对比学习论文——[MoCo,CVPR2020]Momentum Contrast for Unsupervised Visual Representation Learning
目录
- 对比学习简述
- MoCo的创新动机
- loss function:InfoNCE
- MoCo的流程伪代码
- 实验和结论
对比学习简述
假设由三张图片,其中两张是人,一张是狗。将三张图片都通过同一个神经网络,得到特征空间中的三个特征 f 1 f_1 f1, f 2 f_2 f2, f 3 f_3 f3,假设前两个是人对应的特征,后一个是狗对应的特征。对比学习要做的就是让 f 1 f_1 f1和 f 2 f_2 f2在特征空间中尽可能接近,并且两者都要和 f 3 f_3 f3保持距离。
要注意这三张图片都是无标签的,但是对比学习需要知道哪两张是类似的图片(两张人的图),等价于还是需要标签信息。所以对比学习通过设计pretext task(代理任务),从而人为定义一些规则,说明哪些图片是相似的(需要在特征空间中尽可能接近),哪些图片是不相似的,从而定义一些监督信号去训练模型,这就是所谓的自监督训练。
举个例子,有个代理任务叫“instance discrimination”(⚠️MoCo采用的代理任务就是它,但注意作者说了MoCo很灵活,能和很多代理任务相结合),直译过来叫“个体判别”。具体做法是,假设有 N N N张图片 X 1 X_1 X1, X 2 X_2 X2,…, X N X_N XN,取图片 X 1 X_1 X1,对其进行裁剪和数据增广,获得两张图 X 1 1 X_1^1 X11和 X 1 2 X_1^2 X12。这两张图看上去可能很不一样,但是由于都是在同一张图片的基础上变换而来的,所以我们认为它们的语义信息不应该有太大的差异,所以就将这两张照片成为正样本(严格来讲是一张图片为anchor,另一张图片为正样本)。同时instance discrimination认为此时数据集中剩下的 N − 1 N-1 N−1张图片都是和 X 1 X_1 X1不相似的,所以说这些图片都是负样本。接下来就可以让这些样本通过神经网络,得到特征空间中的特征,正样本对应的特征应该尽可能接近,负样本则应该尽可能远离,这是由对比学习的目标函数实现(比如NCE loss,在后文中会讲到)。
这样一来,就可以大开脑洞去制定定义正样本和负样本的规则,比如视频领域,可以定义同一个视频中的帧是正样本,其他视频中的帧是负样本。
MoCo的创新动机
MoCo将对比学习视为字典查询任务:具体而言,anchor通过神经网络后得到的特征为query,正样本和负样本通过神经网络后得到的特征都是key(key们组成一个字典),这样一来对比学习就可以视为一个字典查询问题。所以MoCo很少用anchor和正负样本这些字眼,取而代之的就是query和key。看看作者给出的三种对比学习机制的对比:
![对比学习论文——[MoCo,CVPR2020]Momentum Contrast for Unsupervised Visual Representation Learning_第1张图片](http://img.e-com-net.com/image/info8/ef69b4dbdc16404eb00861b32b5f54ac.jpg)
第一种,是通过两个encoder分别得到query和key,然后让query和正样本对应的key在特征空间中尽可能接近,和负样本对应的key在特征空间中尽可能远离。由于两个encoder都要用梯度下降法进行训练,所以字典不能太大(字典的大小是计算一次contrastive loss时用到的key的个数,或者一次前向传播时通过encoder k获得的特征的个数,这个和batchsize是高度相关的,两者数量相似)。
第二种,不知道是什么,先不管它,不影响对MoCo的理解。(在b站李沐MoCo视频56分钟左右,很简单)字典中key的一致性不是很好(一致性consistency是什么,往后看就能逐渐了解)
第三种,是MoCo采用的机制,相比于第一种,是将encoder k替换为momentum encoder,并且这个encoder不再使用梯度下降法进行更新。MoCo的字典大小不再和batchsize有相近的数量,而是可以远大于batchsize。具体做法是用一个队列表示字典,当前batch得到的key加入队列,并且将最早进入队列的几个key出队,这样字典的大小就不受batchsize的限制。
⚠️接下来就是MoCo的创新点:思考上述队列,并且注意力放在上图的©中。假设采用的是批梯度下降法,那么每个batch进来后,都会改变encoder的参数(通过梯度下降),并且momentum encoder也需要进行更新。现在注意作者提出的假设:
字典应该large and consistent。
