机器学习收入阶层分类(python)
文章目录
- 相关文件
- 一.数据说明
- 二.特征工程
-
- 2.1导入相关包
- 2.2导入数据
- 2.3资本收入-资本支出构造新的feature
- 2.4将数据中的非数字数据类型转化为数值型数据。
- 2.5发现数据中存在很多的"?"需要进行填充。
-
- ①工作类型:采用决策树进行模型预测
- ②国籍直接填充众数
- ③职业采用决策树进行模型预测
- 2.6对离散型数据进行划分区间
- 三.对于test数据进行同步映射处理
- 四.进行模型的训练
-
- 4.1划分训练集和测试集
- 4.2集成模型:XGB
- 4.3集成模型:adaboost
- 4.4集成学习:stacking
- 五.对test数据集进行预测并输出测试结果
相关文件
机器学习收入阶层分类相关文件 提取码:zxcv
一.数据说明
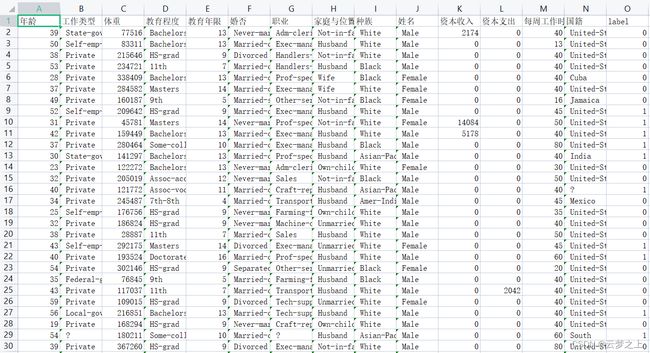
数据提供了30000多个包括 “年龄 工作类型 体重 教育程度 教育年限 婚否 职业 家庭与位置 种族 姓名 资本收入 资本支出 每周工作时间 国籍
”等特征的样本,以识别收入阶层(1为高收入阶层,0为非高收入阶层)。提交数据时:第一例为ID, 第二例为Label (0 或1)
二.特征工程
2.1导入相关包
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import StackingClassifier
from sklearn.preprocessing import KBinsDiscretizer
import copy
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
import xgboost as xgb
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import AdaBoostClassifier
2.2导入数据
#导入训练数据
data=pd.read_csv(r'D:\Users\RK\PycharmProjects\小项目\大数据上机3\相关文件2\train.csv',encoding='gbk')
#导入测试数据
data2=pd.read_csv(r'D:\Users\RK\PycharmProjects\小项目\大数据上机3\相关文件2\test.csv',encoding='gbk')
2.3资本收入-资本支出构造新的feature
former_data=copy.deepcopy(data)
tem=former_data['资本收入']-former_data['资本支出']
data['surplus']=tem
2.4将数据中的非数字数据类型转化为数值型数据。

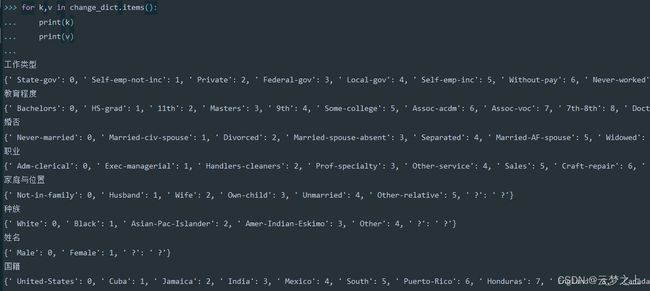
cat_cols = [col for col in data.columns if data[col].dtype == 'O']
da=data[cat_cols]
#对训练数据进行处理,输出替换的映射的字典
##########################
change_dict={}
for i in cat_cols:
tem = da[i].unique().tolist()
tem1=[i for i in tem if i!=' ?']
tem2 = list(np.arange(0, len(tem1), 1))
tem1.append(' ?')
tem2.append(' ?')
da[i]=da[i].map(dict(zip(tem1,tem2)))
change_dict[i]=dict(zip(tem1,tem2))
data[cat_cols]=da
2.5发现数据中存在很多的"?"需要进行填充。
[i for i in data.columns if sum(data[i]==' ?')>0]

