Tensorflow嵌入式部署、联调、C++API深度学习前向推理
Tensorflow嵌入式部署、联调、C++API深度学习前向推理
- 前言
- 一、C++与python的混合编程
-
- 1、需要调用的python脚本
- 2、环境准备
- 3、混合编程
- 4、结果展示
- 二、嵌入式部署(目标检测)
-
- 1、模型准备
-
- ①、模型网络(目标检测)
- ②、将ckpt文件转成pb文件
- 2、CPU环境
-
- ①、环境配置
- ②、前向推理获取输出
-
- 1)、输入网络的数据准备
- 2)、前向推理代码运行逻辑
- ③、对输出进行解析_获取最终结果
- 3、GPU环境
-
- ①、环境配置
- ②、代码更改
前言
_____这篇博客可能有点长,涉及到的内容也比较多,只想了解其中一部分的朋友可以直接跳转,之所以写第一部分,是因为在使用C++对应的tensorflow-API之前,听说可以使用混合编程以实现tensorflow框架模型嵌入式部署,但是经过试验,每次将变量恢复到图中时,都会异常跳出,不管是pb文件还是ckpt文件,都会遇到这个问题,但是我觉得这种混合编程的方式可能适合某些场景(因为python脚本中如果不含tensorflow代码时,是可以实现混合编程输出结果的),所以分享出来,希望能帮助大家。
一、C++与python的混合编程
本次使用Visual Studio2013版本,python3.6.5版本,win7和win10都是64位操作系统。
1、需要调用的python脚本
本次C++调用python脚本主要展示在脚本的主程序包含另一个函数,且该函数在自定义包里,而自定义包又含有python的第三方库,待执行脚本名称为Custom_package.py,代码如下:
import function_library as fl
def test_array(a,b):
print("进入python主程序,开始执行相应操作!")
print("接受到的实参a={},b={}".format(a,b))
print("="*30)
return fl.funx2(a,b)+b
自定义包在待执行脚本同一级文件夹里,名称为function_library.py,代码如下:
import numpy as np
def funx2(a,b):
print("进入python子函数程序,开始执行!")
initial_data = np.random.randint(1,9,size=(2,3))
print("生成的numpy数组是:")
print(initial_data)
result_data = initial_data * a + b
print("initial * a + b 的结果是:")
print(result_data)
print("执行numpy操作完成,返回结果!")
return a*2
2、环境准备
新建文件夹,命名为C++_python,将python环境中的include文件夹和libs文件夹复制到该文件夹下(就是配置pycharm时,选择python.exe文件所在的同一层文件夹里有这两个文件夹),将libs文件夹里的python36.lib文件拷贝一份,并重命名为python36_d.lib;打开Visual Studio:
文件>新建>项目>Visual C++>Win32控制台应用程序>名称(改为:cpythonimport)>位置(选择刚才新建的文件夹C++_python)>确定>完成
设置环境:
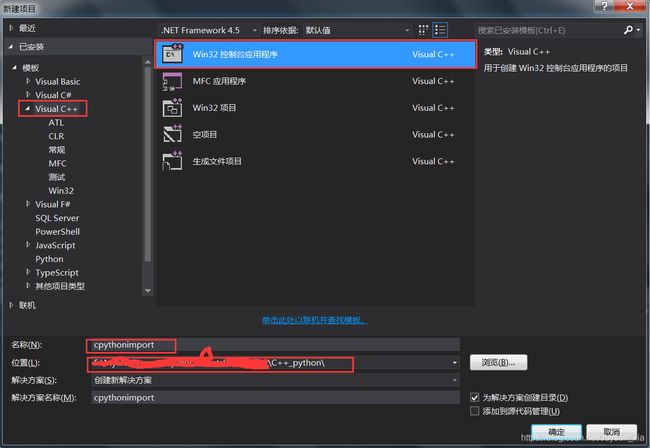
项目>cpythonimport属性>配置管理器(右上角)>活动解决方案配置(修改成Release)>活动解决方案平台(修改成X64,没有就点击新建)>关闭
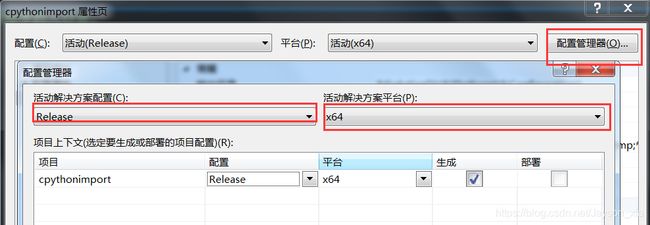
项目>cpythonimport属性>配置属性>VC++ 目录>包含目录(修改成相对路径,选择C++_python文件夹下的include文件夹)>应用目录(修改成相对路径,选择C++_python文件夹下的include文件夹)>库目录(修改成相对路径,选择C++_python文件夹下的libs文件夹)
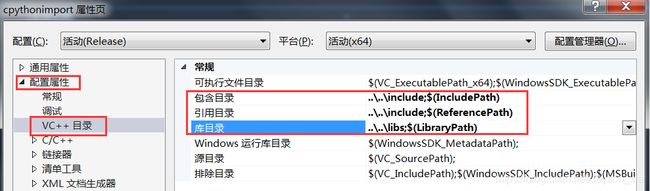
配置属性>链接器>输入>附加依赖项(将python36_d.lib添加到该项里)

最后点击 应用> 确定 完成配置,复制混合编程中所示代码,编译,将Custom_package.py和function_library.py文件放到C++_python> cpythonimport>x64>Release文件夹下即可
3、混合编程
调用python脚本的C++代码如下:
// cpythonimport.cpp : 定义控制台应用程序的入口点。
//如果不使用预编译头,在 项目>属性>配置属性>C/C++>预编译头>预编译头>不使用预编译头 即可,这个设置在该用例中无碍。
#include "stdafx.h"
#include <Python.h>
//把char *c转 wchar_t * ,因Py_SetPythonHome()函数的形参为wchar_t 类型,也可以直接使用L进行转换
//wchar_t *GetWCHAR(const char *c)
//{
// const size_t cSize = strlen(c) + 1;
// wchar_t* WCHAR = new wchar_t[cSize];
// mbstowcs(WCHAR, c, cSize);
// return WCHAR;
//}
int main()
{
/*Py_SetPythonHome()设置python脚本运行的依赖环境,防止python脚本调用第三方包时出错;如果不设置,在不调用第三方包时,不会报错;
一旦调用第三方包,则会出现异常,该路径为python的安装路径(有python.exe的那个文件夹的路径,且需使用绝对路径);
即相应包都下载在该路径下。*/
