“泰迪杯”数据分析职业技能大赛 B 题 新冠疫情数据分析
参考:python数据分析案例简单实战项目(二)–新冠疫情数据分析
采用工具软件:pycharm(数据处理),tableau(可视化)
数据:“泰迪杯”数据分析职业技能大赛 B 题 新冠疫情数据分析
数据+生成数据: 提取码:zxcv
任务一:数据的基本处理
任务 1.1
根据附件 1“城市疫情”中的数据统计各城市自首次通报确诊病
例后至 6 月 30 日的每日累计确诊人数、累计治愈人数和累计死亡人数,将结果
保存为“task1_1.csv”,第一行为字段名,按城市、日期、累计确诊人数、累计
治愈人数、累计死亡人数的次序分别放在 A 列~E 列。在论文中给出实现方法的
相关描述,并列表给出武汉、深圳、保定每月 10、25 日的统计结果。
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月06日
import pandas as pd
data = pd.read_excel(r"D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\新冠疫情分析数据.xlsx",header =0,)#导入数据
df=data.copy()
df.rename(columns={'新增确诊':'累计确诊人数','新增治愈':'累计治愈人数','新增死亡':'累计确诊死亡'},inplace=True)
index = pd.date_range('20200110','20200630')#创建日期索引
city_list=df['城市'].value_counts().index.to_list()
count=0
for i in city_list:
da=df[df['城市']==i]
da = da.set_index('日期').reindex(index, fill_value=0) # 进行日期的补全
da['城市'] = i # 补全城市列数据
da = da.rename_axis('日期').reset_index() # 保留日期列
da['累计确诊人数'] = da['累计确诊人数'].cumsum() # 累加
da['累计治愈人数'] = da['累计治愈人数'].cumsum() # 累加
da['累计确诊死亡'] = da['累计确诊死亡'].cumsum() # 累加
list2 = ['武汉', '深圳', '保定']
if i in list2:
tem_15=[]
tem_25=[]
for i in range(1, 7):
# tem_15.append( da[da['日期'] == f"2020-0{i}-10"])
# tem_25.append(da[da['日期'] == f"2020-0{i}-25"])
tem_15.append(da[da['日期'] == f"2020-0{i}-10"].index.to_list()[0])
tem_25.append(da[da['日期'] == f"2020-0{i}-25"].index.to_list()[0])
print(da.loc[tem_15, :])
print(da.loc[tem_25, :])
da = da.set_index("城市") # 将城市作为索引 存入csv是第一行便是城市
if count == 0:
da.to_csv(r"C:\Users\yunmeng\Desktop\task1_1.csv", index=True, na_rep='0', encoding='utf-8',mode = 'a')#写入csv文件,包括表头和索引 encoding需要用GB18030否则文字乱码
else:
da.to_csv(r"C:\Users\yunmeng\Desktop\task1_1.csv", index=True, header=None, na_rep='0', encoding='utf-8',
mode='a') # 追加写入,不包括表头
count+=1
任务 1.2
根据任务 1.1 的结果,并结合附件 1“城市省份对照表”统计各省
级行政单位按日新增和累计数据,将结果保存为“task1_2.csv”,第一行为字段
名,按省份、日期、新增确诊人数、新增治愈人数、新增死亡人数、累计确诊人
数、累计治愈人数、累计死亡人数的次序分别放在 A 列~H 列。在论文中给出实
现方法的相关描述,并列表给出湖北、广东、河北每月 15 日的统计结果。
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月07日
import pandas as pd
index = pd.date_range('20200110','20200630')
city_data = pd.read_excel(r"D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\相关文件\新冠疫情分析数据.xlsx", header=0,sheet_name=1) # 导入数据 sheet_name=1读取第二张表
df = pd.read_excel(r"D:\Users\RK\PycharmProjects\数据分析\泰迪\相关文件\新冠疫情分析数据.xlsx", header=0) # 导入表1数据 每日数据
list_keys = city_data['城市'].to_list() # 存储key
list_values = city_data['省份'] # 存储value
city_dic=dict(zip(list_keys,list_values))
df['城市']=df['城市'].map(city_dic)
city_list=df['城市'].value_counts().index.to_list()
df.rename(columns={'城市':'省份'},inplace=True)
province_list=df['省份'].value_counts().index.to_list()
count=0
for i in province_list:
da=df[df['省份']==i]
da=da.groupby('日期', as_index=False).sum()
da = da.set_index('日期').reindex(index, fill_value=0) # 进行日期的补全
da['省份'] = i # 补全城市列数据
da = da.rename_axis('日期').reset_index() # 保留日期列
da['累计确诊人数'] = da['新增确诊'].cumsum() # 累加
da['累计治愈人数'] = da['新增治愈'].cumsum() # 累加
da['累计确诊死亡'] = da['新增死亡'].cumsum() # 累加
list2 = ["湖北","广东","河北"]
if i in list2:
tem_15=[]
for i in range(1, 7):
tem_15.append(da[da['日期'] == f"2020-0{i}-15"].index.to_list()[0])
print(da.loc[tem_15, :])
da = da.set_index("省份") # 将城市作为索引 存入csv是第一行便是城市
if count == 0:
da.to_csv(r"C:\Users\yunmeng\Desktop\task1_2.csv", index=True, na_rep='0', encoding='utf-8',mode = 'a')#写入csv文件,包括表头和索引 encoding需要用GB18030否则文字乱码
else:
da.to_csv(r"C:\Users\yunmeng\Desktop\task1_2.csv", index=True, header=None, na_rep='0', encoding='utf-8',
mode='a') # 追加写入,不包括表头
count+=1
任务 1.3
根据任务 1.2 的结果,统计各省级行政单位每天新冠病人的住院
人数,将结果保存为“task1_3.csv”,第一行为字段名,按省份、日期、住院人
数的次序分别放在 A 列~C 列。在论文中给出实现方法的相关描述,并列表给出
湖北、广东、上海每月 20 日的统计结果
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月08日
import pandas as pd
df=pd.read_csv(r"C:\Users\yunmeng\Desktop\泰迪标准代码文件\新冠B\task1_2.csv",sep=",")
data=df[['省份','日期']]
data['在院人数']=(df['累计确诊人数']-df['累计治愈人数']-df['累计确诊死亡'])
list2 = ["湖北","广东","上海"]
for j in list2:
tem_20 = []
da=data[data['省份']==j]
for i in range(1, 7):
tem_20.append(da[da['日期'] == f"2020-0{i}-20"].index.to_list()[0])
print(da.loc[tem_20, :])
data.to_csv(r"C:\Users\yunmeng\Desktop\task1_3.csv", index=False, na_rep='0', encoding='utf-8',mode = 'a')#写入csv文件,包括表头和索引
任务 1.4
假设新冠病人的传播半径为 1 km,根据附件 1“A 市涉疫场所”
在平面图中分别绘制该市第 6 天和第 10 天的疫情传播风险区域,并在论文中给
出分析和实现过程。

