsa"]
15、支付宝沙箱测试不需要重新设置密钥和公钥,直接使用默认。
使用支付宝网页支付接口一直报错商户ID错误,原因settle_detail_info.trans_in才是设置商户ID(PID),而不是设置买家id的
sub_merchant.merchant_id是设置子商户商户id的而不是商户ID的
16、使用支付宝交易查询接口要使用AlipayTradeQueryResponse来获取解析后响应的结果
返回的数据就封装在这个类里,像使用交易支付接口一样的方法就会报Alipay SDK源代码出错
17、win10上没法部署uwsgi,可以通过其它方式间接使用uwsgi,但没必要,最终都是要部署在Linux系统。
18、Django网站响应慢(修改数据库查询方式)
CONN_MAX_AGE(定义连接的最大生存期的参数)=None设置为无限制的持久连接,避免了在每个请求中重新建立到数据库的连接的开销,但是
除了get方法外,all,filter,exclude,order_by方法都会返回一个查询集(QuerySet)
查询集特性:
1、惰性查询:只有在实际使用查询集中的数据的时候才会发生对数据库的真正查询。
2、缓存:当使用的是同一个查询集时,第一次使用的时候会发生实际数据库的查询,然后把结果缓存起来,之后再使用这个查询集时,使用的是缓存中的结果。
19、指定表名,不用一定和应用名相连,class Meta: db_table = '表名'
20、发布网站时需要在settings.py中把debug改为false,allowed_host = ['*']
21、cookie:是由服务器生成,存储在浏览器端的一小段文本信息。
设置:HttpResponse('').set_cookie('key', value, max_age=计算秒数,expires=)
获取:reques.COOKIE
22、session
浏览器访问服务器,在django_session表中设置session信息,表中有个session_key和session_data,session_key这一列是唯一标识码,session_data这一列是设置的信息。
然后django拿着这个唯一标识码设置一个cookie名为sessionid,下次浏览器访问服务器就会根据sessionid的值取出对应session的信息(这一步django会自动帮我们做),放在request.session中。
设置:request.session['']=
获取:request.session['']
23、模板中的自定义过滤器参数只能是一个或俩个
模板继承:所有页面都相同的内容都放在父模板文件中{% extensds 'booktest/base.html' %}
父模板需要预留一个块,{% block 块名 %} {% endblock 块名 %}
24、csrf防护(跨站请求伪造攻击):
只针对post请求,在有post请求的模板下加一个模板标签{% csrf_token %}
1)渲染模板文件时在页面生成一个名字叫做csrfmiddlewaretoken的隐藏域。
2)服务器交给浏览器保存一个名字为csrftoken的cookie信息。
3)提交表单时,两个值都会发给服务器,服务器进行比对,如果一样,则csrf验证通过,否则失败。
25、url反向解析:
某一个url配置的地址发生变化时,页面上使用反向解析生成地址的位置不需要发生变化。
from django.urls import reverse