Py_SetPythonHome(L"D:\\ArtificialIntelligence\\Anaconda");
Py_Initialize();//初始化相应python的依赖环境
//设定参数值
int a = 2;
int b = 3;
PyObject *pModule;//定义PyObject对象
PyObject *pFunction;
PyObject *pArgs;
PyObject *pRetValue;
//导入python脚本(自定义的python待执行脚本的文件名)
pModule = PyImport_ImportModule("Custom_package");
if (!pModule) {
printf("import python failed!!\n");
return -1;
}
//获取对应Custom_package.py中的def test_array(a,b)主程序(需要执行的函数)
pFunction = PyObject_GetAttrString(pModule, "test_array");
if (!pFunction) {
printf("get python function failed!!!\n");
return -1;
}
//申明python中的tuple对象
pArgs = PyTuple_New(2);
//将a,b放到元祖中,索引为0的值为a,索引为1的值为b
PyTuple_SetItem(pArgs, 0, Py_BuildValue("i", a));
PyTuple_SetItem(pArgs, 1, Py_BuildValue("i", b));
//调用获取的函数并传参
pRetValue = PyObject_CallObject(pFunction, pArgs);
//python3中只有long,PyLong_AsLong(python2中是PyInt_AsLong),注意返回值的类型,接受的函数类型和返回的数据类型需要一致
printf("==============================\n");
printf("python脚本调用完毕,输出返回结果!\n");
printf("%d + %d = %ld\n", a, b, PyLong_AsLong(pRetValue));
/*CPython垃圾收集器使用“引用计数”,即它维护对象的引用列表。如果对象的引用计数降至零,则表示垃圾收集器释放该对象的空间是安全的。
因此,当定义PyObjects类时,必须显式调用Py_INCREF和Py_DECREF,分别增加和减少对象的引用计数。*/
Py_DECREF(pModule);//减少对象的引用计数
Py_DECREF(pFunction);
Py_DECREF(pArgs);
Py_DECREF(pRetValue);
if (!pModule) {
printf("import python failed!!\n");
return -1;
}
//如果是多次导入PyImport_ImportModule模块
//只有最后一步才调用Py_Finalize(),此时python全局变量一直保存着
Py_Finalize();
system("pause");
return 0;
}
4、结果展示
运行结果如下(如果运行显示无法访问.....exe,关闭360,或者添加信任即可):

二、嵌入式部署(目标检测)
1、模型准备
①、模型网络(目标检测)
模型为YOLOv3改得,但是输入和输出名称没有变,所以仍然可以用yolov3的模型。
②、将ckpt文件转成pb文件
将ckpt文件转换成pb文件需要提前知道网络的input_name和output_name,和自己骨干网络有关。 Tensor("input/input_data:0", shape=(?, 256, 256, 3), dtype=float32) Tensor("pred_sbbox/concat_2:0", shape=(?, ?, ?, 3, 8), dtype=float32) Tensor("pred_mbbox/concat_2:0", shape=(?, ?, ?, 3, 8), dtype=float32) Tensor("pred_lbbox/concat_2:0", shape=(?, ?, ?, 3, 8), dtype=float32) 具体代码如下:
import tensorflow as tf
from core.yolov3 import YOLOV3
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
os.environ["CUDA_VISIBLE_DEVICES"] = '-1'
ckpt_file = "./checkpoint/Abrasions_test_loss=9.5520train_loss=3.4781.ckpt-1900"#自己的ckpt文件
pb_file = "./voc.pb"#要保存的pb文件名称和路径
output_node_names = ["input/input_data", "pred_sbbox/concat_2", "pred_mbbox/concat_2", "pred_lbbox/concat_2"]#模型的输入和输出的名称
with tf.name_scope('input'):
input_data = tf.placeholder(dtype=tf.float32, shape=[None, 256, 256, 3], name='input_data')#定义输入
model = YOLOV3(input_data, trainable=False)#通过实例化代码构建模型图,训练时也是需要实例化改骨干网络
print(input_data)#打印输入的tensor信息
print(model.pred_sbbox, model.pred_mbbox, model.pred_lbbox)#打印输出的tensor信息
