如何科学地进行A_B实验
前言
本文日常在A/B实验方面工作实践与理论学习的心得,主要旨在面向产品业务同学介绍如何科学的进行A/B实验以及实践过程中常见的一些A/B实验的误区,希望可以帮助到同学更好更深入的了解A/B实验,本文不足之处,望读者多多指正
1.A/B实验作用
在实际业务中,衡量一个优化/改进动作对产品/功能的价值的最常见的方式就是对比-用未做改进的A版本的数据效果VS做过改进的B版本的数据效果,进而判断该动作对产品是否有效,上述动作,便是我们工作常用的ab实验一般流程。A/B实验通过对比思想,分析不同差异对产品用户的影响,是帮助业务对产品实现快速优化改进的工具。
2.A/B实验流程
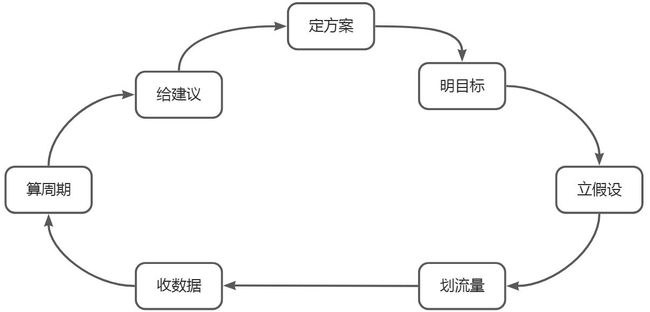
(1)定方案
即业务与分析同学一起确认产品/功能优化的点是什么,如:优化UI、改进算法优化排序、优化内容吸引用户……后再确认相应的开发同学进行优化版本的实现。
(2)明目标
即明确优化方案可以使得那些指标有所提升,并用与评价实验是否通过,需要做到:
-
根据自身业务明确一个最终用户评价实验方案成功与否的关键指标(如优化结果页内容方案的一般选用户在改结果页的停留时长或结果页用户的机器人留存率作为关键指标,而用户的平均问句数、结果页日活等则作为跟踪指标)
-
明确关键指标的可以在原有基础上的预期提升值,用于接下来对样本量的评估(继续以上述结果页实验为例,优化结果页内容方案预期可以原理的用户留存30%的基础上提升2%将用户留存提升至32%)
(3)提假设
即提出假设,用于后续的实验的假设检验分析,假设一般根据自身业务优化点与优化的关键指标利用反证思想建立假设,如:业务同学与分析同学发现基于经验认为用户对推荐内容为标题+文首句话的排版样式的点击意愿更高,于是以该改进版本进行A/B实验,关键指标为推荐内容的曝光点击率,假设为:推荐内容为标题+文首句话的排版样式与老版的样式相比点击率不会提高(反证)【不妨ab实验理解一个保守的把关员,其思想是尽可能不让实验效果不好的实验方案通过,故通过反证的方式,进行验证,即实验组必须推翻原有的假设才能通过】
(4)分流量
即分配好流量到对应的A B版本中进行实验,划分流量的过程中一般业务/分析同学一般要做到:
-
各组分到的流量具有有一致性,即等比例分配

-
各组分到的流量保持同质性,即各组样本与目标用户群特征相似
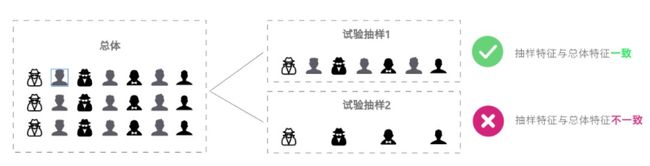
如反例:验证主动进入的新手期用户推荐内容为A时 转化成熟期用户比例是否会变高,实验组的推荐用户为主动进入的新手期用户,而对照组的推荐用户却为主动进入的成长期用户) -
各组分到的流量尽可能做到互不影响
如xx商品发放5元优惠劵对提升用户下单率效果最佳的实验中,处在实验组的用户A领完优惠劵后对商品进行下单将改优惠信息分享给处于的对照组(不发优惠劵)好友用户B,于是好友通过询问客服的方式也获取该优惠劵,进而也完成下单,造成实验测算的偏差)
- 用于实验的样本量符合实验要求
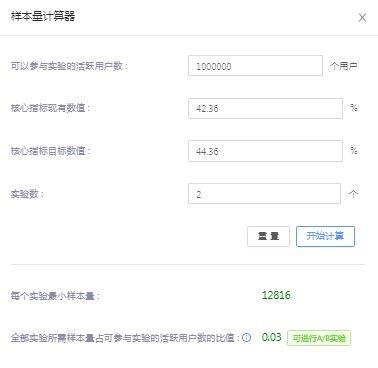
如改进标题后内容曝光点击率预计提升2%,原基础点击率为42.36%,则在95%的置信度、80%的功效下每一组所需的最小样本量为12816)【影响实验统计功效、显著性水平因素包括实验参与的样本量与实验组指标与对照组的指标差值】
(5)排周期
即计划完成实验所需的放量时长,需要考虑:
- 实验的新奇效应:新上线的功能往往由于用户的新奇效应其点击率会在开始的一段时间比老功能的高,可以延长实验的测试周期消除实验中的新奇效应
