数据挖掘-4.Pandas高级
文章目录
- pandas高级
- 1 高级处理-缺失值处理
-
- 学习目标
- 1 如何处理nan
- 2 电影数据的缺失值处理
-
- 2.1 判断缺失值是否存在
- 2.2 存在缺失值nan,并且是np.nan
- 2.3 不是缺失值nan,有默认标记的
- 3 小结
- 2 高级处理-数据离散化
-
- 学习目标
- 1 为什么要离散化
- 2 如何数据的离散化
- 3 股票的涨跌幅离散化
-
- 3.1 读取股票的数据

- 3.2 将股票涨跌幅数据进行分组
- 3.3 股票涨跌幅分组数据变成one-hot编码
- 4 小结
- 3. 高级处理-合并
-
- 学习目标
- 1 pd.concat实现数据合并
- 2 pd.merge
-
- 2.1 pd.merge合并
- 3 总结
- 4 高级处理-交叉表与透视表
-
- 学习目标
- 1 交叉表与透视表什么作用
- 2 案例分析
-
- 2.1 数据准备
- image-202111031729331702.2 查看效果
- 2.3 使用pivot_table(透视表)实现
- image-202111031729162313 小结
- 5 高级处理-分组与聚合
-
- 学习目标
- 1 什么分组与聚合
- 2 分组API
- 3 星巴克零售店铺数据
-
- 3.1 数据获取

- 3.2 进行分组聚合
- 4 小结
- 6 综合案例
pandas高级
1 高级处理-缺失值处理
学习目标
- 目标
- 应用isnull判断是否有缺失数据NaN
- 应用fillna实现缺失值的填充
- 应用dropna实现缺失值的删除
- 应用replace实现数据的替换
1 如何处理nan
- 获取缺失值的标记方式(NaN或者其他标记方式)
- 如果缺失值的标记方式是NaN
- 判断数据中是否包含NaN:
- pd.isnull(df),
- pd.notnull(df)
- 存在缺失值nan:
- 1、删除存在缺失值的:dropna(axis=‘rows’)
- 注:不会修改原数据,需要接受返回值
- 2、替换缺失值:fillna(value, inplace=True)
- value:替换成的值
- inplace:True:会修改原数据,False:不替换修改原数据,生成新的对象
- 1、删除存在缺失值的:dropna(axis=‘rows’)
- 判断数据中是否包含NaN:
- 如果缺失值没有使用NaN标记,比如使用"?"
- 先替换‘?’为np.nan,然后继续处理
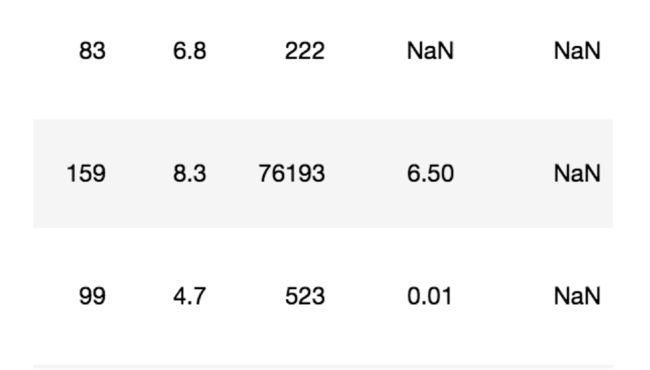
2 电影数据的缺失值处理
- 电影数据文件获取
# 读取电影数据
movie = pd.read_csv("./data/IMDB-Movie-Data.csv")

2.1 判断缺失值是否存在
-
np.any()
# 1)判断是否存在缺失值 np.all有一个False就返回False np.any 有一个True返回 True np.any(movie.isnull()) # 返回True说明数据中 存在缺失值 True -
np.all()
np.all(movie.notnull()) # 返回False说明数据中 存在缺失 True -
pd.notnull()
pd.isnull(movie).any()
-
pd.isnull()
pd.notnull(movie).all()
2.2 存在缺失值nan,并且是np.nan
- 1、删除
pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
# 不修改原数据
movie.dropna() # 加上inplace=True 则修改原始数据
# 可以定义新的变量接受或者用原来的变量名
data = movie.dropna()
- 2、替换缺失值
# 替换存在缺失值的样本的两列
# 替换填充平均值,中位数
# movie['Revenue (Millions)'].fillna(movie['Revenue (Millions)'].mean(), inplace=True)
替换所有缺失值:
for i in movie.columns:
if np.all(pd.notnull(movie[i])) == False:
print(i)
movie[i].fillna(movie[i].mean(), inplace=True)
2.3 不是缺失值nan,有默认标记的
数据是这样的:

cancer = pd.read_csv("../../resource/cancer/breast-cancer-wisconsin.data", names=["Sample code number", "Clump Thickness", "Uniformity of Cell Size", "Uniformity of Cell Shape", "Marginal Adhesion","Single Epithelial Cell Size", "Bare Nuclei", "Bland Chromatin", "Normal Nucleoli", "Mitoses", "Class"])
cancer
处理思路分析:
- 1、先替换‘?’为np.nan
- df.replace(to_replace=, value=)
- to_replace:替换前的值
- value:替换后的值
- df.replace(to_replace=, value=)
# 把一些其它值标记的缺失值,替换成np.nan
wis = wis.replace(to_replace='?', value=np.nan)
- 2、在进行缺失值的处理
# 删除
wis = wis.dropna()
3 小结
- isnull、notnull判断是否存在缺失值【知道】
- np.any(pd.isnull(movie)) # 里面如果有一个缺失值,就返回True
- np.all(pd.notnull(movie)) # 里面如果有一个缺失值,就返回False
- dropna删除np.nan标记的缺失值【知道】
- movie.dropna()
- fillna填充缺失值【知道】
- movie[i].fillna(value=movie[i].mean(), inplace=True)
- replace替换具体某些值【知道】
- wis.replace(to_replace="?", value=np.NaN)
2 高级处理-数据离散化
学习目标
- 目标
- 应用cut、qcut实现数据的区间分组
- 应用get_dummies实现数据的one-hot编码
1 为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
2 如何数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。
离散化有很多种方法,这使用一种最简单的方式去操作
- 原始人的身高数据:165,174,160,180,159,163,192,184
- 假设按照身高分几个区间段:150~165, 165180,180195
这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个"哑变量"矩阵
数据离散化步骤
data = pd.Series({"Nol:165": 165, "No2:174": 174, "No3:160": 160, "No4:180": 180,
"No5:159": 159, "No6:163": 163, "No7:192": 192, "No8:184": 184})
data

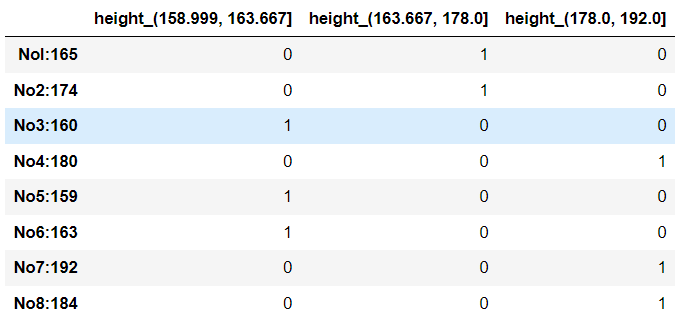
# 2.分组
# 自行分组 pd.qcut(data, q) 对数据进行分组将数据分组,一般会与value_counts搭配使用,统计每组的个数
sr = pd.qcut(data, 3)
sr.value_counts()
#输出
(158.999, 163.667] 3
(178.0, 192.0] 3
(163.667, 178.0] 2
dtype: int64
sr
#输出
Nol:165 (163.667, 178.0]
No2:174 (163.667, 178.0]
No3:160 (158.999, 163.667]
No4:180 (178.0, 192.0]
No5:159 (158.999, 163.667]
No6:163 (158.999, 163.667]
No7:192 (178.0, 192.0]
No8:184 (178.0, 192.0]
dtype: category
Categories (3, interval[float64]): [(158.999, 163.667] < (163.667, 178.0] < (178.0, 192.0]]
# 3.转换成one-hot编码
pd.get_dummies(sr, prefix="height")
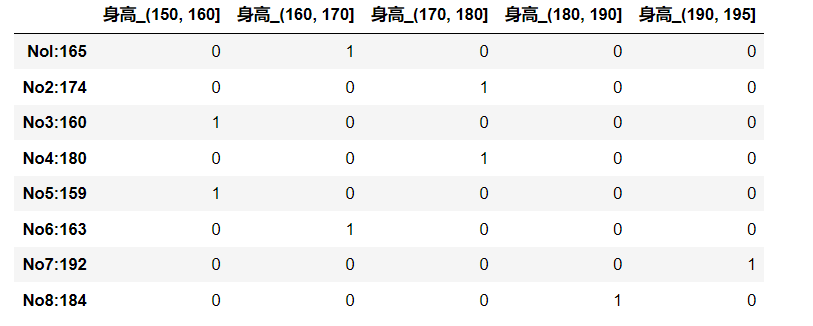
# 自定义分组
bins = [150, 160, 170, 180, 190, 195]
sr2 = pd.cut(data, bins)
sr2
#输出
Nol:165 (160, 170]
No2:174 (170, 180]
No3:160 (150, 160]
No4:180 (170, 180]
No5:159 (150, 160]
No6:163 (160, 170]
No7:192 (190, 195]
No8:184 (180, 190]
dtype: category
Categories (5, interval[int64]): [(150, 160] < (160, 170] < (170, 180] < (180, 190] < (190, 195]]
sr2.value_counts()
#输出
(150, 160] 2
(160, 170] 2
(170, 180] 2
(180, 190] 1
(190, 195] 1
dtype: int64
# get_dummies
pd.get_dummies(sr2, "身高")
3 股票的涨跌幅离散化
我们对股票每日的"p_change"进行离散化