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True))#构建会话
saver = tf.train.Saver()
saver.restore(sess, ckpt_file)#构建恢复模型
converted_graph_def = tf.graph_util.convert_variables_to_constants(sess,
input_graph_def=sess.graph.as_graph_def(),
output_node_names=output_node_names)#会话和output_node_names传入到转换函数里面去(函数的意思是将变量转换成常量,pb文件中的值是常量,已经不再是变量)
with tf.gfile.GFile(pb_file, "wb") as f:#将得到的converted_graph_def(得到的图)写入到指定路径
f.write(converted_graph_def.SerializeToString())#将图写入磁盘,并序列化成字符串
print('成功输出模型')
2、CPU环境
本次使用的各平台版本为:Visual Studio2015、python3.6.5,tensorflow为1.8.0(编译的指令集为sse,基于cmake编译,对应VS为2015)win7和win10都是64位操作系统,具体编译操作先略过。
①、环境配置
1、 准备好tensorflow的c++环境文件,看cpu指令集是sse还是avx2的,不知道就用sse指令集
2、打开vs2015新建工程:

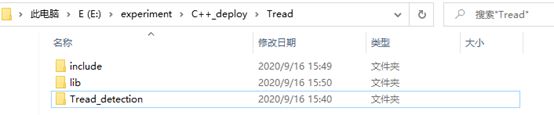
3、将tensorflow的C++环境包解压,将解压后将该文件夹下的include和lib文件夹复制到Tread_detection文件夹的同一层:
4、将opencv的lib文件复制到新建的lib文件夹下,lib文件夹下的lib压缩包有如下:

5、将opencv的头文件拷贝到include文件夹下:
6、将对应的opencv的.dll和tensorflow的.dll文件放到程序执行的环境中,这里是如下路径:如果没有x64,编译一遍就会出现:
opencv_core2410.dll
opencv_highgui2410.dll
opencv_imgproc2410.dll
tensorflow.dll
7、 配置环境(配置opencv、tensorflow环境的include、lib,如果使用相对路径,文件的起始路径为exe或者是dll文件所在的文件夹(就是主程序所在的文件夹),将模式改成 Release > x64,看个人电脑情况修改,修改方式和可见开始得环境配置



建议设置成相对路径,以便于项目移植,设置的地方如下:
…\include;KaTeX parse error: Can't use function '\.' in math mode at position 17: …IncludePath) ..\̲.̲.\lib;(ReferencePath)
…\lib;$(LibraryPath)

8、 将下列预定义复制到C/C++ > 预处理器 > 预处理器定义里:
NDEBUG
_WINDOWS
COMPILER_MSVC
NOMINMAX
PLATFORM_WINDOWS
_CRT_SECURE_NO_WARNINGS

9、将lib文件夹的相关.lib格式的压缩包文件添加到连接器>输入>附加依赖项里:
opencv_core2410.lib
opencv_highgui2410.lib
opencv_imgproc2410.lib
tensorflow.lib
tensorflow_static.lib

②、前向推理获取输出
1)、输入网络的数据准备
之前在部署时,无法得到正确的结果,经过Debug,发现在喂入网络前的数据处理上出现了问题,所以这里单独拿出来分享下:
void cvMat2tfTensor(cv::Mat input, tensorflow::Tensor&outputTensor, int height, int width) {
// 4:(b,h,w,c)
auto outputTensorMapped = outputTensor.tensor<float, 4>();
cv::Mat new_image_input = input.clone();
int initial_image_height = new_image_input.rows;//加载图片的初始高
int initial_image_width = new_image_input.cols;
//将实际输出图片还原到网络需要的宽高
float scale = min(1.0f * width / initial_image_width, 1.0f * height / initial_image_height);
int new_width = int(scale * initial_image_width);
int new_height = int(scale * initial_image_height);
//将像素值转换成浮点3通道类型
new_image_input.convertTo(new_image_input, CV_32FC3, 1.0f / 255);//先转成浮点再resize,否则有精度损失
cv::resize(new_image_input, new_image_input, cv::Size(new_width, new_height));
/*遍历每一个像素值,将其赋值给新申明的auto中转类型以转换成tensor类型。两个数据类型的值的位置需要一一对应;
循环的顺序从内到外一次是深度方向(channel)>宽度方向(cols)>高度方向(rows)*/
int dw = (width - new_width) / 2;
