基于MindStudio的Tensorflow 模型命令行推理一键式精度比对
基于MindStudio的Tensorflow 模型命令行推理一键式精度比对
---以AIPaint为例
对应的视频教程链接:基于MindStudio的Tensorflow模型命令行推理一键式精度比对_哔哩哔哩_bilibili
目录
第1章. 引言...
第2章. 前置知识与基础介绍...
模型推理与模型保存格式...
模型转换(从pb转为om)与图优化...
华为模型转换工具...
精度损失与精度比对工具...
MindStudio软件...
第3章. 环境准备...
MindStudio 安装与基本设置...
和远程开发环境相连...
第4章. 实验...
脚本获取...
启动项目...
查看文件映射关系...
脚本环境设置...
运行脚本与环境变量设置...
结果解析...
第5章. 总结...
第6章. 附录...
遇到的问题以及解决方法...
一些开发建议...
一些文档...
-
引言
大家好,模型转换是在推理时常见的一种需求,如在Ascend 310上部署应用需要[1] 使用om模型,然而我们通常使用MindSpore 、Tensorflow 或 Pytorch所开发的模型都不是om模型,从而需要对不同的格式进行转换或者称为翻译。模型文件通常包含两部分构成:1. 模型的图信息(包含节点和边);2. 模型的参数信息(如卷积层kernel的weight)。不同的文件格式代表了其对图信息和参数信息的描述不同,同一个卷积在tensorflow模型格式 pb 和 Pytorch格式的pt中描述不同。
模型转化就是针对不同的格式(或者称为图描述,参数描述)做对应目标的转换。然后这种转换通常会对原始模型做一定程度的优化,如消除一些没用到的图节点,合并算子以及降低数据精度(将fp32转为fp16)。 这种操作可能会使得转换后的模型(om模型)精度不如原始模型(pb模型)。这时候为了找到因为算子转换导致的精度差异,通常会将原始模型(pb模型)和转换后模型(om模型)的全图运算信息获取下来(称为dump过程),进行逐算子对比,从而找到差异.
然而获取全图逐算子运算结果是非常复杂的过程.为此本文会向大家介绍一键精度比对工具,以及如何使用MindStudio实现精度的比对。MindStudio 本文主体由基础知识介绍,环境准备,具体实验和总结四部分组成。实验部分是以官方例子AIPaint做基础演示。最后本文是本文档的总结,以及根据笔者的开发经验,总结出一些tips,希望能帮助到各位开发者。在本文中,tools库中的msquickcmp将用来一键生成对比数据,MindStudio将用于精度对比.
提醒:如果对基础知识以及有了较多的了解或者想尽快浏览实验部分的,可以直接跳过第一部分--前置知识和第二部分—环境准备,直接到第三部分的实验和第四部分的总结。
-
前置知识与基础介绍
模型推理与模型保存格式
推理首先需要固定模型,一般是由训练好的模型前向传播图固定成框架对应的格式,其中与训练不同的是除了个别算子的值(如dropout和bathnorm之类的归一化算子)会发生改变,其他与训练时没有差别. 如tensorflow框架下开发的模型,通常需要保存为pb模式, pytorch框架开发的模型通常会保存为pt格式.除了框架相关的格式外,还有统一的格式:onnx(开放神经网络交换,Open Neural Network Exchange ). 保存的文件一般包含:模型的算子图信息和参数信息, 常见的模型包括om模型都可以使用MindStudio的model visualize 模块或者netron打开查看图结构. 这里需要说明一点, 单纯使用torch.save(“model.pt”,model)保存的模型只有参数信息,并不具有算子网络图信息,只有torch脚本定义的高级图信息(图节点为自定义的module name).通过torch.jit.trace()模拟输入dummy_input,调用traced.save()存储成的pt模型才具有算子级网络图信息.如果需要转为om模型,通常会先将pt转为onnx然后转为om.
模型转换(从pb转为om)与图优化
从原始格式模型转换到目标格式模型,过程涉及到算子和图的格式转换. 在华为Atals 服务器(搭载Ascend 910或者Ascend 310芯片)上,模型加速推理的运行时(CANN Compute Architecture for Neural Networks) 依赖om格式的模型。这里的加速推理指的是使用AICore进行推理.
模型转换可以采用算子级别一对一转换,即只针对模型的算子格式做转换,并不更改更多的内容.模型的值运算通常需要在特定的设备(加速卡等)上做矩阵运算,而模型的赋值操作通常涉及到cpu操作,数据在两种设备之间频繁传递. 为了减少这样的传递, 通常会在原始网络模型基础上做进一步优化. 优化主要包括两个部分: 网络图优化和精度优化. 图优化主要包括:节点级优化(消除没有使用的算子或者全等算子,如 dropout在推理时可以直接去掉), 块级优化(包括常数折叠,算子合并等). 这里我们呈现两个例子:

上图右边是pb模型,左边是对应的om模型,如图所示,出现了多个算子合并,如卷积算子合并,将两个算子合并为一个算子,还有后面的多个算子也是合并为单个算子。这样对于算子的描述就会发生改变,下图是om模型中,一个add算子的描述:

attributes表示该算子其实是一个合并算子(fused op),是将add和relu合在一起的算子。
通常这种优化不会对精度产生任何影响,任何一个优化操作原则上不会对计算结果造成偏差,但是会在一定程度上减少数据的搬运和计算的次数. 然而精度优化例外. 精度的优化通常指的是 将fp32的权重值改为fp16的值,从而加速运算. 由于fp32的权重值改为fp16, 部分运算可能会出现精度丢失.一般情况下, fp32的运算改为fp16去算,对结果不会造成太大的影响, 但由于神经网络是由大量的矩阵运算组成,因此很难确保过程中是否会导致较大的值偏移.另外还有一种模型参数精度的优化:将fp32的模型转为int8的模型,从而大大减小模型的参数空间.这一种优化称为模型量化,是另外一个分支.
还有涉及到后端(特定设备)的优化, 如算子调度优化, 内存优化等. 但是这些只影响算子的运行效率,不影响精度. 感兴趣的小伙伴可以参考 The Deep Learning Compiler: A Comprehensive Survey.
华为模型转换工具
将pb, onnx模型转为om模型需要使用到 ATC工具(Ascend Tensor Compiler).该工具集成在 CANN包中, 将开源框架(如 Caffe、TensorFlow、ONNX)和单算子 json 文件的网络模型转换为 Ascend AI Processors 支持的离线模型。在模型转换过程中,可以实现算子调度优化、权重数据重排、内存优化,不依赖设备完成模型预处理。
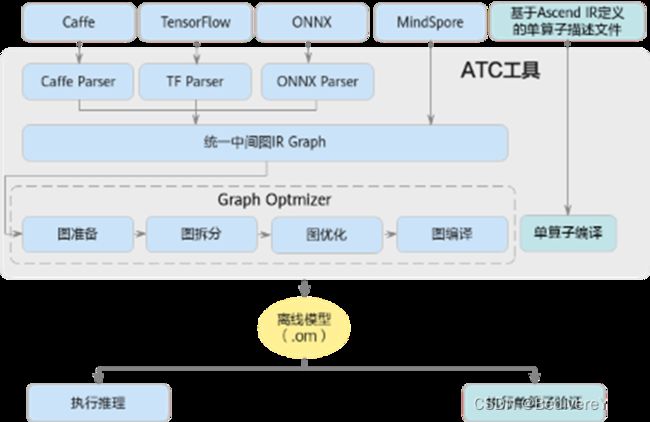
这里需要说明的是 ATC包含了模型编译的前端和后端。前端指的是将原始格式模型转为高级IR,后端指的是对于设备的代码模型优化,如调度优化和显存优化,从而得到更高的性能。对于后端的调优可以采用auto tune工具。
这里需要说明的是 ATC包含了模型编译的前端和后端。前端指的是将原始格式模型转为高级IR,后端指的是对于设备的代码模型优化,如调度优化和显存优化,从而得到更高的性能。对于后端的调优可以采用auto tune工具。
精度损失与精度比对工具
Om模型推理与pb模型推理的主要精度差异来自俩方面:1. 输入不同导致的精度不同(常见原因有预处理没有对齐),2. 算子精度下降或者算子运算出错。对于第一种精度差异,可以通过对齐预处理来解决。方式是将预处理后的结果直接保存为bin文件,然后pb和om用相同的bin文件作为输入进行推理。注意om模型的输入通常都是32位的,如果保存格式为fp64或者fp16,会导致异常。这里记录一个笔者遇到的问题:transfering gan模型需要输入一个random.normal 的值,np.random.normal得到的是float64类型,如果以此保存为bin文件会导致结果差异较大。
而算子精度下降,需要对比算子的输入输出值,通常需要采集两侧的算子运算过程值。这里采集pb模型推理过程中的算子输入输出可以使用tensorflow.python debug模块,开启debug模型,通过dump得到tensor的信息。Om模型的算子运行结果可以在msame运行时开启dump选项。算子的输入输出值通常都是高维数据,通常采用欧式距离(如l1 距离,l2距离)和相似度(cosine similarity)。 现有的集成在CANN包中的精度对比差异计算方式支持如下算法:
- 0:CosineSimilarity,表示余弦相似度算法。
- 1:MaxAbsoluteError,表示最大绝对误差算法。
- 2:AccumulatedRelativeError,表示累积相对误差算法。
- 3:RelativeEuclideanDistance,表示欧氏相对距离算法。
- 4:KullbackLeiblerDivergence,表示KL散度算法。
- 5:StandardDeviation,表示标准差算法。
- 6:MeanAbsoluteError,表示平均绝对误差。
- 7:RootMeanSquareError,表示均方根误差。
- 8:MaxRelativeError,表示最大相对误差。
- 9:MeanRelativeError,表示平均相对误差。
MindStudio软件
MindStudio提供在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助您在一个工具上就能高效便捷地完成AI应用开发。MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。需要注意的是, MindStudio只有Linux和Windows两个版本,MAC电脑所使用的Unix OS不支持.
MindStudio 类似IDEA 软件,如下图所示,