所谓large,指的是字典的大小应该非常大,这样里面就包含足够多的语义丰富的负样本,对于学习自然就是有利的,有助于学到更有判别性的那些特征。但是由于字典非常large,所以没有办法对momentum encoder采用梯度下降的方式进行更新,因为梯度会传递给队列中的所有样本,而样本数量非常大(因为字典是large的)。所以momentum encoder要用别的方式进行更新,但是要注意它每次不能更新太多,因为这样一来,队列中的特征将会是用很不一样的encoder生成的,就缺失了一致性。
比较暴力的方式是,通过每个batch更新query的encoder后,直接将它的参数复制给key的encoder,这样效果不太好,作者认为可能的原因是一致性不太好(encoder改变太快导致queue中很多key都是差别较大的encoder生成的)。用momentum update的方式就能更好保证一致性consistency。这就是为什么作者说字典不仅应该是large,还应该是consistent。具体地,momentum encoder更新方式如下:
![]()
θ k \theta_k θk是momentum encoder的参数, θ q \theta_q θq是生成query的encoder的参数。意思是说momentum encoder的参数随着生成query的encoder的参数的更新而更新,但是会将m设置成很接近1的值,以避免更新太快。这样字典中的key都是由参数差不多的encoder生成,就能够保证consistency。(文中作者说m为0.999的效果比0.9的效果要好)
总之,MoCo的创新关键词就是:large和consistent。
loss function:InfoNCE
假设一个batch有 K + 1 K+1 K+1张图片 X 0 X_0 X0, X 2 X_2 X2,…, X K X_K XK,为了简便,选取 X 0 X_0 X0,令它通过query的encoder获得query q;同时令 X 0 X_0 X0, X 2 X_2 X2,…, X K X_K XK通过momentum encoder生成key { k 0 , k 1 , . . . , k K } \{k_0,k_1,...,k_K\} {k0,k1,...,kK}。显然,在字典中和q match的key就只有 k 0 k_0 k0,我们称它为 k + k_+ k+,q应当和 k + k_+ k+相似,和其他k不相似。
所谓InfoNCE,公式如下:
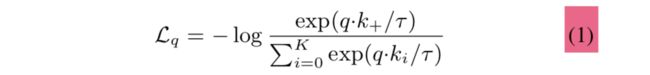
不看-log的话,十分像softmax。直观上来讲,可以视为对q进行分类,类别有 { k 0 , k 1 , . . . , k K } \{k_0,k_1,...,k_K\} {k0,k1,...,kK},上式就是要将q分类为 k 0 k_0 k0类别,即 k + k_+ k+类别。 τ τ τ是temperature hyper-parameter per,用于控制分布的形状,不做深究。上式其实可以直接使用交叉熵损失函数来实现,相当于做的是K+1类的分类问题。
关于NCE和InfoNCE,以及后者和交叉熵的区别,详见b站李沐视频——MoCo的40分钟左右的讲解。
MoCo的流程伪代码
![对比学习论文——[MoCo,CVPR2020]Momentum Contrast for Unsupervised Visual Representation Learning_第2张图片](http://img.e-com-net.com/image/info8/8aebdbd0a87e4c6dbab257c700d548ee.jpg)
通过仔细分析上述伪代码,彻底搞懂MoCo的流程。首先从loader中取一个batch的图片x,x表示N张图片。分别对x进行两次随机的数据增强,得到x_q和x_k。接下来,将两者分别通过生成query的encoder和生成key的encoder,获得q和k。q表示queries,有N个query,每个的维度都是C;k表示keys,有N个key,每个的维度都是C。所谓logits,就是指公式(1)中的 q ⋅ k q·k q⋅k,如果是相匹配的q和k,那么就得到positive logits,如果不匹配,就得到negative logits。注意队列中所有的key都是和当前batch生成的q不匹配的。每个q都对应有1个positive logits,K个negative logits。然后通过交叉熵损失函数实现InfoNCE。然后对生成query的encoder进行梯度下降法的更新,对生成key的encoder进行momentum的更新。最后将本轮的key加入队列,并将最早入队的几个key出队。这个伪代码不算很难理解,由此,我们就知道了MoCo的运作流程。
实验和结论
其他任务多数用的都是MoCo这套框架;MoCo相对来讲对计算资源需求较小(视频原话是:已经很良心了)。
其他的之后再补充,主要先了解MoCo和对比学习原理流程。