int dh = (height - new_height) / 2;
int depth = new_image_input.channels();
int a = 0;
int b = 0;
for (int y = 0; y < height; y++)
{
for (int x = 0; x < width; x++)
{
int g = 0;
for (int c = 0; c < depth; ++c)
{
if (y >= dh && y <(new_height + dh) && x >= dw && x < (new_width + dw)) {
outputTensorMapped(0, y, x, c) = new_image_input.at<Vec3f>((y - dh), (x - dw))[c];
}
else {//和输入图片不对应的地方就填充均值并做归一化
outputTensorMapped(0, y, x, c) = 1.0f * 128 / 255;
a++;
}
}
}
}
}
2)、前向推理代码运行逻辑
得到输入网络的数据以后,需要构建图,并将对应pb文件的变量恢复到图中,然后新建会话,将会话和图关联,在推理过程中直接将这个会话传递过去便可以了(如果每次推理都要新建图和会话,那么将会耗费非常多的资源和时间,所以只需要构建一次便可以,建议是放在初始化的时候进行这个操作)
#include <stdio.h>
#include <vector>
#include <string>
#include <iostream>
#include <iomanip>
#include "tensorflow/core/public/session.h"
#include "tensorflow/core/platform/env.h"
#include "opencv2/opencv.hpp"
#include "opencv2/highgui/highgui.hpp"
using namespace std;
using namespace cv;
using namespace tensorflow;
//整个前向推理代码包含的头文件如上
int main(int argc, char* argv[]) {
//模型存放路径,要使用绝对路径,且路径不能含有中文
std::string model_path = "E:\\experiment\\C\\pb_C++_Four_detection\\pbpred\\x64\\Release\\yolov3_face.pb";
//待检测的图片路径,且路径也是绝对路径也不能含有中文
string image_path = "E:\\experiment\\C\\pb_C++_Four_detection\\pbpred\\x64\\Release\\1.jpg";
int inputHeight = 224;//输入网络的图片的高,下面是宽
int inputWidth = 224;//
//以上参数建议在初始化时进行加载(将以上信息写入配置文件)
// 创建图
tensorflow::GraphDef graph_def;//新建图
tensorflow::Session *p_session;//新建会话
SessionOptions opts;//申明会话的配置变量
// 将模型加载到图中
tensorflow::Status ret = tensorflow::ReadBinaryProto(tensorflow::Env::Default(), model_path, &graph_def);
if (!ret.ok()) {
std::cout << "模型加载失败" << std::endl;
return NULL;
}
//session配置(配置会话)
NewSession(opts, &p_session);
// 模型图与session相关联
ret = p_session->Create(graph_def);
if (!ret.ok()) {
std::cout << "模型与session关联失败,请检查session创建是否成功!" << std::endl;
return NULL;
}
//将对应参数传递到推理函数中
int out = inference(p_session, image_path, inputHeight, inputWidth);
system("pause");
return 0;
}
加载了pb模型,创建了图和会话以后,可以进行前向推理了:
int inference(tensorflow::Session *p_session, string image_path, int inputHeight, int inputWidth)
{
long xx = GetTickCount();
double totaltime;//查看运行时间
/*如下四个变量为网络的输入和三个输出,需要和固化成pb文件时的变量名称一致,否则得不到正确的输出结果*/
std::string input_tensor_name = "input/input_data:0";//和python不一样,这里不需要带:0即不需要写成("input/input_data:0")
std::string output_tensor_name0 = "pred_sbbox/concat_2:0";
std::string output_tensor_name1 = "pred_mbbox/concat_2:0";
std::string output_tensor_name2 = "pred_lbbox/concat_2:0";
// 读取图片输出转换成输入tensor类型
cv::Mat image_data = cv::imread(image_path, 1);
tensorflow::Tensor input_tensor(tensorflow::DT_FLOAT, tensorflow::TensorShape({ 1,inputHeight,inputWidth,3 }));