需要说明的是,通常在Windows服务器上安装MindStudio,昇腾AI设备需要安装对应的驱动、固件、Ascend-cann-toolkit和AI框架包。我们在本地写脚本,然后在云端(昇腾AI设备)执行,如下图所示:

如果您是直接在开发板上写脚本,会不同。本文针对的是以上开发场景。
MindStudio解决了两个问题:文件和云端同步以及脚本能够在云端执行。其中针对远程开发,MindStudio提供了Tools工具,该工具下面包含最常用的Deployment和SSH session工具。

其中Deployment 可以实现脚本的自动上传,SSH能够帮助我们随时链接远程服务器。
Ascend工具
MindStudio 还提供了 Ascend工具,其中包含很多我们开发Ascend应用时需要使用的工具, 如迁移工具(migration tools), 模型转换工具(model converter) , 模型可视化工具(model visualizer),模型精度分析工具(model accuracy analyzer),dump工具等.

Ascend 工具同时操纵远程的昇腾AI设备以及本地的开发环境.部分工具对本地环境有限制,如migration tools需要本地安装有pandas等库, profiler工具需要本地的python3环境能够使用sqlite.
-
环境准备
本次的实验涉及本地开发环境(window10) 和 远程开发环境(Ascend 910服务器).
本地开发环境需要安装python3 和 MindStudio 软件.远程开发环境需要CANN中Ascend-cann-toolkit(开发套件包)。该开发套件是为开发者提供基于昇腾AI处理器的相关算法开发工具包,旨在帮助开发者进行快速、高效的模型、算子和应用的开发。开发套件包只能安装在Linux服务器上,开发者可以在安装开发套件包后,使用MindStudio开发工具进行快速开发.
目前远程开发环境(Ascend 910服务器)一般已经由华为官方配置好了,主要是驱动和CANN包的安装.
MindStudio安装与基本设置
MindStudio软件在本地安装时有环境要求, 为了避免后续出问题,建议遵循先检查环境是否完备,然后再安装软件.
参考链接:
昇腾社区-官网丨昇腾万里 让智能无所不及
首先检查本地环境
本地是否有python3.7及以上版本?
在cmd中输入python即可查验.

这里可能出现的问题是不少用户使用Conda或者miniconda实现python的环境管理,而跳过安装python的步骤,而使用anaconda或者miniconda所携带的默认python, 根据笔者的实验,发现: miniconda所自带的python版本通常为3.9, 且部分依赖缺失,如sqlite的dll文件.因此,建议安装独立安装python3.7.
Python3.7 的版本可以通过 Welcome to Python.org 获得. 下载安装文件后,注意将python的路径添加到环境变量的path中. 在window10上可以通过win+s键,然后输入编辑环境快速进入环境变量设置界面.
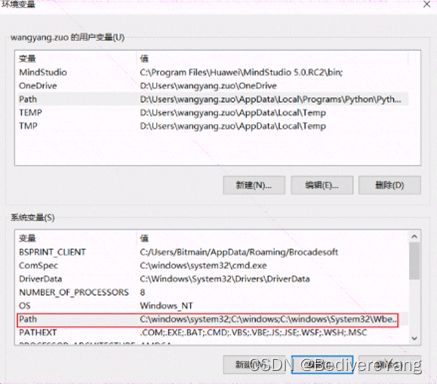

需要安装一下python包, xlrd==1.2.0 absl-py numpy和pandas.
本地是否有MinGW 和 cmake?
由于部分脚本可能依赖c++和cmake环境, 而在window上安装c++编译器需要使用到MinGW. 通过MinGW-w64 - for 32 and 64 bit Windows - Browse Files at SourceForge.net 下载MinGW ,下载完安装好后,添加bin目录到path路径中,和上面操作相同.
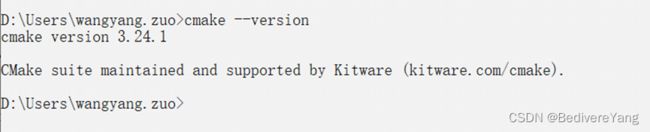
Cmd启动的terminal中输入 gcc –v可以查验gcc是否安装成功.

输入 cmake –version,出现下图所示则说明安装成功.
需要注意的是: 我们可以完全在远程开发环境上安装MindStudio, 而本地只需要安装MobaXterm即可. 在远程开发环境上启动带有界面的MindStudio, 通过MobaXterm中自带的XServer映射远程软件的GPU, 从而实现单机安装MindStudio进行开发. 然而这种连接对网络和设备要求都较高, 会出现高延迟卡顿等情况, 笔者并不推荐, 然而这似乎也是MAC用户使用MindStduio的唯一解.
软件安装
软件包下载地址: 昇腾社区-官网丨昇腾万里 让智能无所不及
获取[1] 最新的MindStudio exe安装包,含有GUI的集成开发环境。也可以下载zip没安装的软件包, 但是exe能够帮助自动设置路径.可以通过如上的网址校验软件, 确保软件包未被篡改.
双击下载的exe即可实现安装, 可以选择一路next到底.

