Mask-RCNN论文解读
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达Mask R-CNN介绍
Mask R-CNN是基于Faster R-CNN的基于上演进改良而来,FasterR-CNN并不是为了输入输出之间进行像素对齐的目标而设计的,为了弥补这个不足,我们提出了一个简洁非量化的层,名叫RoIAlign,RoIAlign可以保留大致的空间位置,除了这个改进之外,RoIAlign还有一个重大的影响:那就是它能够相对提高10%到50%的掩码精确度(Mask Accuracy),这种改进可以在更严格的定位度量指标下得到更好的度量结果。第二,我们发现分割掩码和类别预测很重要:为此,我们为每个类别分别预测了一个二元掩码。基于以上的改进,我们最后的模型Mask R-CNN的表现超过了之前所有COCO实例分割任务的单个模型,本模型可以在GPU的框架上以200ms的速度运行,在COCO的8-GPU机器上训练需要1到2天的时间。
MaskR-CNN拥有简洁明了的思想:对于FasterR-CNN来说,对于每个目标对象,它有两个输出,一个是类标签(classlabel),一个是边界框的抵消值(bounding-box offset),在此基础上,Mask R-CNN方法增加了第三个分支的输出:目标掩码。目标掩码与已有的class和box输出的不同在于它需要对目标的空间布局有一个更精细的提取。接下来,我们详细介绍Mask R-CNN的主要元素,包括Fast/Faster R-CNN缺失的像素对齐(pixel-topixel alignment)。
Mask R-CNN的工作原理
Mask R-CNN 使用了与Faster R-CNN相通的两阶段流程,第一阶段叫做RPN(Region Proposal Network),此步骤提出了候选对象边界框。第二阶段本质上就是FastR-CNN,它使用来自候选框架中的RoIPool来提取特征并进行分类和边界框回归,但Mask R-CNN更进一步的是为每个RoI生成了一个二元掩码,我们推荐读者进一步阅读Huang(2016)等人发表的“Speed/accuracy trade-offs for modern convolutional object detectors”论文详细对比Faster R-CNN和其他框架的不同。
掩码将一个对象的空间布局进行了编码,与类标签或框架不同的是,Mast R-CNN可以通过卷积的像素对齐来使用掩码提取空间结构。
ROIAlign:ROIPool是从每个ROI中提取特征图(例如7*7)的标准操作。
网络架构(Network Architecture):为了证明Mast R-CNN的普遍性,我们将Mask R-CNN的多个构架实例化,为了区分不同的架构,文中展示了卷积的主干架构(backbone architecture),该架构用于提取整张图片的特征;头架构(headarchitecture),用于边框识别(分类和回归)以及每个RoI的掩码预测。
在Faster R-CNN网络上的修改,具体包括:
(1)将ROI Pooling层替换成了ROIAlign;
(2)添加了并列的FCN层(Mask层)。
技术要点
一、增强了基础网络
将ResNeXt-101+FPN用作特征提取网络,达到State-of-the-art的效果。
二、加入了ROIAlign层
ROIPool是一种针对每一个ROI的提取一个小尺度特征图(E.g. 7x7)的标准操作,它用以解决将不同尺度的ROI提取成相同尺度的特征大小的问题。ROIPool首先将浮点数值的ROI量化成离散颗粒的特征图,然后将量化的ROI分成几个空间的小块(Spatial Bins),最后对每个小块进行Max Pooling操作生成最后的结果。
通过计算[x/16]在连续坐标x上进行量化,其中16是特征图的步长,[ . ]表示四舍五入。这些量化引入了ROI与提取到的特征的不对准问题。由于分类问题对平移问题比较鲁棒,所以影响比较小。但是这在预测像素级精度的掩模时会产生一个非常的大的负面影响。
由此,作者提出ROIAlign层来解决这个问题,并且将提取到的特征与输入对齐。方法很简单,避免对ROI的边界或者块(Bins)做任何量化,例如直接使用x/16代替[x/16]。作者使用双线性插值(Bilinear Interpolation)在每个ROI块中4个采样位置上计算输入特征的精确值,并将结果聚合(使用Max或者Average)。
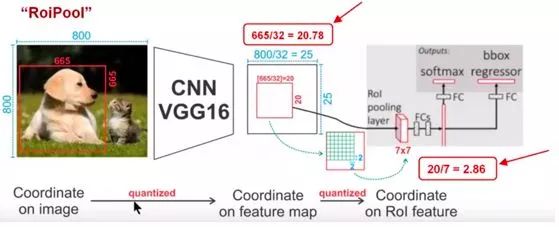
用例子具体分析一下上述区域不匹配问题。如图所示,这是一个Faster-RCNN检测框架。输入一张800*800的图片,图片上有一个665*665的包围框(框着一只狗)。图片经过主干网络提取特征后,特征图缩放步长(stride)为32。因此,图像和包围框的边长都是输入时的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,带有小数,于是ROI Pooling 直接将它量化成20。接下来需要把框内的特征池化7*7的大小,因此将上述包围框平均分割成7*7个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征图上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,影响还是很大的。
具体方法要点:
遍历每一个候选区域,保持浮点数边界不做量化。
将候选区域分割成k x k个单元,每个单元的边界也不做量化。
在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
三、改进了分割Loss
由原来的基于单像素Softmax的多项式交叉熵变为了基于单像素Sigmod二值交叉熵。该框架对每个类别独立地预测一个二值掩模,没有引入类间竞争,每个二值掩模的类别依靠网络ROI分类分支给出的分类预测结果。这与FCNs不同,FCNs是对每个像素进行多类别分类,它同时进行分类和分割,基于实验结果表明这样对于对象实例分割会得到一个较差的性能。
下面介绍一下更多的细节,在训练阶段,作者对于每个采样的ROI定义一个多任务损失函数$L=L_{cls}+L_{box}+L_{mask}$,前两项不过多介绍。掩模分支对于每个ROI会有一个$Km^2$维度的输出,它编码了$K$个分辨率为$m\times m$的二值掩模,分别对应着$K$个类别。因此作者利用了A Per-pixel
Sigmoid,并且定义为平均二值交叉熵损失(The Average Binary Cross-entropy Loss)。对于一个属于第$K$个类别的ROI,仅仅考虑第$K$个Mask(其他的掩模输入不会贡献到损失函数中)。这样的定义会允许对每个类别都会生成掩模,并且不会存在类间竞争。
四、掩模表示
一个掩模编码了一个输入对象的空间布局。作者使用了一个FCN来对每个ROI预测一个的掩模,这保留了空间结构信息。
end
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