cvMat2tfTensor(image_data, input_tensor, inputHeight, inputWidth);
//构建输入tensor
std::vector<std::pair<std::string, tensorflow::Tensor>> inputs;
inputs.push_back(std::pair<std::string, tensorflow::Tensor>(input_tensor_name, input_tensor));
//构建输出tensor
std::vector<tensorflow::Tensor> outputs;
//前向推理获取输出
tensorflow::Status status = p_session->Run(inputs, { { output_tensor_name0,output_tensor_name1,output_tensor_name2 } }, {}, &outputs);
if (!status.ok()) {
std::cout << "ERROR: prediction failed..." << status.ToString() << std::endl;
return -1;
}
totaltime = GetTickCount() - xx;
cout << "\n前向推理运行时间为" << totaltime << "ms!" << endl;
/*定义一个容器,将输出值存放到这个容器中(二维容器),最内层存放x,y,w,h,conf,classes,最外层存放又多少个这样的框*/
vector<vector<float>> all_bbox_data;//存放所有bbox
float score_threshold = 0.75;//预测为前景的概率大于这个值时保留框,否则舍去
int initial_image_height = image_data.rows;//加载图片的初始高
int initial_image_width = image_data.cols;
float iou_threshold = 0.45;//0.45;
//阈值、宽高、输入图片的变量名称都建议放到配置文件中,初始化时加载
//以下3个函数都在结果解析板块
primary_bbox(all_bbox_data, outputs, score_threshold, initial_image_height, initial_image_width, inputHeight, inputWidth, image_data);//初筛框
nms(all_bbox_data, iou_threshold);//非极大值抑制
show_image(all_bbox_data, image_data);//显示结果
//std::cout << "最后的框尺寸是:" << all_bbox_data.size() << std::endl;
p_session->Close();//关闭会话,释放内存
return 0;
}
③、对输出进行解析_获取最终结果
初筛框的操作:
void primary_bbox(vector<vector<float>> &all_bbox_data, vector<tensorflow::Tensor> outputs, float score_threshold, int initial_image_height, int initial_image_width, int inputHeight, int inputWidth, cv::Mat image)
{
//开始初筛bbox
cv::Mat new_image_data = image.clone();
//网络最终的3个输出都存放在outputs中,通过索引取出来;每一个tensor都是一个5维度的[bath_size,input_size,input_size,anchor_number,(5+classes)]
for (std::size_t i = 0; i < outputs.size(); i++)//输出中几个tensor
{
Tensor output = outputs[i];
auto output_data = output.tensor<float, 5>(); // 将tensor值转化能读取的类型
int dims = output.shape().dims(); //输出tensor的shape数
int last_dim = output.shape().dim_size(dims - 1); // 输出tensor的最后一个维度的元素个数
int data_num = 1; //用于计算输出的tensor有多少个框
for (int ndim = 0; ndim < output.shape().dims() - 1; ndim++)//将最后一个维度前面的维度相乘就是框的个数,最后一个维度是框的信息。
{
int output_dim = output.shape().dim_size(ndim);
data_num = data_num * output_dim;
}
for (int j = 0; j < data_num; j++)
{
vector<float> bbox_data;//存放一个锚框的信息,x1,y1,x2,y2,conf,class
for (int k = 0; k < last_dim; k++)
{
int num = j * last_dim + k;
bbox_data.push_back(output_data(num));
}
float scores;
float max_classes_value = 0.0;//预测为某个类别的概率
int claess = 5;//这个类别如果要输出,需要减5(x,y,w,h,conf)
for (int i = 5; i < last_dim; i++) {
