Twibot-22数据集介绍
目录
1 数据收集过程介绍
用户网络收集第一阶段:
数据集收集第二阶段:
数据集收集时间:
数据集标注策略:
Twibot22与Twibot20注释质量对比
数据集局限性介绍
2 数据集中文件
node.json or {tweet, user, list, hashtag}.json
twibot22元数据信息介绍
twibot22实体之间的关系类型:
twibot22详细的统计数据
split.csv
label.csv
edge.csv
3 数据集泛化能力研究
1 数据收集过程介绍
数据集官方网站:
TwiBot-22: Towards Graph-Based Twitter Bot Detection
数据集获取链接:
https://drive.google.com/drive/folders/1YwiOUwtl8pCd2GD97Q_WEzwEUtSPoxFs?usp=sharing
数据集文档:
GitHub - LuoUndergradXJTU/TwiBot-22: Offical repository of TwiBot-22 @ NeurIPS 2022, Datasets and Benchmarks Track.
用户网络收集第一阶段:
(1)采用@NeurIPSConf 作为起始用户;
(2)使用 Twitter API 检索 1,000 个关注者和 1,000 个关注者作为 BFS 扩展的用户社区;
(3)采样策略:
分布多样性:给定用户元数据(例如关注者数量),不同类型的用户会以不同的方式进入元数据分布;分布多样性旨在对分布的顶部、中间和底部的用户进行抽样。对于数值类元数据,在用户的邻居及其元数据值中,选择具有最高值的 k 个用户,具有最低值的 k 个用户,并从其余用户中随机选择 k 个。对于真或假元数据,选择 k 为真,k 为假;
数值多样性:给定一个用户及其元数据,采用值多样性,以便更可能包括具有显著不同元数据值的邻居,确保收集到的用户的多样性。对于数值元数据,在扩展用户 u 的邻居 X 及其元数据值 ![]() 中,用户 x ∈X 被采样的概率表示为
中,用户 x ∈X 被采样的概率表示为 ![]() 。对于真或假元数据,从相反的类别中选择 k 个用户。
。对于真或假元数据,从相反的类别中选择 k 个用户。
(4)扩展数据:随机采用两种采样策略(分布多样性或价值多样性)中的一种,并从下表中随机选择一个元数据,将其邻域的 6 个用户包含到 TwiBot-22 数据集中;

(5)然后在 TwiBot-22 中随机选择一个未扩展的用户进行新一轮的邻域扩展;
数据集收集第二阶段:
(1)首先,为用户网络中的用户收集1000条推文(1000个关注和1000个关注者),并为从用户网络中扩大的用户收集200条推文(第一阶段扩散出的用户);
(2)在 TwiBot-22 中收集每个用户的置顶推文和最近 100 条喜欢的推文。对于收集的每条推文,收集它转发、引用或回复的推文以及它提及的用户;
(3)收集用户最近的 100 个列表,其中包含最新的 100 个成员、关注者和推文;
(4)收集列表推文中的所有主题标签,并使用 Twitter API 搜索与话题相关的更多推文。最后,确保收集每条推文的创建者,以及收集这些用户的 40 条推文;
数据集收集时间:
(1)第一阶段用户网络采集时间为2022年1月20日至2月1日;
(2)第二阶段异构图构建时间为2022年2月1日至2022年3月15日。
数据集标注策略:
(1)选择西交大LBD研究小组中的 17 位研究人员,他们是活跃的 Twitter 用户,熟悉机器人检测文献,并使用 TwiBot-20 数据集进行了实验;
(2)然后,将 TwiBot-22 中的每个 Twitter 用户分配给 5 位不同的专家,并要求他们评估用户是人类、机器人还是不确定;
(3)使用多数投票来获得这 1000 名用户的专家注释,然后利用这些注释来指导弱监督学习过程;
Twibot22与Twibot20注释质量对比
(1)要求 6 位研究人员参与专家研究:他们熟悉 Twitter 机器人检测研究,并且他们中的大多数人之前都曾就此主题发表过文章;
(2)具体来说,分别从 TwiBot-20 和 TwiBot-22 中随机选择 500 个用户,并将每个用户分配给 3 位专家;
(3)然后,要求他们将每个用户评估为“肯定是机器人”、“可能是机器人”、“不确定”、“可能是人类”和“肯定是人类”。根据他们的评估,计算专家意见和数据集标签之间的准确性和 F1 分数,还报告了 Randolph 的 Kappa 系数;