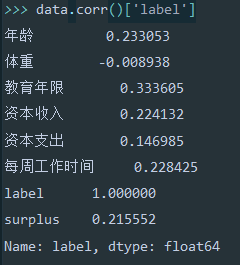
查看数据与label的相关系数,对相关系数低的进行众数填充,对相关系数高的进行模型预测。
①工作类型:采用决策树进行模型预测
#####进行?的填充######################################################################
train_data=data.loc[(data['工作类型']!=' ?')]
need_change_job_data = data.loc[(data['工作类型']==' ?')]
train_x = train_data[['年龄','教育程度','教育年限','婚否','家庭与位置','资本收入']]
train_y=train_data['工作类型']
# for i in train_x.columns:
# print((train_x[i] == ' ?').value_counts())
# need_change_job_data = need_change_job_data[['年龄','教育程度','教育年限','婚否','家庭与位置','资本收入']]
# for i in need_change_job_data.columns:
# print((need_change_job_data[i] == ' ?').value_counts())
need_change_job_data = need_change_job_data[['年龄','教育程度','教育年限','婚否','家庭与位置','资本收入']]
RFR = RandomForestClassifier(n_estimators=1000, n_jobs=-1)
train_y=train_y.astype(int)
train_x=train_x.astype(int)
RFR.fit(train_x,train_y)
predictAges = RFR.predict(need_change_job_data)
data.loc[(data['工作类型']==' ?'),'工作类型']= predictAges
##########################################################输出的预测模型RFR
②国籍直接填充众数
#国籍直接填充众数
train_data1=data.loc[(data['国籍']!=' ?')]
predictAges2=int(train_data1['国籍'].mode())
data.loc[(data['国籍']==' ?'),'国籍']= predictAges2
# fill_list=[ i for i in data.columns if (data[i]==' ?').value_counts().loc[False]!=29999]
# for i in fill_list:
# print((data[i] == ' ?').value_counts())
##############################输出的众数 predictAges2
③职业采用决策树进行模型预测
##职业##################################################33
train_data3=data.loc[(data['职业']!=' ?')]
need_change_job_data3 = data.loc[(data['职业']==' ?')]
train_x3 = train_data3[['年龄','教育程度','教育年限','家庭与位置','资本收入','姓名','国籍']]
train_y3=train_data3['职业']
need_change_job_data3 = need_change_job_data3[['年龄','教育程度','教育年限','家庭与位置','资本收入','姓名','国籍']]
RFR3 = RandomForestClassifier(n_estimators=1000, n_jobs=-1)
train_y3=train_y3.astype(int)
train_x3=train_x3.astype(int)
RFR3.fit(train_x3,train_y3)
predictAges3 = RFR3.predict(need_change_job_data3)
data.loc[(data['职业']==' ?'),'职业']= predictAges3
########################################################预测模型3 predictAges3
2.6对离散型数据进行划分区间
#二阶段映射
###############################################333
x=data[['年龄', '工作类型', '体重', '教育程度', '教育年限', '婚否', '职业', '家庭与位置', '种族', '姓名',
'资本收入', '资本支出', '每周工作时间', '国籍', 'surplus']]
y=data['label']
change_dict_2={}
need_change=[i for i in x.columns if x[i].var()>100]
for i in need_change:
if i=='年龄':
est=KBinsDiscretizer(n_bins=8, strategy='uniform',encode='ordinal')#'uniform
elif i=='每周工作时间':
est = KBinsDiscretizer(n_bins=10, strategy='kmeans', encode='ordinal') # 'uniform
elif i=='资本收入':
est = KBinsDiscretizer(n_bins=10, strategy='kmeans', encode='ordinal') # 'uniform
elif i=='体重':
est = KBinsDiscretizer(n_bins=10, strategy='kmeans', encode='ordinal') # 'uniform
elif i=='资本支出':
est = KBinsDiscretizer(n_bins=10, strategy='kmeans', encode='ordinal') # 'uniform
elif i=='surplus':
est6 = KBinsDiscretizer(n_bins=10, strategy='kmeans', encode='ordinal') # 'uniform
est.fit(np.reshape(x[i].to_list(),(-1,1)))
after=est.transform(np.array(x[i]).reshape(-1,1))
change_dict_2[i]=est.bin_edges_.tolist()
after_data=[i[0] for i in after.data.tolist()]
#pd.DataFrame({'1':after_data})['1'].unique()
x[i]=after_data
################################################################
处理完后数据

三.对于test数据进行同步映射处理
####################################33
#对于test数据进行同步映射处理
former_data2=copy.deepcopy(data2)
tem2=former_data2['资本收入']-former_data2['资本支出']
data2['surplus']=tem2
##一步映射
for k,v in change_dict.items():
data2[k]=data2[k].map(v)
test填充“?
##填充“?”################
test_need_change_job_data = data2.loc[(data2['工作类型']==' ?')]
test_need_change_job_data = test_need_change_job_data[['年龄','教育程度','教育年限','婚否','家庭与位置','资本收入']]
test_predictAges = RFR.predict(test_need_change_job_data)
data2.loc[(data2['工作类型']==' ?'),'工作类型']= test_predictAges
##########################################################输出的预测模型RFR
#国籍直接填充众数
data2.loc[(data2['国籍']==' ?'),'国籍']= predictAges2
##职业##################################################33
test_need_change_job_data3 = data2.loc[(data2['职业']==' ?')]
test_need_change_job_data3 = test_need_change_job_data3[['年龄','教育程度','教育年限','家庭与位置','资本收入','姓名','国籍']]
test_predictAges3 = RFR3.predict(test_need_change_job_data3)
data2.loc[(data2['职业']==' ?'),'职业']= test_predictAges3
test 二阶段转化
#test 二阶段转化
#######################################################################
for j,k in change_dict_2.items():
k=k[0]
for m in range(len(k)-1):
n=m+1
if m==(len(k)-2):
data2.loc[k[m] < data2[j] ,j] = m
data2.loc[(k[m]<=data2[j] )& (data2[j]<k[n]),j]=m
#data2.to_csv(r'D:\Users\RK\PycharmProjects\小项目\大数据上机3\相关文件\test_after_transform.csv')
转化后数据

四.进行模型的训练
4.1划分训练集和测试集
x=x.astype(int)
x=x[['年龄', '工作类型', '教育程度', '教育年限', '婚否', '职业', '家庭与位置', '种族', '姓名',
'资本收入', '资本支出', '每周工作时间', 'surplus']]
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=25)
4.2集成模型:XGB
###########################33
params_2 = {
'learning_rate':[0.13],#np.arange(0.01,0.18,0.03),
'max_depth': [8],#np.arange(3,10,1),
'alpha': [3],#np.arange(1,10,1),
'booster': ['gbtree'],
'objective': ['binary:logistic'],
}
result_2 = GridSearchCV(xgb.XGBClassifier(), param_grid=params_2, cv=4,scoring='f1')
train = [x_train, y_train]
eval = [x_test, y_test]
result_2.fit(x_train, y_train,eval_metric=['logloss','auc','error'],eval_set=[train,eval])
best2_para=result_2.best_params_
print('best_paramas:',best2_para)
print(classification_report(y_test,result_2.predict(x_test)))

4.3集成模型:adaboost
params_3 = {
'learning_rate':[0.81],#np.arange(0.01,1.0,0.1),#np.arange(0.01,1.0,0.1),
'n_estimators':[60]#np.arange(30,70,10),#np.arange(30,70,10)
}
adab=AdaBoostClassifier(random_state=0)
ada = GridSearchCV(adab, param_grid=params_3, cv=4)
ada.fit(x_train, y_train)
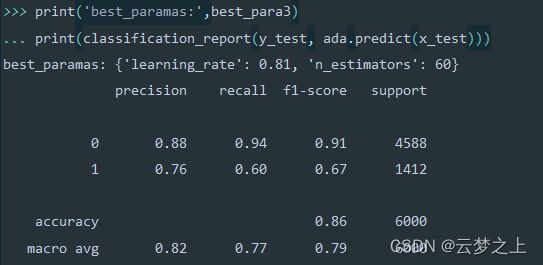
best_para3=ada.best_params_
print('best_paramas:',best_para3)
print(classification_report(y_test, ada.predict(x_test)))
4.4集成学习:stacking
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.1,random_state=17)
models=[('xgb',xgb.XGBClassifier(learning_rate=0.13,max_depth=8,alpha=3)),('rf',make_pipeline(StandardScaler(),RandomForestClassifier(n_estimators=9,max_depth=4,min_samples_split=7)))
,('adaboost',AdaBoostClassifier(random_state=0,learning_rate=0.81,n_estimators=60))]
reg = StackingClassifier(estimators=models)
reg.fit(x_train,y_train)
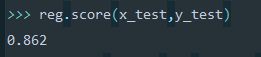
reg.score(x_test,y_test)
五.对test数据集进行预测并输出测试结果
#######test_data预测
te=data2[['年龄', '工作类型', '教育程度', '教育年限', '婚否', '职业', '家庭与位置', '种族',
'姓名', '资本收入', '资本支出', '每周工作时间', 'surplus']]
te=te.astype(int)
label=reg.predict(te)
pre_label=pd.DataFrame({'ID':data2['ID'],'label':label})
pre_label.to_csv(r'D:\Users\RK\PycharmProjects\小项目\大数据上机3\相关文件\pre_label2.csv')