if (bbox_data.at(i) > max_classes_value) {
max_classes_value = bbox_data.at(i);
claess = i;
}
}
scores = bbox_data.at(4) * max_classes_value;//预测为具体类别的概率(conf)*某个类别的概率才是真正的这个类别的预测概率值
//将x,y,w,h转换成x1,y1,x2,y2(左上角右下角点)
if (scores >= score_threshold) {//设定背景框阈值
float left_up_x = bbox_data.at(0) - bbox_data.at(2) / 2;
float left_up_y = bbox_data.at(1) - bbox_data.at(3) / 2;
float right_down_x = bbox_data.at(0) + bbox_data.at(2) / 2;
float right_down_y = bbox_data.at(1) + bbox_data.at(3) / 2;//因为左上角为原点,水平向右为x增大,竖直向下为y增大,所以同加同减
//将预测框缩放到原图比例
float resize_ratio = min(1.0f * inputWidth / initial_image_width, 1.0f * inputHeight / initial_image_height);
float dw = (inputWidth - resize_ratio * initial_image_width) / 2;
float dh = (inputHeight - resize_ratio * initial_image_height) / 2;
left_up_x = 1.0f * (left_up_x - dw) / resize_ratio;
right_down_x = 1.0f * (right_down_x - dw) / resize_ratio;
left_up_y = 1.0f * (left_up_y - dh) / resize_ratio;
right_down_y = 1.0f * (right_down_y - dh) / resize_ratio;
if ((left_up_x - right_down_x < 0) && (left_up_y - right_down_y < 0)) {
//这里看情况添加是否扔掉坐标点小于0的框的代码
vector<float> new_bbox_data;
float calsses = 1.0f * (claess - 5);
new_bbox_data.push_back(left_up_x);
new_bbox_data.push_back(left_up_y);
new_bbox_data.push_back(right_down_x);
new_bbox_data.push_back(right_down_y);
new_bbox_data.push_back(scores);
new_bbox_data.push_back(calsses);
all_bbox_data.push_back(new_bbox_data);//初筛的框存到容器中,等待做NMS
//rectangle(new_image_data, cvPoint(left_up_x, left_up_y), cvPoint(right_down_x, right_down_y), Scalar(0, 0, 255), 1, 1, 0);
//putText(new_image_data, "Tread", cvPoint(left_up_x, left_up_y), FONT_HERSHEY_COMPLEX, 0.3, Scalar(0, 0, 255), 1);
}
}
}
}
//imshow("效果图", new_image_data);
//cvWaitKey();
//imwrite("E:\\初筛结果detection.jpg", new_image_data);
//std::cout << "初筛框完成"<
}
做完初筛框以后就是非极大值抑制,这个函数会用到两个辅助函数,一个是排序函数,一个是计算IOU的函数:
IOU的函数如下:
float Iou(vector<float> initial_bbox, vector<float> wait_bbox)
{
float inter_left_up_x = max(initial_bbox.at(0), wait_bbox.at(0));
float inter_left_up_y = max(initial_bbox.at(1), wait_bbox.at(1));
float inter_right_down_x = min(initial_bbox.at(2), wait_bbox.at(2));
float inter_right_down_y = min(initial_bbox.at(3), wait_bbox.at(3));
if (inter_left_up_x > initial_bbox.at(2) || inter_left_up_x > wait_bbox.at(2) || inter_left_up_y > initial_bbox.at(3) || inter_left_up_y > wait_bbox.at(3)) {
return 1e-5f;
}//满足任意一种,则两框无交集
float inter_area = fabs((inter_right_down_x - inter_left_up_x)) * fabs((inter_left_up_y - inter_right_down_y));//交集面积
float initial_bbox_area = fabs((initial_bbox.at(2) - initial_bbox.at(0))) * fabs((initial_bbox.at(1) - initial_bbox.at(3)));//计算面积
