Kaggle树叶分类Leaves Classify总结
Kaggle树叶分类Leaves Classify总结
- 前言
- 工具准备
-
- pytorch可视化
-
- 安装visdom
- visdom例程
- 数据增强库
-
- torchvision
- CutMix
- 程序预处理准备
-
- 创建树叶种类标签枚举体
- 自定义Dataset
- 准确率计算模块
- Transform
- DataSet & DataLoader
- 数据集处理前后对比
-
- 处理前
- 处理后
- 优化器
- 训练模块
- 主程序
- 预测结果
前言
作为初学者,在Kaggle上获得了最高95.6%的识别准确率的一个及格成绩,本文作为总结和分享
Kaggle Classify Leaves竞赛地址

工具准备
pytorch可视化
使用Visdom进行数据可视化的操作
安装visdom
pip install visdom
或者到visdom的github下载后到根目录安装
https://github.com/fossasia/visdom
cd visdom
pip install -e .
在terminal输入以下命令启动visdom
visdom
或
python -m visdom.server
启动visdom后,如果出现
Downloading scripts, this may take a little while
请不要按照visdom服务启动时提示Downloading scripts, this may take a little while解决办法所说下载script替换,这样会导致server在浏览器打开后图像不会实时更新的问题
直接上梯子等一会就行
由于我是python3.8,所以会出现NotImplementedError
参照关于Python3.8运行Visdom.server抛出NotImplementedError异常的解决方法即可
成功启动后显示
Checking for scripts.
It's Alive!
INFO:root:Application Started
You can navigate to http://localhost:8097
在浏览器中输入http://localhost:8097即可打开
visdom例程
import torch
from torchvision.models import AlexNet
from torch.optim.lr_scheduler import CosineAnnealingLR
from visdom import Visdom
import time
visdom = Visdom()
# 创建一个初始点位为(0, 0),window句柄为test,标题为test的图像窗口
visdom.line(Y=[0], X=[0], win='test', opts=dict(title='test', legend=['test1', 'test2']))
numEpochs = 75
model = AlexNet(num_classes=2)
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
scheduler1 = CosineAnnealingLR(optimizer,T_max=numEpochs)
for epoch in range(numEpochs):
optimizer.zero_grad()
optimizer.step()
scheduler1.step()
updatedLearningRate1 = scheduler1.get_last_lr()[0]
# 将图像加入visdom
visdom.line(Y=[updatedLearningRate1], X=[epoch], win='test', update='append', name='test1') # name需要与legend对应
visdom.line(Y=[epoch*0.001], X=[epoch/10], win='test', update='append', name='test2')
time.sleep(0.1)

数据增强库
torchvision
具体请参照玩转pytorch中的torchvision.transforms
CutMix
pip install git+https://github.com/ildoonet/cutmix
程序预处理准备
创建树叶种类标签枚举体
import pandas as pd
# 树叶种类标签枚举体
leavesLabels = sorted(list(set(pd.read_csv('classify-leaves/train.csv')['label'])))
ELeavesLabels = dict(zip(leavesLabels, range(len(leavesLabels))))
# 类别数量
nClass = len(leavesLabels)
# 再转换回来,最后预测的时候使用
ELeavesLabelsInverse = {}
for label, index in ELeavesLabels.items():
ELeavesLabelsInverse[index] = label
自定义Dataset
# 继承pytorch的dataset,创建自己的
class CLeavesData(Dataset):
def __init__(self, csv_path, file_path, mode='unknown', valid_ratio=0.2, transform=None):
"""
Args:
csv_path (string): csv 文件路径
file_path (string): 图像文件所在路径
mode (string): 训练模式还是测试模式
valid_ratio (float): 验证集比例
"""
self.file_path = file_path
self.mode = mode
self.transform = transform
# 读取 csv 文件
self.data_info = pd.read_csv(csv_path)
# 计算 数据长度和训练集长度
self.data_length = len(self.data_info.index) - 1
self.train_length = int(self.data_length * (1 - valid_ratio))
if mode == 'train':
# 第一列包含图像文件的名称
self.train_image = np.asarray(self.data_info.iloc[:self.train_length, 0])
# 第二列是图像的 label
self.train_label = np.asarray(self.data_info.iloc[:self.train_length, 1])
self.image = self.train_image
self.label = self.train_label
elif mode == 'valid':
self.valid_image = np.asarray(self.data_info.iloc[self.train_length:, 0])
self.valid_label = np.asarray(self.data_info.iloc[self.train_length:, 1])
self.image = self.valid_image
self.label = self.valid_label
elif mode == 'test':
self.test_image = np.asarray(self.data_info.iloc[:, 0])
self.image = self.test_image
elif mode == 'unknown':
print('请指定模式')
return
self.sample_length = len(self.image)
print('Finished reading the {} set of Leaves Dataset ({} samples found)'
.format(mode, self.sample_length))
def __getitem__(self, index):
# 读取图像文件
# 从image中得到索引对应的文件名
single_image_name = self.image[index]
single_image = Image.open(self.file_path + single_image_name)
# 应用transformers
if self.transform is not None:
single_image = self.transform(single_image)
if self.mode != 'test':
# 得到图像的 string label
label = self.label[index]
# number label
label_number = ELeavesLabels[label]
return single_image, label_number #返回每一个index对应的图片数据和对应的label
else:
return single_image
def __len__(self):
return self.sample_length
准确率计算模块
def EvaluateAccuracy(net, data_iterator, device=None):
"""Compute the accuracy for a model on a dataset using a GPU."""
if isinstance(net, torch.nn.Module):
net.eval() # Set the model to evaluation mode
if not device:
device = next(iter(net.parameters())).device
# accuracy = number of correct predictions / number of predictions
metric = d2l.Accumulator(2)
for X, y in data_iterator:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), d2l.size(y))
return metric[0] / metric[1]
Transform
由于树叶分类主要特征是树叶的形状,所以只对图像的形状角度进行数据增强,亮度饱和度等提升效果不大
trainTransform = transforms.Compose([
# 随机拉伸并裁切224x224大小的图片
transforms.RandomResizedCrop(size=224, scale=[0.64, 1.0], ratio=[1.0, 1.0]),
# 随机水平翻转
transforms.RandomHorizontalFlip(p=0.5),
# 随机垂直翻转
transforms.RandomVerticalFlip(p=0.5),
# # 随机锐化
# transforms.RandomAdjustSharpness(sharpness_factor=10),
# # 随机曝光
# transforms.RandomSolarize(threshold=0.3),
# # 随机更改亮度,对比度和饱和度
# transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),
# 随机应用下列transform
transforms.RandomApply([
# 随机旋转
transforms.RandomRotation([-45,45], fill=[255, 255, 255]), # 填充白色
# 仿射变换
transforms.RandomAffine(degrees=[-30,30], translate=[0, 0.2], scale=[0.8, 1], fill=[255, 255, 255]),
]),
transforms.ToTensor(),
# 标准化图像的每个通道
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]),
# 随机擦除部分图像
transforms.RandomErasing(),
])
validTestTransform = transforms.Compose([
transforms.Resize(256),
# 从图像中心裁切224x224大小的图片
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
])
DataSet & DataLoader
# 建立自己的训练集,验证集和测试集
trainData = CLeavesData(filePath + 'train.csv', filePath, mode='train', transform=trainTransform)
validData = CLeavesData(filePath + 'train.csv', filePath, mode='valid', transform=validTestTransform)
testData = CLeavesData(filePath + 'test.csv', filePath, mode='test', transform=validTestTransform)
# 将训练集进行CutMix处理
trainAData = CutMix(dataset=trainData, num_class=176, beta=1.0, prob=0.5, num_mix=2)
trainDataLoader = DataLoader(
dataset=trainAData,
batch_size=batchSize,
shuffle=False, # 是否随机打乱顺序
num_workers=3, # CPU核心分配数
# 固定CPU核心分配则在切换读取训练集和验证集二者之间多线程不用重新分配核心,节省训练时间
persistent_workers=True, # 固定处理数据集的CPU核心
)
validDataLoader = DataLoader(
dataset=validData,
batch_size=batchSize,
shuffle=False,
num_workers=3,
persistent_workers=True,
)
testDataLoader =DataLoader(
dataset=testData,
batch_size=batchSize,
shuffle=False,
num_workers=6,
)
数据集处理前后对比
处理前

处理后
import matplotlib.pyplot as plt
def imageConvert(tensor):
image = tensor.to("cpu").clone().detach()
image = image.numpy().squeeze()
image = image.transpose(1,2,0)
image = image.clip(0, 1)
return image
fig=plt.figure(figsize=(20, 12))
columns = 4
rows = 4
inputs, classes = iter(trainDataLoader).next()
for index in range (columns*rows):
ax = fig.add_subplot(rows, columns, index+1, xticks=[], yticks=[])
plt.imshow(imageConvert(inputs[index]))
plt.show()

优化器
# CutMix包推荐使用的损失函数
criterion = CutMixCrossEntropyLoss(True)
# Adam优化器的变种,优点是对鲁棒性强,对学习率敏感度不高
optimizer = torch.optim.AdamW()
# cos函数学习率
scheduler = CosineAnnealingLR(optimizer,T_max=21/20*num_epochs) # 使最后几个epoch的学习率不接近0
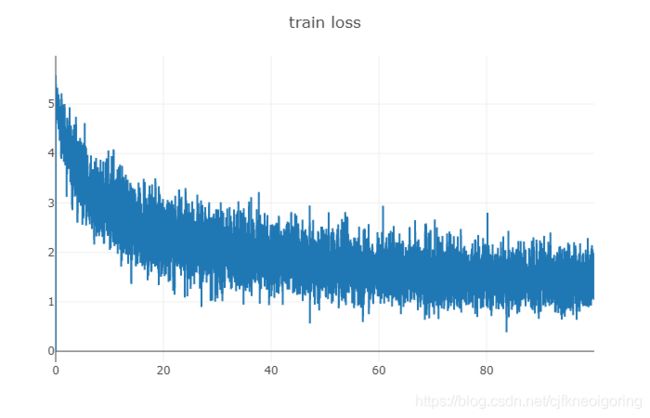
训练模块
def train(net, train_iterator, valid_iterator, num_epochs, learning_rate, weight_decay, device):
print('training on', device)
net.to(device) # 将数据集放入GPU
# 选择损失函数,优化器和学习率
criterion = CutMixCrossEntropyLoss(True)
optimizer = torch.optim.AdamW(net.parameters(), lr=learning_rate, weight_decay= weight_decay)
scheduler = CosineAnnealingLR(optimizer,T_max=21/20*num_epochs)
# 在visdom中画入初始点位
best_accuracy = 0
visdom.line(Y=[0], X=[0], win='accuracy', update='append', name='valid accuracy')
# 开始计时
timer, num_batches = d2l.Timer(), len(train_iterator)
timer.start()
for epoch in range(num_epochs):
net.train() # 进入训练模式
for i, (X, y) in enumerate(train_iterator):
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
train_loss = loss.item()
train_accuracy = d2l.accuracy(y_hat, y) / X.shape[0]
n_iteration = (epoch * num_batches + i)
# 在visdom中画入训练损失和准确率
if n_iter % 10 == 0:
visdom.line(Y=[train_loss], X=[(n_iteration +1)/num_batches], win='train_loss', update='append')
visdom.line(Y=[train_accuracy], X=[(n_iteration +1)/num_batches], win='accuracy', update='append', name='train accuracy')
print(f'epoch: {epoch}, train loss: {train_loss:.3f}train accuracy: {train_accuracy:.3f}, learning rate: {optimizer.param_groups[0]["lr"]:.9f}')
scheduler.step() # 更新学习率
# 计算验证集准确率,并画入visdom
valid_accuracy = EvaluateAccuracy(net, valid_iterator)
visdom.line(Y=[valid_accuracy], X=[epoch+1], win='accuracy', update='append', name='valid accuracy')
print(f'epoch: {epoch}, valid accuracy: {valid_accuracy:.3f}')
# 储存最好的模型
if valid_accuracy > best_accuracy:
best_accuracy = valid_accuracy
torch.save(net.state_dict(), 'BestModel')
print(f'已储存当前最优模型,精度{best_accuracy:.3f}')
# 训练结束,停止计时
timer.stop()
print(f'train completed\n'
f'loss {train_loss:.3f}, train accuracy ,'
f'valid accuracy {valid_accuracy:.3f}, best accuracy {best_accuracy:.3f}')
print(f'total training time: {timer.sum()/60:.1f} minutes')
主程序
由于是在windows系统下进行python的多线程操作,整个训练函数都需要在main中运行,不然num_worker > 0时分配多线程会报错
Pytorch生成的DataLoader被iter或者enumerate调用后卡死的原因
因为dataloader读取一张图片后,会先将其进行既定的transform操作,多线程操作可以图片迅速被处理完,使得GPU充分被利用(>95%),否则会频繁在cpu和gpu处理中切换,拖累训练速度
class需要放在另一个python文件中加载进来,否则多线程会报未定义class的错误
预处理需要放在主函数中调用,不然会重复执行多次额外占用内存
if __name__ == '__main__':
# 启动visdom
visdom = Visdom()
# 创建一个(0, 0)作为起点,window id作为'train_loss',标题为train loss的窗口
visdom.line(Y=[0], X=[0], win='train_loss', opts=dict(title='train loss'))
# 创建一个(0, 0)作为起点,window id作为'accuracy',标题为accuracy的窗口
visdom.line(Y=[0], X=[0], win='accuracy', opts=dict(title='accuracy', legend=['train accuracy', 'valid accuracy']))
######################################################################
# 不使用迁移学习,
isPreTrained = False
net = resnest50(pretrain=isPreTrained)
if isPreTrained:
net.load_state_dict(torch.load('ModelPath'))
# 冻结所有层的梯度计算
for name, parameter in net.named_parameters():
parameter.requires_grad = False