没有报错就可以看到入口的界面 :
此时完成安装.
华为的远程环境(除了在华为云ECS上买的Ascend 310推理环境)需要通过secoclient连接昇腾生态众智实验室网络,具体教程链接为:
guide/common/tutorials/昇腾生态众智实验室网络连接指导.md · Ascend/docs-openmind - Gitee.com
在本机中,出现如下所示即可表示连上了华为的昇腾生态众智实验室网络.


我们新建一个项目,测试与服务器的连接.
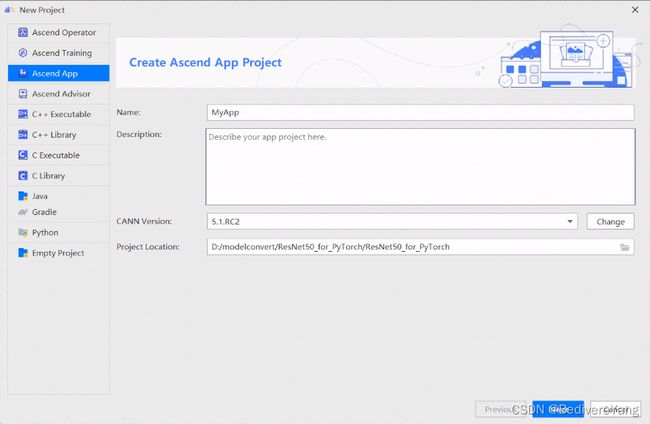
通过change设置与远程服务器CANN的连接.

点击右侧的![]() 进入ssh配置环节, 通过test connect 测试连接是否通达.
进入ssh配置环节, 通过test connect 测试连接是否通达.
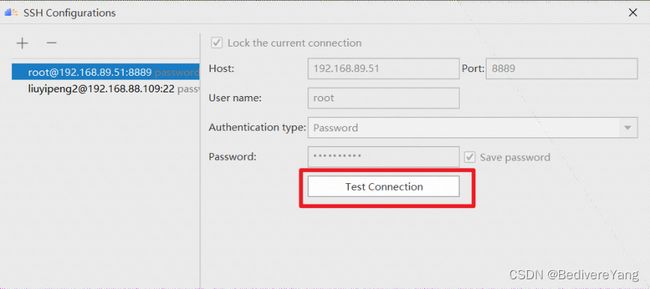
出现下图所示表示连接成功.

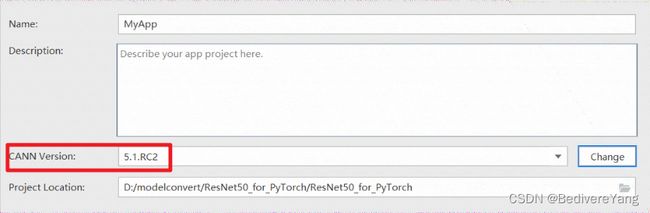
出现上图表示已经找到了CANN包,如果MindStudio没有自动找到,可以通过如下路径添加 /usr/local/Ascend
-
实验
脚本获取
本次实验需要使用msame工具实现om模型的推理以及dump功能. msame工具在tools库中. 通过 git clone tools: Ascend tools 获取tools仓库。
另外本次实验需要使用一键精度对比(msquickcmp)工具,参考如下链接:
一键式全流程精度比对 - CANN 5.0.4 开发工具指南 01 - 华为
msquickcmp 工具是一个脚本集, 也在tools下面. 参考链接:
tools: Ascend tools - Gitee.com
启动项目
由于我们本地已经有项目文件,因此我们选择Empty Project

点击finish后便可进入项目。

我们将其转为 Ascend project,以方便使用MindStudio自带的Ascend 工具。
转换后我们可以看到有Ascend工具栏更新了

在这个项目里面,我们会用到 Convert 工具和Accuracy Analyzer工具。
查看文件映射关系
通过Tools Deployment configuration 可以看到本地文件与远程服务器的映射关系。


