OpenCV学习笔记(一)
OpenCV简介
本篇属于翻译类的学习笔记,督促现在的自己学习之用,也供以后回头再看。
OpenCV (Open Source Computer Vision Library: http://opencv.org) 是一个BSD开源许可协议下的库,它包含了成千上万的计算机视觉算法。
OpenCV是模块化结构,这意味着这个库包含了几个共享或者静态子库。以下的库在OpenCV中:
Core functionality - 一个定义了基本数据结构的简洁模块,包括密集多维数组Mat(dense multi-dimensional array我觉得这里密集可能是相对与稀疏矩阵来讲的)以及一些供其他模块使用的基础函数。
Image processing - 一个图像处理模块,包括线性和非线性的图像滤波,图像几何变换(缩放、仿射和透视变换,通用表格重新映射),颜色空间转换,直方图等等。
video - 视频分析模块,包括运动估计、背景消除、目标跟踪算法。
calib3d - 基本的3D图像处理算法,包含了多视角几何算法、单体和立体相机标定、对象姿态估计、双目立体匹配算法和元素的三维重建。
features2D - 显著特征检测算法、描述算法、算子匹配算法。
objdetect - 目标检测和预定义的物体类(如脸、眼睛、马克杯、人、车等等)。
highgui - 简单UI易用的接口。
Video I/O 视频捕获和视频编码的易用接口。
gpu - 为其他模块提供GPU加速算法。
其他一些辅助模块,比如FLANN和Google测试包装、Python绑定以及其他。
接下来的章节描述每个模块。首先要熟悉常用的API概念,这些概念将贯穿整个库。
API概念
cv Namespace(cv命名空间)
所有OpenCV类和函数都在cv命名空间里面。因此你的代码要使用这些函数的时候就要使用cv::或者using namespace cv.
例如:
#include "opencv2/core.hpp"
...
cv::Mat H = cv::findHomography(points1,points2,CV_RANSAC,5);
...或者
#include "opencv2/core.hpp"
using namespace cv;
...
Mat H = findHomography(points1,points2,CV_RANSAC,5);
...一些当前或者将来的OpenCV外部名称可能会与STL库或者其他库冲突。这种情况下,显示的使用命名空间来解决名字冲突问题:
Mat a(100,100,CV_32F);
randu(a,Scalar::all(1),Scalar::all(std::rand()));
cv::log(a,a);
a /= std::log(2.);自动内存管理
所有的内存OpenCV都自动处理。
首先,函数和方法所使用的std::vector,Mat以及其他数据结构都有析构函数,这使得在需要的时候可以释放潜在的内存缓冲。这意味着析构函数并不总是释放缓冲,比如使用Mat时候。他们会考虑数据有可能共享。一个析构函数减少与矩阵数据缓冲引用的计数器。当且仅当计数器为零的时候这个缓冲才释放,也就是,没有其他结构引用该缓冲的时候。同样,当一个Mat实例被复制时,并不是数据重新复制了一份。而是引用计数增加了,代表另外一个拥有同样的数据。Mat::clone方法则创建了一个矩阵数据的完整副本。
看下面的例子:
// 创建一个8Mb的大矩阵
Mat A(1000, 1000, CV_64F);
// 为同一个矩阵创建另外一个名字,这是一个即时操作,不管矩阵大小
Mat B = A;
// 为矩阵A的第三行创建另外一个名字,同样没有复制数据
Mat C = B.row(3);
// 现在创建矩阵的独立副本
Mat D = B.clone();
// 复制B的第五行到C,也就是,复制A的第五行到A的第三行
B.row(5).copyTo(C);
// 现在让A和D共享数据;修改了A后,B和C依然引用着
A = D;
// 现在设置B为空,修改A时,依然被C引用着,尽管C只是原始A的一行
B.release();
// 最后,复制C。结果最初的大矩阵将因没有被任何所引用而被释放。
C = C.clone();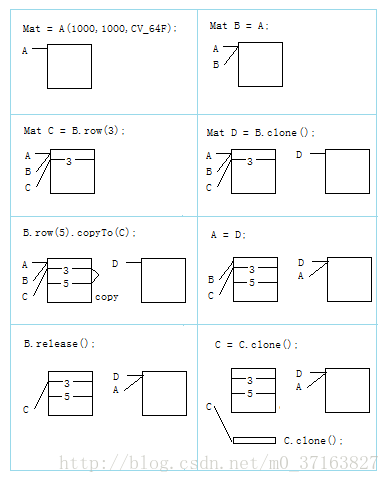
你可以看出使用Mat以及其他基本数据结构很简单。但是更高类或者用户数据类型被创建的时候不用考虑自动内存管理?对他们而言OpenCV提供Ptr模板类类似于C++11标准中的std::shared_ptr,而不是使用简单的指针。
T* ptr = new T(...);可以使用
Ptr<T> ptr(new T(...));或者
Ptr<T> ptr = makePtr<T>(...);Ptr封装一个指向T实例的指针以及与指针有关的引用计数器。有关详细信息,请参阅Ptr描述。
自动分配输出数据