float wait_bbox_area = fabs((wait_bbox.at(2) - wait_bbox.at(0))) * fabs((wait_bbox.at(1) - wait_bbox.at(3)));
float union_area = initial_bbox_area + wait_bbox_area - inter_area;
float bbox_iou = max(1.0f * inter_area / union_area, 1e-5f);//IOU,交并比
return bbox_iou;
}
排序函数如下(降序排列):
bool cmpScore(vector<vector<float>> &boundingBox)
{
const int num_boxes = boundingBox.size();
for (int i = 1; i < num_boxes; ++i) {
vector<float> key_bboxe = boundingBox.at(i);//这个赋值,当原地址改变后赋值的内容是否会被改变?
float key_score = key_bboxe.at(4);
int j = i - 1;
while (j >= 0 && key_score > boundingBox.at(j).at(4)) {
boundingBox.at(j + 1) = boundingBox.at(j);
j--;
}
boundingBox.at(j + 1) = key_bboxe;
}
return true;
}
非极大值抑制NMS(硬版)
void nms(vector<vector<float>> &boundingBox, float iou_threshold, string method = "nms", float sigma = 0.3)
{
if (boundingBox.empty()) {
return;
}
//对各个候选框根据score的大小进行降序排列
cmpScore(boundingBox);
vector<vector<float>> temporary_boundingBox = boundingBox;//临时存放框,防止删除框后原始数据被删除
vector<vector<float>> pick_boundingBox;//存放经过抑制后的最合适的框
while (temporary_boundingBox.size() > 0)
{
vector<float> bbox_data = temporary_boundingBox.at(0);
pick_boundingBox.push_back(bbox_data);//这里需要深度拷贝
vector<vector<float>> delete_boundingBox;//要删除的框
for (int i = 1; i < temporary_boundingBox.size(); i++) //获取IOU
{
float iou = Iou(bbox_data, temporary_boundingBox.at(i));
if (iou > iou_threshold) {
delete_boundingBox.push_back(temporary_boundingBox.at(i));
}
}
//删除temporary_boundingBox的第0个位置上的元素(框)
temporary_boundingBox.erase(remove(temporary_boundingBox.begin(), temporary_boundingBox.end(), bbox_data));
while (delete_boundingBox.size() > 0)
{
temporary_boundingBox.erase(remove(temporary_boundingBox.begin(), temporary_boundingBox.end(), delete_boundingBox.at(0)));//删除IOU大于阈值的框
delete_boundingBox.erase(remove(delete_boundingBox.begin(), delete_boundingBox.end(), delete_boundingBox.at(0)));//更新待删除框
}
}
boundingBox.resize(pick_boundingBox.size());
boundingBox = pick_boundingBox;
//std::cout << "非极大值抑制完成" << std::endl;
}
最终结果显示的函数:
void show_image(vector<vector<float>> all_bbox_data, cv::Mat image)
{
if (all_bbox_data.empty()) {
return;
}
cv::Mat new_image_data = image.clone();
for (int i = 0; i < all_bbox_data.size(); i++) //获取框
{
vector<float> bbox_data = all_bbox_data.at(i);
float left_up_x = bbox_data.at(0);
float right_down_x = bbox_data.at(2);
float left_up_y = bbox_data.at(1);
float right_down_y = bbox_data.at(3);
rectangle(new_image_data, cvPoint(left_up_x, left_up_y), cvPoint(right_down_x, right_down_y), Scalar(0, 0, 255), 3, 1, 0);