- 让参与实验的样本量符合实验要求:如改进标题提升曝光点击率的实验需要9W样本用户参与实验,而该文章的日活为9W,周活为50W,为了让参与实验的样本量符合实验要求,实验周期最好排一周以上
(6)收数据
即实验放量后进行的数据回收,一般将日志数据回收至数仓,由数仓同学完成,用于下一步进行数据统计与分析
(7)给建议
即根据回收数据进行计算实验的显著水平,判断接受原假设还是拒绝原假设(评价实验是否通过)这一步一般有数分同学获平台自动化统计完成。
3.A/B实验在实践中常见的误区
(1)主观解读-统计功效不具有说服力
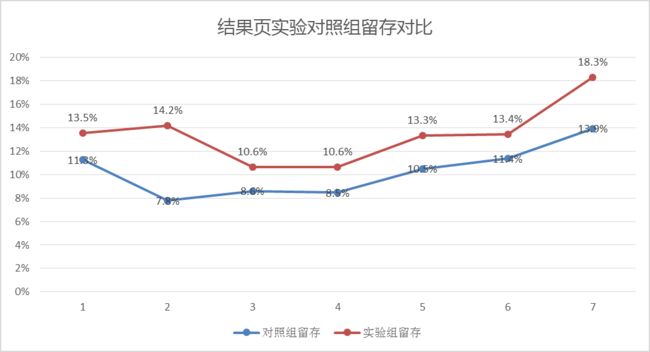
A/B实验中主观解读主要体验在:当实验的评价指标相较对照组高出很多,假设检验判断该实验不通过,而业务主观认为实验有效,将实验版本全量上线,如:在某次关于结果页内容的优化实验中,业务同学希望通过改进结果页内容以提升用户的结果页留存率,在实验期间,实验组留存率比对照组高出2%以上,于是业务认为实验可以通过,但实际上该实验在实验平台显示并未通过
事实上,不能直接得出这个结论,因为缺少了关键的步骤——假设检验。假设检验的目的之一是排除运气、抽样误差 等随机因素对于试验结果的误判,即通常所说的Ⅰ类错误;目的之二是 排除由于漏报对于试验结果的影响,即Ⅱ类错误。为了避免Ⅰ类错误、 Ⅱ类错误带来的误判和漏报,需要对试验结果进行严格的假设检验,类似于留存率、点击率等率值相关指标可以采用Z检验或卡方检验(非正态情况下),而人均时长、用户购买量等指标可以使用t检验。【相关的统计学原理本文暂不做详细讲解】
实际由于上述实验参与实验的样本数量较少,最终得到的结果如下表,并不能通过实验
| 对照组样本量 | 实验组样本量 | 对照组留存 | 实验组留存 | z检验值(大于1.960假设检验通过) |
|---|---|---|---|---|
| 320 | 340 | 11.3% | 13.5% | 0.9 |
| 231 | 226 | 7.8% | 14.2% | 2.2 |
| 221 | 226 | 8.6% | 10.6% | 0.7 |
| 248 | 301 | 8.5% | 10.6% | 0.9 |
| 238 | 278 | 10.5% | 13.3% | 1.0 |
| 255 | 253 | 11.4% | 13.4% | 0.7 |
| 300 | 300 | 13.9% | 18.3% | 1.4 |
(2)分流不均匀-辛普森悖论
辛普森悖论是指在某个条件下的两组数据,分别讨论时都会满足某 种性质,可是一旦合并考虑,却可能导致相反的结论。
在A/B实验中如果随意切割流量比例也会造成辛普森悖论,如:某个周五,微软试验人员为试验中的某版本分配了1%流量,到周六那天,又将流量增加到50%。
现象:该网站每天有100万个访客,虽然在周五和周六这两天,新版本的转化率都高于对照组,但是当汇总数据时,该版本的总体转化率反而降低了,具体数值下表所示。
分流不均对A/B实验的影响(数据来自数据分析之道)
| 周五 对照组流量:实验组流量=99:1 |
周六 对照组流量:实验组流量=1:1 |
总计 | |
|---|---|---|---|
| 对照组 | 20000/99000=2.02% | 5000/500000=1.00% | 25000/1490000=1.68% |
| 实验组 | 230/10000=2.30% | 6000/500000=1.20% | 6230/510000=1.20% |
(3)实验周期短-忽略用户的新奇效应
新奇效应也是A/B实验中常见的误区之一,思考以下两个问题。
- 试验所需的样本量决定了试验的时间长短,为了尽快得出结论是否可以分配较大流量使得试验尽快收集到所需样本量?
- 或者按照正常的流量分配,达到样本量之后立即停止试验?
答案是否定的,面对以上两种情况需要考虑是否因为新奇效应的存在给结果带来了一定的影响。在统计学上,新奇效应也称为均值回归,即随着试验次数的增加,结果往往趋近于均值。如图3所示,在A/B实验中,试验早期用户可能会因为新的改动而产生好奇,从而带来点击率 的提升,但是随着试验时间的增加,这个点击率会趋近于用户的真实点击水平。因此,数据分析师需要等到观测指标平稳之后才能停止试验,以避免新奇效应对于试验结果的影响。

(4)以偏概全(不同质)-幸存者偏差
在流量分配的时候需要保证对照组和试验组的用户具有同质性、均匀性和唯一性。换句话说就是需要将用户属性相近的用户分配到A组或B组中且同时进行实验。 当实验中未注意到这个点时,容易导致幸存者偏差问题。
如:业务同学为了提升语音助手用户粘性,上线教用户xxx,全量上线前,先圈选5%用户体验通过推荐曝光功能,观察数据发现,在推荐曝光后点击使用过“教用户xxx”功能的用户的次日留存为58%(未推荐的5%用户留存为40%),于是判定,该功能可以提升用户次日留存,于是全量上线该功能。而事实上,推荐曝光后点击使用过教用户xxx功能的用户本身就是一批较为较为活跃的用户(成熟期用户占比87%,而未推荐的5%用户成熟期用户占比仅为50%),正确的对比方式应为:将圈选的5%可以触发推荐“教用户xxx”功能的用户的留存于未推荐该功能的5%对照用户的留存进行对比。
因此,实验时间的选择应该格外注意,两组参与实验的样本各项属性是否无差异。
(5)实验不同时-混淆因果
另外,在流量分配的时候需要保证对照组和试验组的用户具有同时性,即需要将两组对照实验样本同时分配到A组或B组中进行试验,当实验中未注意到这个点时,容易导致问题之一就是混淆因果问题。
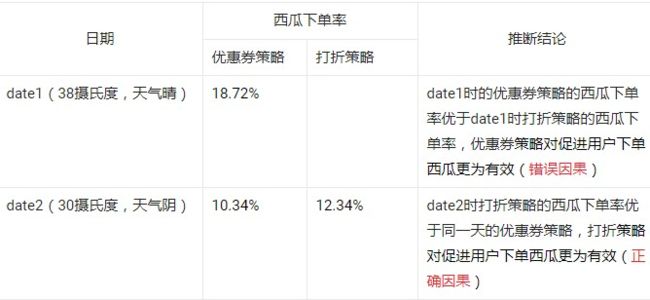
如:某超市有两中营销策略对西瓜进行促销,一中是优惠券策略:对用户发放2元的西瓜优惠券,另一种打折策略:直接对西瓜打8折促销,超市计划一天推行优惠券策略,一天推行打折策略,用超市用户的下单率对策略效果进行评估,得到:推行优惠券策略时的用户的西瓜下单率为18.72%,推行打折策略时的用户的西瓜下单率为12.34%,于是认定,优惠券策略对促进用户下单西瓜更为有效。
事实上,上述实验方式得出的结论并不是有效结论,不同时间维度下外界温度、天气等因素不同,从而影响用户的买瓜意愿,使得结论无效,实际的结果可能如下表:
参考资料
《关键迭代》
《数据分析之道》