YOLOv8n-seg.pt的使用(实例分割,训练自己制作的数据集)
Ubuntu+python3
一、YOLOV8源码下载
参考:GitHub - ultralytics/ultralytics: NEW - YOLOv8 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
二、数据集制作
1.labelme下载:pip3 install labelme
2.终端输入labelme,打开labelme。界面“打开目录”,打开图片目录images,进行多边形标注(右键选择多边形),进行多点标注。
3.标注完成的图片保存到文件夹json.
4.将json文件转换为txt文件(txt文件说明:每行数据代表图像中的一个对象,包含对象的类别、实例分割的多边形坐标—每对数字是一个坐标点,表示为图像宽度和高度的比例,定义了图像中对象的精确形状),具体代码参考如下:
(自己作为学习使用,在此留存,不记得之前看的那个博主的了,如介意可删除)
法一:(自己使用的时候,转换后的txt文件中的classes类别不对,应该是从0开始)
import json import os def convert(img_size, box): x1 = box[0] y1 = box[1] x2 = box[2] y2 = box[3] center_x = (x1 + x2) * 0.5 / img_size[0] center_y = (y1 + y2) * 0.5 / img_size[1] w = abs((x2 - x1)) * 1.0 / img_size[0] h = abs((y2 - y1)) * 1.0 / img_size[1] return (center_x, center_y, w, h) def decode_json(jsonfloder_path, json_name): txt_name = '/home/ubuntu210/learn/ultralytics-main/dataset/data1/labels/label' + json_name[0:-5] + '.txt' # txt保存位置,根据自己的文件填写绝对位置 txt_file = open(txt_name, 'w') # te files json_path = os.path.join(json_folder_path, json_name) data = json.load(open(json_path, 'r')) img_w = data['imageWidth'] img_h = data['imageHeight'] for i in data['shapes']: if (i['shape_type'] == 'rectangle'): # 仅适用矩形框标注 x1 = float(i['points'][0][0]) y1 = float(i['points'][0][1]) x2 = float(i['points'][1][0]) y2 = float(i['points'][1][1]) if x1 < 0 or x2 < 0 or y1 < 0 or y2 < 0: continue else: bb = (x1, y1, x2, y2) bbox = convert((img_w, img_h), bb) if i['label'] == "bottle": txt_file.write("0 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "bike": txt_file.write("1 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "people": txt_file.write("2 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "car": txt_file.write("3 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "pensils": txt_file.write("4 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "kids": txt_file.write("5 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "skate": txt_file.write("6 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "dog": txt_file.write("7 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "cat": txt_file.write("8 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "rubbish box": txt_file.write("9 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "desk": txt_file.write("10 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "chair": txt_file.write("11 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "electric vehicle": txt_file.write("12 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "motorcycle": txt_file.write("13 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "birds": txt_file.write("14 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "computer": txt_file.write("15 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "keyboard": txt_file.write("16 