脚本环境设置
如tools仓库msquickcmp Readme 所示,我们需要额外安装一些pip包。由于910服务器已经安装好了tensorflow, 我们只需要安装 onnxruntime, onnx, numpy skl2onnx pexpect 和gnureadline。
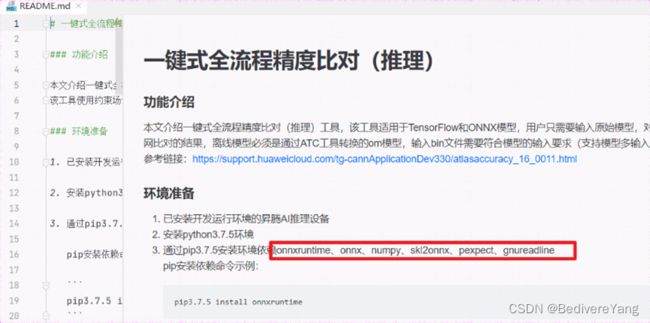
这里还需要readline包,部分机器第一次安装这个包可能会出问题,详见附录部分。
模型准备和转换:
下载相关模型,本次实例用的是msquickcmp 的示例模型,原始模型获取地址
https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_ATC_Models/AE/ATC%20Model/painting/AIPainting_v2.pb
om模型获取地址
https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_ATC_Models/AE/ATC%20Model/painting/AIPainting_v2.om
但是已有的om模型是基于Ascend310编译的,为了适配当前的环境,我们需要重新编译(转换)pb模型。
可以得到pb文件,通过deployment可以自动同步到本地,注意远程目录的地址,可以通过tools工具栏中的start ssh session启动ssh,然后进入相应的目录实现模型下载。 也可以现在本地下载后通过右键文件,deployment到服务器。
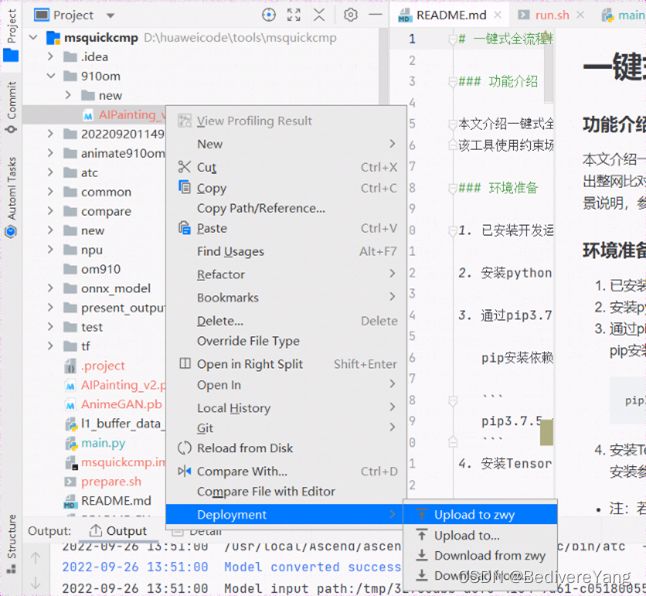
在Ascend工具栏中点击model convert,并选择文件后出现如下界面

注意Target SoC Version的选择,因为我们是910服务器所以选择Ascend910A。下面的Input Nodes自动解析是Ascend工具自动在pb文件中查找出的,但是根据netron对模型可视化(这里也可以通过model visualize可视化,但是个人感觉netron可视化界面以及布局方式都比MindStudio好看)。

所以我们需要将上图的objs type改为int32,此过程比较简单,不再截图演示。这里需要说明的是,Ascend工具可能是通过数据大小猜测输入为fp16,因为fp16和int64所占据的空间大小是相同的。

这里我们不做选择,直接next。
不过需要说明的是om可以将预处理集成在其中,从而利用硬件加速预处理。感兴趣的伙伴可以试试。另外因为我们要做dump,需要严格要求模型的输入一致,所以这里不可以使用Data Preprocessing。

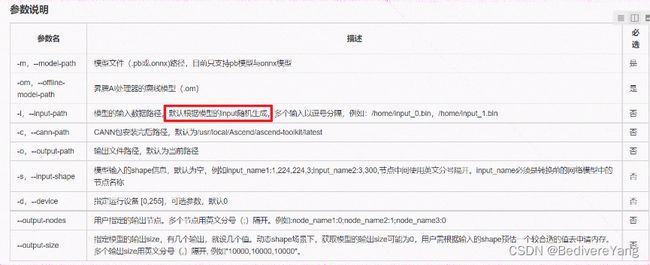
下一步是一些高级设置。这里对应初开始的背景介绍。第一个是算子合并(operation fusion),是图优化的一部分,auto tune会同时优化前后端,但是都只加速运行速度,不影响精度。影响精度的并没有在这里体现出来。查看上图的command preview可以观察到工具是通过将前面的设置转化为command命令实现模型转换,本质上还是调用ATC工具。而ATC工具在模型转换时有一些默认参数。这里我们在ssh界面通过输入 atc –help可以看到很多参数设置,也可以通过如下文档和图看到。
参数概览 - CANN 5.0.4 ATC工具使用指南 01 - 华为
这里额外关注算子调优参数(--precision mode),他的默认参数是 force_fp16(default).

即强制将转化模型参数从fp32转为fp16.
我们暂时只做了解,不做修改。

图来源华为官网 ATC参数讲解图
点击finish开始转换,查看output可以看到

转换成功。这里我们就准备好了模型,下面开始推理(注意上传文件到远程开发目录下)。
一般来说,推理需要准备推理的输入。一键精度比对工具和msame工具类似支持输入bin文件也支持无数据输入。在无数据输入时,默认根据模型的input随机生成。(如果我们发现部分的推理有问题,可以采用携带bin文件进行精度比对,否则可以使用默认的随机数据作为精度比对。)
运行脚本与环境变量设置
根据msquickcmp文档,需要设置一些环境变量,如下所示:

带有export的都是环境设置。这些环境变量设置需要在运行main.py脚本时使用。main.py有很多参数,如下图所示:
运行main.py首先需要配置python解释器。这里我们选择左上角的Add Configuration添加python脚本的配置。
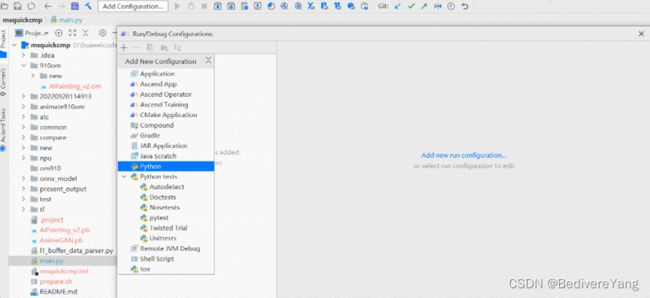
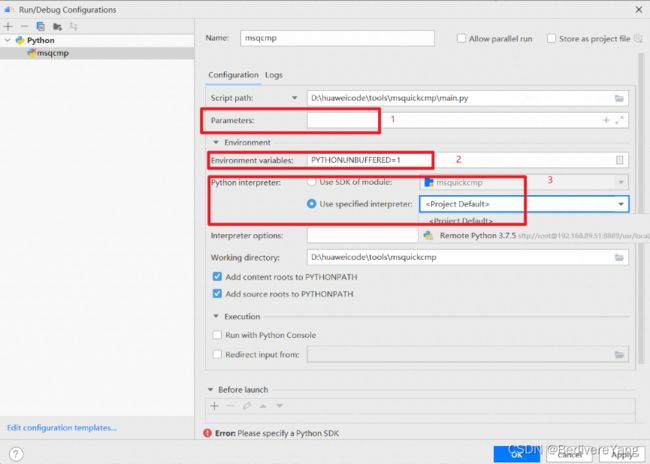
其中1处添加参数,2处添加前文提及的环境变量,3处设置remote python3.7.5环境。
我的1处配置为:-m ./AIPainting_v2.pb -om ./910om/AIPainting_v2.om -c /usr/local/Ascend/ascend-toolkit/latest -o ./test
2的配置是export环境变量的转换

配置完后, ,会出现该标志,msqcmp对应上截图所示的name。点击右边按钮运行脚本。查看run窗口可以看到脚本已经运行。
,会出现该标志,msqcmp对应上截图所示的name。点击右边按钮运行脚本。查看run窗口可以看到脚本已经运行。
接下来需要等待一段时间等待运行结束。这里介绍main.py的精度比对原理:
- 模拟tf debug工具开启tensorflow的debug模型,并通过GDB的接口模拟输入得到pb模型的dump结果。
- 构建工程目录父目录的msame工具(这里可能会出错,没有msame工具,解决方案详细查看附录)。
- 通过msame dump om模型的算子运行结果。
- 比对两者之间的差异生成report文件。
出现如下结果表示比对结束:

红色圈出的部分是msquickcmp给出的总结。
仔细观察输出详细可以发现tf和npu的dump文件地址。msquickcmp会给出总的结果。

通过 ls 可以看到其生成了以.csv结尾的文件,该文件记录了整网比对的结果。

注意dump文件较大,不建议同步到本地。
结果解析
result为一键精度比对分析结果。但是result不具有格式化,结果也不无法自定义,因此我们使用MindStudio的Ascend工具里面的Model Accuracy Analyzer来分析精度差异。
首先我们新建一个task。

随后可以看到new task的配置:注意
- output的位置为最后生成的result csv文件的位置(是本地存放的位置);
- Analysis Mode应该为 NPU和GPU/CPU的对比;
- Framework 为tensorflow;
- NPU Dump的地址为npu dump目录中的最后一层详细看下图的右边部分;
- Model File 为om模型的位置;
- Ground Truth为pb dump的位置;
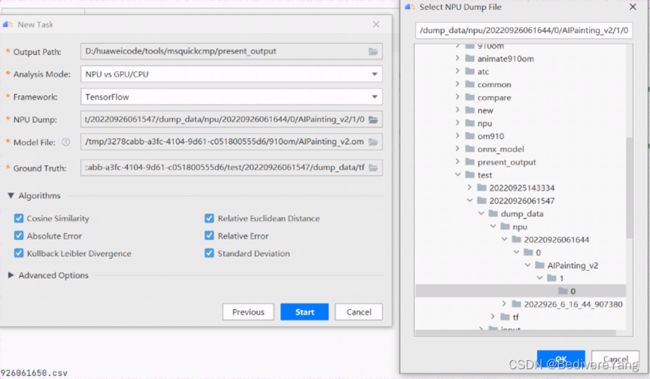
这里的Advanced Options如下图所示,可以自定义比对算法,但是本文档不涉及。
随后开始进行比对,可以看到如下图:


左上角是生成的result文件,中间主体部分是对应的表格内容和可视化图。result csv展示了丰富的对比结果,下面是csv中模型比对结果参数说明:
| 参数 |
说明 |
| Index |
网络模型中融合算子的ID。 |
| OpSequence |
部分算子比对时算子运行的序列。即-f参数指定的全网层信息文件中算子的ID。仅配置-r参数时展示。 |
| LeftOp |
表示基于昇腾AI处理器运行生成的dump数据的算子名。 |
| RightOp |
表示基于GPU/CPU运行生成的npy或dump数据的算子名。 |
| TensorIndex |
表示基于昇腾AI处理器运行生成的dump数据的算子的input ID和output ID。 |
| Shape |
比对的Tensor的Shape。 |
| OverFlow |
溢出算子。显示YES表示该算子存在溢出;显示NO表示算子无溢出;显示NaN表示不做溢出检测。 |
| CosineSimilarity |
进行余弦相似度算法比对出来的结果,取值范围为[-1,1],比对的结果如果越接近1,表示两者的值越相近,越接近-1意味着两者的值越相反。 |
| MaxAbsoluteError |
进行最大绝对误差算法比对出来的结果,取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| AccumulatedRelativeError |
进行累积相对误差算法比对出来的结果,取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| RelativeEuclideanDistance |
进行欧氏相对距离算法比对出来的结果,取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| KullbackLeiblerDivergence |
进行KL散度算法比对出来的结果,取值范围为0到无穷大。KL散度越小,真实分布与近似分布之间的匹配越好。 |
| StandardDeviation |
进行标准差算法比对出来的结果,取值范围为0到无穷大。标准差越小,离散度越小,表明越接近平均值。该列显示两组数据的均值和标准差,第一组展示基于昇腾AI处理器运行生成的dump数据的数值(均值;标准差),第二组展示基于GPU/CPU运行生成的dump数据的数值(均值;标准差)。 |
| MeanAbsoluteError |
表示平均绝对误差。取值范围为0到无穷大,MeanAbsoluteError趋于0,RootMeanSquareError趋于0,说明测量值与真实值越近似;MeanAbsoluteError趋于0,RootMeanSquareError越大,说明存在局部过大的异常值;MeanAbsoluteError越大,RootMeanSquareError等于或近似MeanAbsoluteError,说明整体偏差越集中;MeanAbsoluteError越大,RootMeanSquareError越大于MeanAbsoluteError,说明存在整体偏差,且整体偏差分布分散;不存在以上情况的例外情况,因为RMSE ≥ MAE恒成立。 |
| RootMeanSquareError |
表示均方根误差。取值范围为0到无穷大,MeanAbsoluteError趋于0,RootMeanSquareError趋于0,说明测量值与真实值越近似;MeanAbsoluteError趋于0,RootMeanSquareError越大,说明存在局部过大的异常值;MeanAbsoluteError越大,RootMeanSquareError等于或近似MeanAbsoluteError,说明整体偏差越集中;MeanAbsoluteError越大,RootMeanSquareError越大于MeanAbsoluteError,说明存在整体偏差,且整体偏差分布分散;不存在以上情况的例外情况,因为RMSE ≥ MAE恒成立。 |
| MaxRelativeError |
表示最大相对误差。取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| MeanRelativeError |
表示平均相对误差。取值范围为0到无穷大,值越接近于0,表明越相近,值越大,表明差距越大。 |
| CompareFailReason |
算子无法比对的原因。 若余弦相似度为1,则查看该算子的输入或输出shape是否为空或全部为1,若为空或全部为1则算子的输入或输出为标量,提示:this tensor is scalar。 |
一一讲解会比较麻烦,这里笔者结合自己的经验介绍主要会观察的几个地方。由于笔者的经验有限,一些错过的地方希望大家能够见谅,并补充在后续的文档里面。
首先我们在众多的评价指标中,cosine similarity是我们比较关注的指标。其次从结果往前看,我们首先找到输出节点。通过netron或者MindStudio 的Model Visualize可以看到
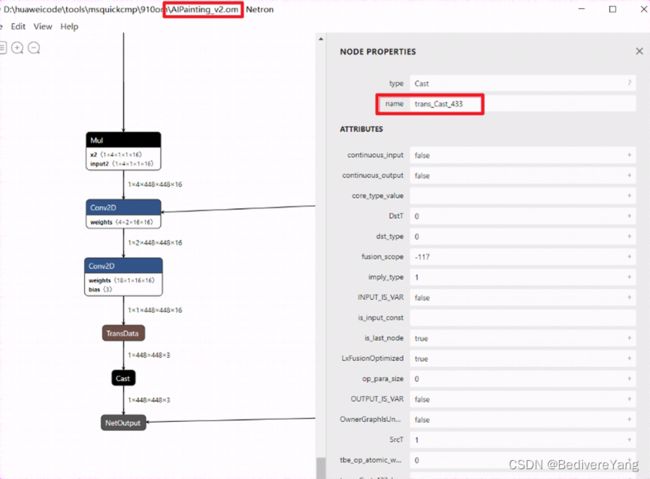
离输出节点最近的是trans_Cast433算子,我们查看table