OpenCV自动释放内存,同样,多数情况下自动为输出函数参数分配内存。因此,一个函数如果有一个或者多个输入数组(例如cv::Mat)和一些输出数组,这些输出数组会自动分配或者重分配。输出数组的大小和类型取决于输入数组的大小和类型。如果需要,函数将用额外的参数计算输出数组的属性。
例如:
#include "opencv2/imgproc.hpp"
#include "opencv2/highgui.hpp"
using namespace cv;
int main(int, char**)
{
VideoCapture cap(0);
if(!cap.isOpened()) return -1;
Mat frame, edges;
namedWindow("edges",1);
for(;;)
{
cap >> frame;
cvtColor(frame,edges,COLOR_BGR2GRAY);
GaussianBlur(edges,edges,Size(7,7),1.5,1.5);
Canny(edges,edges,0,30,3);
imshow("edges",edges);
if(waitKey(30) >= 0)break;
}
return 0;
}由于视频捕获模块知道视频帧的分辨率和位深度,所以>>操作符将为数组frame自动分配内存。数组edges由cvtColor函数自动分配。它的大小和深度与输入数组一样。通道的数量是1,因为颜色转换代码是COLOR_BGR2GRAY,意思是彩色转灰度。注意,frame和edges在循环体的第一次执行中只分配一次,因为所有下一个视频帧都有相同的分辨率。如果你在某种程度上改变了视频分辨率,那么数组就会自动重新分配。
这项技术的关键组成部分是Mat::创建方法。它决定所需的数组大小和类型。如果数组已经有指定的大小和类型,则该方法什么也不做。否则,它将释放以前分配的数据,如果有的话(这部分涉及到将引用计数器进行减记,并将其与0进行比较),然后分配所需大小的新缓冲区。大多数函数为输出数组调用Mat::创建方法,这样就实现了输出数据的自动分配。
和这种功能(自动分配)有明显区别的是 cv::mixChannels, cv::RNG::fill,以及其他少量的函数和方法。它们不能分配输出数组,所以你必须提前做这个(分配内存)。
色饱和度运算
作为一个计算机视觉库,OpenCV处理大量的图像像素,这些图像像素通常被编码成一个紧凑的,8或16位的通道,形式,因此有一个有限的值范围。此外,对图像的某些操作,如颜色空间转换、亮度/对比度调整、锐化、复杂插值(双立方、兰开斯)可以产生出可用范围之外的值。如果您只存储结果中最低的8(16)位,这将导致人为视觉化,并可能影响进一步的图像分析。为了解决这个问题,我们使用了所谓的饱和算术。例如,要将一个操作的结果存储为一个8位的图像r,您可以在0到255范围中找到最近的值。
I(x,y)=min(max(round(r),0),255)
(round(r),对r进行四舍五入取整。然后与0比较,取较大值。最后与255比较取较小值。这样得到一个最接近的可视结果。也就是,取整后,小于0的用0代替,大于255的用255代替,其他保留。)
同样的规则适用于8位有符号、16位有符合和无符号类型。这个语义在库中的任何地方都被使用。在C++代码中,它使用了saturate_cast<> 函数类似标准的C++cast操作。参见下面的公式的实现:
I.at<uchar>(y, x) = saturate_cast<uchar>(r);其中cv::uchar是OpenCVS中8位无符号整数类型。在优化的SIMD代码中,这些SSE2指令有paddusb, packuswb, 等被使用。它们可以帮助实现与C++代码完全相同的操作。
当结果是32位整数时,不应用饱和度。
固定像素类型。有限使用的模板
模板是C++的一个很好的特性,它能够实现非常强大、高效且安全的数据结构和算法。但是,大量使用模板可能会极大地增加编译时间和代码大小。此外,当模板被单独使用时,很难分离一个接口和实现。这对于基本的算法来说是很好的,但是对于计算机视觉库来说不是很好,因为一个算法可以跨越数千行代码。因此,为了简化其他语言的绑定,比如Python、Java、Matlab,这些都没有模板,或者有有限的模板功能,当前的OpenCV实现基于多态和运行时调度。在那些运行时调度会太慢的地方(如像素访问操作符)、不可能的(泛型Ptr<>的实现),或者非常不方便的(saturate_cast<>())当前的实现引入了小的模板类、方法和函数。在当前OpenCV版本的其他任何地方,模板的使用都是有限的。
因此,有一组有限的原始数据类型,这是库可以操作的。也就是说,数组元素应该有下列类型之一:
- 8-bit unsigned integer (uchar)
- 8-bit signed integer (schar)
- 16-bit unsigned integer (ushort)
- 16-bit signed integer (short)
- 32-bit signed integer (int)
- 32-bit floating-point number (float)
