编译原理--实验1 词法分析
文章目录
- 前言
- 1.1 实验目的
- 1.2 实验任务
- 1.3 实验内容
-
- 1.3.1 实验要求
- 1.3.2 输入格式
- 1.3.3 输出格式
- 1.3.4 样例
- 1.3.5 C--语言文法
- 1.4 程序代码
-
- 1.4.1 程序流程图
- 1.4.2 程序源码
- 1.5 总结
前言
编译原理课程实验的实验课内容—构造词法分析程序。通过本次实验,希望对于编译原理中词法分析这个功能有更深和更好的理解。
1.1 实验目的
(1)理解有穷自动机及其应用。
(2)掌握 NFA 到 DFA 的等价变换方法、DFA 最小化的方法。
(3)掌握设计、编码、调试词法分析程序的技术和方法。
1.2 实验任务
编写一个程序对输入的源代码(源代码可以是C++, C, Java等)进行词法分析,并打印分析结果。
1.3 实验内容
1.3.1 实验要求
你的程序要能够查出源代码中可能包含的词法错误: 词法错误(错误类型 A):(以输入 C–源代码为例)即出现 C–词法中未定义的字符 以及任何不符合 C–词法单元定义的字符;
1.3.2 输入格式
你的程序输入是一个包含 C++ 源代码的文本文件,程序需要能够接收一个输入文件名作为参数,以获得相应的输出结果。
1.3.3 输出格式
要求通过标准输出打印程序的运行结果。对于那些包含词法错误的输入文件,只要输出相关的词法有误的信息即可。在这种情况下,注意不要输出任何与语法树有关的内容。
要求输出的信息包括错误类型、出错的行号以及说明文字, 其格式为:
Error type [错误类型] at Line [行号]: [说明文字].
说明文字的内容没有具体要求,但是错误类型和出错的行号一定要正确,因为这是判断 输出的错误提示信息是否正确的唯一标准。请严格遵守实验要求中给定的错误分类(即词法 错误为错误类型 A).注意,输入文件中可能会包含一个或者多个词法错误(但输入文件的同一行中保证不出现多个错误),你的程序需要将这些错误全部报告出来,每一条错误提示信息在输出中单独占一行。 对于那些没有任何词法错误的输入文件,你的程序需要打印每一个词法单元的名称以及 与其对应的词素,无需打印行号。词法单元名与相应词素之间以一个冒号和一个空格隔开。 每一条词法单元的信息单独占一行。
在很多程序设计语言中,下面的类别覆盖了大部分或所有的词法单元:
1)关键字。一个关键字的类型就是该关键字本身。
2)运算符。它可以表示单个运算符,也可以像表 1-1 中的 comparison 那样,表示一类 运算符。
3)标识符。一个表示所有标识符的词法单元。
4)常量。一个或多个表示常量的词法单元,比如数字和字面值字符串。 5)界符。每一个标点符号有一个词法单元,比如左右括号、逗号和分号。

1.3.4 样例
样例1:
输入:
int main()
{
int i=1;
int j=~i;
}
输出:
Error type A at Line 4: Mysterious character "~".
样例2:
int inc()
{
int i;
i=100;
}
输出:
TYPE: int
ID: inc
LP: (
RP: )
LC: {
TYPE: int
ID: i
SEMI: ;
ID: i
RELOP: =
INT: 100
SEMI: ;
RC: }
1.3.5 C–语言文法
以下为C–文法中各个标识符或关键字等所对应的名称
INT→ /* A sequence of digits without spaces */
FLOAT → /* A real number consisting of digits and one decimal point. The decimal point must be surrounded by at least one digit */
ID → /* A character string consisting of 52 upper- or lower-case alphabetic, 10 numeric and one underscore characters. Besides, an identifier must not start with a digit */
SEMI → ;
COMMA → ,
ASSIGNOP→ =
RELOP → > | < | >= | <= | == | !=
PLUS → +
MINUS → -
STAR → *
DIV → /
AND → &&
OR → ||
DOT → .
NOT → !
TYPE →int | float
LP → (
RP → )
LB → [
RB → ]
LC → {
RC → }
STRUCT → struct
RETURN → return
IF → if
ELSE → else
WHILE → while
1.4 程序代码
1.4.1 程序流程图
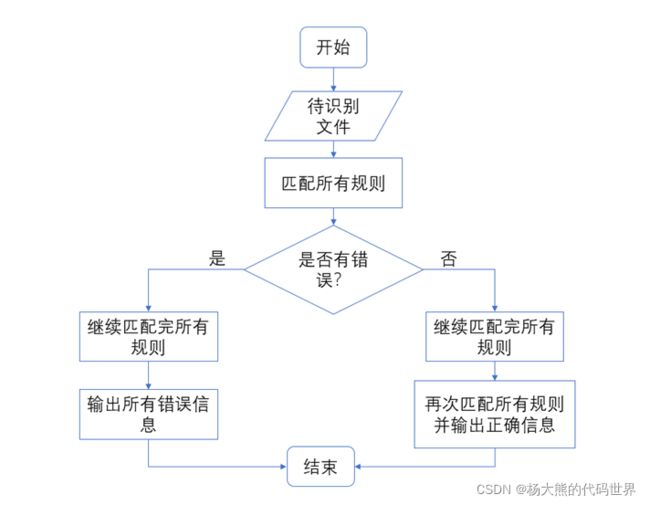
1.4.2 程序源码
# include1.5 总结
这次实验让我掌握了一个小型词法分析程序完整的构造过程,从查阅各种资料开始,到慢慢的理解别人的代码和思想,再到自己动手去编写一个词法分析程序。这样的一个过程既锻炼了自己的学习能力,也锻炼了自己的思维和编程能力,帮助我更好的学习编译原理这门课程,令我感到受益匪浅。
参考文献:(38条消息) 编译原理实验一:词法分析_那又怎样的博客-CSDN博客_编译原理实验一 词法分析