利用 AI 强化学习算法,训练50级比卡超,单挑70级超梦!


作者 | Michael Ip
责编 | 寇雪芹
出品 | AI 科技大本营(ID:rgznai100)
强化学习(Reinforcement Learning, RL),是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
OpenAI Gym是一款用于研发和比较强化学习算法的工具包,它支持训练智能体(agent)做任何事——从行走到玩Pong或围棋之类的游戏都在范围中。这次我会仿照Gym的游戏模式,再根据pokemon官网给出的战斗数据,创建一个pokemon的对战系统, 再利用强化学习训练50级比卡超单挑70级超梦。如果之前有玩开gym的CartPole, MonuntainCar…的同学, 可以直接用你们的算法套入这个环境。
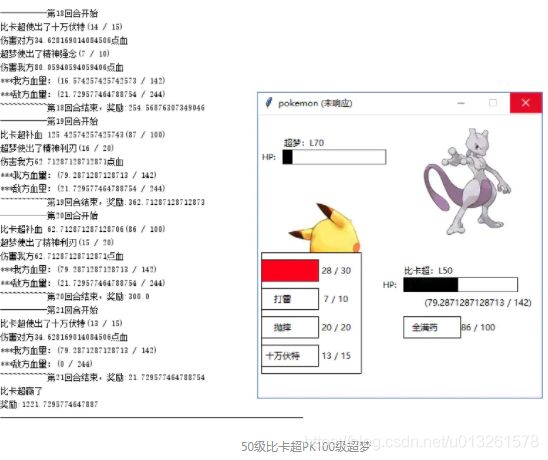
先看下效果:

环境:
python3.6
window10
tensorflow-2.4.1
需要的文件:
https://github.com/MichaelYipInGitHub/pokemon_pk/
搭建对战系统:
本来想用天池杯宝可梦分析赛里面的数据,但考虑到我要训练的是50级的比卡超和70级超梦,属性更高,所以官网上搜索比卡超和超梦的对应属性。
首先看看相克图

从相克图看出超能力对电,或是电对超能力都是1比1。这里可以放心不考虑他们的相克属性和特殊属性。
看看相关属性:

比卡超属性:
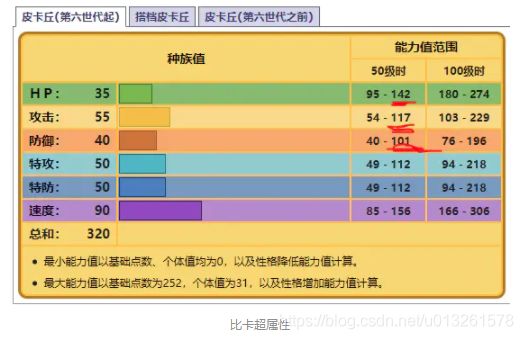
这里比卡超有四招:‘电击’, ‘打雷’, ‘抛摔’, ‘十万伏特’

超梦也有四招, 都是攻击为主:‘念力’, ‘精神利刃’, ‘精神强念’, ‘精神击破’

招式伤害计算公式:

攻击与防御 分别是攻击方的攻击或者特攻(取决于是物理招式、特殊招式或特殊情况),和防守方的防御或特防(取决于招式是物理招式、特殊招式或特殊情况)。这里简单点,because超能力对电都是1:1, 这里不考虑加成。下面是计算伤害的函数:
def get_hurt(self, level, my_attack, enemy_defend, power):
hurt = ((2 * level + 10) / 250) * (my_attack / enemy_defend) * power + 2
return hurt
利用tkinter创建画布:

这里的奖励机制是:
我伤害对方的血量 - 对方伤害我的血量
我赢了加1200分
我输了减1200分
这里的观测值有7个,分别是:
1.自己的血量
2.敌人的血量
3.招式一可使用次数
4.招式二可使用次数
5.招式三可使用次数
6.招式四可使用次数
7.补血可使用次数
可以选择action有5个,分别是:
1.招式一
2.招式二
3.招式三
4.招式四
5.补血
环境全部代码(pokemon_env.py):https://github.com/MichaelYipInGitHub/pokemon_pk/tree/main/com.michaelip.pokemon/pokemon_env.py
这里为什么将招式可用次数也归为观察值?因为当招式用完后如何处理,他是不能再出招了。
我一开始想法是, 一个招式(比如打雷)的次数用完后,直接从神经网络输出的神经元抽掉一个,其他权重和偏差保持不变。但后来发现操作很复杂, 如果算法不是神经网络, 是一个table的话, 可能容易操作一下, 但涉及神经元后就比较麻烦, 如果有哪位同学知道如何抽掉输出神经元而又保持其他权重和偏差不变的可以私信我讨论下。
这里我这样处理,如果招式用完后算法还是选中这个action的话,我会让这回合的奖励为0,没有奖励,让算法继续选一个action。同时招式的剩余数量也纳入观察值,意思是给机器知道,这招等于0了,后面再怎么使用这个action,reward都是0。
本来也写了一个对方出招的function,就是判断所有招式用完后会自己输掉, 但后面发现一个漏洞,就是比卡超一直用补血,在第六十多回合超梦就会用完所有招式而输掉,我初衷不是这样,所以这里让超梦可以无限出招,而我给出的补血药也是够用的,让算法自己找出一条最优策略。
搭建算法系统:
一开始我是考虑用DQN,或者policy gradient,或者是PPO

因为DQN是基于价值选择行为,policy gradient 和PPO都是基于策略选择对应的action。
这里我觉得DQN就够用,且对于这游戏policy gradient 可能很难收敛。
算法模型全部代码如下(RL_brain_DQN.py):
https://github.com/MichaelYipInGitHub/pokemon_pk/tree/main/com.michaelip.pokemon/RL_brain_DQN.py
这里建立两个神经网络,target_net 和 evaluate_net,两个网络结构相同,只是target网络的参数在一段时间后会被eval网络更新。
两层全连接,隐藏层神经元个数都是343个,最后先更新target_net ,用target_net - evaluate_net, 意思就是选这个action后,这个action得到的reward和之前猜测的值有何不同,用来求误差。
每200步替换一次两个网络的参数,eval网络的参数实时更新,并用于训练 target网络的用于求loss,每200步将eval的参数赋给target实现更新。
运行文件(run_this.py)全部代码:
https://github.com/MichaelYipInGitHub/pokemon_pk/tree/main/com.michaelip.pokemon/run_this.py
一开始验证环境和模型是否正确, 我们将超梦的等级调到40级, 所有招式的威力一样, 比卡超一一样, 只留一招打雷, 看最后训练出来的结果是不是每招都使用打雷。

结果:



So far so good~训练结果还是让人满意, 到后面比卡超只会用打雷,损失值也慢慢减少,基本上后面都是赢。ok, 我们恢复正常参数,让真实的50级比卡超PK 70级超梦!

对战开始:



到此为止, 50级的比卡超总算是能战胜超梦~但如果想提高胜率, 还需要增加一些优化。
Epsilon 优化:
因为我们每选一个action我都要随机判断, 随机值大于epsilon (初始设置为0.9),用随机的action, which mean百分之十的记录是在探索新路, 但随着我训练的增加,epsilon 也相应地增加, 每次增加0.0001, 也就说我的探索也逐渐减少。

# increasing epsilon
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max
奖励优化:
从数据上看, 训练模型已经可以让比卡超P赢超梦, 算是比较理想。但胜率还是不高,只有百分之十到二十, 所以我想继续优化, 于是在奖励机制上加了点逻辑, 就是血量低过63%左右, 使用补血是有奖励的, 血量高过63% ,使用招式才有奖励。因为血量低过63%很容易被超梦的大招一招毙命,所以以补血为主。所以尝试这样人为干预再看看结果。
more_reward = 0
if action == 4 and self.hp_up_current_num > 0 and (self.my_current_hp / self.my_hp) < 0.63:
more_reward = 800
elif (self.my_current_hp / self.my_hp) >= 0.63 and action in (0, 1, 2, 3):
more_reward = 800
reward = 1 * (self._my_current_hp - self.my_current_hp) - 1 * (self._enemy_current_hp - self.enemy_current_hp) \
+ more_reward
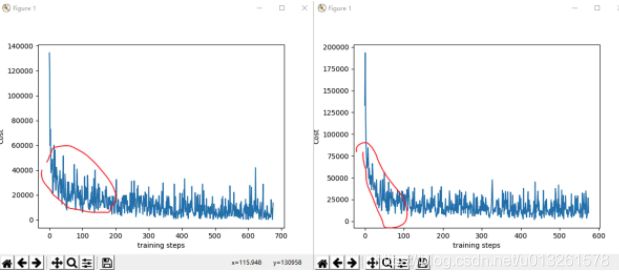
由上图所示, 左边是没加奖励干预的, 右边是加了奖励干预, 加了干预的xue微收敛得快一点(虽然不是很明显/苦笑)。
但实际胜率还是挺高的, 可以去到百分之九十!甚至百分之百!

后续
这里我只训练了400步,可以成功打赢70级超梦,胜率可以达到90%,但如果我疯狂训练,跑10万次:

但貌似跑到最后连赢都赢不了,误差还慢慢增大,我试过换成double DQN 去减少过拟合, 但效果也不太理想,训练十万步还不如几百步的训练量好, 莫非机器也闹情绪?
我也在尝试其他算法, 就像PPO, 就如我之前所料, 很难收敛, 但偏差得太厉害,有可能我参数试得不够,后续再试一试!
感谢阅读!
参考链接:
https://mofanpy.com/
https://wiki.52poke.com/wiki/%E4%B8%BB%E9%A1%B5
原文链接:
https://blog.csdn.net/u013261578/article/details/116971552
作者简介:
Michael Ip 华南理工大学硕士,现任汇丰科技有限公司高级软件工程师

更多精彩推荐 从程序媛到启明星辰集团云安全总经理,郭春梅博士揭秘云时代安全攻防之道
王炸不断,半导体巨头们到底在打什么牌?
Python 爬影评,《悬崖之上》好看在哪里?热文 | 卷积神经网络入门案例,轻松实现花朵分类点分享点收藏点点赞点在看