MoCo论文:Momentum Contrast for Unsupervised Visual Representation Learning
目录
- 一. 引言
- 二. 背景介绍:对比学习
- 三. 标题和作者
- 四. 动量方式:
- 五. 摘要
- 六. 相关工作
- 七. 结论
- 八. MoCo方法
- 九. MoCo伪代码
- 十. 文章贡献
-
- 10.1 第一个贡献:如何把一个字典看成队列
- 10.2 文章的第二个贡献:如何使用动量的思想去更新编码器
- 十一. 两种架构
-
- 11.1 第一种就是比较直接的端到端学习的方式
- 11.2 memory bank(更关注字典的大小,而牺牲一些一致性)
- 11.3 MoCo:解决字典大小和特征一致性的问题
- 十二. 代理任务
- 十三. MoCo论文中的小trick:Shuffling BN
- 十四. 试验
-
- 14.1 数据集的使用
- 14.2 训练的情况
- 14.3 结果
- 十五. 结论
一. 引言
MoCo是CVPR2020的最佳论文提名,算是视觉领域中使用对比学习的一个里程碑式的工作
- 对比学习作为从19年开始一直到现在,视觉领域乃至整个机器学习领域最炙手可热的方向之一,它简单、好用、强大,以一己之力盘活了从2017年开始就卷的非常厉害的机器视觉领域,涌现了一大批优秀的工作,MoCo就是其中之一
- MoCo作为一个无监督的表征学习的工作,不仅在分类任务上逼近了有监督的基线模型,而且在很多主流的视觉任务(比如检测、分割、人体关键点检测)上,都超越了有监督预训练的模型,也就是ImageNet上预训练的模型,在有的数据集上甚至是大幅度超越
- 所以说MoCo的出现从某种意义上来说,是给视觉领域吃了一个定心丸:无监督学习是真的可以的,有可能真的不需要大规模的标好的数据去做预训练。这个结论也从侧面上证明了之前Yannn LeCun在NeurlPS 2016做演讲的时候用的一张图,如下图所示:
它的意思是说如果将机器学习比做一个蛋糕的话,那强化学习只能算是这个蛋糕上的一个小樱桃,有监督学习最多就算这个蛋糕上的那层糖霜,只有无监督学习才是这块蛋糕的本质,才是我们真正想要的。而现在也确实是这样,不光是在自然语言处理里很多我们耳熟能详的大模型都是用自监督的预训练得到的,那么在视觉里也快了。
GPT和BERT已经证明了无监督的表征学习在NLP领域是非常成功的,但是在视觉领域有监督的预训练还是占主导地位:
-
虽然也有很多出色的无监督工作,但是它们往往要比这些有监督的模型在效果上要差很多
-
作者认为原因有可能来源于原始的信号空间不同,对于自然语言处理的任务来说,它的信号空间是离散的(也就是说它原始的信号空间是由单词或者是词根词缀去表示的),从而可以很容易地建立一些Tokenize(Tokenize就是把某一个词对应成某一个特征)的字典,一旦有了这个字典,无监督学习也就可以基于它很容易地展开,因为可以简单地把这个字典里所有的key(就是所有的条目)想象成一个类别,这就变成了一个有监督学习的范式,还是有一个类似于标签一样的东西去辅助学习,所以在NLP中,无监督学习很容易建模,而且建好的模型相对比较容易优化
-
但是对于视觉来讲就完全不一样了,因为视觉的原始信号是在一个连续的而且高维的空间里,它并不像单词那样有很强的语义信息而且浓缩的非常好,没有那么简洁,所以导致它并不适合去建立一个这样的字典。但是如果没有这个字典,无监督学习就很难去建模,所以导致在视觉中无监督学习远不如有监督学习
最近有一些基于对比学习的无监督表征学习的方式取得了非常不错的效果,虽然这些方式的出发点或者具体的做法都不一样,但是它们都可以被归纳成一种方法:构造一个动态的字典
-
一个数据集中有n张图片,随机选择一张图片x1,在这张图片上经过不同的变换以后得到x11和x12,这两张图片就组成了一个正样本对,一般将x11叫做anchor也就是锚点(基准点),将x12叫做positive(也就是相对于基准点来说,x12是x11的一个正样本),剩下的所有的图片,从x2到xn全都是负样本(negative)
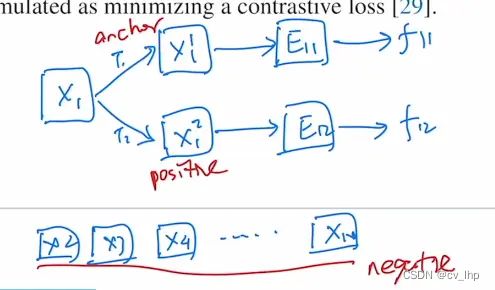
-
有了正负样本这些概念,接下来将这些样本丢给编码器得到一些特征输出,比如说x11进入到编码器E11之后就会得到一个特征f11,x12进入到编码器E12之后就会得到一个特征f12,这两个编码器既可以是同一个模型,也可以是不同的模型,因为在MoCo这篇论文中选用的是相同的模型不共享权重参数,所以这里就分开画了 。
-
至于剩下的负样本,其实应该使用E12这个编码器,因为所有的负样本和正样本f12都是相对于原来的锚点f11来说的,所以说这些负样本也应该和这个正样本使用同样的编码器,从而让它们的特征保持一致性,于是这些负样本也通过这个编码器从而得到了f2到fN的特征
-
对比学习的作用就是让这一个正样本对的特征在特征空间中尽可能相近,而让那些负样特征尽可能地远离f11(也就是锚点)
为什么本文的作者认为之前的对比学习都可以被归纳成在做一个动态的字典呢?
-
如果将f12、f2、f3一直到fN的这些特征当成字典,字典中的条目(key)是从数据中抽样出来的,然后用一个编码器去表示,也就是说这里的key其实对应的是特征而不是原来的图像。
-
如果将f1当成是一个query,所有这些字典中的其它特征都当成是key,那对比学习就转化成为了一个字典查询的问题了
-
具体来说,就是对比学习要去训练一些编码器,从而去进行一个字典的查找,查找的目的就是让一个已经编码好的query(特征f11)尽可能和它匹配的那个key的特征(也就是f12这个正样本特征)相似,然后和其他的key(也就是其他负样本的特征)远离,那么整个学习的过程就变成了一个对比学习的框架,从而只需要去最小化一个对比学习的目标函数就可以了。
在MoCo这篇论文当中,因为作者已经把所有的对比学习的方法归纳成为了一个动态字典的问题,所以很少使用anchor或者正负样本这些词,用的都是query和key,所以x1一般用x_q表示,x2一般用x_k表示,也就是x_query和x_key,同样地,特征f11用的是q,代表query,剩下的特征用k0、k1等来进行表示。
MoCo的作者是以一个自顶向下的方式来写这篇论文的,他假设读者已经对对比学习的前人的工作已经了如指掌了,假设读者能跟上他的节奏。
从这个角度(把对比学习当成动态字典)来看,最后要有好的结果,这个字典应该具有两个特性:
-
第一是必须要大。字典越大,就能更好地从这个连续的高维的视觉空间做抽样(字典里的key越多,所能表示的视觉信息、视觉特征就越丰富,当拿一个query去跟后面的key做对比的时候,就真的有可能学到那些把物体区分开的特征,也就是更本质的特征。如果字典很小,模型很有可能就学到了一个捷径shortcut solution,从而导致预训练好的模型不能很好地做泛化)
-
第二就是在训练的时候要尽可能地保持一致性。字典里的key都应该用相同或者说相似的编码器去产生得到,也就是说从k0一直到kN的这些key应该是用相同或者说相似的编码器抽取得到的,这样当和query做对比的时候,才能保证对比尽可能的一致,否则如果这些特征是由不同编码器得到的话,很有可能query就找到了和它使用相同或者相似编码器的key,而不是真的和它含有相同语义信息的key(这样其实也就是变相地引入了一个shortcut solution,也就是说引入了一条捷径从而让模型学不好)
作者说,现在已有的这些使用对比学习的方法,都至少被上述所说的两个方面中的一个所限制(其实这里说明一下现在已有的方法是怎么受限的会更有助于读者去理解,但是受限于篇幅,作者只能说接下来在该谈的时候会做介绍)
介绍完了研究动机、之前工作的局限性以及想要达到的目标,接下来就是作者提出自己的方法:
提出MoCo是为了给无监督的对比学习构造一个大而且一致的字典,具体的模型总览图如下图所示 :
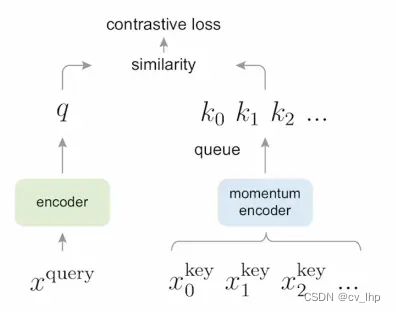
-
这个图和之前所画的对比学习的一般框架很相似
-
有query的图片,还有key的图片,这些图片通过一些编码器得到最后的特征,然后query的特征去跟所有的key的特征做类比,最后用对比学习的loss去训练整个模型
-
它和之前的那个框架有什么不同?queue和momentum encoder,这也是MoCo这篇论文的贡献所在
-
为什么要用一个队列去表示字典?主要还是受限于显卡的内存,如果字典太大,也就意味着要输入很多很多的图片,如果字典的大小是几千甚至上万的话,显卡的内存肯定是吃不消的,所以需要想一个办法,能让字典的大小跟每次模型去做前向过程时的batch size大小剥离开,于是作者想到了一个巧妙的办法:用队列的数据结构来完成这项任务。具体来说,就是这个队列可以很大,但是每次更新这个队列是一点一点进行的,也就是说当用一个很小的batch size的时候,现在这个batch抽得的特征进入队列,然后把最老的也就是最早的那个mini-batch移除队列,这样一下就把训练时用的mini batch的大小和队列的大小直接分开了,最后这个队列的大小,也就是字典的大小可以设的非常大,因为它大部分的元素都不是每个iteration都需要更新的,这样只用普通的GPU也能训练一个很好的模型
-
但是这个字典中的key最好要保持一致性,也就是说他们最好是用同一个或者说相似的编码器产生得到的。如果只有一小部分(也就是当前的batch)是从当前的编码器得到的,而之前的key都是用不同时刻的编码去抽取特征,就不一致了,所以作者又提出了一个改进:momentum(动量编码器)。
-
如果用上面的动量的概念来写一下数学表达式,如果现在的编码器用θ_q(θquery)代替,momentum encoder用θ_k(θkey)表示,那么θk的更新就可以表示为θ_k = m * θ_(k-1) + ( 1 - m ) * θ_q ,也就是说,虽然动量编码器刚开始是由旁边的编码器θ_q初始化而来的,但是模型的训练中选择了一个很大的动量,那么这个动量编码器θ_k其实是更新的非常缓慢的,而不会跟着θ_q快速地改变,从而保证了字典中所有的key都是由相似的编码器抽取得到的,尽最大可能地保持了他们的一致性
所以基于这两点贡献,MoCo可以构建一个又大又一致的字典,从而去无监督地学习一个视觉的表征。
选用什么代理任务去充当这个自监督信号,从而进行模型的训练?
因为MoCo只是建立中间模型的方式,它只是为对比学习提供了一个动态的字典,那么具体选择什么样的代理任务去做自监督学习?其实MoCo是非常灵活的,它可以跟很多代理任务合起来使用
在这篇论文中,作者选择了一个比较简单的instance discrimination任务(个体判别任务),选择它的原因不仅仅是因为它简单,也是因为它的效果确实非常好。
这个任务简单来说就是如果一个query和一个key是同一个图片不同的视角(比如说不同的随机裁剪得到的),那么就说这个query和这个key能配对,也就是说能在这个字典中查找到query对应的key,用了这个代理任务,MoCo在ImageNet数据集上做Linear Classification的时候,能跟之前最好的方法打个平手或者是有更好的表现 ,结果:
-
无监督的表征学习最主要的目的就是当在一个没有标注的数据集上做完预训练之后,预训练好的特征是能够直接迁移到下游任务的,MoCo就做到了这一点:
-
在七个下游任务(既有检测也有分割)上,MoCo这种无监督的预训练方式都能超越用ImageNet去做有监督的预训练方式,有的时候甚至还是大幅度的超越。因此重要性不言而喻,MoCo是第一个做到这么好结果的。
-
大家对无监督学习还有另外一个期待:就像在NLP中,如果用更多的数据,用更大的模型,希望这个模型的提升是永无止境的,最好不要有性能饱和的现象。所以作者这里为了实验的完整性又做了另外一组实验,作者除了把MoCo在ImageNet做预训练之外,还在facebook自己的10亿的Instagram数据集上也做了预训练,最后的结果还能提升,所以这也就证明了MoCo是可以在一个更偏向于真实世界而且有亿级规模图片的数据集上工作的很好。
-
relatively uncurated scenario:因为这个数据集并不是像ImageNet一样是精心挑选过、而且大部分图片都是只有一个物体在中间的,Instagram的图片的场景是相当丰富的,而且也会展示出真实世界中数据有的一些特性(比如说数据分类不均衡(长尾),或者说一张图片可能含有多个物体),所以和ImageNet比起来,可能从数据的挑选和标注上都没有那么严格。

因为MoCo不论是在中型数据集上做预训练还是在大型数据集上做预训练都能取得很好的结果,所以作者最后说,这些结果证实了MoCo可以在很多视觉任务上把无监督学习和有监督学习的坑填平,而且甚至可以在一些真实的任务上去取代之前大家一直使用的在ImageNet预训练的模型
MoCo的影响力就在于几乎所有的应用都可以换成使用MoCo无监督的训练方式训练好的模型,说不定效果还会更好。
二. 背景介绍:对比学习
MoCo这篇论文的写作是假定读者已经对对比学习有一定的了解了,如果对之前的工作不了解的话,这里就不理解为什么要做Momentum Contrast(动量对比学习),也无法体会到MoCo的精妙之处。
假如说有两张图,对比学习顾名思义就是对比着去学习,模型并不需要真的知道图片中代表的是什么,而只需要知道哪些图片是类似的,哪些图片是不一样的就可以了。
- 假如将这三张图片都通过一个网络m,然后得到三个特征f1、f2、f3,分别对应的就是三张图片的特征
- 假如说最后学好的三个特征是embedding space(特征空间)里的三个点,就希望对比学习能够将两个类似图片的特征尽量拉近,而让另外一个并不类似的特征尽量的远离那两个相似的特征点。如果真的能够做到将所有相似的物体都在这个特征空间里相邻的区域,而不类似的物体都在不相邻的区域的话,那么其实目的就已经达到了,学到的特征就会是一个很好的特征。
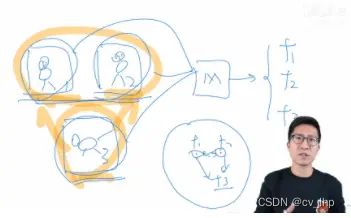
对比学习虽然不需要知道每张图里的标签信息,但是它还是需要知道哪些图片是类似的,也就意味着不还是需要标签信息去做这种有监督学习吗,也还是需要知道哪些图片是类似的,哪些图片不是类似的才能去做模型的训练,那么为什么对比学习在视觉领域一般被认为是无监督的训练方式呢?因为在视觉领域大家是通过设计一些巧妙的代理任务(pretext task),从而人为地定了一些规则,这些规则可以用来定义哪些图片是相似的,哪些图片不是相似的,从而可以提供一个监督信号去训练模型,这也就是所谓的自监督训练(自己监督自己训练)
例子:最广为应用的代理任务:instance discrimination (个体判别)
这个代理任务是说有一个没有标注的n张照片的数据集,x1、x2,一直到xn,那么该如何定义哪些图片是相似的,哪些图片不是相似的呢?
instance discrimination的做法是:
-
如果从这个数据集中选一张图片x_i,现在在这张图片上随机裁剪,从而得到另外两张图,一张是x_i1,另一张是x_i2(当然在裁剪之后,还做了很多的数据增广),这里把裁剪和增广都叫做transformation(x_i1和x_i2对应的裁剪和增广操作叫做T_1和T_2),最终可以得到两张看起来很不一样的照片,但是因为它们都是从同一张照片x_i经过某些变化得到的,它们的语义信息不应该发生变化,这两张照片被称为正样本
-
至于和x_i这张图片不相似的那些图片,instance discrimination这个代理任务认为这个数据集剩下的所有照片都可以被当作不相似,也就是说x_j(j≠i)这些样本相对于xi来说都是负样本
-
instance discrimination直译过来就是个体判别,因为在这个任务看来,每张图片都是自成一类的,剩下所有的图片都跟它不是一个类的,拿ImageNet举例的话,现在就不是有1000个类了,而是有100多万个类(1000*1000),因为每个图片都是它自己的类。
-
一旦有了这个代理任务,就知道了怎么样去定义正样本,怎么样去定义负样本,接下来就是通过一个模型,再去得到一些特征,然后在这些特征上使用一些常见的对比学习的目标函数(比如说NCE loss)就可以了,基本上这样一种框架就是对比学习里常见的一种学习方式了。
看起来好像平平无奇,但是对比学习最厉害的地方就在于它的灵活性,只要能够找到一种方式去定义正样本和负样本就足够了,剩下的操作都是比较标准的。这样可以打开脑洞去制定很多如何定义正样本和负样本的规则
-
比如说在视频领域,很多人就认为同一个视频中的任意两帧都可以认为是正样本,而其他视频中的所有帧都可以认为是负样本
-
在NLP领域里也可以这么使用,比如说SimSCE那篇论文就是把同样的句子扔给模型,但是做两次forward,每次forward使用不同的dropout,这样得到的两个特征作者认为是正样本,其它所有句子的特征就是负样本
-
还有在CMC这篇论文,作者认为一个物体的不同View(不同视角)也可以作为正样本,比如说一个物体的正面和背面、一个物体的RGB图像和一个物体的深度图像等这些都可以作为不同形式的正样本
以上也就说明了对比学习的灵活性,什么领域都能使用,自然而然后来也扩展到了多模态领域,也就造就了OpenAI的CLIP模型。
三. 标题和作者
标题:Momentum Contrast for Unsupervised Visual Representation Learning,MoCo的名字来源于前两个单词的前两个字母。
论文链接:https://arxiv.org/abs/1911.05722
代码链接:https://github.com/facebookresearch/moco
作者团队来自FAIR,他们5个人在google scholar上的引用加起来已经超过50万了,在各个视觉会议上也是拿奖拿到手软。
四. 动量方式:
用动量对比的方法去做无监督的表征学习,动量从数学上可以理解成一种加权移动平均:y_t = m * y_( t - 1 )+( 1 - m )* x_t
- m就是动量的超参数
- y_( t - 1 )是上一个时刻的输出
- y_t是这一时刻想要改变的输出
- x_t是当前时刻的输入
简单来说,就是不想让当前时刻的输出完全依赖于当前时刻的输入,所以这里引入了之前的输出,并且给了他一个权重。
因为这里动量的超参数m是介于0和1之间的数,如果m很大(趋近于1)的时候,y_t的改变是非常缓慢的,因为后面的1-m基本就趋近于0,也即是说不怎么依赖当前的输入,只依赖于前一时刻;反过来说,如果m很小的话,那就是说当前的输出更多地依赖于当前的输入,不依赖于前一时刻。
MoCo利用了动量的这种特性,从而缓慢地更新一个编码器,让中间学习的字典中的特征尽可能地保持一致。
五. 摘要
本文提出了MoCo去做无监督的表征学习,虽然是基于对比学习的,但是本文是从另外一个角度来看对比学习,也就是说把对比学习看作是一个字典查询的任务。具体来说,就是做一个动态的字典,这个动态的字典由两个部分组成:
- 第一个部分是一个队列,因为队列中的样本不需要做梯度回传,所以就可以往队列中放很多负样本,从而使得这个字典变得很大
- 第二个部分是一个移动平均的编码器,使用这个移动平均的编码器的目的是想让字典中的特征尽量的保持一致。作者发现在训练的过程中,如果能有一个很大而且比较一致的字典,会对无监督的对比学习非常有好处。
这篇论文主要的亮点在于它的结果,所以剩下大篇幅的摘要留给了结果:
- 分类:在ImageNet数据集上,如果使用大家普遍采用的linear protocol去做测试的话,MoCo能够取得跟之前最好的无监督学习方式差不多或者更好一点的结果。linear protocol:如果先预训练好一个骨干网络,当把它用到不同的数据集上的时候,将它的骨干网络冻住(backbone freeze),然后只去学习最后的那个全连接层,也就是分类头,这样就相当于把提前训练好的预训练模型当成了一个特征提取器,只用它来抽取特征,这样就可以间接证明之前预训练好的那个模型的特征到底好不好。
- 更重要的是MoCo学习到的特征能够很好地迁移到下游的任务,这才是整篇文章的精髓:MoCo作为一个无监督的预训练模型,能够在7个下游任务(分割、检测等)上,而且比如说在VOC、COCO这些数据集上超越之前的有监督的预训练模型,有时候甚至是大幅度超越
- 这里的counterpart是说模型使用的是一样的,比如说都是Res50,只是训练的方式不一样,一个是用有监督的带标签的数据去训练,一个是用无监督不带标签的数据去训练,如下图:
- 最后作者总结说,这就意味着对于很多视觉任务来说,无监督和有监督的表征学习中间的鸿沟已经填上了,之前虽然有一些无监督的工作能够在某个数据集或者是某个任务上能够比它对应的有监督预训练模型好一点,但是MoCo是第一个能够在这么多主流视觉任务上,全面地让无监督训练的模型比有监督训练的模型表现要好。
六. 相关工作
无监督学习(自监督学习,其实自监督学习是无监督学习的一种,但之前在前人的工作中大家一般不作区分,但是在本文中,作者选择了使用无监督学习这个词,因为定义的更加广泛一些)一般有两个方向可以做:
-
一个是在代理任务上做文章。代理任务一般是指的那些大家不太感兴趣的任务(不是分类、分割、检测这种有实际应用场景的任务),这些代理任务的提出,主要是为了学习一个好的特征。
-
一个是在目标函数上做文章。目标函数就比较广泛了,目标函数的研究其实是可以和代理任务分开的
MoCo主要是在目标函数上下功夫,它所提出的这个又大又一致的字典主要是影响后面InfoNCE目标函数的计算,这里的目标函数主要是针对无监督的方式来说的。
最常见的构建目标函数的方式,就是衡量一个模型的输出和它应该得到的固定的目标之间的差距:
-
比如说用auto-encoder(自编码器)的话,就是输入一张原图或者一张已经被干扰过的图,通过一个编码器解码器将这张图重建出来,这里既可以使用L1 loss,也可以使用L2 loss,但是总的来说,衡量的是原图和重新构建的图之间的差异,这种属于生成式网络的做法,因为是在生成一张图片。
-
如果是想走判别式网络,一般的做法有:eight position,它是15年的一篇论文,主要思想是说如果将一张图片打成九宫格,假如这个九宫格有序号(从1到9),现在先把中间5这一格拿到,然后再随机从剩下的八个格子中挑一格,看能不能预测出这个随机挑出来的这一格是位于中间这一格的哪个方位(左上、右下等等)。因为这里的每一块其实都是自带序号的,其实就相当于把这个代理任务转化成了一个分类任务,因为它只有八个方位可以去预测,所以这里就用了8个位置来代替这个方法。
-
除了判别式或者生成式这种常见的目标函数,还有对比学习的目标函数和对抗性的目标函数
-
对比学习的目标函数主要是去一个特征空间中衡量各个样本对之间的相似性,它所要达到的目标就是让相似物体的特征尽量拉近,不相似物体之间的特征尽量远离。对比学习的目标函数和生成式或者判别式目标函数有很大的区别:不论是判别式(预测8个位置)还是生成式(重建整张图),目标都是一个固定的目标,但是在对比学习中,它的目标是在训练的过程中不停的改变的(在训练的过程中,目标其实是由一个编码器抽出来的数据特征而决定的,也就是本文所指的字典,作者接下来说最近几篇效果不错的方法,它们的核心思想都是用的对比学习)
-
对抗性的目标函数在GAN这篇论文中也提到过,它主要衡量的是两个概率分布之间的差异。对抗性的目标函数主要是用来做无监督的数据生成的,但是后来也有一些对抗性的方法用来做特征学习,因为大家认为,如果能生成很好很真实的图片的话,按到底来说,它是已经学到了这个数据的底层分布,这样模型学出来的特征应该也是不错的
接下来就是代理任务这个方面,代理任务其实过去几年大家提出了非常多的形式:
-
denoising auto-encoder:重建整张图
-
context auto-encoder:重建某个patch
-
colorization:用给图片上色当作自监督信号
-
还有很多代理任务是去生成一些伪标签,像examplar image其实也是给同一张图片做不同的数据增广,它们都属于同一个类;patch ordering,也就是九宫格的方法,要么是打乱了之后去预测它的顺序,要么就是随机选一个patch去预测它的方位;还有利用视频的信息去做tracking,以及一些聚类的方法。
最后一段作者讨论了一下对比学习和之前这些不同的代理任务之间的关系
-
不同的代理任务是可以和某种形式的对比学习的目标函数配对使用的,比如说本文中使用的个体判别的方式就跟之前的examplar based代理任务很相关
-
对于之前两个比较重要的工作CPC和CMC来说,CPC做的是预测性的对比学习它是用上下文的信息去预测未来,这样就跟上下文自编码代理任务非常相关;对于CMC来说,它是利用一个物体的不同视角去做对比,这个就跟给图片上色的代理任务非常相似,因为给图片上色这个任务就涉及了同一个图片的两个视角(黑白和彩色)
总的来说,相关工作写的还是非常的简洁明了,之所以围绕目标函数和代理任务这两个方向去写相关工作,是因为这两个方面是主要跟有监督学习不一样的地方:
-
如果和有监督学习对比一下,假如有一个输入x,然后通过一个模型得到y(也就是输出),有了输出之后就去和一个ground truth做比较,然后需要一个目标函数去衡量一下这个比较的结果,这就是有监督学习的流程。
-
对于无监督学习或者是自监督学习来说,缺少的就是标签,也就是这里的ground truth,如果没有标签就自己造标签,这时候代理任务就派上用场了,代理任务的用处就是去生成一个自监督的信号,从而去充当ground truth这个标签信息,一旦有了输出y,又有了标签信息,接下来还需要一个目标函数去衡量他们之间的差异,从而让模型学得更好。
所以这就是为什么本文从目标函数和代理任务这两个角度去写相关工作。
七. 结论
MoCo的最后一部分不光是结论,主要的内容都围绕在了讨论上面,结论其实就是一句话,MoCo在一系列的方法和数据集上都取得了比较好的效果。
接下来就是讨论了两个比较有趣的问题:
- 通过实验,作者发现当预训练的数据集从ImageNet换到Instagram的时候,提升虽然是有的,但是都相对来说比较小,只有零点几个点或者一个点,但是数据集是从一百万增加到10亿了,扩大了一千倍,这样的提升着实是有点小,所以作者觉得是因为大规模的数据集没有被很好地利用起来,可能一个更好的代理任务有可能解决这个问题。
- 除了这个简单的个体判别任务,有没有可能把MoCo和另外一个代理任务(Masked auto-encoding)(MAE)结合起来用,就像NLP中的BERT一样,用masked language modeling完形填空去自监督地训练模型。
最后作者希望MoCo能够对其他那些使用对比学习的代理任务有帮助,之所以强调对比学习是因为MoCo设计的初衷就是去构造一个大的字典,从而让正负样本能够更有效地进行对比,提供一个稳定地自监督信号,最后去训练模型。
八. MoCo方法
总结以前对比学习方法:之前的对比学习以及最新的一些效果比较好的变体,它们都可以想象成是训练一个编码器,从而去做一个字典查找的任务。
假设有一个编码好的query q,也就是特征,还有一系列已经编码好的样本,也就是k0、k1、k2等,这些可以看作是字典中的那些key。
-
这里做了一个假设:在这个字典中只有一个key是跟query是配对的,也就是说它们两个互为正样本对,这个key叫做key positive。
之所以有这个假设,前面在讲个体判别任务的时候也提到过,这个代理任务就是从一个图片经过两种变换得到两种图片,其中一个作为基准图片,另外一个作为正样本,所以就是只有一个正样本对。当然理论上是可以使用多个正样本对,之后也有工作证明使用多个正样本对有可能会提升任务的性能。
一旦定义好了正样本和负样本,接下来就需要一个对比学习的目标函数,这个对比学习的目标函数最好能满足以下要求:
- 当query q和唯一的正样本k plus相似的时候,它的loss值应该比较低
- 当query q和其他所有的key都不相似的时候,这个loss的值也应该比较高
这个也是训练模型的目标,如果已经能够达到这么一种状态,就说明模型差不多训练好了,当然希望目标函数的loss值尽可能的低,就不要再去更新模型了;反之,如果q和正样本key plus不相似,或者说query q和本来应该是负样本的那些key相似,那么这个目标函数的loss值就应该尽可能的大,从而去惩罚这个模型,让模型加速更新它的参数。
在本文中,采取了一个叫做InfoNCE的对比学习函数来训练整个模型:
-
InfoNCE:先看下图中右边手写的式子,它是softmax的操作,那如果是在有监督学习的范式下,也就是有一个one-hot向量来当作ground truth,如下图所示:
-
其实在前面加上一个-log,整个其实就是cross entry loss,也就是交叉熵目标函数,但是需要注意的是下图红色圆圈圈出来的k在有监督学习中指的是这个数据集有多少个类别(比如说ImageNet就是1000类,k就是1000,是一个固定的数)
-
回到对比学习,其实对比学习理论上来说是可以用上面这个公式去计算loss的,但是实际上行不通。如果说像大部分对比学习的工作一样,就使用instance discrimination这个代理任务去当自监督信号的话,那这里的类别数k将会是一个非常巨大的数字,就拿ImageNet数据集来举例,这里的k就不再是1000了,而是128万,就是有多少图片就有多少类。
-
softmax在有这么多类别的时候,它其实是工作不了的,同时因为这里还有exponential操作,当向量的维度是几百万的时候,计算复杂度是相当高的,如果每个训练的iteration都要这样去计算loss,那么训练的时间将会大大延长。
所以就有了NCE loss(noise contrastive estimation的缩写),之前因为类别太多所以没办法计算softmax,从而没办法计算目标函数,NCE的做法是:将这么多的类简化成一个二分类问题,现在只有两个类别了:一个是数据类别data sample;一个是噪声类别noisy sample。
那么每次只需要拿数据样本和噪声样本做对比就可以了,也就是文中所说的noise contrastive。但是如果还是将整个数据集剩下的图片都当做负样本,那么其实noise contrastive estimatation解决了类别多的问题,但是计算复杂度还是没有降下来,那么该如何让loss计算的更快一点呢?没有别的办法,只有取近似了。
- 意思就是说,与其在整个数据集上算loss,不如就从这个数据集中选一些负样本来算loss就可以了,这也是这里estimation的含义,它只是估计、近似
- 但是按照一般的规律,如果选取的样本很少,就没有那么近似了,结果自然就会比较差。选的样本越多,自然就跟使用整个数据集的图片的结果更加近似,效果自然也会更好,所以这也是MoCo一直强调的希望字典足够大,因为越大的字典,越能够提供更好的近似。
总的来说,NCE这个loss就是把一个超级多类分类的问题变成了一系列的二分类的问题,从而让大家还是可以使用softmax操作
这里说的InfoNCE其实就是NCE的一个简单的变体,作者认为如果只把问题看作是一个二分类(只有数据样本和噪声样本)的话,可能对模型学习不是很友好,毕竟在那么多的噪声样本中,大家很有可能不是一个类,所以还是把它看成一个多分类的问题比较合理,于是NCE就变成了InfoNCE,公式如下图所示:
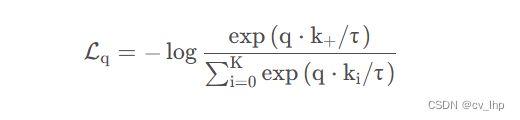
-
公式中的q * k_+,其实就相当于是logit,也可以类比为上面softmax中的z,也是模型出来的logit
-
公式中的τ是一个温度的超参数,这个温度一般是用来控制分布的形状的,τ的值越大,1/τ就越小,就相当于将分布中的数值都变小了,尤其是经过exponential之后就变得更小了,最后就会导致这个分布变得更平滑;相反,如果τ取得值越小,也就是1/τ越大,那么分布里的值也就相应的变大,经过exponential之后,原来大的值变得更大了,就使得这个分布更集中,也就变得更加peak了。
-
所以说温度这个超参数的选择也是很有讲究的,如果温度设的越大,那么对比损失对所有的负样本都一视同仁,导致学习的模型没有轻重;如果温度的值设的过小,又会让模型只关注那些特别困难的样本,其实那些负样本很有可能是潜在的正样本,如果模型过度地关注这些特别困难的负样本,会导致模型很难收敛,或者学好的特征不好去泛化。
但是温度这个超参数终究只是一个标量,如果忽略掉它,就会发现,其实这个InfoNCE loss就是cross entropy loss,唯一的区别就在于在cross entropy loss中k指代的是数据集里类别的多少,但是在对比学习的InfoNCE loss中,k指的是负样本的数量。 -
公式下面分母中的求和其实是在一个正样本和k个负样本上做的,因为是从0到k,所以是k+1个样本,也就指的是字典里所有的key
-
如果直观地想一下,InfoNCE loss就是一个cross entropy loss,它做的就是一个k+1类的分类任务,它的目的就是想把q这个图片分成k_+这个类。所以到这里可以发现,InfoNCE也不是那么难理解,和之前常用的cross entropy loss是有很大联系的
-
如果直接跳到后面MoCo的伪代码的话,也会发现MoCo这个loss的实现就是基于cross entropy loss实现的
既然已经有了这个代理任务提供的正负样本,也有了可以用来训练模型的目标函数输入和模型大概是什么?(这里作者还是从一个自顶向下的方式去写的)
普遍来说,query q是一个输入x_q通过一个编码器f_q得到的,同理所有的k的表示也都是key的输入通过了一个key的编码器,输入和模型具体的实现是由具体的代理任务决定。在代理任务不一样的时候,输入x_q和x_k既可以是图片,也可以是图片块,或者是含有上下文的一系列的图片块。
对于模型,query的编码器和key的编码器既可以是相等的(就是说模型的架构一样,参数也是完全共享的),或者说它们的参数是部分共享的,也可以是彻底不一样的两个网络。
(整个论文,每一段和每一段之间最好都有承上启下的段落,每当开始讲一个新的东西的时候最好先讲一下为什么需要它,一旦有了这个承上启下的段落,也就是因为所以的逻辑关系之后,论文读起来就会更加顺畅。否则论文上来每一段都是直接讲方法的话,很容易让人看得一头雾水,无论自己觉得写的有多清晰,读者可能从一开始就没明白为什么要这么做)
作者说从以上角度,对比学习是一种在高维的连续的输入信号上去构建字典的一种方式,这里的高维和连续其实指的就是图片。这个字典是动态的:
- 之所以是动态的是因为这个字典中的key都是随机取样的,而且给这些key做编码的编码器在训练的过程中也是在不停的改变
- 这和之前所讲的无论是在有监督还是无监督的方法都不太一样,因为之前的那些工作最后学习的target都是一个固定的目标,所以作者认为,如果想学一个好的特征,这个字典就必须拥有两个特性(大,大的字典能够包含很多语义丰富的负样本,从而有助于学到更有判别性的特征;一致性主要是为了模型的训练(保证模型数据近似一样的编码),能够防止模型学到一些trivial solution,也就是一些捷径解)
所以基于以上的研究动机,作者就提出了momentum contrast。
九. MoCo伪代码

- 首先定义了一些参数f_q、f_k,它们分别是query和key的编码器
- queue这个队列指的是字典,里面一共有k个key,所以它的维度是c*k,c指的是每个特征的维度
- m是动量
- t是算InfoNCE loss的时候的那个温度
整个模型的前向过程:
-
首先初始化两个编码器,对于query编码器f_q来说,它是随机初始话的,然后将f_q的参数直接复制给f_k,这样就把f_k也初始化了
-
接下来从data loader里拿一个batch的数据,这里数据用x表示,它有n个sample(在MoCo的代码中,默认的batch-size就是256,也就是n等于256,所以是非常标准的batch-size,是可以在常用的GPU上进行训练的)
-
接下来的第一步就是得到一个正样本对,所以从原始的数据x开始,先做一次数据增强,得到一个query的图片,然后再去随机的做一次数据增强,得到一个key的图片,因为这个query和key都是从同一个数据x得到的,它的语义不应该发生太大的变化,所以这个x_q、x_k就成为了一个正样本对
-
接下来将query的数据通过query的编码器做一次前向,从而得到真正的特征q,q的特征维度是nc,也就是256128
-
为了便于理解,这里再具体化一些,假如编码器f_q、f_k就是一个Res50的网络,Res50等到最后一层做完global average pooling之后会得到一个2048维的特征
-
一般如果是在ImageNet数据集上去做有监督训练的时候,会加一个分类头,将这个2048维变成1000维,这样就可以做分类了
-
这里作者就是将1000换成了128,也就是说从2048维变成了128维
-
这里为什么使用128?其实是为了跟之前的工作保持一致,也就是之前memory bank的工作(文献61)。memory bank这篇文章中,为了让整个memory bank变得尽可能的小,所以特征的维度选的也相对比较小,只有128
-
通过编码器f_k得到正样本的那个key的维度也是256*128
-
因为是pytorch的代码,所以用了detach操作将gradient去掉,这样对于key来说就没有梯度回传了,反正也是要放到队列中去的
-
下一步就是计算logit,也就是之前公式1中算InfoNCE loss的时候的分子(q * k_+),这样就得到了正样本的logit,它的特征维度就变成了n * 1,(256,1)
-
如何计算负样本的logit?首先从队列中把负样本拿出来,也就是代码中的queue,接下来就是计算公式1中InfoNCE的分母,也就是对query * k_i相乘(i是从0到k的),做完了这一步的乘法之后,就得到了负样本的logit,也就是n * k,所以就是256 * 65536(因为MoCo中默认的字典大小是65536)
-
最后总体的logit(既有正样本又有负样本,所有的logit拼接起来)就变成了256 *65537的一个向量,也就是像公式1中所说的,现在所做的其实就是k + 1路的分类问题
-
一旦有了正负样本的logit,接下来就是算loss了,这里其实就是用了一个cross entropy loss去实现的,既然是交叉熵loss,肯定就得有一个ground truth(作者在这里巧妙地设计了一个全零的向量作为ground truth,之所以使用全零,是因为按照作者的这种实现方式,所有的正样本永远都是在logit的第一个位置上,也就是位置0,所以对于正样本来说,如果找对了那个key,在分类任务中得到的正确的类别就是类别0,所以巧妙地使用了这种方式创建了一个ground truth,从而计算出了对比学习的loss)
-
有了loss之后,自然就是先做一次梯度回传,有了梯度之后就可以去更新query的编码器了
-
接下来就到了MoCo的第二个贡献(动量更新),因为不想让f_k变得太快,所以f_k的参数大部分都是从上一个时刻的参数直接搬过来的,只有非常少的一部分是从当前更新过的f_q中拿过来的,这样就保证了key network是缓慢更新的
-
最后一步是更新队列,将新算的key放进队列中,然后将最老的key从队列中移出
读完伪代码,应该是对MoCo有了一个更全面的了解,建议查看MoCo的官方代码,写的极其出色,非常简洁明了,而且基本上就跟伪代码一模一样。
十. 文章贡献
10.1 第一个贡献:如何把一个字典看成队列
作者说,方法的核心其实就是把一个字典用队列的形式表现出来
- 队列其实就是一种数据结构,如果有一个队列,里面有很多元素,假如新来的元素从下面进来,为了维持这个队列的大小,最老的数据会从队列中出去,所以说队列一般被称作是一个FIFO(first in first out,先进先出)的数据结构,如下图所示:
- 作者在这里是用一个队列去代表一个字典,也就是说整个的队列就是一个字典,里面的元素就是放进去的key
- 在模型训练的过程中,每一个mini-batch就会有新的一批key被送进来,同时也会有一批老的key移出去,所以用队列的好处是可以重复使用那些已经编码好的key,而这些key是从之前的那些mini-batch中得到的,比如说队尾指的是当前mini-batch送进来的新key,那么紧挨着它上面的那些key就是在它之前的那些mini-batch编码好送进来的
- 这样使用了队列之后,就可以把字典的大小和mini-batch的大小彻底剥离开了,就可以在模型的训练过程中使用一个比较标准的mini-batch size,一般是128或者是256,但是字典的大小可以变得非常大,它的大小非常灵活,而且可以当作一个超参数一样单独设置
这个字典一直都是所有数据的一个子集,在算对比学习目标函数的时候只是取一个近似,而不是在整个数据集上算loss
使用队列的数据结构,可以让维护这个字典的计算开销非常小,事实也是如此,如果把字典的大小从几百变到几千或者上万,整体的训练时间基本是不变的。
最后作者又强调了为什么要使用队列这个数据结构:因为队列有先进先出的特性,这样每次移出队列的都是最老的那些mini-batch,也就是最早计算的那些mini-batch,这样对于对比学习来说是很有利的,因为从一致性的角度来说,最早计算的那些mini-batch的key是最过时的,也就是说跟最新的这个mini-batch算的key是最不一致的
10.2 文章的第二个贡献:如何使用动量的思想去更新编码器
用队列的形式当然可以使这个字典变得更大,但是也因为使用了非常大的字典,也就是非常长的队列,就导致没办法给队列中所有的元素进行梯度回传了,也就是说,key的编码器无法通过反向传播的方式去更新它的参数。
- 如果想更新这个key的编码器,其实有一个非常简单的方法:就是每个训练iteration结束之后,将更新好的编码器参数fq直接复制过来给key的编码器fk就可以了
- 这个想法简单确实是简单,但是作者紧接着说这种方式的结果并不好,原因是一个快速改变的编码器降低了这个队列中所有key的特征的一致性。
- 假如现在有一个队列如上图所示,新的元素从左边进来,旧的元素从右边出去,假设mini-batch size就是1,也就是说每次只更新一个key,k1、k2等这些所有的key都是由不同的编码器产生的,这样的话这些快速改变的编码器就会降低所有key之间的一致性。
所以作者提出了动量更新的方式来解决这个问题:如果将key编码器f_k参数设为θ_k,query编码器f_q的参数设为θ_q,那θ_k就是以以下公式所示的动量改变方式进行更新的。
- 上式中m是动量参数,它是一个0到1之间的数
- θ_q,也就是query编码器,是通过梯度反向回传来更新它的模型参数的
- θ_k除了刚开始是用θ_q初始化以外,后面的更新大部分主要是靠自己,因为如果动量参数m设的很大,那么θ_k更新就非常缓慢,所以作者接下来说,因为使用了这种动量更新的方式,虽然在队列里的key都是由不同的编码器产生得到的,但是因为这些编码器之间的区别极小,所以产生的key的一致性都很强
- 为了强调这一观点,作者说,他们在实验中使用了一个相对比较大的动量0.999,意思就是每次θ_k更新的时候,99.9%都是来自原来的编码器参数,只有0.1%是从更新好的θ_q中借鉴过来的,自然而然的,θ_k的更新就非常缓慢了
- 作者还做了对比实验,当他把这个动量变小一点,变成0.9的时候(其实0.9也不算小了),作者说使用一个相对较大的动量0.999比0.9效果要好得多,所以就意味着,如果想充分利用好队列,一个缓慢更新的key编码器是至关重要的,因为它可以保证这个队列里所有的key是相对一致的。
到这里,其实MoCo的主要贡献就已经讲完了,但是如果对对比学习不是很熟的人来说可能还是不太理解MoCo的前向过程到底是什么样子的,可惜的是这篇论文并没有提供一个很直观、形象的模型总览图,取而代之的是伪代码,写得相当简洁明了,理解和复现都比较容易。
十一. 两种架构
作者在引言中提到过,之前的那些对比学习方法都可以看作是字典查找,但是它们都或多或少受限于字典的大小和字典的一致性的问题,这里作者将之前的方法总结了一下,归纳成了两种架构:
11.1 第一种就是比较直接的端到端学习的方式
端到端学习,顾名思义就是编码器都是可以通过梯度回传来更新模型参数的。
下图的标题中也写道编码器q和k可以是不同的网络,但是之前很多工作都用的是同样的网络,为了简单起见,MoCo实验中编码器q和k是同一个模型,也就是一个Res50。
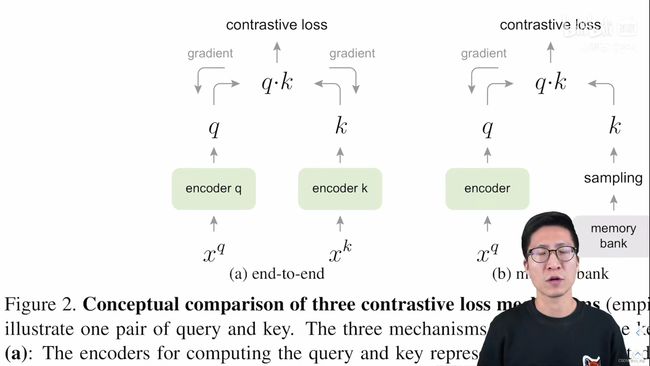
- 这里为什么可以使用同一个模型?因为模型的正负样本都是从同一个mini-batch里来的,也就是x_q和x_k都是从同一个batch中来的,它做一次forward就能得到所有样本的特征,而且这些样本是高度一致的,因为都是来自一个编码器。
- 听起来确实很美好,编码器都能用反向回传学习了,特征也高度一致了,但是它的局限性就在于字典的大小,因为在端到端的学习框架中,字典的大小和mini-batch size的大小是等价的,如果想要一个很大的字典,里面有成千上万个key的话,也就意味着mini-batch size的大小必须也是成千上万的,这个难度就比较高了。因为现在的GPU是塞不下这么大的batch-size的,而且就算有内存够大的硬件,能塞下这么大的batch-size,但是大的batch-size的优化也是一个难点,如果处理不得当,模型是很难收敛的。
- 所以作者说这种端到端学习的方式受限于字典的大小,之所以选择读MoCo这篇论文而不是SimCLR,是因为SimCLR就是这种端到端的学习方式,它还用了更多的数据增强,而且提出了在编码器之后再用一个projector,会让学到的特征大大变好,但是总体来说SimCLR就是端到端的学习方式,之所以这么做,是因为google有TPU,TPU内存大,所以可以无脑上batch-size,SimCLR中选用了8192当作batch-size,这样最后就会有10000多个负样本,这个负样本的规模就足够对比学习了,所以SimCLR就可以用这么简单的方式直接去做端到端的学习。
- 端到端学习的优点在于编码器是可以实时更新的,所以导致它字典里的那些key的一致性是非常高的,但是它的缺点在于因为它的字典大小(就是batch-size的大小),导致这个字典不能设置的过大,否则硬件内存吃不消。
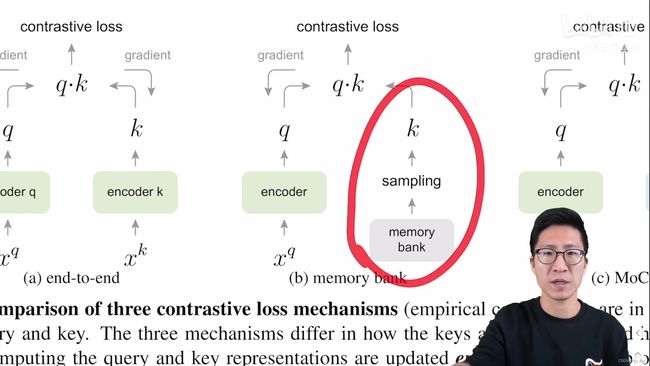
11.2 memory bank(更关注字典的大小,而牺牲一些一致性)
- 在memory bank中其实就只有一个编码,也就是query的编码器是可以通过梯度回传来进行更新学习的。
- 但是对于字典中的key是没有一个单独的编码器的
- memory bank把整个数据集的特征都存到了一起,对于ImageNet来说,memory bank中就有128万个特征(看上去好像很大,但是memory bank的作者在论文中说,因为每一个特征只有128维,所以即使整个memory bank中有128万个key,最后也只需要600M的空间就能把所有的这些key存下来了,即使是对整个数据集的特征做一遍最近邻查询,在泰坦XGPU上也只需要20毫秒,所以是非常高效的)。
- 一旦有了这个memory bank,在每次模型做训练的时候,只需要从memory bank中随机抽样很多的key出来当作字典就可以了,就相当于下图中红色圆圈圈出来的整个右边的那些操作都是在线下执行的,所以完全不用担心硬件内存的问题,也就是字典可以抽样抽的很大,但是有得必有舍,memory bank的做法在特征一致性上就处理的不是很好
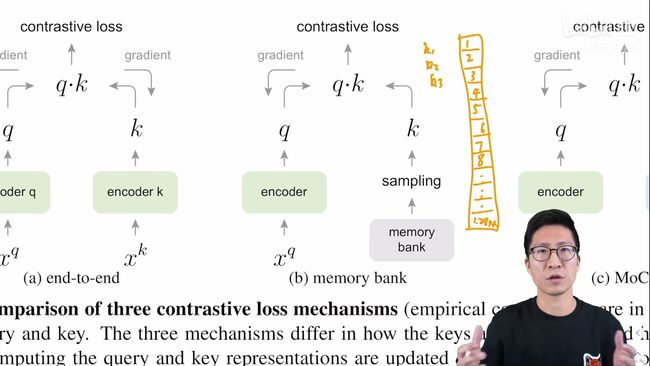
- 假如说有一个memory bank如下图所示,里面有128万个key,它在训练的时候是随机抽样很多样本出来当作字典,这里为了方便讲解,将它简化为顺序抽样而且字典的大小就是3,也就是说当在做对比学习的时候,当前用的mini-batch可以先把k1、k2、k3这三个key抽出来当作负样本,然后去和query计算loss
- 算完这个loss,回传的梯度更新了左边的编码器encoder之后,memory bank的做法就是会用新的编码器在原来对应的位置上,也就是k1、k2、k3的位置上的那些样本去生成新的特征,也就是下图中蓝色的新的k1、k2、k3,然后把新的key放回到memory bank中就把memory bank更新了
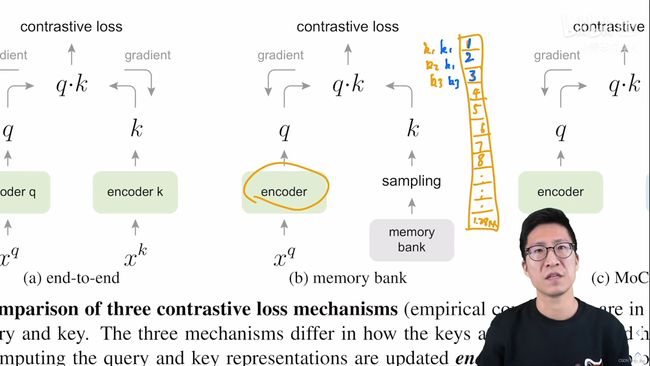
- 依此类推,下一次假如是将4、5、6这三个key抽出来做一次模型更新,然后再把新的key4、5、6放回去,那么4、5、6也就被更新了。
- 这里也就有一个问题:因为这里的特征都是在不同时刻的编码器得到的,而且这些编码器都是通过梯度回传来进行快速更新的,这也就意味着这里得到的特征都缺乏一致性
- 而且memory bank还有另外一个问题,因为memory bank中存储了所有的图片,也就意味着模型训练了整整一个epoch才能把整个memory bank更新一遍,那也就意味着,当开始下一个epoch训练的时候,假如选了三个key,那这三个key的特征都是上一个epoch不知道哪个时间点算出来的特征了,这也就导致query的特征和key的特征差的特别远,key的特征也很不一致。
- 所以总结一下,memory bank的做法就是牺牲了特征的一致性,从而获得了可以构造很大的字典的特权。
11.3 MoCo:解决字典大小和特征一致性的问题
显然,无论是端到端的学习还是memory bank的方法,都和作者说的一样,受限于字典大小和特征一致性这两方面中的至少一个,所以为了解决之前这两种做法的局限性,作者就提出了MoCo
- MoCo采用队列的形式去实现字典,从而使得它不像端到端的学习一样受限于batch-size的大小
- 同时为了提高字典中特征的一致性,MoCo使用了动量编码器
- 其实从整体上来看,MoCo跟Memory bank的方法是更加接近的,它们都只有一个编码器(query的编码器,它是通过梯度回传来更新模型参数的),它们的字典都是采取了额外的数据结构进行存储从而和batch-size剥离开了,memory bank中使用了memory bank,而MoCo中使用了队列
- memory bank这篇论文(文献61)也意识到了特征不一致性所带来的坏处了,所以作者当时还加了另外一个loss(proximal optimization),目的就是为了让训练变得更加平滑,这其实和MoCo中的动量更新是有异曲同工之效的
- MoCo的作者也提到memory bank这篇论文中也提到了动量更新,只不过它的动量更新的是特征,而MoCo中动量更新的是编码器,而且MoCo的作者还补充说MoCo的扩展性很好,他可以在上亿级别的图像库上进行训练。
- 但是对于特别大的数据集memory bank的方法就捉襟见肘了,因为它需要将所有的特征都存到一个memory bank中,对于ImageNet这种百万规模的数据集来说,存下的特征只需要600兆的空间,但是对于一个拥有亿级图片规模的数据,存储所有的特征就需要几十G甚至上百G的内存了,所以memory bank的扩展性不如MoCo好
总之,MoCo既简单又高效,而且扩展性还好,它能同时提供一个又大而且又一致的字典,从而进行对比学习
十二. 代理任务
作者为了简单起见,使用了个体判别的任务,个体判别任务的定义:通过对一个样本x经过不同的数据增强方式得到两个样本x_q,x_k,这两个样本当成一个正样本,语义信息没有改变,而剩下的字典中所有2(N-1)个样本当成负样本,语义信息不同,这里是针对每个样本来做的。如下图所示:
十三. MoCo论文中的小trick:Shuffling BN
(这个操作在接下来很多论文里,甚至包括作者团队接下来的工作,比如SimSiam也没有再用Shuffling BN这个操作了)
因为用了BN以后,很有可能造成当前batch里的样本中间的信息的泄露,因为BN要计算这些样本的running mean和running variance,也就是说,它能通过这些泄露信息很容易地找到正样本,而不需要真正地去学一个好的模型(也就是作者所说的模型会走一条捷径)
如何解决这个问题?:Shuffling BN
因为BN这个操作大部分时候都是在当前GPU上计算的,所以作者在做多卡训练之前,先把样本的顺序打乱再送到所有的GPU上去,算完了特征之后再回复顺序去算最后的loss,这样的话对loss是没有任何影响的,但是每个GPU上的BN计算就不一样了(因为正样本不是原来那个顺序,从而模型找不到正样本的位置,防止模型走一条捷径解),就不会再存在信息泄露的问题了。
类似的BN操作还在后续BYOL那篇论文中引起了一段很有意思的乌龙事件,总之,BN操作让人又爱又恨,用的好威力无穷,但是90%的情况都是属于用的不好的,会带来各种莫名其妙的问题,而且很难去debug,所以现在换成transformer也好,这样直接就用layer norm,就能暂时不用理会BN了。
十四. 试验
14.1 数据集的使用
- 在做无监督的预训练的时候,使用了标准的ImageNet数据集
- 为了验证MoCo的扩展性好,还使用了facebook自己的Instagram 1Billion的数据集
- ImageNet一般都叫做ImageNet 1k,因为它有1000个类别,但是作者这里叫ImageNet 1 million,在MoCo的论文中使用的是个体判别的任务,所以类别数不再是1000,而是整个数据集图片的数量,也就是1 million。
- Instagram这个数据集作者在之前的引言中也提到过,他和ImageNet有一些不一样的特性:它展示了真实的世界中数据的分布(长尾的、不均衡的);同时他的图片既有那种只有一两个物体的,也有有很多物体或者是场景层面的图片。
14.2 训练的情况
- 因为还是CNN时代,所以还是使用的SGD当成优化器
- 对于ImageNet数据集来说,作者用的是标准的batch-size 256在一台8卡机上进行训练
- 如果是使用Res50网络结构的话,训练200个epoch大概需要53个小时
- 相对于SimCLR、SwAV或者BYOL这些工作,MoCo不论是从硬件本身还是从训练时长上,都已经是最affordable的方法了,其实后面还可以了解到,MoCo或者MoCoV2这一系列的方法,它们的泛化性能非常好,在做下游任务的时候,学到的特征依旧非常强大,所以看起来SimCLR的引用会比MoCo稍微高一些,但是其实真正在视觉领域里,大家在别的任务上使用对比学习的时候,绝大多数工作都是沿用的MoCo的这套框架。
14.3 结果
1、作者分成了两大部分进行了结果的展示,Linear Classification Protocol:将训练好的模型当作一个特征提取器
- 在完成了无监督学习的预训练之后,将模型的backbone冻住,只将它作为一个特征提取器,然后在上面训练一个全连接层去充当分类头,训练这个分类头用了100个epoch。
- 结果的衡量是在ImageNet的测试集上,包括了1-crop、top-crop的准确度
- 作者做了一个grid search,然后发现最佳的学习率是30。这个其实是很不可思议的,因为除了在神经网络搜索(NAS)的那些工作里可能会搜到一些比较夸张的学习率之外,过去几十年里用神经网络的工作,都没有用超过1的学习率,因为已经预训练好了一个网络,所以只需要做微调就可以了,所以学习率最大可能也就是设个0.1,然后0.01、0.001这样往下降,很少有人会设一个比1大的学习率,但是在这里竟然是30。所以说做无监督学习或者说是做对比学习的人可以看一下学习率,如果结果不好,很有可能是学习率没有设置对。
- 基于这个现象,作者也做了总结,这个学习率确实比较诡异,它暗示了这种无监督对比学习学到的特征分布跟有监督学习学到的特征的分布是非常不同的。
1.1 第一个消融实验,如下图所示:
- 这个消融实验主要是用来对比三种对比学习的流派:端到端学习(end to end)、memory bank和本文提到的MoCo
- 横坐标用k表示,指的是用了多少个负样本,也可以粗略地理解为字典的大小
- 纵坐标指的是在ImageNet数据集上的top one的准确率,也就是Linear Classification Protocol下的准确率
- 黑色的线表示的是端到端的学习,它的结果只有三个点,因为受限于显卡内存(用一台8卡v100内存32g的机器能塞下的最大的batch-size只有1024)
- 蓝色的线表示的是memory bank的形式,它可以用很大的字典,所以它可以走得很远,但是它的效果整体上要比端到端学习和MoCo的结果都要差一截。作者说这是因为特征的不一致性导致的
- 橙色的线表示MoCo,MoCo确实可以有很大的字典,之所以停在65536这个数字,从下图中可以看到,从16384到65536性能也已经比较饱和了,所以再大也可能不会带来更多的性能提升了。如果拿MoCo和端到端学习的方法做比较,可以发现,它们的曲线在刚开始的时候的重合度还是比较高的,但是作者说,因为没有实验的支撑,不知道黑线是否能继续按照现有的趋势继续增长下去,有可能结果会更高,也有可能结果会更低,但是因为做不了实验,所以无从得知。
所以基于下图所示,MoCo是性能最好,对硬件要求最低,而且扩展性也比较好的方法。
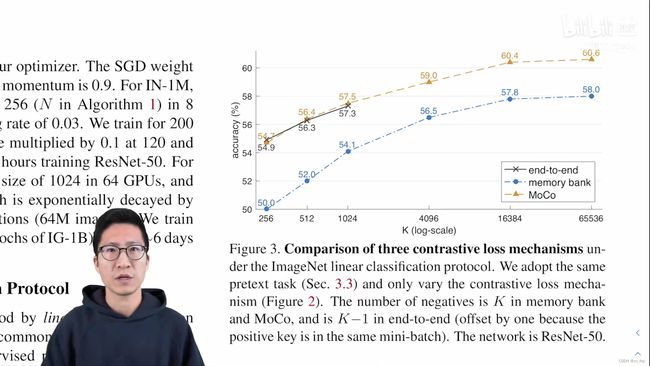
1.2 第二个消融实验:
这个消融实验是为了证实本文的第二个贡献,也就是动量更新带来的好处,如下图所示(在写论文的时候,如果是自己提出了有几点贡献,那就一定得做针对这几点贡献的消融实验,这样才能证明提出的贡献是有效的,否则口说无凭)
- 动量使用一个相对较大的值0.999或者0.9999的时候性能是最好的,差不多都是59,这就说明了一个变化非常缓慢的编码器是对对比学习有好处的,因为它能够对字典提供一个一致性的特征。
- 但是当把动量逐渐变小,变到0.99或者是0.9的时候,性能的下降就比较明显了,尤其是当直接去掉动量,直接将快速更新的query编码器拿过来当key编码器用的时候,就会发现不光是性能下降的问题,整个模型甚至都不能收敛,loss一直在震荡,从而导致训练失败
- 这个table非常有力地证明了作者的论点,就是要建立一个一致性的字典
1.3 ImageNet数据集上效果的比较:
下图中所有的方法都是在Linear Classification Protocol下面进行的,也就是说都是把这个网络当成一个特征提取器,抽出特征再去训练一个全连接层当作分类头,最后得到结果,所有的结果都没有更新backbone。
- 表格中上半部分都不是使用的对比学习,下半部分都是使用的对比学习
- 首先可以发现,对比学习的效果还是不错的,因为明显准确率要比没有使用对比学习得到得结果要好
- 作者还强调:在无监督学习中,模型的大小还是非常关键的(模型越大,一般效果就会越好),所以只是比较最后的准确度,而不去关注模型大小的话,就不太公平了,所以作者在表格中列出了所使用的网络结构以及网络的模型参数大小,这样就可以做一个相对全面而且相对公平的比较了
- 比如只看标准的Res50,它的模型参数都是24million,MoCo要比之前的结果高两个点,已经算是很大的提升了,如果不对模型架构做限制,MoCo只用375million就已经能达到68.6了,还是比之前的方法都要高的。
- 作者在有的准确度后面加了特殊标记,有这些特殊标记的方法都用了fast auto augment做了数据增强,而这个数据增强的策略之前是在ImageNet用有监督的训练方式训练得到的,这就有一点不太公平
- 对于CMC来说,其实是用了两个网络,而不是只是一个网络,所以它其实是47M(两个24)
- 但是不论是用了更好的数据增强,还是用了两个甚至是更多的编码器,总而言之,MoCo既能在小模型上得到最好的效果,也能在大模型的比较中得到最好的结果。
2、迁移学习的效果
文章的最后一个章节,也是全文的点睛之笔,作者就是想验证一下MoCo预训练模型得到的特征到底在下游任务上能不能有好的迁移学习效果。
无监督学习最主要的目标就是学习一个可以迁移的特征。
有监督的预训练:用ImageNet做有监督的预训练,它最有用、最有影响力的时候就是在下游任务上做微调,可以用这个预训练模型做模型的初始化,从而当下游任务只有很少的标注数据的时候也能获得很好的效果
作者用视觉领域中最常见、应用最广的检测任务来做无监督的MoCo预训练模型和ImageNet的有监督预训练模型之间的比较。
2.1 归一化
- 如果拿MoCo学出来的模型直接当一个特征提取器的话,那它在做微调的时候的最佳学习率是30,也就说明MoCo学到的特征跟有监督学到的特征的分布是非常不一样的,但是现在需要拿这个特征去做下游的任务,不可能在每个下游任务上都去做一遍grid search找一下它最佳的学习率是多少,这个相对来讲比较麻烦,也失去了无监督预训练的意义,所以作者就想,如果可以拿之前有监督的预训练已经设置好的超参数来做微调的话,既可以做公平对比,而且也不用做grid search。
- 一般来说,当分布不一致的时候,最常想到的方法就是归一化,所以作者这里使用了特征归一化的方法,具体来说就是整个模型现在都在微调,而且尤其是BN层(作者用的是sync BN,也就是synchronized batch norm,就是将多机训练的所有GPU上的batch norm的统计量都合起来,算完running mean、running variance之后再做BN层的更新,这样就会让特征的归一化做的更彻底一点,也会让模型的训练更稳定一些)。
- 在新加的层中,比如说在做检测的时候都会用fbn的结构,作者在这里也用了BN,目的就是去调整一下值域的大小,从而便于做特征的归一化
- 一旦做完归一化之后,作者发现就可以拿有监督训练用的超参数来做微调了。
2.2 schedule
- 作者之前有一篇论文(文献31)发现:当下游任务的数据集足够大的时候,可以不需要预训练,直接从随机初始化开始从头训练,最后的效果一样可以很好。有了这个结论,无论是有监督的预训练还是无监督的预训练就都无所谓了,反正已经不需要预训练的模型去做初始化了,这样就没办法体现MoCo的优越性了
- 但是在文献31中说的是当训练足够长的时候,也就是训练6或者9的学习时长的时候,如果训练的短的话,预训练模型还是有用的,那么就在训练时长短的时候做比较就可以了
- 所以在本文中,作者说只用1或者2的学习时长,这个时候预训练还是非常有用的,就可以比较到底是MoCo预训练的好还是有监督的ImageNet的训练好了
总之,归一化和学习时长都是为了铺垫:当使用MoCo的预训练模型去做微调的时候,微调也是跟有监督预训练模型在微调时候的方式是一样的,这样做的好处是当在不同的数据集或者不同的任务上做微调的时候,就不用再去做调参搜索了,就用之前在有监督模型微调 调好的参数就行了。
- 作者补充说这么做可能对MoCo来说是不利的,因为如果针对提出的方法做超参搜索的话,有可能得到更好的结果
- 但即使是这样,MoCo的表现也都还是很好的
- 在pascal VOC数据集上做检测的结果如下图所示

- 表a和表b分别是用了两种不同的网络结构,每一个表格中都是四行
- 第一行使用的是随机初始化的模型再做微调,所以它是一个基线网络,分数比较低
- 第二行使用的是有监督的ImageNet的预训练的模型做初始化然后再做微调,也就是一个比较强的极限结果
- 最后两行分别是MoCo在ImageNet上和在Instagram 1Billion上做无监督预训练当作模型的初始化,然后再做微调
- 除了表a中的第三行的第一个结果MoCo是略微不如有监督预训练的模型,在其他所有的衡量指标下MoCo 就已经超过了有监督的预训练模型
- 当换成更大的数据集Instagram 1Billion的时候还会有进一步的提升,其实Instagram 1Billion带来的提升都不是很大,只有零点几个点
接下来作者又再次比较了三种对比学习的方式:端到端学习、memory bank、MoCo,前一次对比是在ImageNet做Linear Classification Protocol下面做测试,现在是在下游任务上再做一次对比,如果还是MoCo最好的话,说服力就比较强了,如下图说示:
MoCo和前面两种方式比起来确实是好了很多,而且最主要的是之前的两种方法都没有超越有监督预训练模型的结果,只有MoCo是真的超越了。
在COCO数据集上作者比较了四个设置:
- 前两个用的都是Res50 fbn,但是学习时长不一样,一个是1*,一个是2*
- 后面两行用的是res50 c4的结构,一个是1*,一个是2*
- 除了在设置a里面MoCo的模型稍显逊色,在剩下的三个设置下,MoCo预训练的模型都比ImageNet有监督预训练模型得到的效果要好
作者又测试了别的不同的任务:
- keypoint detection人体关键点检测
- pose estimation姿态检测
- 实例分割
- 语义分割
基本的结论还是MoCo预训练的模型在大部分时候都比ImageNet的预训练模型要好,即使偶尔比不过也是稍显逊色
作者最后总结:MoCo在很多的下游任务上都超越了ImageNet的有监督预训练模型,但是在零零星星的几个任务上,MoCo稍微差了一点,主要是集中在实例分割和语义分割的任务上,所以接下来大家也都怀疑对比学习的方式是不是不太适合做dence prediction的task,就是这种每个像素点都要去预测的任务,所以后续也涌现了很多基于这个出发点的工作,比如dence contrast或者是pixel contrast之类。
十五. 结论
-
文章最后的结论:MoCo在很多的视觉任务上,已经大幅度的把无监督和有监督之间的坑给填上了
-
最后作者强调MoCo在Instagram数据集中是要比ImageNet训练出来的模型要好的,而且是在所有任务上普遍表现的都很好,这说明了MoCo的扩展习惯很好,也就是说如果有更多的数据,MoCo有可能就能学到更好的模型,这和NLP中得到的结论是一样的,这也符合了无监督学习的终极目标。但是使用了更大的数据集,提升的点很少,平均只有0.5-1.0个点左右,可能与MoCo使用的是个体判别这个代理任务来进行预训练有关
-
MoCo这篇论文以及它高效的实现,能让大多数人有机会用普通的GPU就能跑对比学习的实验,做研究
-
因为MoCo在各个视觉任务上取得了更好的性能,也激发了很多后续分析性的工作,去研究MoCo学出来的特征到底和有监督学出来的特征有什么不同,还能从别的什么方向去提高对比学习