3.1 读取股票的数据
先读取股票的数据,筛选出p_change数据
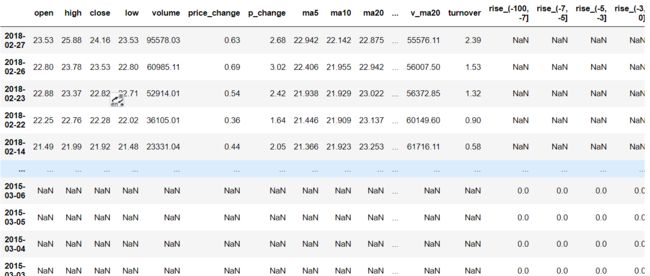
data = pd.read_csv("./data/stock_day.csv")
p_change= data['p_change']
3.2 将股票涨跌幅数据进行分组
使用的工具:
- pd.qcut(data, q):
- 对数据进行分组将数据分组,一般会与value_counts搭配使用,统计每组的个数
- series.value_counts():统计分组次数
# 自行分组
qcut = pd.qcut(p_change, 10)
# 计算分到每个组数据个数
qcut.value_counts()
自定义区间分组:
- pd.cut(data, bins)
# 自己指定分组区间
bins = [-100, -7, -5, -3, 0, 3, 5, 7, 100]
sr = pd.cut(p_change, bins)

3.3 股票涨跌幅分组数据变成one-hot编码
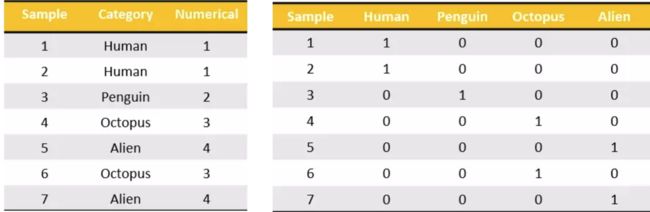
- 什么是one-hot编码
把每个类别生成一个布尔列,这些列中只有一列可以为这个样本取值为1.其又被称为热编码。
把下图中左边的表格转化为使用右边形式进行表示:
- pandas.get_dummies(data, prefix=None)
- data:array-like, Series, or DataFrame
- prefix:分组名字
# 3.转变成one_hot编码
stock_change = pd.get_dummies(sr, "rise")
stock_change.head()
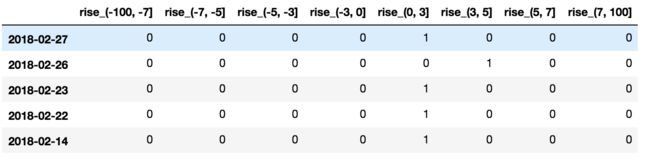
4 小结
- 数据离散化【知道】
- 可以用来减少给定连续属性值的个数
- 在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值代表落在每个子区间中的属性值。
- qcut、cut实现数据分组【知道】
- qcut:大致分为相同的几组
- cut:自定义分组区间
- get_dummies实现哑变量矩阵【知道】
3. 高级处理-合并
学习目标
- 目标
- 应用pd.concat实现数据的合并
- 应用pd.merge实现数据的合并
如果你的数据由多张表组成,那么有时候需要将不同的内容合并在一起分析
1 pd.concat实现数据合并
- pd.concat([data1, data2], axis=1)
- 按照行或列进行合并,axis=0为列索引,axis=1为行索引
比如我们将刚才处理好的one-hot编码与原数据合并
# 处理好的one-hot编码与原数据进行合并
stock.head()

stock_change.head()

