使用中文预训练模型 bert-wwm 获得字向量和词向量
使用中文预训练模型 bert-wwm 获得字向量和词向量
- 1.下载
- 2.解压
- 3.使用bert获得字向量和词向量
通过下载模型的形式,要比直接调用库的快很多。
1.下载
链接:github (使用宽带打不开的话可尝试手机热点)
打开以后是这样滴:
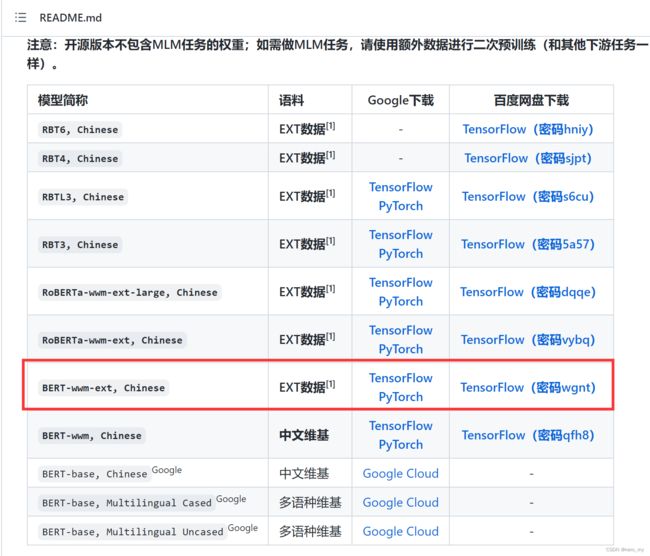
我下载了这个版本的PyTorch,大小不到 0.5G(并不知道有什么区别,随便下的)
2.解压
解压之后里面有三个文件,需要把 bert_config.json 改名为 config.json

3.使用bert获得字向量和词向量
import torch
from transformers import BertTokenizer,BertModel
tokenizer = BertTokenizer.from_pretrained('bert') # 包含上面三个文件的文件夹目录
model = BertModel.from_pretrained('bert')
input_ids = torch.tensor(tokenizer.encode("自然语言处理")).unsqueeze(0) # Batch size 1
print(input_ids)
outputs = model(input_ids)
# last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
sequence_output = outputs[0]
pooled_output = outputs[1]
print(sequence_output)
print(sequence_output.shape) ## 字向量
print(pooled_output.shape) ## 句向量
输出结果:
tensor([[ 101, 5632, 4197, 6427, 6241, 1905, 4415, 102]])
tensor([[[-0.5152, -0.0859, 0.8517, ..., -0.0063, -0.4380, -0.0603],
[ 0.2122, -0.4674, 0.7332, ..., -0.0799, -0.2016, 0.6670],
[ 0.1858, -0.6106, -0.0027, ..., -0.2438, -0.1905, 0.4633],
...,
[ 0.1136, 0.2130, 1.3360, ..., -0.1908, 0.3598, 0.0100],
[-0.2338, -0.1829, 0.8073, ..., -0.1682, 0.5623, 0.1589],
[-0.1665, 0.2620, 1.2459, ..., -0.2552, -0.1596, 0.0035]]],
grad_fn=<NativeLayerNormBackward>)
torch.Size([1, 8, 768])
torch.Size([1, 768])
参考:https://blog.csdn.net/sarracode/article/details/109060358