- 64-bit floating-point number (double)
- 一个由多个元素组成的元组,其中所有元素都具有相同的类型(上面的一个)。如果一个数组的元素是元组,该数组被称为多通道数组,与单通道数组相反,后者的元素是标量值。通道的最大可能数量是由CV_CN_MAX常量定义的,它当前设置为512。
对于这些基本类型,应用以下枚举:
enum { CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3, CV_32S=4, CV_32F=5, CV_64F=6 };可以使用以下选项指定多通道(n通道)类型:
- CV_8UC1 … CV_64FC4 常量(通道从1到4)
- CV_8UC(n) … CV_64FC(n) 或者 CV_MAKETYPE(CV_8U, n) … CV_MAKETYPE(CV_64F, n)在编译时,通道数量大于4或未知的宏。
CV_32FC1 == CV_32F, CV_32FC2 == CV_32FC(2) == CV_MAKETYPE(CV_32F, 2), 以及 CV_MAKETYPE(depth, n) == ((depth&7) + ((n-1)<<3)
.这意味着常数类型是由深度形成的,取最小的3位,而通道的数量减去1,取 log2(CV_CN_MAX)的下一位。
例如:
Mat mtx(3,3,,CV_32F);//创建一个3x3的浮点矩阵
Mat cmtx(10,1,CV_64FC2)//创建一个10x1的2通道浮点矩阵(10个元素的复合向量)
Mat img(Size(1920,1080),CV_8UC3);//创建一个3通道(彩色)1920列1080行的图片
Mat grayscale(image.size(),CV_MAKETYPE(image.depth(),1));//创建一个与image一样大小一样深度的1通道图
使用OpenCV不能构造或处理更复杂的元素的数组。此外,每个函数或方法只能处理所有可能的数组类型的一个子集。通常,算法越复杂,支持的格式子集就越小。以下是这些限制的典型例子:
- 人脸检测算法只适用于8位灰度或彩色图像。
- 线性代数函数和大多数机器学习算法只使用浮点数组。
- 基本函数,如cv::add,支持所有类型。
- 颜色空间转换函数支持8位无符号、16位无符号和32位浮点类型。
每个函数的支持类型的子集都是根据实际需要定义的,并且可以在将来根据用户请求进行扩展。
InputArray 和OutputArray
许多OpenCV函数处理密集的二维或多维数字数组。通常,这样的函数将cppMat作为参数,但在某些情况下,使用std::vector<> 更方便(例如,一个点集)或Matx<> (对于3x3的同形矩阵等)。为了避免API中的许多重复,已经引入了特殊的“代理”类。基本的“代理”类是InputArray。它用于在函数输入上传递只读数组。来自InputArray类派生的OutputArray的用于指定一个函数的输出数组。通常,您不应该关心这些中间类型(您不应该显式地声明这些类型的变量)——它将自动地工作。你可以用Mat, std::vector<>, Matx<>, Vec<> 或者标量来代替inputarray/outputarray。当一个函数有一个可选的输入或输出数组时,如果您没有或不想要,可以使用cv::noArray()。
错误处理
OpenCV使用异常来表示运行时错误。当输入数据有正确的格式并属于指定的值范围时,但是算法由于某种原因不能成功(例如,优化算法没有收敛),它返回一个特殊的错误代码(通常是一个布尔变量)。
异常情况可以是cv::Exception类或它的派生类。反过来,cv::Exception是std::exception的衍生。因此,可以使用其他标准的C++库组件在代码中很好地处理它。
通常抛出的异常是使用 CV_Error(errcode, description)宏,或者它的printf型CV_Error_(errcode, printf-spec, (printf-args)) 变体,或者使用CV_Assert(condition)宏检查条件,并在不满足时抛出异常。对于性能关键的代码, CV_DbgAssert(condition) 只在调试配置中保留。由于自动内存管理,所有中间缓冲区都自动地在发生意外错误时自动处理。如果需要的话,您只需要添加一个try语句来捕获异常:
try
{
... // 调用OpenCV
}
catch( cv::Exception& e )
{
const char* err_msg = e.what();
std::cout << "exception caught: " << err_msg << std::endl;
}多线程和重载
当前的OpenCV实现是完全可重载。也就是说,相同的函数,类实例的相同常数方法,或者不同类实例的非常量方法可以从不同的线程中调用。相同的 cv::Mat可以在不同的线程中使用,因为引用计数操作使用特定于体系结构的原子指令。
END