个人整理。
1.摘要
simplex:提出了余弦对比损失(CCL),并将其进一步合并到一个简单的统一CF模型,称为simplex。
许多最近基于GNN的研究对BPR损失进行了实验,并将负采样率设置为一个较小的值(每个正用户采样1或10个负样本一对),这样可以证明他们提出的交互编码器的优越性,但他们忽略了损失函数和负采样在CF模型学习中的重要性。使用BPR损失和较小的负采样率进行训练会导致许多CF模型的效果较差。在本文中,我们表明,选择合适的损失函数和适当数量的负样本比交互编码器起着同等或更重要的作用。
CCL损失通过最大化正用户项目对的余弦相似度来优化嵌入,同时将负用户项目对的相似度最小化到一定的余量。
借鉴了一些已有的研究成果:youtubenet中的平均池化,ACF中的注意力。我们将simplex构建为集成矩阵分解和用户行为建模的统一模型。具体来说,它包括一个行为聚合层(平均池化),从历史交互的项目中获取用户的偏好向量,然后通过加权和与用户嵌入向量融合。simplex通过我们的CCL损失和较大的负采样率进行了优化,它可以作为一个超强的基线模型,并且由高效率而具有巨大的工业应用潜力。
2.相关工作
CF:我们将重点放在隐式CF上,(从隐式反馈数据如点击,访问,购买中学习。)对CF模型学习有重要影响的三个方面:
1.交互编码:学习每个用户和每个项目的嵌入,这些嵌入捕获交互矩阵中反映用户之间行为相似性的协作信号。
2.损失函数:CF常见的损失函数:二元交叉(BCE)和均方误差(MSE)将学习过程视为二分类或回归任务。BPR成对损失被优化,使得正用户-项目对的相似度大于负用户-项目对。
3.负采样:进行负采样来提高训练效率。
3.模型
CCL余弦对比损失:给定一个正用户-项目对(u,i)和一组随机采样的负样本(i.e,N),CCL损失如下:
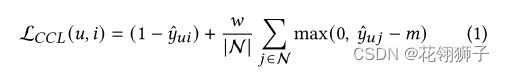
y是计算用户和项目表示向量之间的余弦相似度。N代表负样本数,m是用来过滤负样本的边距,通常设为0-1。CCL被优化为最大化正对之间的相似度,最小化边缘以下的负对相似度。m,w是超参来控制正样本损失和负样本损失的相对权重。
首先,我们不使用点积(例如lightgcn)或者欧氏距离(CML)来度量用户-项目之间的相似度,而是选择计算他们之间的余弦相似度,通过对两个表示向量进行L2归一化,余弦相似度只计算角度差,从而避免了表示量的影响。这是有利的,因为用户/项目表示的大小可能会因其在CF任务中的受欢迎程度而产生强烈的偏差。
其次,当负样本数较大,通常会存在大量冗余但信息不足的样本,BPR对每一个负样本都是等价的,模型可能会被这些缺乏信息的样本所淹没,降低性能。CCL使用适当的边距来过滤无信息的负样本来缓解这个问题。当无信息的负样本在边缘以下具有较小的余弦相似度时候,将在CCL中获得零损失,该算法能够自动识别余弦相似度大于m的硬负样本,从而更好的训练模型。
第三,直接求和或平均所有负样本的损失项会降低模型的性能,尤其是当负样本数较大的时候,这是由于正负样本之间的高度不平衡。我们引入了一个w来控制正负样本之间的平衡,它也达到了与加权矩阵因式分解中施加在负样本上的置信度全职类似的效果。
左边为用户向量eu,右边为经过池化后的池化向量pu
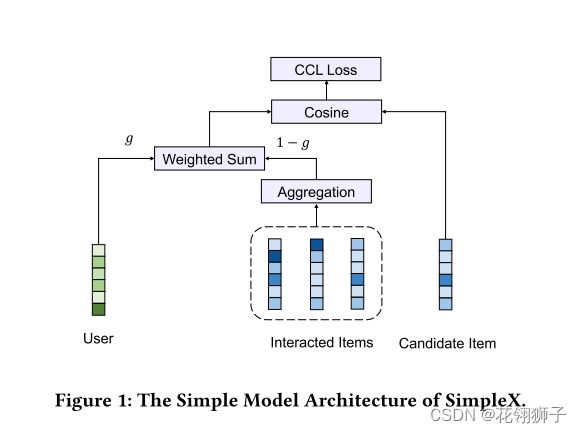
simplex:在simplex设计中,我们考虑了简单性,借鉴了youtubenet,ACF,pinsage等几个成功的模型。很大程度上遵循MF的机制,将用户和项目分解到一个公共的潜在空间中。还将每个用户的交互项目序列作为额外的输入,更好的建模用户行为。simplex的关键部分在于它的聚合层用于行为序列的聚合。
三种常见的聚合选择:平均池化,自我关注和用户关注。
假设用户u的交互项集为Hu,将其最大大小设置为K,对于具有不同大小的交互项目的用户,可以相应的填充或者分块,聚合向量:
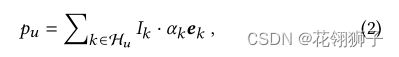
ek是项目k的d维嵌入向量,Ik表示填充期间Hu的掩码索引,Ik=0表示填充标记,否则=1。αk表示聚合权重,根据不同聚合类型计算:
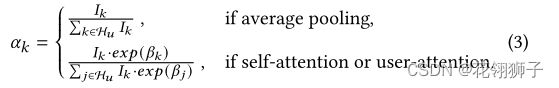
平均池化:提供了一种直接聚合交互项目的方法,但它平等对待每个项目,未能考虑不同项目的相对重要性以及用户对每个项目的偏好。
注意机制:他们的区别在于βk的计算:
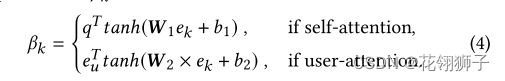
q是self-attention的可学习全局查询向量。eu是用户u在user-attention中的用户特定查询向量。W,b是可学习参数。
通过等式2进行行为聚合后,池化向量pu可能于用户向量eu位于不同的潜在空间,我们进一步融合这两部分得到最终的用户表示hu:
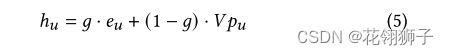
V是可学习参数,g是超参数权重,最后我们测量用户和项目之间的余弦相似度作为CCL损失的输入:

以上三个聚合层提供了不同的视图,包括全局平均视图,用户特定的加权视图,他们之间的选择非常依赖于数据。
设置g=1,基于GNN 的模型,例如在选择用户注意力聚合层时,它几乎等同于仅应用于用户节点的图形注意力(GAT)层。如果使用自注意力聚合层,工作方式类似于NIA-GCN中的邻居交互。
batchsize:1024,优化器在0.001,0..0004,0.0001]之间调整学习率,在嵌入参数上使用了L2正则化,并在1e-9~1e-2之间搜索正则化权重,增加比为5,阜阳本书选择100,500,1000.margin在0~1之间以0.1间隔体哦阿正,amazon-book0.4,yelp0.9,gowalla0.9.
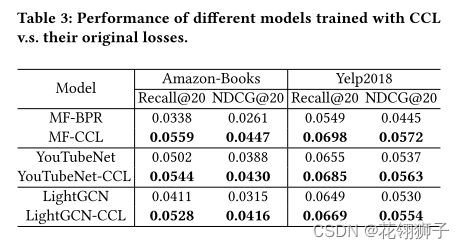
BPR只在gowalla表现强劲,在amazon-book和yelp上表现不佳,表明使用BPR训练可能不是最优的。
为什么CCL损失表现好?
CCL可以通过其边际机制自动过滤掉模型难以区分(即余弦相似度大)的硬负样本。如m设为0.8,只有余弦相似度>0.8的负对会导致损失。CCL允许模型强调对硬负样本的学习,从而生成更具判别性的表示。
PHL损失由正负样本之间的相对距离决定。即使负样本实际上很难区分,CCL通过惩罚每个负样本的绝对相似度y来避免。
当负样本数达到50时,PHL,MSE,BPR的性能都变得稳定。CCL,BCE,SCE随着负样本数的增加而保持性能增益。

由于YouTube net和lightgcn的编码器复杂且强大,可以学习有偏差的协作信号,相比之下损失函数对他们的影响似乎相对较小