# 按照行索引进行
pd.concat([stock, stock_change], axis=1).head() # 水平拼接

pd.concat([stock, stock_change], axis=0) # 如果两个表的字段不一致,就会多加出来另一张表的一列数据
2 pd.merge
- pd.merge(left, right, how=‘inner’, on=None)
- 可以指定按照两组数据的共同键值对合并或者左右各自
left: DataFrameright: 另一个DataFrameon: 指定的共同键- how:按照什么方式连接
| Merge method | SQL Join Name | Description |
|---|---|---|
left |
LEFT OUTER JOIN |
Use keys from left frame only |
right |
RIGHT OUTER JOIN |
Use keys from right frame only |
outer |
FULL OUTER JOIN |
Use union of keys from both frames |
inner |
INNER JOIN |
Use intersection of keys from both frames |
2.1 pd.merge合并
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
# 默认内连接
result = pd.merge(left, right, on=['key1', 'key2'])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dqNbpULF-1635939362020)(https://gitee.com/mjcwkq/imgs/raw/master/imgs/202111031711676.png)]
- 左连接
result = pd.merge(left, right, how='left', on=['key1', 'key2'])

- 右连接
result = pd.merge(left, right, how='right', on=['key1', 'key2'])

- 外连接
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B1wx50D8-1635939362025)(https://gitee.com/mjcwkq/imgs/raw/master/imgs/202111031712616.png)]
3 总结
- pd.concat([数据1, 数据2], axis=**)【知道】
- pd.merge(left, right, how=, on=)【知道】
- how – 以何种方式连接
- on – 连接的键的依据是哪几个
4 高级处理-交叉表与透视表
学习目标
- 目标
- 应用crosstab和pivot_table实现交叉表与透视表
1 交叉表与透视表什么作用
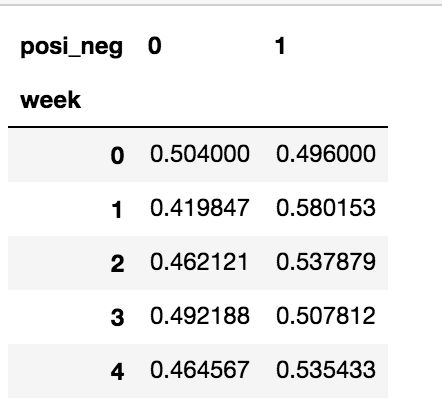
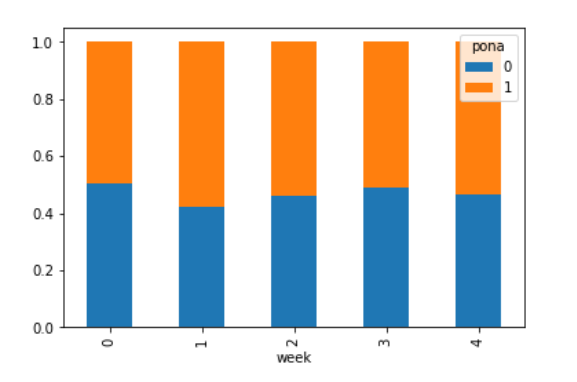
探究股票的涨跌与星期几有关?
以下图当中表示,week代表星期几,1,0代表这一天股票的涨跌幅是好还是坏,里面的数据代表比例
可以理解为所有时间为星期一等等的数据当中涨跌幅好坏的比例

-
交叉表:
交叉表用于计算一列数据对于另外一列数据的分组个数(用于统计分组频率的特殊透视表)
- pd.crosstab(value1, value2)
-
透视表:
透视表是将原有的DataFrame的列分别作为行索引和列索引,然后对指定的列应用聚集函数
- data.pivot_table()
-
- DataFrame.pivot_table([], index=[])
2 案例分析
2.1 数据准备

- 准备两列数据,星期数据以及涨跌幅是好是坏数据
- 进行交叉表计算
# 寻找星期几跟股票张得的关系
# 1、先把对应的日期找到星期几
date = pd.to_datetime(data.index).weekday
data['week'] = date