putText(new_image_data, "Tread", cvPoint(left_up_x, left_up_y - 5), FONT_HERSHEY_COMPLEX, 0.5, Scalar(0, 0, 255), 0.5);
std::cout << "满足背景置信度的框为:" << bbox_data.at(0);
std::cout << ",";
std::cout << bbox_data.at(1);
std::cout << ",";
std::cout << bbox_data.at(2);
std::cout << ",";
std::cout << bbox_data.at(3);
std::cout << ",";
std::cout << bbox_data.at(4);
std::cout << ",";
std::cout << bbox_data.at(5);
std::cout << std::endl;
}
imshow("效果图", new_image_data);
cvWaitKey();
imwrite("E:\\detection.jpg", new_image_data);
}
如果是分类网络,前向推理和目标检测几乎一致,对于解析outputs也是需要知道输出的个数个每个tensor的维度,原理和目标检测的一样,甚至要更简单。因为只需要找一个bath_size中的预测结果,如果是logits激活后的结果,只需要选择哪个概率值(conf)最大把这个最大值的索引取出来就是具体的类别了。如果网络输出的是类别,则直接读取对应类别的值便可以了:
void Result(std::vector<tensorflow::Tensor> outputs)
{
std::cout << "Output tensor size:" << outputs.size() << std::endl;
for (std::size_t i = 0; i < outputs.size(); i++) {
std::cout << outputs[i].DebugString();
}
std::cout << std::endl;
Tensor t = outputs[0]; // Fetch the first tensor
//int ndim = t.shape().dims(); // Get the dimension of the tensor
auto tmap = t.tensor<float, 2>(); // Tensor Shape: [batch_size, target_class_num]
int output_dim = t.shape().dim_size(1); // Get the target_class_num from 1st dimension
std::vector<double> tout;
// Argmax: Get Final Prediction Label and Probability
int output_class_id = -1;
double output_prob = 0.0;
for (int j = 0; j < output_dim; j++) {
std::cout << "Class " << j << " prob:" << tmap(0, j) << "," << std::endl;
if (tmap(0, j) >= output_prob) {
output_class_id = j;
output_prob = tmap(0, j);
}
}
//打印
std::cout << "class id: " << output_class_id << std::endl;
std::cout << "class prob: " << output_prob << std::endl;
std::cout << "Output Prediction Value:" << output_prob << std::endl;// Assign the probability to prediction
}
3、GPU环境
①、环境配置
Visual Studio的配置几乎一致,只需要增加安装对应编译环境的CUDA和cudnn就可以了
②、代码更改
GPU环境所不同的就是在新建会话时要设置显存占用比和动态分配显存,并使用GPU版本的编译环境:
#include <stdio.h>
#include <vector>
#include <string>
#include <iostream>
#include <iomanip>
#include <stdlib.h>
#include "tensorflow/core/public/session.h"
#include "tensorflow/core/graph/default_device.h"//新加头,需要将该头里面定义的常量TENSORFLOW_GRAPH_DEFAULT_DEVICE_H_加到预编译头里面
#include "tensorflow/core/platform/env.h"
#include "opencv2/opencv.hpp"
#include "opencv2/highgui/highgui.hpp"
//包含的头文件如上
// 创建图(和CPU环境一样)
tensorflow::GraphDef graph_def;//新建图(和CPU环境一样)
tensorflow::Session *p_session;//新建会话(和CPU环境一样)
SessionOptions opts;//申明会话的配置变量(和CPU环境一样)
//只需要加上如下两句,其他代码和CPU环境一样
opts.config.mutable_gpu_options()->set_per_process_gpu_memory_fraction(0.8);
opts.config.mutable_gpu_options()->set_allow_growth(true);
..........(和CPU环境一样的代码)