数据集局限性介绍
TwiBot-22 的一个小限制是作者没有在 TwiBot-22 中下载和存储用户媒体(图像和视频),而这些多媒体内容可能对机器人检测有用;
如果研究人员确实认为多媒体内容对于 bot 检测是必要的,他们可以自己下载 TwiBot-22 中的媒体链接。
2 数据集中文件
每个数据集包含 node.json、label.csv、split.csv 和 edge.csv(用于具有图结构的数据集);
node.json or {tweet, user, list, hashtag}.json
twibot22元数据信息介绍
此文件包含 twitter 用户信息(用于非图数据集)或实体(包括tweet, user, list, hashtag等)
TwiBot-22 是迄今为止最大、最全面的 Twitter 机器人检测基准。具体来说,TwiBot-20 旨在解决以前数据集中有限的数据集规模、不完整的图形结构和低注释质量的挑战。
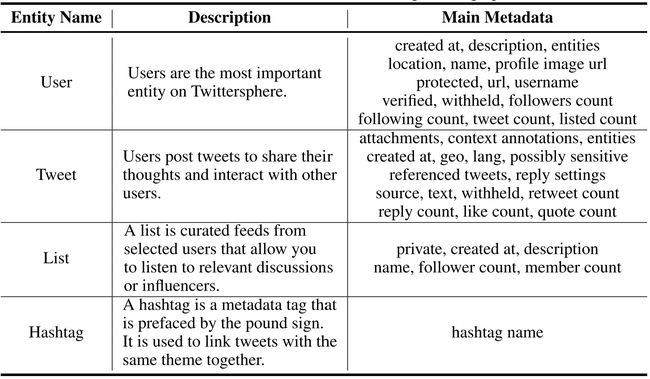
TwiBot-22 在 Twitter 社交网络上收集四种类型的实体:用户、推文、列表和主题标签。这些实体的详细信息如下表所示;
User: 用户元数据信息;
推文:用户发表的推文;
列表:列表是来自选定帐户的精选供稿,可以看到列表用户参与的讨论和发布的推文,最多加入1000个(也可以查看其他用户的列表);
主题:用户关注的话题标签;
list.json数据集展示:
tweet.json数据集展示:

hashtag.json数据集展示:

user.json数据集展示:

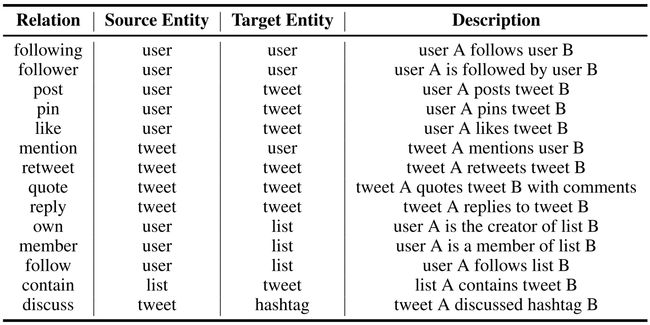
twibot22实体之间的关系类型:
关注;关注者;发布(用户发布推文); 置顶(用户置顶推文) ;点赞;提及;转发;引用;回复;拥有(用户创建列表);成员(列表包含列表用户);包含(列表包含的tweet);讨论(推文带了哪些话题);
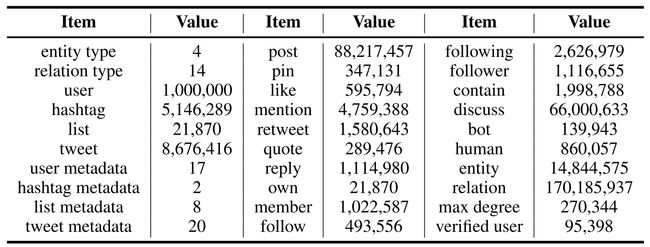
twibot22详细的统计数据
数据基本情况统计:实体类型;关系类型;用户数量;话题数量;列表数量(有的用户是没有设置列表的);发布推文的数量;机器人账户数量;人类账户数量;实体的数量;关系的数量;节点的最大度;经过认证的账户;
收集的数据集情况统计:话题元数据(话题id,话题,上图有展示);列表元数据(上图有展示);推文元数据(上图有展示);
用户与推文之间的互动: 用户总共发布推文的数量;多少用户置顶了推文;用户与推文间点赞互动数量;推文提及用户的数量;
推文之间的互动:推文之间相互转发的数量(不同用户发布的推文有不同的id,所以转发涉及的是推文与推文之间的);一条推文引用一条推文;推文与推文之间的回复;
用户与列表之间的互动:用户创建的列表数量;用户是列表的成员;用户关注了某列表;
用户与用户之间的互动:用户是用户的关注者总数量;用户关注了某用户总数量;
列表与推文的互动:列表包含的推文数量;
推文与话题的互动:推文讨论了某个话题;
转发推文形式展示:
引用推文形式展示:
推文与推文之间回复展示:
split.csv
该文件包含数据拆分信息,其中第一列(id)为用户id,第二列(split)为对应的拆分(train、valid或test);
label.csv
该文件包含基本事实标签,其中第一列 (id) 是用户 ID,第二列 (label) 是相应的标签(人类或机器人);
edge.csv
该文件包含出现在 node.json 中的实体关系。每个条目都包含 source_id、target_id 和关系类型;
3 数据集泛化能力研究
为了评估现有方法及其对看不见的数据进行泛化的能力,作者在 TwiBot-22 网络中确定了 10 个子社区,并在进行了实验,实验结果如下图所示。

(在fold i 上训练模型并在fold j 上进行测试。展示模型准确性并报告每个热图的平均值(avg),作为泛化能力的总体指标)
子数据集:
(1)具体来说,首先围绕@BarackObama、@elonmusk、 @CNN、@NeurIPSConf 和 @ladygaga;
(2)这五个用户具有不同的兴趣领域,他们的邻居代表了 Twitter 网络的不同领域方面;
(3)使用 K-means 对话题的 word2vec 表示进行聚类,并将发布类似标签的用户识别到 5 个子社区中。
(4)这些子社区中这些话题标签的示例见下表;

(5)下表列出了10个子社区的统计数据;