# 重定义全连接层后requires_grad自动为True
net.fc = nn.Linear(net.fc.in_features, nClass)
######################################################################
trainTransform = transforms.Compose([
# 随机拉伸并裁切224x224大小的图片
transforms.RandomResizedCrop(size=224, scale=[0.64, 1.0], ratio=[1.0, 1.0]),
# 随机水平翻转
transforms.RandomHorizontalFlip(p=0.5),
# 随机垂直翻转
transforms.RandomVerticalFlip(p=0.5),
# # 随机锐化
# transforms.RandomAdjustSharpness(sharpness_factor=10),
# # 随机曝光
# transforms.RandomSolarize(threshold=0.3),
# # 随机更改亮度,对比度和饱和度
# transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),
# 随机应用下列transform
transforms.RandomApply([
transforms.RandomRotation([-45,45], fill=[255, 255, 255]),
# 仿射变换
transforms.RandomAffine(degrees=[-30,30], translate=[0, 0.2], scale=[0.8, 1], fill=[255, 255, 255]),
]),
transforms.ToTensor(),
# 标准化图像的每个通道
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]),
transforms.RandomErasing(),
])
validTestTransform = transforms.Compose([
transforms.Resize(256),
# 从图像中心裁切224x224大小的图片
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
])
######################################################################
# 建立自己的训练集,验证集和测试集
trainData = CLeavesData(filePath + 'train.csv', filePath, mode='train', transform=trainTransform)
validData = CLeavesData(filePath + 'train.csv', filePath, mode='valid', transform=validTestTransform)
testData = CLeavesData(filePath + 'test.csv', filePath, mode='test', transform=validTestTransform)
# 将训练集进行CutMix处理
trainAData = CutMix(dataset=trainData, num_class=176, beta=1.0, prob=0.5, num_mix=2)
trainDataLoader = DataLoader(
dataset=trainAData,
batch_size=batchSize,
shuffle=False, # 是否随机打乱顺序
num_workers=3, # CPU核心分配数
# 固定CPU核心分配则在切换读取训练集和验证集二者之间多线程不用重新分配核心,节省训练时间
persistent_workers=True, # 固定处理数据集的CPU核心
)
validDataLoader = DataLoader(
dataset=validData,
batch_size=batchSize,
shuffle=False,
num_workers=3,
persistent_workers=True,
)
testDataLoader =DataLoader(
dataset=testData,
batch_size=batchSize,
shuffle=False,
num_workers=6,
)
######################################################################
learningRate = 1e-4
numEpochs = 100
weightDecay = 1e-3
# 开始训练
train(net, trainDataLoader, validDataLoader, numEpochs, learningRate, weightDecay, d2l.try_gpu())
预测结果
# 读取模型并预测
print("读取模型")
net.load_state_dict(torch.load('BestModel'))
device = d2l.try_gpu()
net.to(device)
print(EvaluateAccuracy(net, validDataLoader, device=device))
print("开始预测")
net.eval()
predictions = None
with torch.no_grad():
for index, image in enumerate(testDataLoader):
prediction = net(image.to('cuda')).argmax(1).detach().cpu()
if predictions is None:
predictions = prediction
else:
predictions = torch.cat([predictions, prediction])
print('预测完成,保存文件')
submission = pd.read_csv('classify-leaves/sample_submission.csv')
submission.label = predictions.cpu().numpy()
submission.label = submission.label.apply(lambda x: ELeavesLabelsInverse[x])
submission.to_csv('classify-leaves/submission.csv', index=False)