第3章 SVM算法介绍
本文主要介绍SVM算法的过程:
目录
1.SVM算法
1.1 SVM
1.2 最大边际的超平面和向量点
1.3公式建立过程
1.4线性不可分(linear inseparable)
1.5核方法
2 SVM算法的简单运用
1.SVM算法
1.1 SVM
SVM(Support Vector Machine)又称为支持向量机,最初是一种二分类的模型,后来修改之后也是可以用于多类别问题的分类。支持向量机可以分为线性核非线性两大类。其主要思想为找到空间中的一个更够将所有数据样本划开的超平面,并且使得本本集中所有数据到这个超平面的距离最短。
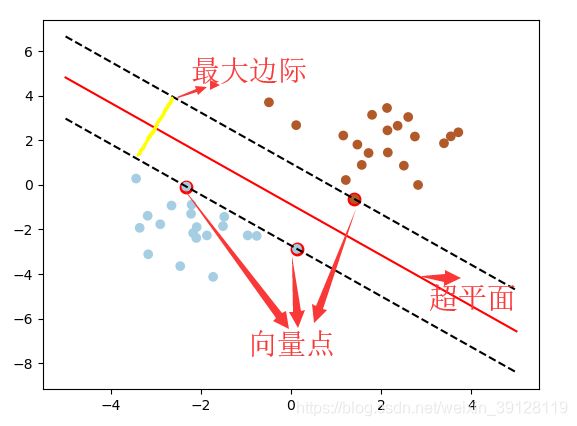
1.2 最大边际的超平面和向量点
我们都知道空间中,有无数个可能的超平面去区分两个点。那么如何选取使边际最大的超平面呢?超平面到一侧最近点的距离等于到另一侧最近点的距离,并且两侧的两个超平面平行,其中这些点就是向量点。如下图所示:
超平面定义为:![]() 。
。
W是权重向量,![]() 。
。
X是训练实例。
b是偏置。
1.3公式建立过程
对n维空间中的点![]() ,到超平面的距离为:
,到超平面的距离为:
![]()
其中||W||为超平面的范数,常数b类似于直线方程中的截距。
假设2维特征向量:X = (x1, X2),则超平面方程变为: ![]() 。由于b是偏置,方便数学运算令b=w0。
。由于b是偏置,方便数学运算令b=w0。
那么,所有超平面右上方的点都满足:![]() ;
;
所有超平面左下方的点都满足:![]() 。
。
调整weight,使超平面定义边际的两边:
H1:![]()
H2:![]()
综合以上两个等式得到:![]() ,其中y为数据点的标签,于是推广到
,其中y为数据点的标签,于是推广到![]() ,公式就满足:y(W*X+b)
,公式就满足:y(W*X+b) 1。
1。
调整w和b,使得对任意一点到超平面的边际最大。目标函数优化为:
![]()
而min(y(W*X+b))=1,故目标函数为:1/||W|| ,对于矩阵等同于,min1/2*|W||^2。
这是一个有约束条件的优化问题,通常我们可以用拉格朗日乘子法来求解,应用拉格朗日乘子法如下:
令 ,
,
求L关于求偏导数得:

带入化简得到:

原问题的对偶问题为:

该对偶问题的KKT条件为:

到此,似乎问题就能够完美地解决了。但是这里有个假设:数据必须是百分之百可分的。但是实际状况中训练集的数据是不可分的,那怎么处理呢?且看下文介绍。
1.4线性不可分(linear inseparable)
如下所示,数据集是线性不可分的情形。
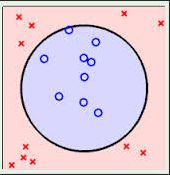
主要两个步骤来解决:
1、利用一个非线性的映射把原数据集中的向量点转化到一个更高维度的空间中;
2、在这个高维度的空间中找一个线性的超平面来根据线性可分的情况处理。
如何把原始数据转化到高维的空间?
例如将3维向量X = (x1,x2,x3)映射到6维空间中为,![]()
新的决策超平面:d = WX+b,根据这个超平面是线性的解出W和b之后,并且带入回原方程计算d。
1.5核方法
在线性SVM中转化为最优化问题时求解的公式计算都是以内积的形式出现的,因为内积的算法复杂度非常大,所以我们利用核函数来取代计算非线性映射函数的内积。
常用的核函数有:
- h度多项式核函数(polynomial kernel of degree h):

- 高斯径向基核函数(Gaussian radial basis function kernel):
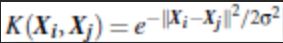
- S型核函数(Sigmoid function kernel):

根据先验知识,比如图像分类,通常使用RBF,文字不使用RBF。尝试不同的kernel,根据结果准确度而定。
例如:
假设定义两个向量: x = (x1, x2, x3); y = (y1, y2, y3)。定义方程:f(x) = (x1x1, x1x2, x1x3, x2x1, x2x2, x2x3, x3x1, x3x2, x3x3) ,K(x, y ) = (
f(x) = (1, 2, 3, 2, 4, 6, 3, 6, 9), f(y) = (16, 20, 24, 20, 25, 36, 24, 30, 36)
K(x, y) = (4 + 10 + 18 ) ^2 = 32^2 = 1024
同样的结果,使用核方法计算容易很多。
2 SVM算法的简单运用
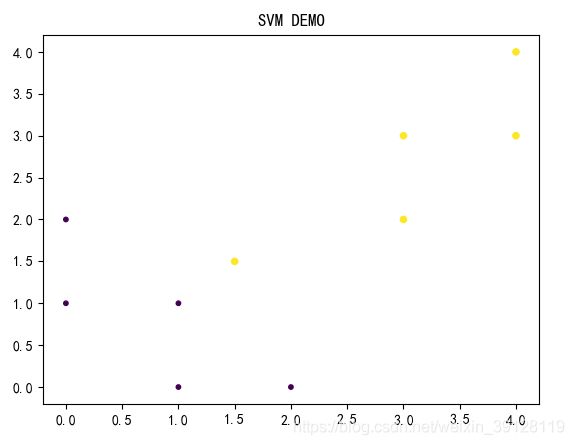
如下代码:
from sklearn import svm
import numpy as np
import matplotlib.pyplot as plt
def plot_figure(data_mat, labels):
fig = plt.figure()
ax = fig.add_subplot(111)
l = []
for label in labels:
if label ==0:
l.append(1)
elif label ==1:
l.append(2)
else:print('ERR:',label)
labels = l
t = ax.scatter(data_mat[:,1],data_mat[:,0],10 * np.array(labels),np.array(labels), marker='o')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.title('SVM DEMO')
plt.show()
x = [[2, 0], [1, 1], [1.5,1.5],[2, 3],[3,3],[4,4],[3,4],[0,2],[0,1],[1,0]]
x = np.array(x)
y = [0, 0 ,1,1,1,1,1,0,0,0]
clf = svm.SVC(kernel = 'linear')
clf.fit(x, y)
#show SVM
print (clf)
# get support vectors
print (clf.support_vectors_)
# get indices of support vectors
print (clf.support_)
# get number of support vectors for each class
print (clf.n_support_)
# visiable SVM
plot_figure(x,y)
# SVM predict
test = np.array([[1,2],])
test_y = clf.predict(test)
y_pred_train = clf.predict(x)
y_score_train = clf.decision_function(x)
y_score_cv = clf.decision_function(test)
print(test_y)
print(y_pred_train)
print(y_score_train)
print(y_score_cv)