1 传统方式的缺点
使用索引的方式无法表达词之间的相似性,n元模型在很多场合难以取得明显的进步和表现。one-hot存在维度方面的问题以及无法表示词和短语之间的相似性。
WordNet:
WordNet是一个由普林斯顿大学认识科学实验室在心理学教授乔治·A·米勒的指导下建立和维护的英语字典。开发工作从1985年开始,从此以后该项目接受了超过300万美元的资助(主要来源于对机器翻译有兴趣的政府机构)。
由于它包含了语义信息,所以有别于通常意义上的字典。WordNet根据词条的意义将它们分组,每一个具有相同 意义的字条组称为一个synset(同义词集合)。WordNet为每一个synset提供了简短,概要的定义,并记录不同synset之间的语义关系。
WordNet(NLTK自带)的开发有两个目的:
它既是一个字典,又是一个辞典,它比单纯的辞典或词典都更加易于使用。
支持自动的文本分析以及人工智能应用。
WordNet的数据库及相应的软件工具的发放遵照BSD许可证书,可以自由的下载和使用,亦可在线查询和使用。
2 CBow连续词袋模型(周围词预测中心词)、SkipGram 中心词预测周围词
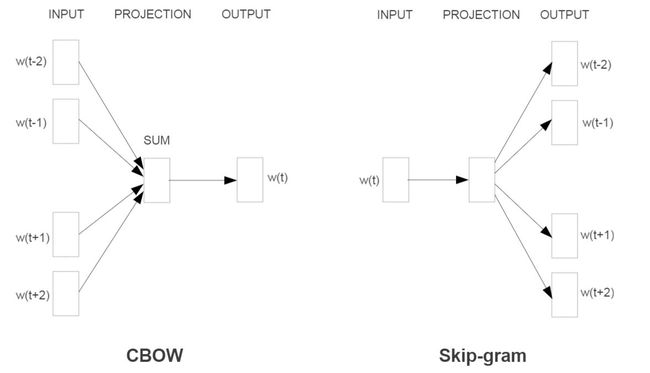
3 参考知识点
霍夫曼树
给定n个权值作为n个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)
设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
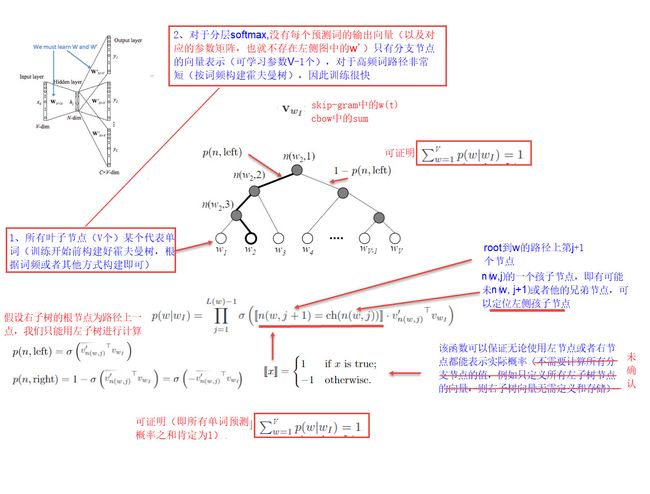
负采样
传统的方法每次更新全部权重的方式进行更新,与传统方式不同,负采样采用一次采样一个正样本多个负样本的方式,训练目标简化为以下公式(作者认为该方式也能产生高质量的词嵌入),每次只更新部分向量:
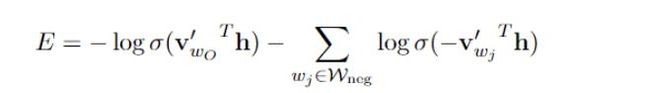
$其中w_{O}是输出词(比如说正样本),v^_{wo}是输出向量, h表示的是隐藏层(project)的输出向量, v^_{wi}是负采样的输出向量。$
另外对于词的采样(尤其是高频词如the(中文‘的’)等类似的词),采用以下方式来进行平衡(噪声分布的情况另外一篇论文详细提到未读)
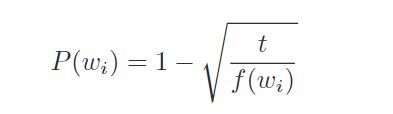
$其中f(w_{i})是词频,t是一个阙值$
4 词嵌入训练/加载等
词嵌入的加载方式出了embedding层、使用数据库、gensim(未验证)外,暂未查到能够有效减少内存消耗的方式。
5 参考文章
- Word2Vec Tutorial - The Skip-Gram Model
- Efficient Estimation of Word Representations in Vector Space(original word2vec paper)
- Distributed Representations of Words and Phrases and their Compositionality (negative sampling paper)
- word2vec Parameter Learning Explained
- Word Embeddings with Limited Memory
文章笔记:Efficient Estimation of Word Representations inVector Space
阅读摘要:
- 数据集16亿词汇量,语法和语义相似性方面达到领先水平
- NNLM(已经有很多研究)
- 单词的连续线表示方式:LSA,LDA(大型数据集对算力需求非常庞大)
- 比较不同模型结构的策略:计算复杂度-参数量,最大化准确率,最小化计算复杂度
- 模型训练复杂度定义为O=E(训练迭代次数) x T(训练集词汇量) x Q(根据模型结构定义)
- NNLM网络结构由输入(N个前面的单词one-hot)、映射层(NXD)、隐藏层、输出层
- 使用霍夫曼树降低计算复杂度,DistBelief分布式训练(CPU)以及Adagrad自适应异步学习率
- 从论文提供的结果来看貌似Skim-gram在大多数情况下优于Cbow
文章笔记:Distributed Representations of Words and Phrasesand their Compositionality
阅读摘要:
- 使用负采样,加速2-10倍,以及提高精度
- 使用NCE加速训练以及更高质量的词向量
- 使用向量来表示短语(比单个单词节省空间,且应该更加有效)
- 对词向量使用简单的数学运算能获得某些不明显的语义上的理解
- 直接使用softmax计算不太实际(词汇量太大会导致计算复杂度极高)
- 使用霍夫曼树的只需评估log2(W词汇量)个节点
- Noise Contrastive Estimation (NCE)是替代分层softmax的方法
- 使用负采样小训练集采用5-20负样本比较合适,大训练集2-5个负样本比较合适
- 使用负采样的精度较霍夫曼的方法有较大提升