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "mouse": txt_file.write("17 " + " ".join([str(a) for a in bbox]) + '\n') elif i['label'] == "book": txt_file.write("18 " + " ".join([str(a) for a in bbox]) + '\n') else: txt_file.write("19 " + " ".join([str(a) for a in bbox]) + '\n') if __name__ == "__main__": json_folder_path = '/home/ubuntu210/learn/ultralytics-main/dataset/data1/json' # json文件夹路径,根据自己的路径填写位置信息 json_names = os.listdir(json_folder_path) # file name for json_name in json_names: # output all files if json_name[-5:] == '.json': # just work for json files decode_json(json_folder_path, json_name)法二:修改最后的路径
# -*- coding: utf-8 -*- import json import os import argparse from tqdm import tqdm def convert_label_json(json_dir, save_dir, classes): json_paths = os.listdir(json_dir) classes = classes.split(',') for json_path in tqdm(json_paths): # for json_path in json_paths: path = os.path.join(json_dir, json_path) with open(path, 'r') as load_f: json_dict = json.load(load_f) h, w = json_dict['imageHeight'], json_dict['imageWidth'] # save txt path txt_path = os.path.join(save_dir, json_path.replace('json', 'txt')) txt_file = open(txt_path, 'w') for shape_dict in json_dict['shapes']: label = shape_dict['label'] label_index = classes.index(label) points = shape_dict['points'] points_nor_list = [] for point in points: points_nor_list.append(point[0] / w) points_nor_list.append(point[1] / h) points_nor_list = list(map(lambda x: str(x), points_nor_list)) points_nor_str = ' '.join(points_nor_list) label_str = str(label_index) + ' ' + points_nor_str + '\n' txt_file.writelines(label_str) if __name__ == "__main__": """ python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_rings/txts --classes "cat,dogs" """ parser = argparse.ArgumentParser(description='json convert to txt params') parser.add_argument('--json-dir', type=str,default='/home/ubuntu210/learn/exercise/ultralytics-main/data/json', help='json path dir') parser.add_argument('--save-dir', type=str,default='/home/ubuntu210/learn/exercise/ultralytics-main/data/txt' ,help='txt save dir') parser.add_argument('--classes', type=str, default='person',help='classes') args = parser.parse_args() json_dir = args.json_dir save_dir = args.save_dir classes = args.classes convert_label_json(json_dir, save_dir, classes)
5.将images和txt合并,划分数据集,参考代码如下:
参考:制作自己的数据集并训练的YOLOv8模型_yolov8 分类 训练-CSDN博客
修改data_dir,train_val_test_dir路径
import os import random import shutil ##数据集分离,训练集16;验证集4;测试集3 def split_dataset(data_dir,train_val_test_dir, train_ratio, val_ratio, test_ratio): # 创建目标文件夹 train_dir = os.path.join(train_val_test_dir, 'train') val_dir = os.path.join(train_val_test_dir, 'val') test_dir = os.path.join(train_val_test_dir, 'test') os.makedirs(train_dir, exist_ok=True) os.makedirs(val_dir, exist_ok=True) os.makedirs(test_dir, exist_ok=True) # 