# 2、假如把p_change按照大小去分个类0为界限
data['pona'] = np.where(data['p_change'] > 0, 1, 0)
# 通过交叉表找寻两列数据的关系
count = pd.crosstab(data['week'], data['pona'])
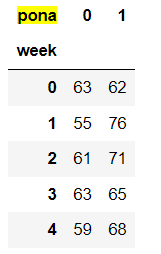
但是我们看到count只是每个星期日子的好坏天数,并没有得到比例,该怎么去做?
- 对于每个星期一等的总天数求和,运用除法运算求出比例
# 算数运算,先求和
sum = count.sum(axis=1).astype(np.float32)
# 进行相除操作,得出比例
pro = count.div(sum, axis=0)
 2.2 查看效果
2.2 查看效果
使用plot画出这个比例,使用stacked的柱状图
pro.plot(kind='bar', stacked=True)
plt.show()
2.3 使用pivot_table(透视表)实现
使用透视表,刚才的过程更加简单
# 通过透视表,将整个过程变成更简单一些
data.pivot_table(['posi_neg'], index='week')
 3 小结
3 小结
- 交叉表与透视表的作用【知道】
- 交叉表:计算一列数据对于另外一列数据的分组个数
- 透视表:指定某一列对另一列的关系
5 高级处理-分组与聚合
学习目标
- 目标
- 应用groupby和聚合函数实现数据的分组与聚合
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况
想一想其实刚才的交叉表与透视表也有分组的功能,所以算是分组的一种形式,只不过他们主要是计算次数或者计算比例!!看其中的效果:

1 什么分组与聚合
2 分组API
- DataFrame.groupby(key, as_index=False)
- key:分组的列数据,可以多个
- 案例:不同颜色的不同笔的价格数据
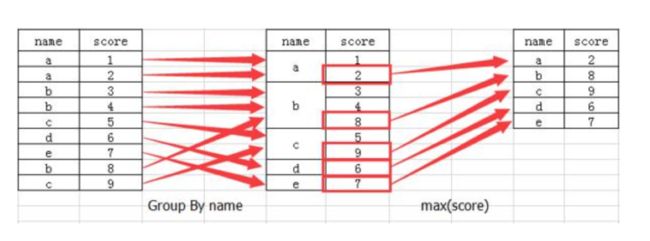
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
color object price1 price2
0 white pen 5.56 4.75
1 red pencil 4.20 4.12
2 green pencil 1.30 1.60
3 red ashtray 0.56 0.75
4 green pen 2.75 3.15
- 进行分组,对颜色分组,price进行聚合
# 分组,求平均值
# 1. 用dataframe的方法进行分组与聚合
col.groupby(['color'])['price1'].mean()
# 用Series的方法进行分组与聚合
col['price1'].groupby(col['color']).mean()
color
green 2.025
red 2.380
white 5.560
Name: price1, dtype: float64
# 分组,数据的结构不变
col.groupby(['color'], as_index=False)['price1'].mean()
color price1
0 green 2.025
1 red 2.380
2 white 5.560
3 星巴克零售店铺数据
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
数据来源:https://www.kaggle.com/starbucks/store-locations/data
3.1 数据获取
从文件中读取星巴克店铺数据
# 导入星巴克店的数据
starbucks = pd.read_csv("../../resource/data-mining/directory.csv")
starbucks.head()
3.2 进行分组聚合
# 按照国家分组,求出每个国家的星巴克零售店数量
starbucks.groupby(by="Country").count()["Brand"].sort_values(ascending=False)[:10].plot(kind="bar")

假设我们加入省市一起进行分组
# 设置多个索引,set_index()
starbucks.groupby(['Country', 'State/Province']).count()
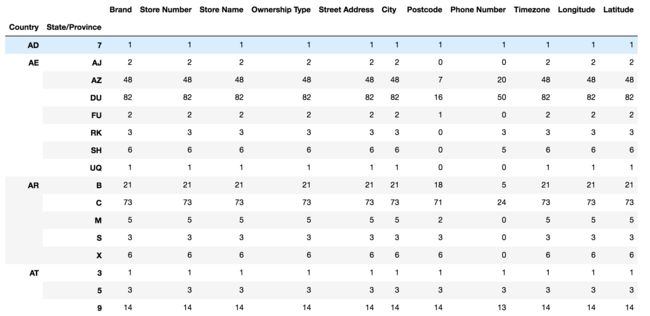
仔细观察这个结构,与我们前面讲的哪个结构类似??
与前面的MultiIndex结构类似
4 小结
- groupby进行数据的分组【知道】
- pandas中,抛开聚合谈分组,无意义
6 综合案例
movie = pd.read_csv("../../resource/data-mining/IMDB-Movie-Data.csv")
movie.head()
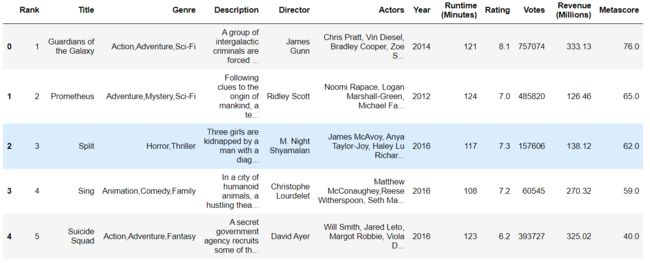
1.我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
# 得出评分的平均分
>>> moive["Rating"].mean()
6.8143198090692145
# 导演的人数等信息
>>> np.unique(movie["Director"]).size
644
2.对于这一组电影数据,如果我们想Rating,Runtime (Minutes)的分布情况,应该如何呈现数据?
import matplotlib.pyplot as plt
plt.rc('font', family='simsun', size=13)
# 1..创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 2..绘制图像 第一个参数横坐标 第二个参数纵坐标
plt.hist(movie["Rating"].values,20)
# 设置横坐标
plt.xticks(np.linspace(movie["Rating"].values.min(),movie["Rating"].values.max(),21))
# 设置网格
plt.grid(linestyle="--", alpha=0.6)
# 设置标题
plt.title("Rating情况分布")
# 3.将画呈现出来
plt.show()

max_ = movie["Runtime (Minutes)"].values.max()
min_ = movie["Runtime (Minutes)"].values.min()
import matplotlib.pyplot as plt
plt.rc('font', family='simsun', size=13)
# 1..创建画布
plt.figure(figsize=(20, 8), dpi=80)
# 2..绘制图像 第一个参数横坐标 第二个参数纵坐标
plt.hist(movie["Runtime (Minutes)"].values,20)
# 设置横坐标
plt.xticks(np.linspace(min_,max_,21))
# 设置网格
plt.grid(linestyle="--", alpha=0.6)
# 设置标题
plt.title("Runtime (Minutes)情况分布")
# 3.将画呈现出来
plt.show()

3.对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
'''
1、创建一个全为0的dataframe,列索引置为电影的分类,temp_df
2、遍历每一部电影,temp_df中把分类出现的列的值置为1
3、求和
'''
# 进行字符串分割
temp_list = [i.split(",") for i in movie["Genre"]]
temp_list[:][:10]

# 获取电影的分类
>>> genre_list = np.unique([i for j in temp_list for i in j])
array(['Action', 'Adventure', 'Animation', 'Biography', 'Comedy', 'Crime',
'Drama', 'Family', 'Fantasy', 'History', 'Horror', 'Music',
'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Sport', 'Thriller',
'War', 'Western'], dtype=')
#创建新的表
>>> count = pd.DataFrame(np.zeros(shape=(len(genre_list),1),dtype=np.int32),index=genre_list,columns=["num"])
#统计每个单词出现的个数
>>> for j in temp_list:
for i in j:
count.loc[i]["num"]+=1
count

#将电影内容排序
count.sort_values(by="num",ascending=False)
re"]]
temp_list[:][:10]
[外链图片转存中...(img-4JTtCEJF-1635939362036)]
```python
# 获取电影的分类
>>> genre_list = np.unique([i for j in temp_list for i in j])
array(['Action', 'Adventure', 'Animation', 'Biography', 'Comedy', 'Crime',
'Drama', 'Family', 'Fantasy', 'History', 'Horror', 'Music',
'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Sport', 'Thriller',
'War', 'Western'], dtype='>> count = pd.DataFrame(np.zeros(shape=(len(genre_list),1),dtype=np.int32),index=genre_list,columns=["num"])
#统计每个单词出现的个数
>>> for j in temp_list:
for i in j:
count.loc[i]["num"]+=1
count
[外链图片转存中…(img-bOzwklht-1635939362037)]
#将电影内容排序
count.sort_values(by="num",ascending=False)