看到非常相似,只有很小的误差,这误差的来源可能是不同的精度(pb为fp32, om为fp16)导致,但是对整体推理结果应该不影响。
大家可能观察到我们是通过result文件得到可视化table和图的,因此我们也可以直接使用msquickcmp的result文件分析,会得到相同的table和图。
另外我们从scatter diagram看会更加清晰:
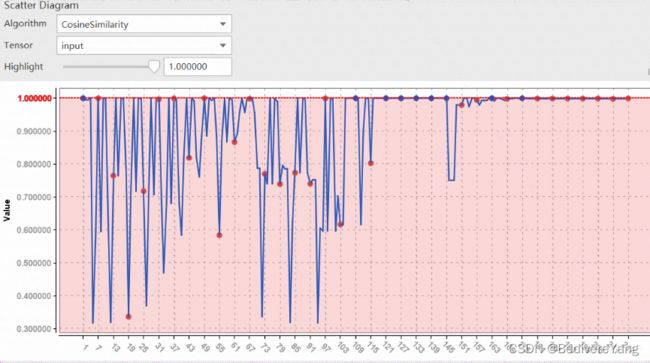
中间会有一些算子的精度可能出现了异常,但是总体这种得到了调整。
到此我们完成了一键精度比对。
-
总结
模型转换过程中出现精度损失可以通过对两个模型进行dump,得到算子级别的差异结果。通过对于算子输入和输出得到精度丢失的算子。比对om和pb或者onnx,进行自动dump和自动计算差异的过程叫做一键精度比对。通过tools库的msquickcmp工具实现一键精度比对,通过MindStudio软件的Model Accuracy Analysis可以得到可视化的结果。
-
附录
遇到的问题以及解决方法
- 文件找不到:
通过linux命令查看是否存在文件,如果不存在,则在MindStudio里面执行一下文件上传。
- 环境依赖问题:
pip 安装 readline 包安装不上。
经查需要安装libncurses5-dev,需要执行sudo apt install libncurses5-dev. 然而我没有sudo权限,因此换了一个有权限的机器。

缺少tfdbg_ascend
ECS中的Ascend310服务器报错如下,这可能是线上的CANN版本过低,没有tfdbg_ascend .

一种方法是升级CANN包。
- 出现报错No such file or directory: '/tmp/msame'
在run.sh运行完后,可能会出现如下错误。原因是msame工具需要在msquickcmp工具在父级目录。因此我们copy tools里面的msame到/tmp/msame里面。通过执行cp -r xxxx、tools/msmae /tmp/msame, 进而重新执行run脚本即可。

- 模型dump运行时间太长
笔者在实验室还对比了其他的模型,包括vision transformer。但是由于vision transformer太大,导致运行时间过长。
会在pb gdb dump过程中卡很长时间,请耐心等待,或者手动实现dump。
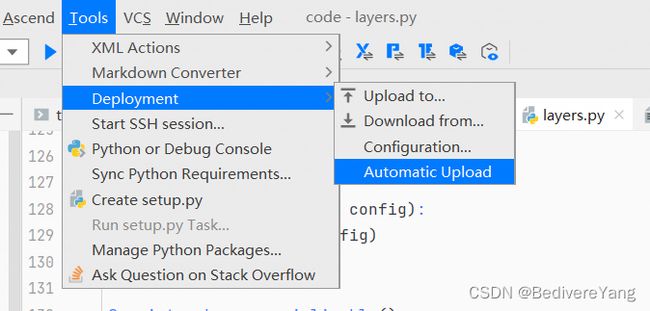
- MindStudio 本地与远程同步时等待时间较长问题
不要同步较大的文件,不要设置tools工具栏里面的automatic upload.
一些开发建议
针对不同的问题,采用的不同的方式。以下是笔者针对加速推理方法和精度差异大问题的建议:
- 如果pb和om结果差异很大(如pb模型的精度为80%,om模型类似随机结果),则可能是前处理或者后处理除了问题。注意查看预处理是否对齐,转成bin文件时是否按照输入要求的格式保存,后处理读取bin文件或者txt文件是否发生精度溢出/不足的情况;
- 如果pb和om结果相差不大,而且om每次都劣于pb模型,则应该注意ATC转换时是否强制转换为fp16,可以通过设置precison_model为fp32或者allow fp32 to fp16提升模型的参数精度(笔者团队中Animate gan出现了这个问题,强制使用fp32的精度结果就正常了。) ;
- 为了加速推理性能,可以使用auto tune对模型做进一步图优化;
- 处于更好地在边缘设备上使用模型,建议使用量化模型。Ascend支持int8量化,具体可以参考 量化 - CANN 5.0.1 Ascend Graph开发指南 01 - 华为。
一些文档
华为文档:
华为 Ascend int8 量化工具:
量化 - CANN 5.0.1 Ascend Graph开发指南 01 - 华为
华为Ascend ATC工具介绍:
运行流程 - CANN 5.0.4 ATC工具使用指南 01 - 华为
MindStudio 工具安装使用指南:
https://support.huaweicloud.com/devg-MindStudio304/atlasms_02_0023.html
华为Ascend实验室网络连接指南:
guide/common/tutorials/昇腾生态众智实验室网络连接指导.md · Ascend/docs-openmind - Gitee.com
一键对比工具使用指南:
tools: Ascend tools - Gitee.com
AI编译器综述: The Deep Learning Compiler: A Comprehensive Survey
https://arxiv.org/abs/2002.03794