任务 2 数字大屏设计
任务 2.1
设计数字大屏,展示国内新冠疫情汇总概要信息、时空变化情况、
重点关注区域等。在论文中附上截图,并给出相关的设计思路。
可以看到湖北省每月的每日在院人数情况,在2月份开始急剧上升,3月份开始急剧下降说明3月份采取的措施十分有效
任务 2.2
设计数字大屏,展现并分析国际疫情态势和发展变化。在论文中
附上截图,并给出相关的分析和设计思路。
任务 3 国际疫情的发展分析

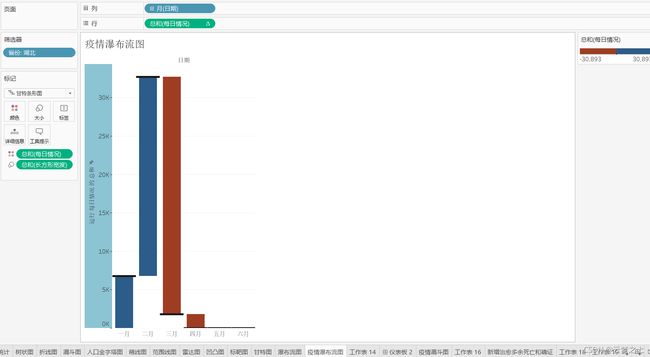
从漏斗图中可以看出:
在3月份期间,确诊人数到治愈人数的转化率开始急剧上升,说明在在此期间的治疗效果是最好的。
同时,死亡转化率平缓上升,说明,控制的还算不错。
任务 3.1
根据附件 1“国际疫情”中的数据,对印度、伊朗、意大利、加
拿大、秘鲁、南非在各个时间段中所处的疫情发展阶段进行划分,并在论文中给
出划分的依据和结果。
意大利的情况:
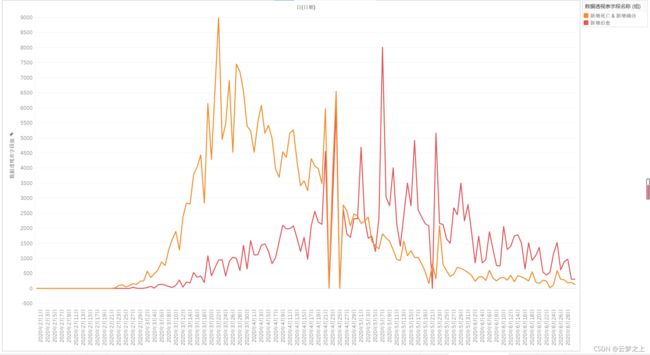
任务 3.2
根据附件 2 中的信息,分析美国、英国、俄罗斯 3 个国家推出的
疫情防控措施对本国疫情变化情况的影响

俄罗斯的情况: