爬了蛋卷数据,策略大赚15个点!
大家好,我是卓怡
半个月涨幅接近15个点,而我,却错过了!
事情是这样的,之前10月份的时候我就开始搭建自己的估值系统
从爬数据,到确定算法,再到最后的自动更新、定时通知,差不多到了11月中旬策略更新到了第二版。
没想到,更新后的第一天,就收到了系统的通知:恒生指数加权、等权历史百分位双双超级低估
因为模型刚开始运行,我就没当回事,现在回过头来看,真香!
下面是前后两次的对比图,最下面是策略的通知时间
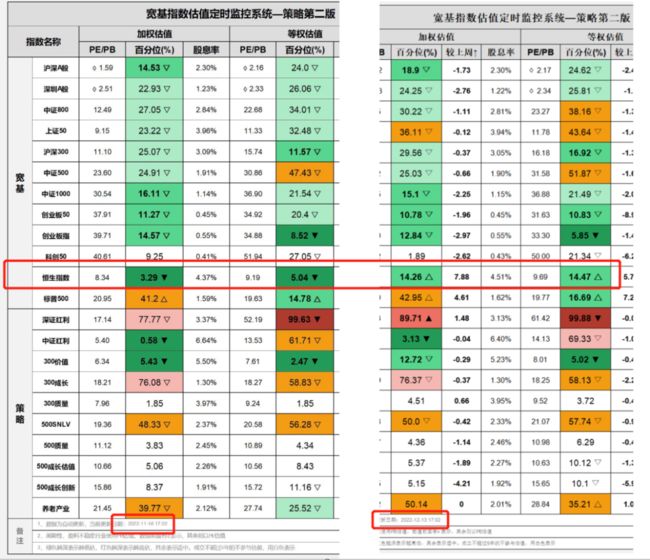
在这个期间,恒生指数ETF涨了14个点,区间最大涨幅超过15%,而且这还仅仅是在大半个月之内!
如果再算上之前的涨幅,妥妥的20个点往上了
哎,错过了

不过后面要是还有双双低估的宽基指数,我肯定要杀进去的
话说回来,前面一直在给大家介绍指数低估,今天就来教大家如何快速爬取指数估值数据
非常简单,而且代码运行起来也很快,基本上1秒之内就能搞定所有数据!
ok,先给一个使用说明,源码和逻辑见后文
1、核心代码
首先是创建一个文件夹,用于存放每天的估值数据:
我这边直接用蛋卷估值来命名
dirpath = "蛋卷估值"
if not os.path.exists(dirpath):
os.mkdir(dirpath)
print('[ 提示 ]: 创建文件夹 {0} 成功,爬取报告中...'.format(dirpath))其次通过爬取蛋卷估值的网页,获取最新估值数据
网页比较简单,不涉及一些反爬的内容,具体后面会有说到
""" ②爬取数据 """
df_data = get_index_val_info()
print('======>> 爬取完成,处理数据中......')
最后是对数据进行处理,用自己的估值标准对最新数据进行评估
并将处理后的数据存到本地文件中:
""" ④导出成本地 """
df_data_res = process_df(df_data)
save_filepath = os.path.join(dirpath, datetime.now().strftime('%Y-%m-%d') + '.xlsx')
df_data_res.to_excel(save_filepath, index=False)
print('======>> 处理完成,已导出本地:{0}'.format(save_filepath))
程序运行图如下:

最终爬取的业绩快报结果如下:

12月13号共有64条估值数据
2、爬虫思路
获取源码文件请直接在后台回复 蛋卷估值
目前来说,官方还是免费提供接口的,后续如果官方做了优化,可能代码会不适用。所以大家先到先得,后面如果有问题我就不再免费维护啦。

首先,之前写过一篇文章,专门剖析过5种常见的指数估值算法(文章后来我主动删了),所以估值算法这块就不再提了。需要说明一点的是,各大网站的数据基本都一样,有差别的是估值算法。
目前只有蛋卷的数据是比较容易拿到的,所以今天的教程也是基于它实现的。
对了,我目前用的不是蛋卷,因为毕竟它只展示了常见的几种指数,数据不全,可能会影响到我的判断。后面有机会我再给大家介绍我用的平台
先打开蛋卷估值的页面,是这样的:

可以看到对应的常见指数估值数据都在上面,有指数名称、类型、PE、PE百分位、PB和PB百分位
甚至ROE和股息率也都有,感兴趣的可以多拓展一下,这两个也可以挖出很多策略来。
当然了,这两个不是我们今天的重点
浏览器打开 F12,定位到对应的源码上
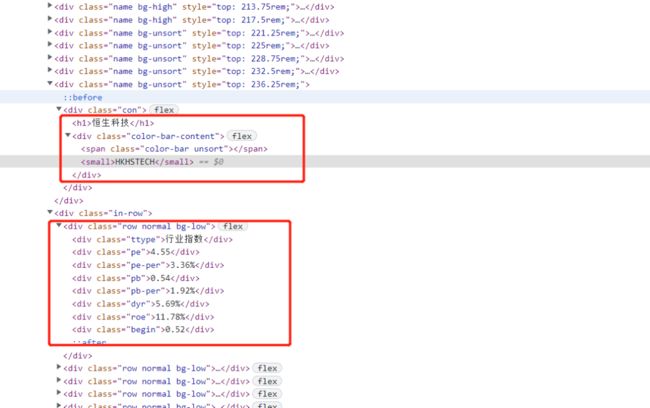
数据被分成了两部分,并不是想象中一条数据一个div
不过,细心点的同学应该在刷新的时候会发现,有一个Name为dj的请求,如下:
切到Preview,可以看到它的返回结果竟然是真个数据集
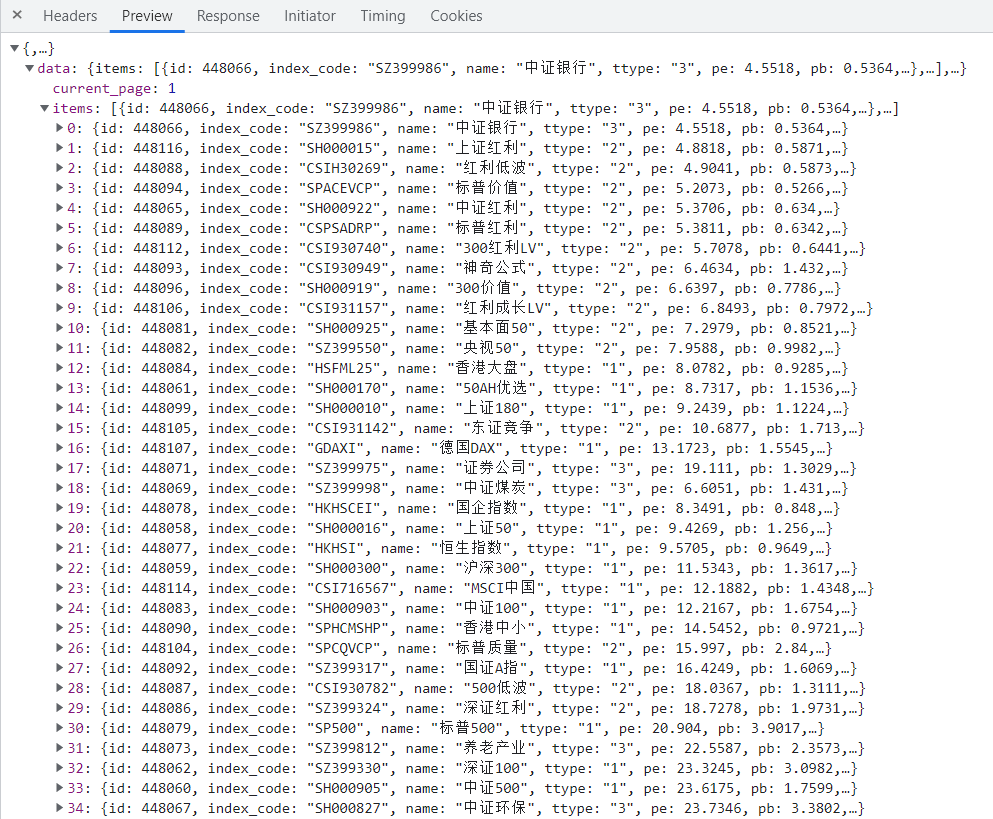
ok,那其实目的就很明确了,通过访问这个链接拿到最新的数据即可
因为不涉及到二级数据的获取,所以,其实真正的数据爬取一步就可以到位
核心代码如下:
index_eva = json.loads(response.text)
# 将json数据生成DataFrame
df_index_eva = pd.json_normalize(index_eva['data']['items'])
然后是将对数据进行处理,例如:将自己的评估算法应用到数据中,设置相应的数据辅助列等。
部分代码如下:
# 添加数据
df_data.loc[df_data['指数名称'] == row['指数名称'], 'PE/PB'] = pe_pb
df_data.loc[df_data['指数名称'] == row['指数名称'], '百分位(%)'] = pe_pb_ratio
df_data.loc[df_data['指数名称'] == row['指数名称'], '估值'] = eva_type
以上是核心源码,这里省去了非核心部分,需要请查看源码文件。