获取数据集中的所有文件 files = os.listdir(data_dir) # 过滤掉非图片文件 image_files = [f for f in files if f.endswith('.jpg') or f.endswith('.png')] # 随机打乱文件列表 random.shuffle(image_files) # 计算切分数据集的索引 num_files = len(image_files) num_train = int(num_files * train_ratio) num_val = int(num_files * val_ratio) num_test = num_files - num_train - num_val # 分离训练集 train_files = image_files[:num_train] for file in train_files: src_image_path = os.path.join(data_dir, file) src_label_path = os.path.join(data_dir, file.replace('.jpg', '.txt').replace('.png', '.txt')) dst_image_path = os.path.join(train_dir, file) dst_label_path = os.path.join(train_dir, file.replace('.jpg', '.txt').replace('.png', '.txt')) shutil.copy(src_image_path, dst_image_path) shutil.copy(src_label_path, dst_label_path) # 分离验证集 val_files = image_files[num_train:num_train+num_val] for file in val_files: src_image_path = os.path.join(data_dir, file) src_label_path = os.path.join(data_dir, file.replace('.jpg', '.txt').replace('.png', '.txt')) dst_image_path = os.path.join(val_dir, file) dst_label_path = os.path.join(val_dir, file.replace('.jpg', '.txt').replace('.png', '.txt')) shutil.copy(src_image_path, dst_image_path) shutil.copy(src_label_path, dst_label_path) # 分离测试集 test_files = image_files[num_train+num_val:] for file in test_files: src_image_path = os.path.join(data_dir, file) src_label_path = os.path.join(data_dir, file.replace('.jpg', '.txt').replace('.png', '.txt')) dst_image_path = os.path.join(test_dir, file) dst_label_path = os.path.join(test_dir, file.replace('.jpg', '.txt').replace('.png', '.txt')) shutil.copy(src_image_path, dst_image_path) shutil.copy(src_label_path, dst_label_path) print("数据集分离完成!") print(f"训练集数量:{len(train_files)}") print(f"验证集数量:{len(val_files)}") print(f"测试集数量:{len(test_files)}") def move_files(data_dir): # 创建目标文件夹 images_dir = os.path.join(data_dir, 'images') labels_dir = os.path.join(data_dir, 'labels') os.makedirs(images_dir, exist_ok=True) os.makedirs(labels_dir, exist_ok=True) # 获取数据集中的所有文件 files = os.listdir(data_dir) # 移动PNG文件到images文件夹 png_files = [f for f in files if f.endswith('.png')] for file in png_files: src_path = os.path.join(data_dir, file) dst_path = os.path.join(images_dir, file) shutil.move(src_path, dst_path) # 移动TXT文件到labels文件夹 txt_files = [f for f in files if f.endswith('.txt')] for file in txt_files: src_path = os.path.join(data_dir, file) dst_path = os.path.join(labels_dir, file) shutil.move(src_path, dst_path) print(f"{data_dir}文件移动完成!") print(f"总共移动了 {len(png_files)} 个PNG文件到images文件夹") print(f"总共移动了 {len(txt_files)} 个TXT文件到labels文件夹") # 设置数据集路径和切分比例 data_dir = '/home/ubuntu210/learn/ultralytics-main/dataset/data2/images' # 图片和标签路径 train_val_test_dir= '/home/ubuntu210/learn/ultralytics-main/dataset/data2' # 目标文件夹 train_ratio = 0.7 # 训练集比例 val_ratio = 0.2 # 验证集比例 test_ratio = 0.1 # 测试集比例 # 调用函数分离数据集 split_dataset(data_dir, train_val_test_dir,train_ratio, val_ratio, test_ratio) # 调用函数移动文件 move_files(os.path.join(train_val_test_dir, 'train')) move_files(os.path.join(train_val_test_dir, 'val')) move_files(os.path.join(train_val_test_dir, 'test'))修改.png后缀,即可改为jpg格式图片文件。
三、修改文件
1.yolov8-seg.yaml中的类别nc:80修改为自己的类别数
2.创建myseg.yaml文件(划分的数据集的路径,建议绝对路径)
path: /home/ubuntu210/learn/ultralytics-main/mydata/split
train: /home/ubuntu210/learn/ultralytics-main/mydata/split/train/images
test: /home/ubuntu210/learn/ultralytics-main/mydata/split/test/images
val: /home/ubuntu210/learn/ultralytics-main/mydata/split/val/images
names:
0: person3.创建train.py文件(权重文件yolov8n-seg.pt路径,yolov8-seg.yaml路径)
from ultralytics import YOLO
model=YOLO("/home/ubuntu210/learn/ultralytics-main/ultralytics/cfg/models/v8/yolov8-seg.yaml")
model=YOLO("/home/ubuntu210/learn/ultralytics-main/yolov8n-seg.pt")
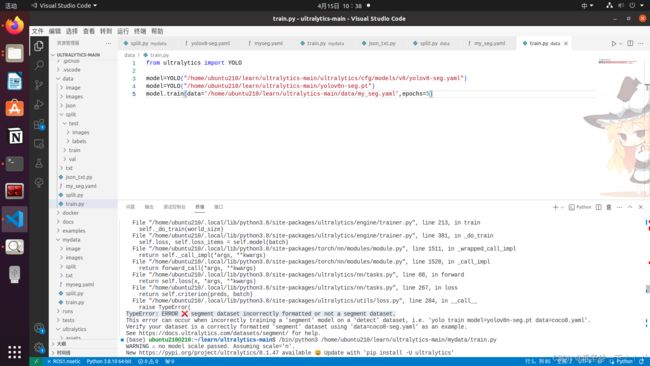
model.train(data='/home/ubuntu210/learn/ultralytics-main/data/my_seg.yaml',epochs=5)四、运行文件train.py
yolov8踩过的坑(不知道理解的对不对,理解的不对请多多交流)
yolov8n-seg.pt训练采用的数据集是多边形标注。如果拿矩形框标注的数据集去训练yolov8-seg.pt会出现如下错误:
yolov8n.pt训练采用的数据集标注是矩形框。
参考:Training on custom dataset - segment dataset incorrectly formatted or not a segment dataset. · Issue #3930 · ultralytics/ultralytics · GitHub
yolov8资料:超详细YOLOv8实例分割全程概述:环境、训练、验证与预测详解_yolov8分割-CSDN博客
yolov8模型训练结果分析以及如何评估yolov8模型训练的效果_yolov8 结果解释-CSDN博客
yolov8隐藏标签和置信度分数(目前尝试完都没效果):
1.ultralytics/engine/results.py---279行注释
2.ultralytics/cfg/__init__.py---hide_labels/hide_conf 设置为True
3.修改ultralytics/cfg/default.yaml中的save_labels/save_conf设置为False
4.修改ultralytics/utils/plotting.py中的163-205注释掉 除了190的cv2.rectangle
5.plotting.py中的cv2.putText注释掉了
6.ultralytics-main/ultralytics/engine/results.py 197行修改labels=False
最终的解决办法是在预测(自己运行best.pt进行模型推理使用的程序)推理model.predict(show_labels=False),看自己的情况选择show_conf=False隐藏置信度(也是通过尝试了巨多的方法之后找到的有效的方法,上面的方法也是在找方法当中留作笔记用的。如果最后的方法不对的话请留言告知)
参考(更改检测框的粗细,也是直接在最后的推理程序predict中修改):YOLOv8及其改进系列(五) modules.py 文件划分子集 | 标签透明化与文字大小调节 | 框粗细调节_yolov8检测框字体修改-CSDN博客
yolov8实现动态扣图(扣除目标识别的类别,保留背景)
####扣除单目标 ###参考:https://blog.csdn.net/qq_42452134/article/details/136272606 from ultralytics import YOLO from matplotlib import pyplot as plt import numpy as np import cv2 # 加载sam模型,如果没有这个框架也会自动的为你下载 model = YOLO('yolov8n-seg.pt') # 读取一张图片, orig_img = cv2.imread('test.jpg') # 这里特别注意,因为使用yolov8训练的时候默认会把图片resize成448*640的尺寸,所以这里也得改成你训练的尺寸 orig_img = cv2.resize(orig_img, (640, 448)) # 注意OpenCV中尺寸是先宽度后高度 # 使用模型进行推理, 后面save=True的参数可以输出测试分割的图片 results = model(orig_img,save=True) # 这里是我获取mask编码部分的。 