Hbase架构与存储组件结构与功能
文章目录
- HBase宏观架构
-
- Master
- RegionServer
- Region
- HDFS
- ZooKeeper
- Region
-
- WAL(预写日志)
-
- 关闭/打开WAL
- 延迟(异步)同步写入WAL
- WAL滚动
- WAL文件归档
- Store
-
- MemStore
- HFile
-
- Data
-
- BlockType(块类型)
- KeyValue类(Cell)
- HBase实现增删改成
-
- 真正删除发生的时候
HBase宏观架构
架构图
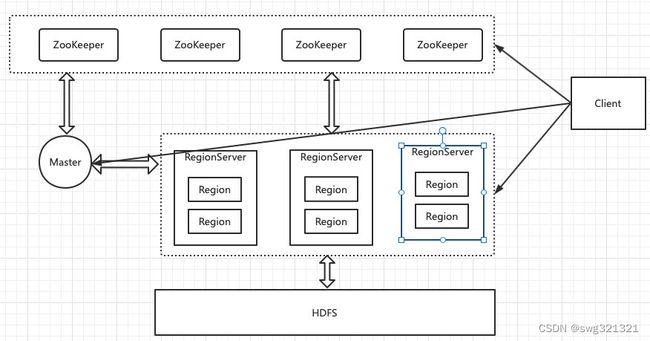
Master
负责启动的时候分配Region到具体的RegionServer,执行各种管理操作,如:Region的分割与合并、创建表、修改列族配置等操作。
RegionServer
存在一个或多个Region,所有的数据是存储在Region上的。Region所有数据存取都是调用HDFS的客户端实现的。
Region
表的一部分数据。HBase是一个会自动分片的数据库。一个Region就相当于关系型数据库中分区表的一个分区。
HDFS
HBase并不直接跟服务器的硬盘交互,而是跟HDFS交互,HDFS是真正承载数据的载体。
ZooKeeper
HBase中组件的高可用是基于ZooKeeper实现,以及元数据一般都是存储在ZooKeeper上的。
Region
一个RegionServer会存在一个或多个Region。
Region相当于一个数据分片,每个Region都有起始rowkey和结束rowkey,代表它所存储的Row范围。
架构图
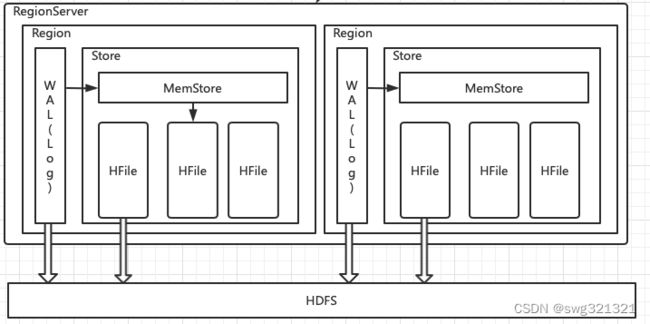
WAL(预写日志)
WAL(Write-Ahead Log),当操作到达Region的时候,HBase会先将操作写入WAL中,在把数据放到基于内存实现的MemStore中,等到数据达到一定的数量时才刷写(flush)到最终存储的HFile中。当遇到故障的时候可以根据WAL恢复数据。
操作类型有:Put、Append、Increment、Delete。当操作到达时会立即被写入WAL中,写入调用的是HDFS客户端接口写入HDFS的。
关闭/打开WAL
WAL模式默认是开启的,可以通过调用下列语句关闭WAL。
Meutaion.setDurability(Durability.SKIP_WAL);
还可以关闭/开启指定操作类型的WAL。这样虽然可以让数据操作更快一点,当服务器宕机时,会导致数据丢失。
延迟(异步)同步写入WAL
通过异步写入WAL,可以让数据操作更快一点,但是也会导致部分数据丢失。
WAL异步写入,调用方法
Meutaion.setDurability(Durability.ASYNC_WAL);
WAL滚动
WAL是一个环状的滚动日志结构,因为这种结构可以写入效果最高,而且可以保证空间不会持续变大。
WAL的检查间隔由hbase.regionserver.logroll.period定义,默认值1小时。检查的内容是把当前WAL中的操作跟实际持久化到HDFS上的操作比较,看哪些操作已经别持久化了,被持久化的操作就会被移动到.oldlogs文件夹内(也存储在HDFS上)。
一个WAL实例包含多个WAL文件。WAL文件的最大数量通过hbase.regionserver.maxlogs定义,默认值32。
触发滚动的条件:
- 当WAL文件所在的快(Block)快要满了。
- 当WAL所占空间大于或等于某个阀值,计算公司
hbase.regionserver.hlog.blocksize * hbase.regionserver.logroll.multiplier。
hbase.regionserver.hlog.blocksize:存储系统块(Block)大小,一般是HDFS的块大小即可,不设定HBase会自己去尝试获取这个参数的值。
hbase.regionserver.logroll.multiplier:默认0.95,如果WAL文件所占空间大于或等于95%的块大小,则这个WAL文件就会被归档到.oldlogs文件夹中。
WAL文件归档
WAL文件被创建出来后会被放在/hbase/.log下,一旦WAL文件被归档,则会被移动到/hbase/.oldlogs文件夹下。
Master会负责定期地清理.oldlogs文件夹,条件是”当这个WAL不需要作为用来恢复数据的备份“时候。判断条件是”没有任何引用指向这个WAL文件“,才会被系统彻底删除。
- TTL进程:该进程会保证WAL文件一直存活直到hbase.master.logcleaner.ttl定义的超时时间(默认10分钟)为止。
- 备份(replication)机制:如果开启了HBase的备份机制,那么HBase要保证备份集群已经完全不需要这个WAL文件了,才会删除这个WAL文件。
备份:是把一个集群的数据实时备份到另外一个集群,如果就一个集群就不需要考虑这个因素。
Store
一个Region可能包含多个Store实例。一个Store对应一个列族的数据,Store内部含有MemStore和HFile这两个组件。
每个Store只有一个MemStore实例,多个HFile实例。当MemStore满了之后HBase就会在HDFS上生成一个新的HFile,然后把MemStore中的内容写到HFile中。
MemStore
数据被写入WAL之后就会被加载到MemStore中,当MemStore的大小增加到超过一定阀值的时候就会被刷写到HDFS上,以HFile形式被持久化起来。
设计MemStore的原因有以下几点
- 由于HDFS上的文件是不可修改的,为了让数据顺序存储从而提高读取效率,HBase使用了LSM树结果来存储数据。
MemStore会将数据整理成LSM树,最后在刷写到HFile上。
读取操作是先BlockCache,在读取MemStore+HFile。 - 优化数据的存储。如:一个数据添加后立马就删除,这样在刷写的时候就可以直接不把这个数据写到HDFS上。
HFile
HFile是数据存储的实际载体,创建的所有标、列等数据都存储在HFile里面。
HFile是由一个一个的块组成的。在HBase中一个块的大小默认是64KB,由列族上的BLOCKSIZE属性定义。
架构图
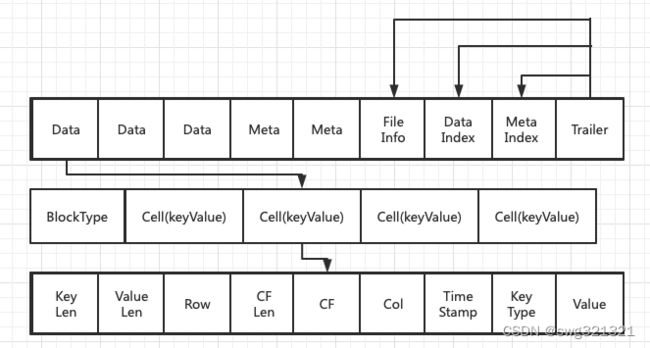
- Data: 数据块。每个HFile中有多个Data块。存储HBase表中的数据。(可选)
- Meta:元数据块。Meta块只有在文件关闭时才写入,Meta块存储该Hfile文件的元信息。(可选)
- FileInfo:文件信息。在文件关闭时写入,存储的是这个文件的信息,如:最后一个Key(Last Key)、平均的Key长度(Avg Key Len)等。(必选)
- DataIndex:存储Data块索引信息的文件块。索引信息即Data块的偏移值(offset),有Data块就有DataIndex。(可选)
- MetaIndex:存储Meta块索引信息的文件块。有Meta才有MetaIndex。
- Trailer:存储FileInfo、DataIndex、MetaIndex块的偏移值。(必选)
Data
Data数据块的第一位存储的是块的elixir,后面存储多个Cell(KeyValue键值对)。
BlockType(块类型)
- DATA(数据)
- ENCODE_DATA(数据编码格式)
- LEAF_INDEX(叶索引)
- BLOOM_CHUNK(BLOOM块)
- META(元数据)
- INTERMEDIATE_INDEX(中间索引)
- ROOT_INDEX(根索引)
- GENERAL_BLOOM_META(通用BLOOM元数据)
- DELETE_FAMILY_BLOOM_META(删除族BLOOM元数据)
- TRAILER
- INDEX_V1
KeyValue类(Cell)
- KeyLen 键长读
- ValueLen 值长度
- RowLen 行长度
- Row:行
- CF LEN:(Column Family,列族)长度
- CF:(Column Family,列族)
- Col: (Column,列)
- Time Stamp: 时间戳
- Key Type: 键类型
10.Value: 具体值
HBase实现增删改成
因HBase是持久化到HDFS的,所有不支持修改。
- 新增一个单元格的时候,HBae在HDFS新增一条数据。
- 修改一个单元格的时候,HBase在HDFS新增一条数据,只是版本好比之间的大。
- 删除一个单元格的时候,Hbase在HDFS新增一条数据,这条数据没有value,类型为DELETE。
真正删除发生的时候
通过Minor Compaction 和 Major Compaction合并实现删除数据
- Minor Compaction: 将Store中多个HFile合并为一个HFile。在这个过程中达到TTL的数据会被移除,但是被手动删除的数据不会被移除,触发频率高。
- Major Compaction: 合并Store中所有HFile为一个HFile。在这个过程中手动删除的数据会被真正地移除。同时被删除的还有单元格内超过MaxVersion的版本数据,触发频率低,默认为7天一次,且消耗性能较大。