NVIDIA重磅发布NVAIE 3.0,AI时代的操作系统来了

文|卖萌酱
近年来,AI技术发展迅速,随着以Pytorch、TensorFlow为代表的深度学习框架的成熟,AI模型的训练流程已经变得相对清晰、成熟。然而,预训练模型和后续一系列超大模型的出现,使得对于大部分AI开发者和企业来说,手动训练、定制模型的必要性正在不断减少。随着大众对AI模型的预期回归理性,企业在AI赛道的竞争已经逐渐从“学术竞争”转向“应用竞争”了。
今年这个现象尤为明显,diffusion models为代表的“文生图”模型的成熟在国内外掀起了一股AI绘画的热潮,AIGC的概念大火。在今年接近尾声的时候,ChatGPT则掀起了人机对话、乃至搜索引擎形态颠覆的热烈讨论,AI已经不再是一个学术层面的概念竞赛了,而是开始成为实实在在的应用和工具,参与到了社会生产力的提升上来。
甚至,AI作画的能力已经足以斩获一些大赛奖项了——
 ▲AI作画:空间歌剧院
▲AI作画:空间歌剧院
如图所示,《空间歌剧院》是Jason Allen使用AI绘图软件MidJourney在近千次的尝试后生成的,并且斩获了美国科罗拉多州博览会的一等奖。
然而,AI技术在应用开发层面的效率却面临了不少的挑战。
在企业的AI应用中,不可避免的要考虑如何将模型部署到生产环境,如何确保模型部署后的可用性和可靠性,以及如何监控和维护模型的性能等。这些挑战需要企业拥有一套完整的AI应用开发流程,并配备相应的工具和资源。
具备这么一套完备的工具链的企业往往是极少数的巨头,且由于工具链不够成熟,经常遭受员工吐槽。
这些问题,往往出现在模型训练完成后,将模型部署到生产环境的过程。模型部署的工具链相对较长,而且上下游工具的兼容性问题层出不穷,企业大量使用开源工具又容易引发安全问题等。 这些零散的问题极大的制约了目前企业开发AI应用的生产力。
举个具体的例子。
我们将模型从训练 checkpoint 转换成可供部署的前向推理 ONNX 模型时,常常会用到 TensorRT 这个推理加速框架。然而,由于AI任务种类繁多,我们经常难以避免的对模型结构有所改动,用到一些不太常见的算子(op)后,就容易出现 TensorRT 算子不支持的问题,为此,我们又需要去写 plugin,做一系列改动和适配,非常拖累部署上线的进度。

就算没有遇到算子适配的问题,由于推理阶段往往对计算的实时性和并发度要求较高,企业为了节省部署资源,常常会降低模型精度——FP16量化甚至INT8量化等,然而在降低计算精度的过程中,又常常发现模型效果损失较多,可能又要回过头去加上一些技巧重训模型。
此外,由于AI模型常常需要处理敏感数据,因此在AI应用开发过程中也需要考虑数据隐私和安全问题。企业需要建立合理的数据保护机制,确保模型在训练和使用过程中不会泄露敏感信息。
总的来说,企业在AI应用开发中面临的挑战并不少,当下越来越迫切的需要一套工具链,来帮助企业更加高效、安全地构建和部署AI应用。这套工具链包括模型部署工具、模型管理平台、模型监控工具、数据隐私保护工具等等。这些工具可以帮助企业更好地管理和控制AI应用开发过程,确保AI应用的可用性和可靠性。
幸运的是,她来了。
NVIDIA AI Enterprise 3.0
前几天,NVIDIA重磅发布了AI Enterprise 3.0(简称NVAIE 3.0),一个堪称操作系统级的AI开发平台。

可以看到,这不是一个像TensorFlow、Pytorch那样的传统深度学习框架,而是一个致力于快速打造AI应用的一站式开发平台,包括了模型的训练、推理优化、部署、模型管理、云原生管理等AI应用开发上线的全流程,以往需要耗时数个月才能开发完成的AI应用,在NVAIE 3.0平台下,甚至可以做到数小时完成。
从图里我们可以看到平台在 4 个层级的关键特性:
囊括了上层工作流、框架和预训练模型: 在应用场景的level上,定义清晰的输入输出,并预置预训练模型,快速完成典型应用场景的AI应用开发
同时支持模型开发和部署: 应用开发的工具闭环,完成机器学习模型从开发到部署的完整生命周期,包括低代码迁移学习工具TAO、主流深度学习框架TF/Pytorch、推理加速TensorRT框架、推理服务引擎等
云原生的架构,支持混合云部署: GPU、DPU在k8s内的集成,MLOps工具等
大量的基础设施优化: 包括GPU虚拟化、基于RDMA的存储访问加速、底层CUDA优化等
下面就展开前两层,看看NVAIE是如何解决AI应用开发中的痛点的。
比如,我们前面提到过,当我们训练得到了一个不错的模型checkpoint后,需要通过TensorRT转换为可供部署的ONNX模型,这时常常遭遇算子缺失的问题。而在NVAIE 3.0平台下,你训练得到的模型则会在平台第二层中的TAO组件的能力加持下,轻松完成到ONNX模型的转换,无需再担心算子缺失、定制化开发的问题。
再比如,我们前面提过的模型量化的痛点,同样在NVAIE的第二层得到了解决——通过第二层的TAO组件可以直接得到的已经量化完成的INT8模型,无需再操心量化流程繁琐和量化精度损失的问题了。
而像一些典型的AI应用场景——比如智能客服,则在平台的最上层预置了应用开发的工作流(workflow):
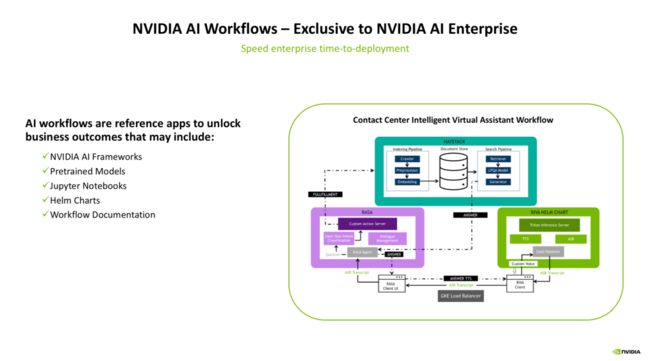
以上图中的智能虚拟助手的workflow为例,我们来看一个典型的workflow是怎么工作的。
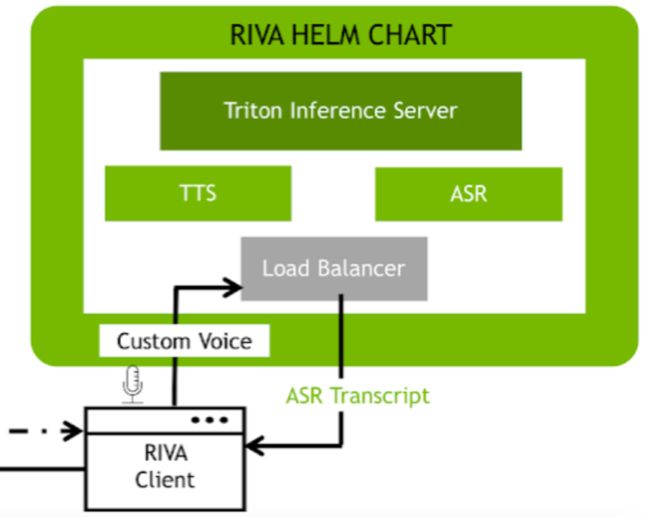 ▲RIVA工作流
▲RIVA工作流
最右下角是一个基于RIVA的工作流,在这里面会完成语音转文字(ASR)、文字转语音(TTS)的操作,来作为智能虚拟助手的“输入预处理”和“输出预处理”操作。而后,经过RIVA得到的用户输入,会被输入到左边的RASA工作流。
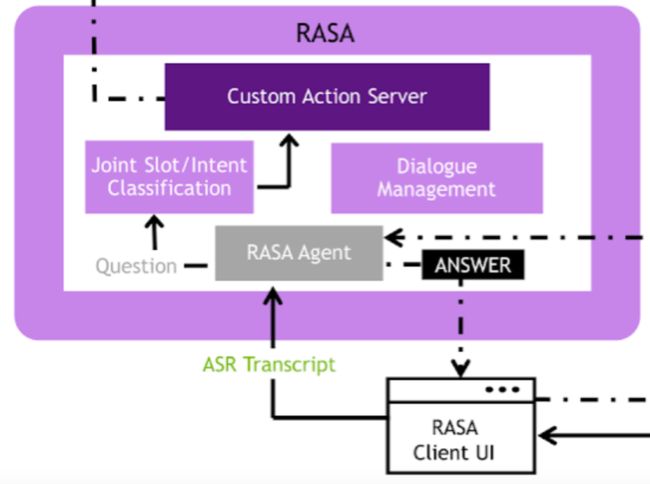 ▲RASA工作流
▲RASA工作流
RASA是一个开源的对话机器人框架,在这里,转成文本的用户语音输入会经过基础的NLU模块,进行分词、意图理解、槽位填充等操作,来得到一个结构化的语义理解结果,该结果会被输入到内部的对话管理(DM)模块来进行对话状态的追踪和管理。得到了语义理解的结果,便会将该结果丢给图中最上面的HEYSTACK工作流,来通过答案检索的方式,得到一个适合回答用户的候选回复,该回复最终会传入回RIVA工作流,通过TTS模块生成语音回复。
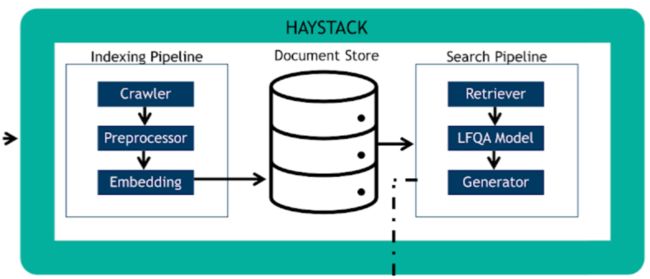 ▲HEYSTACK工作流
▲HEYSTACK工作流
如此,一个复杂的智能虚拟助手的运转全流程便完成了。如果从头要搭建这么一套复杂系统,常常要耗费数个月的时间,而基于NVAIE平台已经定义好的工作流,甚至可以实现小时级的全流程打通,可以说极大的解放了AI应用开发的生产力。
除此之外,平台还内置了语音转录工作流、数字安全防护认证工作流等,并且平台正在持续不断为更多的应用场景设计workflows, 未来可能会有基于地图的workflow、基于OCR的workflow等,非常值得期待!
值得注意的是,平台为了加快AI应用开发效率,并提升最终的AI应用效果,还内置了大量的预训练模型(比如效果先进的行人检测模型PeopleNet),且这些预训练模型都是未加密、完全开放权重的,用户完全可以拿来进行AI模型的“热启动”,并且标注场景化的数据进行模型权重的微调。
而这些预训练模型,覆盖的应用场景也是非常广泛。仅仅是车的识别方面,就内置了诸如车辆识别、车牌识别、车型识别等多种模型。有了预训练模型的加持,AI应用的开发进度便可以得到极大的提速,感兴趣的小伙伴可以在NVIDIA的 NGC目录 中查询可用的预训练模型:

NGC目录传送门如下:
https://catalog.ngc.nvidia.com/
除了以上模型层面的优化外,NVAIE 3.0还对AI服务的并发、可靠性、GPU利用率等进行了大量的优化,而这些问题对企业开发人员来说是非常耗时、头疼的事情。可以说,NVAIE平台实现了操作系统级别的开发套件封装,使得企业用户能够得到AI应用开发完整生命周期的效率、效果和安全性保障。
更不必说,作为全球领先的GPU制造商,NVIDIA在GPU层面是具备硬核的“Know How”能力的,这一点使得NVAIE平台可以实现真正的闭环优化,这对于应用的高效率开发是十分重要的保障。
在云原生方面,NVAIE 3.0对混合云部署的支持,则能够满足企业不同的部署需求。这里面还提供了优秀的服务支持,包括三年的Long term support,让企业在使用NVAIE 3.0的过程中感受到更多的便捷和安全。
总的来说,NVIDIA的NVAIE 3.0是一款非常优秀的AI开发平台,它的出现为企业的AI应用开发带来了一次“效率革命”。我们期待着NVAIE 3.0能够在未来的发展中帮助更多的企业实现AI的梦想。
点击阅读原文,申请试用,给AI正式投入生产的机会吧~
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群