mask = results[0].masks.data[0].cpu().numpy().astype(np.bool_) # 应用掩码到原始图像 # 如果你想要背景是黑色的 masked_image = np.zeros_like(orig_img) masked_image[~mask] = orig_img[~mask] # 如果你想要背景透明(假设原始图像是RGB格式) # 创建一个RGBA图像,其中背景是透明的 alpha_channel = np.ones(mask.shape, dtype=orig_img.dtype) * 255 # 创建alpha通道 masked_image_rgba = np.dstack((masked_image, alpha_channel)) # 将alpha通道添加到RGB通道 masked_image_rgba[mask] = (0, 0, 0, 0) # 将掩码区域设置为透明 # 保存图片,黑色背景 cv2.imwrite('./datasets/results/masked_image_test.jpg', masked_image) # 如果背景是透明的 cv2.imwrite('./datasets/results/masked_image_test.png', masked_image_rgba)#########实现多目标扣图,扣除多个相同的(读取的图片采用原始图片,在我尝试的过程中采用了推理之后的图片,会出现目标扣除不彻底) ####参考:https://blog.csdn.net/weixin_47415047/article/details/136645315 from ultralytics import YOLO # 导入YOLO模型类 from matplotlib import pyplot as plt import numpy as np import cv2 # 导入OpenCV库 # 加载预训练的模型 model = YOLO('/home/ubuntu210/learn/ultralytics-main/runs/segment/train2/weights/best.pt') # 读取图片并调整其大小以匹配模型训练时的输入尺寸 orig_img = cv2.imread('/home/ubuntu210/learn/ultralytics-main/data/predict_result/0000000000.png') # 使用cv2读取图片(原图片) # 这里特别注意,因为使用yolov8训练的时候默认会把图片resize成448*640的尺寸,所以这里也得改成你训练的尺寸 orig_img_resized = cv2.resize(orig_img, (640, 256)) # 调整图片大小 # 使用模型对调整后的图片进行推理 results = model(orig_img_resized, save=True) # 初始化一个布尔数组掩码,用于合并所有检测到的物体掩码 combined_mask = np.zeros(orig_img_resized.shape[:2], dtype=np.bool_) # 遍历检测到的所有掩码 for mask in results[0].masks.data: mask_bool = mask.cpu().numpy().astype(np.bool_) # 将掩码转换为布尔数组 combined_mask |= mask_bool # 使用逻辑或操作合并掩码 # 使用合并后的掩码创建抠图 masked_image = np.zeros_like(orig_img_resized) # 初始化一个全黑的图片数组 masked_image[~combined_mask] = orig_img_resized[~combined_mask] # 应用掩码,将类别扣除 # # 创建一个带有透明背景的RGBA图像 # alpha_channel = np.ones(combined_mask.shape, dtype=orig_img.dtype) * 255 # 创建全白的alpha通道 # masked_image_rgba = np.dstack((masked_image, alpha_channel)) # 将RGB图像和alpha通道合并 # #masked_image_rgba[~combined_mask] = (0, 0, 0, 0) # 设置背景为透明 # masked_image_rgba[combined_mask] = (0,0,0, 0) # 设置背景为透明 # 保存两种处理后的图像 cv2.imwrite('/home/ubuntu210/learn/ultralytics-main/data/predict_result/masked_image_all_objects.jpg', masked_image) # 保存带黑色背景的图像 #cv2.imwrite('/home/ubuntu210/learn/ultralytics-main/data/predict_result/masked_image_all_objects.png', masked_image_rgba) # 保存带透明背景的图像 # 显示第一张处理后的图像 #masked_image = cv2.resize(masked_image, (1200, 950)) # 调整图像大小 #v2.imshow("YOLOv8 Inference", masked_image) # 显示图像 #cv2.waitKey(0) # 等待用户按键 #cv2.destroyAllWindows() # 关闭所有OpenCV窗口
一、实现输出检测框的坐标信息
1)(注意:如果是apt install ultralytics的方式,作出的更改文件plooting.py的文件是安装的环境包里面的,通过命令行pip show ultralytics输出location即为文件路径):YOLOv8、YOLOv8_OBB输出detect检测到的目标坐标信息_yolov8输出预测框的坐标-CSDN博客
2)直接调用系统参数(推荐):
YOLOv8打印检测框坐标_yolov8获取框框坐标-CSDN博客
根据该博客内容可将输出坐标信息输出整数
import torch print(torch.trunc(r.boxes.xyxy))##取整输出检测框坐标二、将检测框路标信息输出到.txt文件里面
三、点击图像输出坐标值及BGR通道信息
参考:Opencv C++ 三、通过鼠标点击操作获取图像的像素坐标和像素值 四、生成一个简单的灰度图像。_c++ opencv鼠标获取图像坐标-CSDN博客
ERROR:
一、TabError: inconsistent use of tabs and spaces in indentation
解决办法(空格和tab键混合使用):【TabError】TabError: inconsistent use of tabs and spaces in indentation-CSDN博客
二、